Now-a-days there is a lot of attention to cloud computing by the Research community. Cloud computing is a platform that supports the sharing of resources, communication and storage capacity over the internet. The primary benefit of moving to the Clouds is application scalability. It provides virtualized resources and are built on the base of Grid & distributed computing. Cloud computing is also environmental friendly framework. It benefits from the efficient utilization of resources and optimal scheduling algorithms. The growth of internet based applications demands the need for the development of algorithms that cope with the escalation in energy consumption and reduce the operational cost and emission of CO gases. In this paper, the authors present a review on energy aware job scheduling algorithms existing 2 in the literature. This paper helps the readers to understand the functionality and parameters focus of various energy aware scheduling algorithms available in the literature.
Cloud Computing is a scorching topic in the field of computers as an emerging new computing model [1]. It is a type of computing in which dynamically scalable and virtualized resources are provided as service over Internet [2]. According to NIST (National Institute for Standard Technology), cloud computing is defined as a pay-peruse model which allows on-demand network access to a shared pool of configurable computing resources that can be rapidly provisioned and released with minimal management effort or service provider interaction. Cloud computing is a model for ubiquitous, on-demand network access to the shared pool of configurable computing resources. The aim of green cloud computing is to have high per formance, and low-power computing infrastructure to have an energy efficient mode.
Models of cloud computing are shifting tremendously. The richest application running on the internet devices is client and in Client/Cloud architecture, a set of application services are running on the server in a rapidly increasing cloud computing platform. Applications can stretch across multiple client devices in the cloud. The environment in the cloud computing could be native application or browser based.
Power consumption is one of the nit picking issues in meeting the needs of different kinds of scheduling the resources in the cloud. Reducing the execution time is one of the factors, while scheduling the workflow and this is achieved by increasing the clock frequency, but which will lead to more consumption of power and heat dissipation [7]. There is a cop-out between performance and the power consumption. The design for aware of energy will not reduce the power or energy, but may decrease the peak power consumption in the processor.
Most researches have concentrated on the energy consumption levels in the data centers [3,4,5].The EPA, Environmental Protection Agency made a study and computed energy consumption at the data center and that will double from 2006 (61 billion kWh) to 2011 [3]. In 2009, the data center accounted for 2% of the worldwide electricity consumption with an impact of $30 billion [5].
The main drawback of consumption of energy in IT sector is the emission of greenhouse gases. IT sector contributes indirectly to carbon dioxide emission [4]. It is also responsible for 2% of carbon dioxide worldwide in 2005 [3]. The efficiency is computed by metric Power Usage Effectiveness (PUE), and which is defined as the ratio of energy usage in the total data center to the energy usage of IT equipment [3].
The tasks are scheduled by user requirements. Scheduling is a very important problem in a cloud computing environment. Scheduling becomes difficult only when the number of users in the cloud gets increased. Therefore, there is a need to go for a better scheduling algorithm than the existing one. This can be done by comparing and evaluating the various existing algorithms, thereby identifying the loopholes in the existing algorithms.
The Scheduling algorithms are compared based on different kinds of parameters such as throughput, Response time, Resource utilization, Execution time, scalability and Fault tolerance.
It is defined as the amount of work that a computer can do in a given Time period (or) Rate at which something can be processed.
It is defined as the total amount of time it takes to respond to a request for service. The sum of service time and the wait time is Response Time (or) the time, the Functional unit takes to react to a given input.
Resources should be utilized efficiently to maximize customer service levels, to minimize lead time, and optimize inventory levels. It is defined as the amount of sources used to perform a particular task.
It prevents a computer network device from failing in an event of error, also enables the system to continue operating properly in the event of failure.
It is defined as the time during which a program runs.
It is defined as the ability to meet the increasing demands and growing amounts of work.
The main objective of this paper is to
There are a number of scheduling algorithms that are used in both Grid and cloud environment. The functionality of various algorithms available in the literature and their features is discussed in this section. Table 1 shows the comparison of various scheduling algorithm
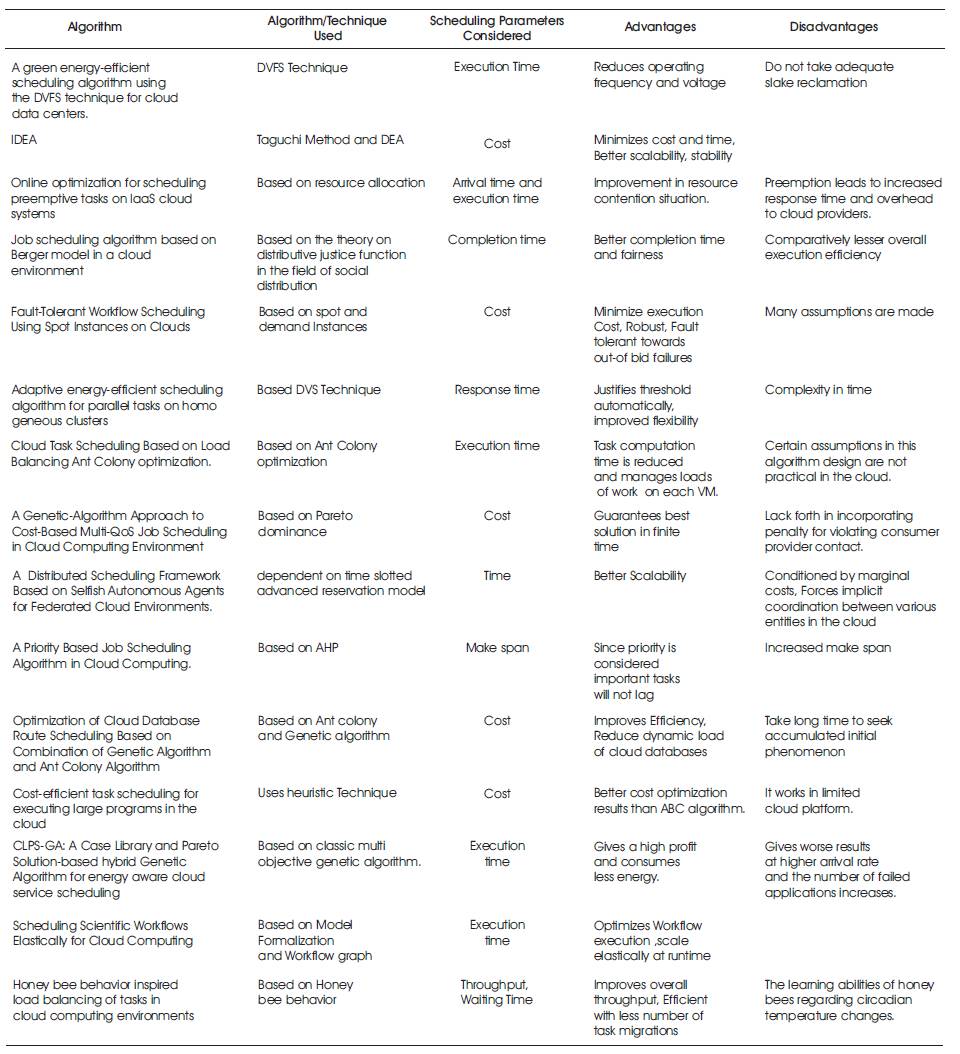
Table 1. Comparison of Various Scheduling Algorithms
Lalshrivratt Singh, et al., proposed P-Backfill algorithm. This algorithm is based on traditional Backfill algorithm using Prioritization of Jobs. To utilize cloud resources efficiently with less waiting time, the dynamic meta scheduler will deploy the arriving jobs using algorithm. It stats the execution of jobs according to priority states. This algorithm also uses Pipelining mechanism [6].
Iaoyong Tang et al., proposed a hierarchical driven scheduling algorithm which has a local scheduler and global scheduler. The algorithm is dependent on the evaluation of every application reliability quantitatively [7].
Chia-Ming et al., proposed a Green Energy Efficiency algorithm for data center using DVFS technique. This technique is used to reduce the consumption of energy in the microprocessors, which is mainly used in laptops and cell phones generated by a separate scheduler. DVFS is used in super computers & clusters which reduces the operating frequency and voltage that leads to decrease in consumption of power of a given resource. There are two disadvantages of this DVFS Technique: (i) It focuses on schedule generation and do not take adequately the slack reclamation approaches to save more energy, (ii) The slack reclamation method use, only one frequency for each task among all set of processors frequency.
The consumption of energy in a server can be reduced using this technique when it is in the idle state or having less workload. The excess use of resources are prevented and minimum resource requirement of a job are satisfied [8].
Jinn-Tsong Tsai et al. proposed IDEA, a scheduling algorithm for cloud computing environment which optimizes task scheduling and resource allocation [7]. Two mock-ups were developed to reduce the total time and cost in Task scheduling. Using Taguchi method, IDEA algorithm improves Differential Evolution Algorithm (DEA) to generate an upgraded offspring.
Jiayin Li et al., proposed an approach for increasing the utilization of clouds using preemptive task execution. The algorithm adjusts resource allocation dynamically [9].
In a cloud data center to arrange the resources for executing jobs, a job scheduler is needed. The algorithm was proposed by Baomin Xu et al., has been established on Berger model. The Berger Model is planted on the Expectation states. This algorithm maintains two constraints. To classify the tasks of users, QoS preferences is the first constraint. Resource allocation fairness is judged by defining the fairness justice function is the second constraint [10].
Deepak Poola et al., designed an algorithm which is Fault tolerant in contrast to spot instances prior termination. The algorithm maps the task submitted by dispatcher onto the cloud resources [11].
Wei Liu, et al., proposed an adaptive energy efficient scheduling algorithm for performing parallel tasks on homogeneous clusters, which combines the adaptive task duplication strategy with Dynamic Voltage Scaling (DVS) Technique. The algorithm improves the Flexibility of the system, that also justifies threshold automatically. The algorithm goes in 2 phases. In the First phase, we can obtain an optimal threshold using adaptive threshold based task duplication strategy. In second phase, it schedules the groups on DVS enabled processors to reduce the energy of processors [12].
The authors have proposed a Load Balancing Ant Colony Optimization (LBACO) algorithm to harmony the total system load while reducing the make span of a given task. This algorithm is better than FCFS, the basic Ant colony optimization [13].
The authors have proposed a genetic algorithm for multi QoS job scheduling which is based on the cost. They have also designed famous genetic cross over operators like PMX, OX, CX, Mutation, Swap and Insertion mutation [14].
Palmerieri et al proposed a federated cloud environment, a fully distributed scheduling framework. The framework is based on independent and self organized agents which does not depend on any centralized control. The benefits are Good quality, Scalability, and gains high performance [15].
Ghanbari and Othman have proposed a priority based job scheduling algorithm based on multiple decision making models. The algorithm is also dependent on the theory of Analytical Hierarchy Process (AHP) [16].
Zhang et al., proposed a route scheduling algorithm based on Ant colony and genetic algorithm. To find an optimal solution from ant colony algorithm, the initial value of genetic algorithm is given as input [17].
The algorithm uses two Heuristics techniques. In the first technique based on the concept of Pareto dominance, tasks are mapped dynamically to most cost efficient VM's. The second technique is complement to that first technique, that is it reduces the monetary costs of non critical tasks [18].
Ying Feng, et al., proposed CLPS-GA (A Case Library and Pareto Solution based hybrid genetic algorithm) for energy aware cloud service scheduling. This algorithm is based on classic multi objective genetic algorithm. CLPSGA includes Multi Parent Crossover Operator (MPCO), which is a 2 stage algorithm structure and case Library [19].
Cui Lia, and Shiyong Lu proposed a Scalable Heterogeneous Earliest Finish Time algorithm, which is used to roster the flow of work in the climate of cloud computing. This algorithm is a prolongation of HEFT algorithm [20].
Dhinesh Babu, et al., proposed Honey Bee Behavior inspired Load Balancing algorithm. The algorithm balances load across VM for maximizing throughput. Load Balancing is based on Honey bee foraging strategy, which also improves the overall throughput [21].
Chang Liu, et al., proposed CCBKE (Cloud Computing Background Key Exchange), a unique, proven key exchange scheme. The main goal of the algorithm is to make the scheduling in scientific applications a proficient and security aware. This algorithm is based on internet key exchange and strategy of Random Reuse [22].
Yuanjun Laili et al., proposed the RCO algorithm. It is a dual scheduling algorithm, which is a combination of Service Composition Optimal Selection (SCOS) and Optimal Allocation of Computing Resources (OACR). To control the state of population, an adaptive Ranking selection is introduced. In this algorithm, Dynamic Heuristics are also defined [23].
Due to the challenges associated with Scheduling such as energy efficiency, resource allocation, and preemptive tasks, scheduling algorithms in cloud computing are more challenging as compared to other networks. In this paper, the authors have given a review about the various scheduling algorithms. Based on the requirements of data center and the kind of data they store in it, the scheduling algorithm for the data center can be chosen. This survey has provided us a good idea about the wide dimensions of scheduling resources and their functions. From the scheduling algorithms, it is observed that there is a need to implement a scheduling algorithm that can improve the availability and reliability in cloud environment.

