Multi document summarization differs from the single document. Issues of compression, speed, and redundancy and passage selection are critical in the form of useful summaries. A collection of different documents is given to a variety of summarization methods based on different strategies to extract the most important sentences from the original document. LDA (Latent Dirichlet Allocation) topic modeling technique is used to divide the documents topic wise for summarizing the large text collection over the MapReduce framework. Compression ratio, retention ratio, Rouge and Pyramid score are different summarization parameters used to measure the performance of the summarizing documents. Semantic similarity and clustering methods are used efficiently for generating the summary of large text collections from multiple documents. Summarizing multi documents is a time consuming problem and it is a basic tool for understanding the summary. The presented method is compared with the MapReduce framework based k-means clustering algorithm applied on Four Multi-document summarization methods. Support for multilingual text summarization is provided over the MapReduce framework in order to provide the summary generation from the text document collections available in different languages.
Multi-document summarization is a difficult task because it takes multiple documents analyzed for generating the meaningful summary. For summarizing the multidocument’s input as the news archives, research papers, tweets, and technical reports are available in the internet. The numbers of Summarization techniques presented generate the meaningful summary by extracting the important sentences from the source of the collection of documents. Summarization Evaluation is performed based on Rouge and Pyramid Scores[7]. There are two summarization approaches, Extractive and Abstractive Extractive: Extractive summarization, extracts the sentences or paragraphs up to certain limit to provide a coherent summary. This technique is mainly focused on automatic summarization method. Extractive method is an essential role in the single and multi-document summarization, where these are used as statistical measures. Some features for extracting the sentences are such as score based [word frequency][ [42,43], identifying the key phrases and position of the text. The main approach for single document summarization is to provide a summary for a single document and whereas in multi-document summarization used, a collection of multi documents which are related to relevant documents produce a summary as a single document. Abstractive Summarization is used to understand the content with a certain degree which are expressed in the original document and creates the summaries based on information[1]. It is a human summarization method, which is more difficult to implement. The process of Query based summarization is mainly used to retrieve the sentences from document and that matches the user query.
MapReduce is a programming model for generating the large data through parallel algorithm. MapReduce is an essential to summarized multi-documents[2]. There are three requirements for summarizing multi-documents, Clustering: it is the ability to cluster similar documents and to find the related information. Anti-redundancy: This requirement is used to minimize redundancy between passages in the summary. Coverage: It is used to find out the main points and extract the important points across the document[4]. Text summarization is the process of summarizing a single document or a set of related important sentences. Redundancy elimination is one of the main difference between single and multi-document summarization.
For eliminating the redundant sentences in multidocument summarization, these models are used: Semantic, Syntactic and Statistical models. Statistical models were used to describe the selection or elimination of the sentences to the summarization process, and these are also subjected to sentences compression[45]. Rouge: To correlate with human evaluations for content match in text summarization and machine translation[8]. It is used to estimate extractive and abstractive summaries, but to correlate better for extractive [46,47]. Pyramid is used to evaluate the performance with precession measure. In text mining, the Text Summarization is a challenging problem. It provides a number of real life applications that can be developed based on text summarization and which benefits the user. There are four types of clustering, they are Partitioning clustering, Hierarchical clustering, Agglomerative clustering and Divisive clustering. We are using the Semantic and Clustering method for summarizing the large data. There are three techniques in semantic and syntactic methods, they are Graph representation, coreference chains and Lexical chains. Agglomarative clustering is a bottom approach, that reduce the large data in this approach[9]. And opposite to the agglomerative clustering is Divisive clustering, it is top down approach. Lexical chain is a flow of related words used to merge the long words. Two or more words or letters referred by the same person is called Co-reference chain. Statistical method is used to compress the sentence and relevant scores. Information Extraction is used to find the relevant sentences and extract it in Summarization of multi documents. MapReduce technique is more efficient for summarizing the large collection of data in either single document or multidocuments. Word Net is an example for automatic text summarization. And it is similar to the dictionary containing the description of the given word[5].
For summarizing the documents, different methods based on different strategies are presented to extract the most important sentences from the original documents. Four types of methods are used to multi-document summarization systems (i.e. the centroid-based method, the graph-based method, LSA, and NMF), and Weighted consensus method with various combination methods (e.g. average score, average rank, Borda count, median aggregation, round-robin scheme, correlation-based weighting method, and graph-based combination).
Weighted consensus multi-document summarization is described in [49]. Text extraction to multi-document summarization based on single - document summarization methods by using additional, available information from the document set as a relationship between the documents. Issues from Single document are speed, Redundancy, passage selection, and Compression.
Multi-Document Summarization By Sentence Extraction is shown in [44]. Big data are decomposed into many parts for parallel clustering. Ant Colony clustering algorithm is an useful method for semantic clustering of the data based on attribute character vectors.
MapReduce based Method for Big Data Semantic Clustering[12,13]. Information Extraction (IE) extracts the structured data from the Text. A Benchmark has been presented to systematically retrieve the large text from IE, along with the performance of the document[50].
A Performance Comparison of Parallel DBMSs and MapReduce on Large-Scale Text Analytics is given in [15].
Social Content Matching in MapReduce[3], distributes the information from supplier to the consumer. There are two matching algorithms for MapReduce paradigm, viz. Greedy MapReduce, Stack MapReduce. For analyzing large data and mining Big Data, MapReduce framework is used in a number of works[10]. Some of the works presented in this direction is web log analysis[2].
Summarizing large text collection is an interesting and challenging problem in text analytics[11]. A number of approaches was suggested for handling large text for automatic text summarization[21].
A MapReduce based distributed and parallel framework for summarizing large text is also presented by Hu and Zou [23].
A technique is proposed by Lai and Renals [24].for meeting summarization using prosodic features and augment lexical features [14]. Features related to dialogue acts are discovered and utilized for meeting summarization. An unsupervised method for the automatic summarization of source code text is proposed by Fowkes et al. [33]. The proposed technique is utilized for code folding, which allows one to selectively hide blocks of code. A multi-sentence compression technique is proposed by Tzouridis et al. [34].
Initially, the authors have collected the multiple documents which are related to each other, such as newspapers, research papers or conference papers through internet. There are four stages of summarizing a multi-document into a single document summary.
Document clustering is an initial stage, which initializes the document as a cluster center from the collected documents and these are applied to the next stage known as LDA (Latent Dirichlet Allocation), that decomposes the cluster centers as topic wise through topic modeling tool. In the Frequent and Semantic terms, the Topics are divided into the form of terms, and this stage, counts the number of frequencies. Sentence Filtering stage is applied on each individual document, and they removed the unimportant sentences and finally they obtained a meaningful summary. Summarizing the multi-document is based on Semantic similarity and clustering method[6].
MapReduce is a programming model for generating the large text collections through parallel algorithm. There are two types of functions they are Map() and Reduce() Functions. The Map() function assigns the jobs, i.e., in the presented methodology, multiple documents are assigned as the jobs and these documents are decomposed as the terms. Figure 1 shows the Multi Document Summarization[16-22].
Calculating the frequency of the these topic terms and selecting as a Semantic similar terms, these selected terms are computed by using WordNet Java API. In Figure 2, the documents such as DOC1 , DOC2 ,…..DOCN are assigned to the Map Function. These are divided as the terms T1 ,T2 ,…TK1 to each documents, and these terms are shuffled and Exchanged to the Reducer function. The Reducer() function, reduces each terms to its relevant documents[25-32].
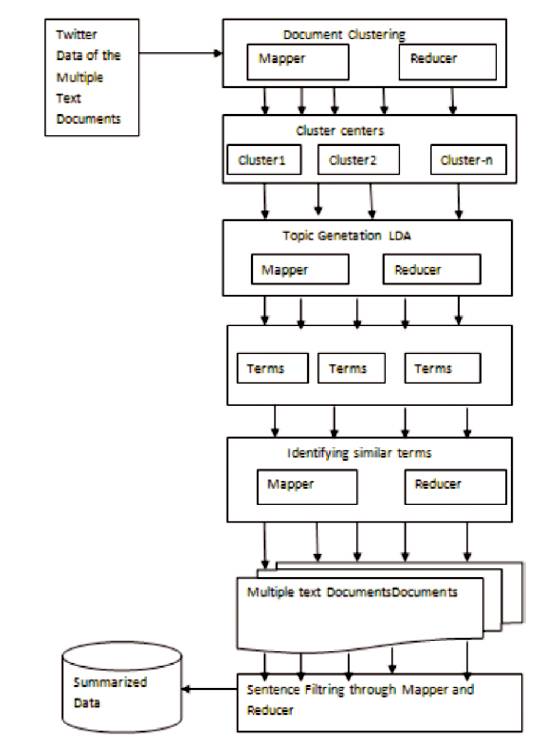
Figure 1. Steps for Multi-Document Summarization (Large Data)
Clustering is a process of creating and collecting of similar objects. K-means is a classical unsupervised learning algorithms used for clustering. It is a simple, low complexity and a very popular clustering algorithm. The kmeans algorithm is a separation based clustering algorithm. It takes an input parameter, k, i.e. the number of clusters to be produced, which separates a set of n objects to generate the k clusters. Performance of kmeans is measured using the square-error function defined in the equation,
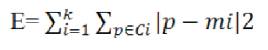
where E is the sum of the square error, p is the point in space instead of a given object and mi is the mean of cluster Ci. This criterion tries to make the resulting k clusters as compact and as separate as possible.
Algorithm: k-means.
Input:
k-the number of clusters,
D: A data set containing n objects
Output:
A set of k clusters.
Method:
(1) Randomly choose k objects from D as the initial clusters.
(2) Repeat.
(3) (Re)assign each object to the cluster to which the object is the most similar, based on the mean value of the objects in the cluster;
(4) Update the cluster means, i.e. calculate the mean value of the objects for each cluster;
(5) Until no change.
The algorithm is applied for each stage based on Mapper and reducer. The initial stage is based on Document Clustering of k-means. In this stage, the Mapper decomposes the documents as the cluster center and finds the near center and provides as a point. After creating the text document clustering, the document belonging to clusters are retrieved and the text information present in each document is collected as an aggregate.
The topic modeling technique is then applied on collective each information to generate the topics from each text document clusters. LDA (Latent Dirichlet Allocation) technique is used for generating topics from each document cluster. WordNet Java API is used to generate the list of semantic similar terms. The semantic similar terms are generated over the MapReduce framework and the generated semantic terms are added to the vector. The semantic similar term finds an intensive computing operation.
Mapper:
1. Initialize the cluster centers randomly and Read it into the memory from a sequence file,
{CMean1,CMean2, ,….C Meank} ←Random
2. Iterate each cluster center for each input key-value pair. Computer Center for all as, (K, V)
3. Calculate distance and assign the nearest center with the lowest distance,
Ci Min(d(key1,Ci ),….,d(keyN, Ci ))
4. Update the cluster center with its vector to the file system,
{(Ki1 ,Vi ),…,(KiM ,Vi1 )) єCi}
1. Iterate each value vector and calculate the mean.
2. Update the new center from the calculated mean,
C ←Avg(di1 ,…dij )
3. Check whether the cluster center is same as new center. If (CiOLD =CiNEW ), then stop, else GoTo next step.
4. If it they are not equal, increment an update counter. Run the Mapper and Reducer until the Cluster Converges.
In LDA algorithm, the cluster centers as C1 ,C2 ,….Cn . The Mapper, divides the Documents as the topic wise based on topic modeling technique. The Reducer integrates the topics of all the clusters, Extract all the topics discovered from LDA in the documents.
1. For each, cluster get the documents it contains and extract the text collection from the these documents.
2. For each cluster Ci є {C1 , C2 ,…., CN }.
3. Extract the documents in Ci as {Di1 , Di2 ,…DiM }.
4. For each document, extract and merge the text from the text collection.
5. Apply LDA topic modeling to these collection and get the list of topics for the cluster Ci as Ti = {Ti1 , Ti2 ,…TiK}.
1. Integrate the topics of all the clusters.
2. For each cluster Ci є{C1 , C2 ,…., CN }.
3. Extract the topics discovered by LDA in the documents in Ci as Ti ={Ti1 , Ti2 ,…TiK }
4. For each document extract, the text and computer the text collection.
5. Topics=Topics{Tij є Ti }
The Mapper computes the semantic similar terms for each topic term generated by the document cluster and the reducer aggregates these terms and counts the frequencies of these terms (topic terms and) semantic similar terms of topic terms) aggregately.
1. For each topic term in topic list {T1 ,T2 ,…TN }.
2. Get the semantic similar terms.
3. TSi = Compute Semantic Similar (Ti ).
//Pass the term Ti in WordNet API and extract the semantic similar Terms in the set TSi .
4. For all term t, t є TSi present in the document D do
5. Emit (term t; count 1)
1. For each term t, counts [c1 ,c2 ]
2. Initialize the sum of term frequency as 0.
3. For all count c є counts[c1 ,c2 ] do
4. Update sum by adding count i.e., sum + =c
5. Emit(term t; count sum)
In the Document Filtering algorithm, select the each individual document from the document collection, and extract the sentences from the document here, removing the unimportant or repeated sentences from the original document. The Reducer, Integrates all the filtered sentences and produces a single document and presents a summary to be easily understandable to the user.
1. Select one document at a time from the document collection.
2. For each Document D є{D1 ,D2 ,…..}
3. Extract the sentences from Document D as {Si1 ,Si2,….} using parsing.
4. If Sik contains the terms present in Tsi
5. Filter the sentences Sik containing the terms and add() Vector to it.
6. Vector=Vector ∪{Sik}
Integrate all the filtered sentences and produce a Single document presenting the Summary=Summary ∪{Slk}
The Implementation is carried by using the java based technologies. Majorly MapReduce implementation is performed by using the Hadoop environment. Initially we are collecting the Twitter data for summarizing the large collection of text data. The experiments are performed through Intel Core i3 processor with the 4GB RAM (Random Access Memory) and Windows 7(32-bit) Operating System. VM Ware Virtual machine is the major part for the experiments.
Many large text of the data are used in collecting the twitter data for summarizing the large data.
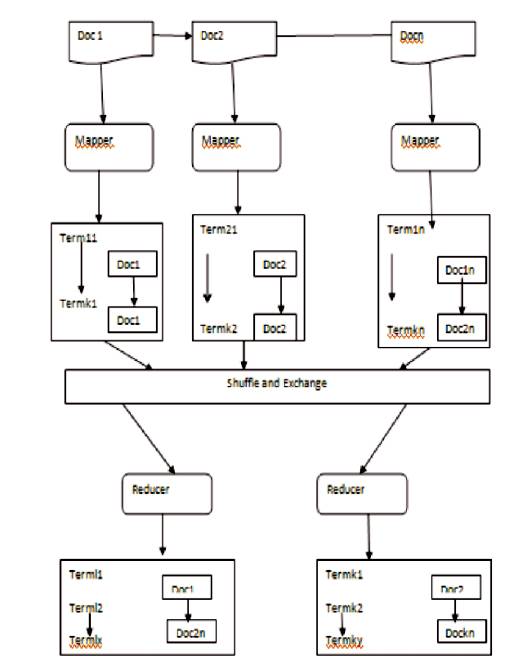
Figure 2. Calculating the Common Terms from the Text Collection by using MapReduce
Figure 3. Integrate all the Files
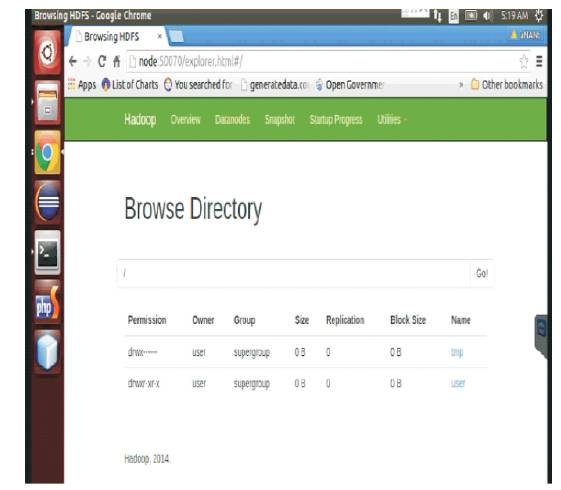
Figure 4. Inserting Node 50070 to Show the Directory
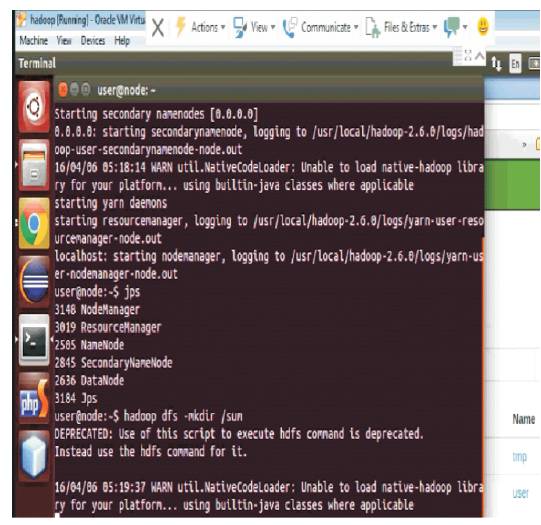
Figure 5. Create the New Directory
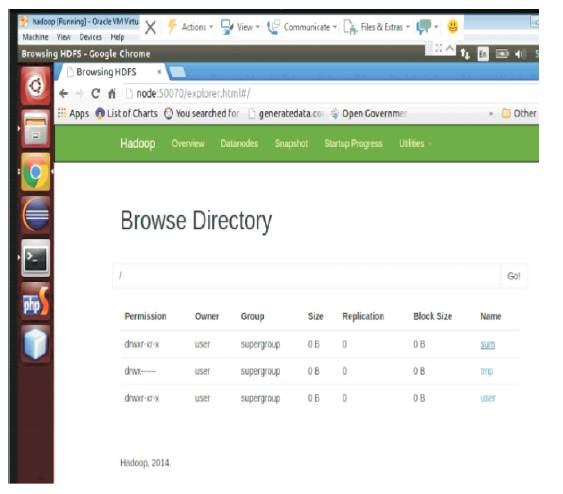
Figure 6. Sum Directory
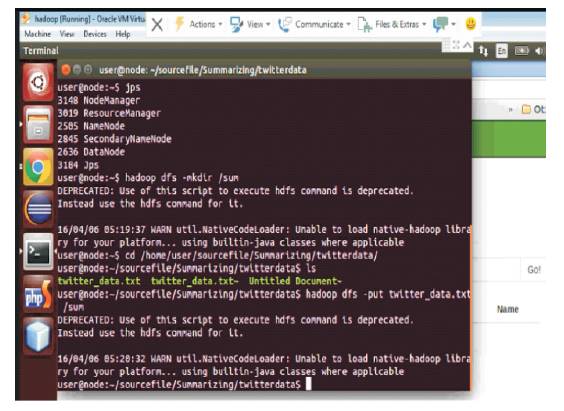
Figure 7. Inserting the Twitter Data for Summarizing
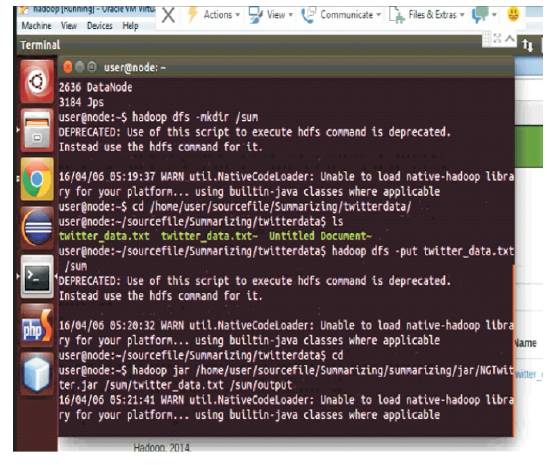
Figure 8. Put the Twitter_Data.txt in Sum Directory
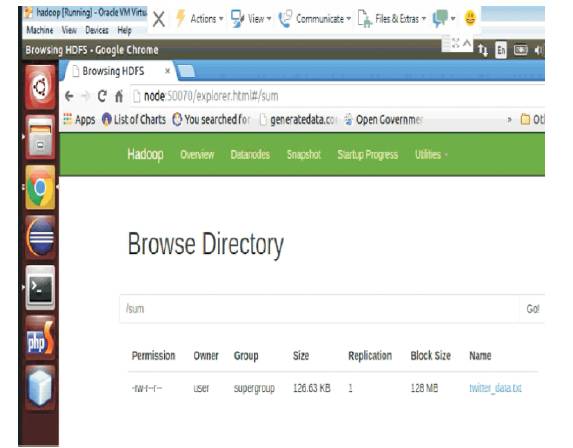
Figure 9. Display the Twitter-Data.txt
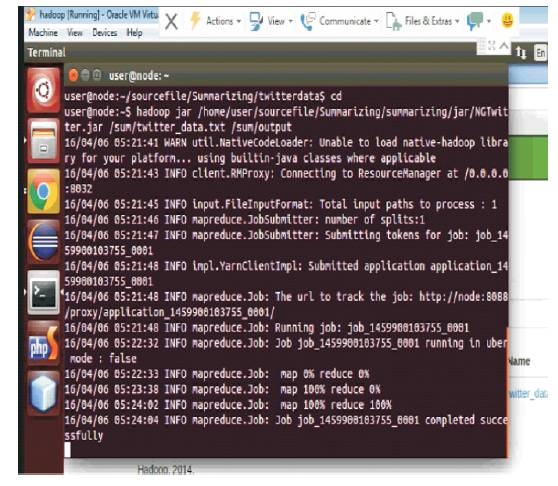
Figure 10. Working of MapReduce Concept to Summarizing the Data
In MapReduce, initially assign the job to the Map Function, i.e., insert the twitter data files in bytes. There are three conditions.
1. Map 0% and reduce 0%.
2. Map 100% and reduce 0%.
3. Map 100% and reduce 100%.
If both the function map() and reduce() are 100%, then the task is successfully completed and it shows all the summarized data with the consisting algorithms.
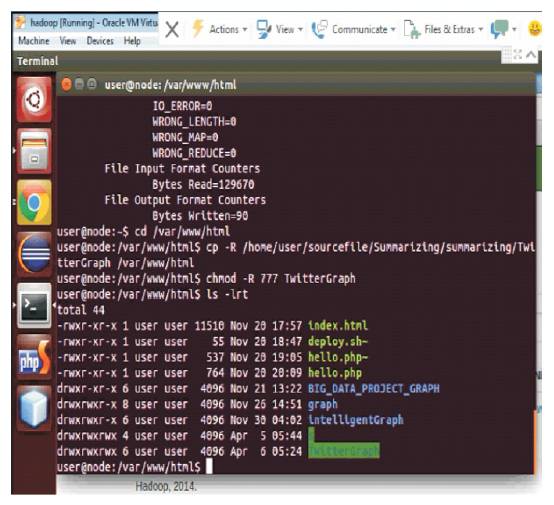
Figure 11. Output by using the MapReduce Task
Figure 12. Twitter Analysation
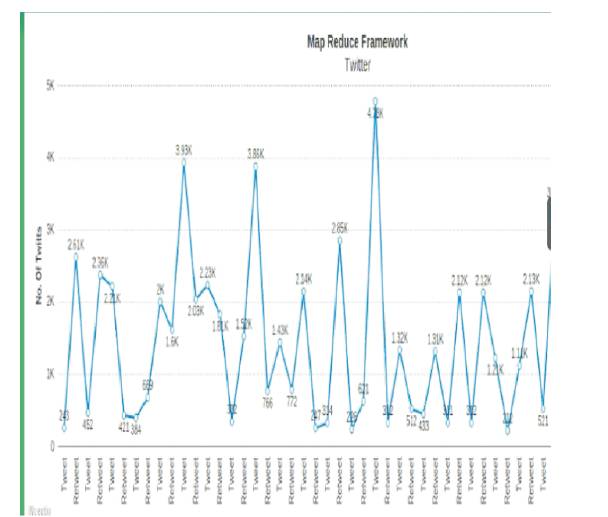
Figure 13. Result in Line Graph
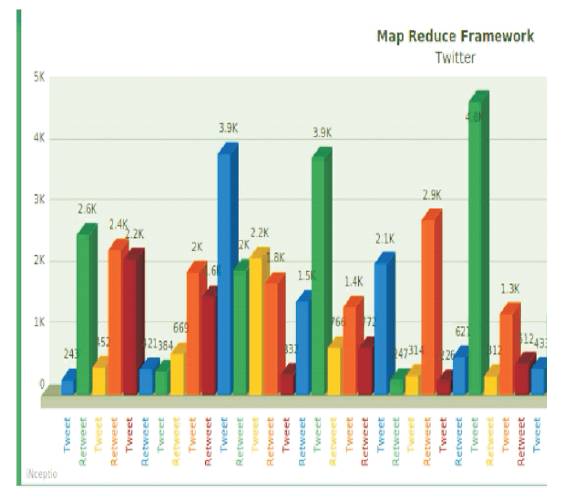
Figure 14. Result in Bar Graph
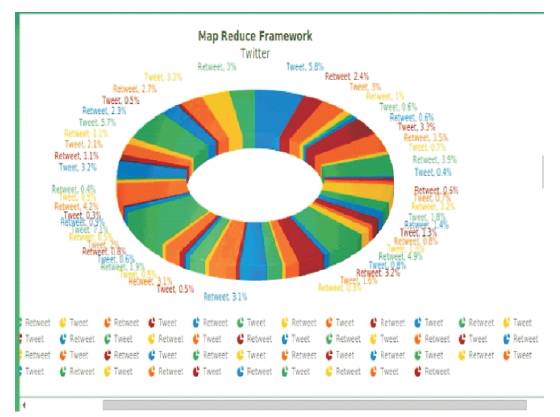
Figure 15. Result in Pie Graph
In this work, the authors have presented a multi-document text summarizer based on MapReduce framework. Experiments are approved using four nodes in the MapReduce framework for a large text collection and summarization in the form of Line Bar, and Pie graphs are evaluated for a large text collection. It is also shown experimentally that the MapReduce framework provides improved scalability and summary time complexity, while considering a large number of text documents for summarization. The result of data semantic clustering has showed good accuracy and calculation efficiency. The authors have studied four most widely used multidocument summarization systems and presented a weighted consensus summarization method to combine the results from single summarization systems. Three possible cases of summarizing the multiple documents of the large data are also studied relatively. While considering the large number of text documents of the data for summarization, MapReduce is an essential part and it gives the reliable output and performance reduce, MapReduce framework gives better results, scalability and reduces the time complexity. Future work is to support for multi-lingual text summarization by using the MapReduce concept in order to provide the summary from the text documents of the large data in different languages.

