Multicore platforms allow developers to optimize applications by intelligent partitioning at different workloads on different processor cores. Currently, application programs are optimized to use multiple processor resources, resulting in faster application performance. The authors earlier research work focused on native thread for Java on windows thread, Pthread, and Intel TBB. The authors also developed Native Threads, Native Pthread, Java Native Intel TBB beneath windows 32-bit platform. This article aims to identify the future directions of native thread for Java on windows thread, Pthread, and Intel TBB through JNI beneath windows 64-bit platforms and other platform besides. Furthermore, it articulates additional opening to pursue approaching developments on parallel programming models through Java.
Parallel computers can be approximately categorized according to the level at which the hardware supports parallelism. Through multicore and multiprocessor computers having many processing elements within a particular machine, clusters, Massively Parallel Processing (MPP) and Grids use multiple computers to work on the similar tasks.
A multicore processor [1] comprises multiple execution units (cores) on the same chip. Each core in a multicore processor can possibly be superscalar as well as on each cycle, each core can perform multiple instructions from one instruction stream. Simultaneous Multi Threading (SMT) was an initial form of pseudo multicoreism. A processor capable of SMT has only one core, but when that execution unit is idling, it uses that execution unit to process a second thread.
A SMP [2] is a computer system with multiple identical processors that share memory and associate via a bus. The bus argument prevents bus architectures from scaling, which do not include more than 32 processors.
A distributed computer [3] is a distributed memory computer system in which the processing elements are connected by a network. Distributed computers are extremely scalable.
Clusters [3] are a collection of multiple stand alone computers connected by a network. Though the computers in a cluster do not have to be symmetric, load balancing is more problematic if they are not. The most collective type of cluster is the Beowulf cluster, is a cluster applied on multiple identical commercial standard computers connected with a TCP/IP Ethernet Local Area Network.
It is a single computer with many networked processors. MPPs [4] have numerous of the same features as clusters, but MPPs have particular interconnect networks. MPPs also tend to be larger than clusters, normally having more than 100 processors.
Grid computing [3,4] is the most distributed forms of parallel computing. It makes use of computers connecting over the Internet to work on a given problem. Grid computing applications use middleware software that connects between the operating system and the application to manage network resources and standardize the software interface.
Reconfigurable computing is the use of an FPGA [4] as a co-processor to a general-purpose computer. The FPGA is in essence a computer chip that can rewire itself for a given task.
GPUs [1,4] are coprocessors have been deeply enhanced for computer graphics processing. Computer graphics processing is a field dominated by data parallel operations mostly on linear algebra matrix operations. Programming languages and platforms have been made to do general purpose computation on GPUs with both NVIDIA and Advanced Micro Devices (AMD) releasing programming environments with CUDA and Stream SDK respectively. The consortium Khronos Group released the OpenCL specification, it is a framework for writing programs that executes across platforms consisting of CPUs and GPUs, AMD, Apple, Intel, NVIDIA.
The aimed research work were identified and developed for the parallel programming model implementations through Java. The research work provided a prototype model to produce any other language threading features to the Java language. The research works done are summarized as follows.
The parallel programming model developed and examined with the framework model and its organization is shown in Figure 1. The encircled dotted portion of the framework shows the overview of the carried out research work. Parallel programs can be utilized on CPU, GPU, Distributed, Cluster, Grid, MPP and FPGA. The framework which the authors implemented is suitable to the multicore CPU platform for both task parallelism and data parallelism.
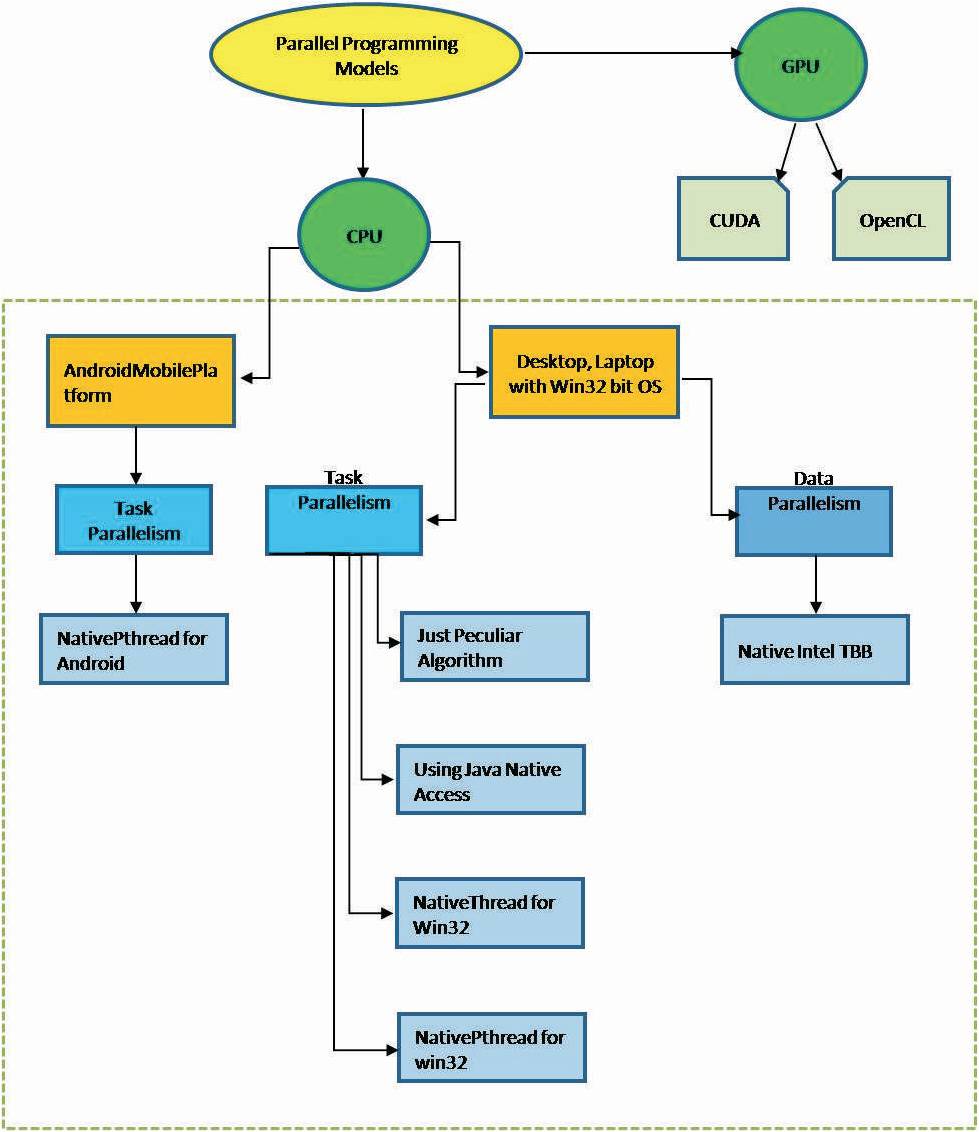
Figure 1. Framework for Parallel Programming Model
Multicore platforms allow developers to enhanced applications by intelligent partitioning of the dissimilar workloads on dissimilar processor cores. Application code can be improved to use multiple processor resources resulting in faster application performance. Successive multi-threaded applications on multicore platforms have dissimilar design thoughts than performing successive multi-threaded applications on single-core platforms.
The authors provided task parallelism on a desktop or laptop computer through Just Peculiar Algorithm, Java Native Access, Win32 thread and Pthread. Just Peculiar Algorithm has been used to set affinity for thread in multicore processor's environment.
Java Native Access mainly provided all the operating system related functionalities in which, they only use to create and set the affinity for thread in multicore processors. The task parallelism [7,8,13] on Win32 thread, POSIX thread were developed using JNI, which enabled to the usage of extra features like setting affinity for thread to schedule the task parallelism on different multicore processors.
The data parallelism on native Intel TBB threads [9] is developed using JNI, which enabled to support data parallelism on different multicore processors. In native TBB, the authors have used parallel_for template, which allowed to perform addition, subtraction, multiplication and division operations. The native Intel TBB can also be extended in the future to use another template available in Intel TBB such as, parallel_scan, parallel_do, parallel_for_each, parallel_pipeline, parallel_sort and parallel_invoke.
The authors provided task parallelism on Android platform [11], which are developed using Android NDK. Android NDK provides a platform for specific structures and trusts on JNI expertise to stick the native code to the Android applications. They also deliberated, how android applications can facilitate in setting affinity using Pthread through Android NDK that can make Pthread to execute task parallelism in hybrid mode with Java threads.
Programming on GPU [12] is supported through SIMD architectures. General Purpose GPU (GPGPU) computing has allowed the GPU to arise as successful co-processors that can be employed to improve the presentation of many dissimilar non- graphical applications. CUDA and OpenCL offer two different interfaces for programming GPUs. Java can facilitate for General Purpose GPU Computing. The authors identified the contrast between CUDA and OpenCL to help the HPC programmers to familiarize with GPGPU. The jcuda and jocl are the native libraries available for Java to perform data parallelism on GPU. However the jcuda or jocl libraries are not up to the present version available for CUDA or OpenCL, since there is a large opening on improving the data parallel library on GPU for Java language.
There are determined tasks, that promotes the research. They are listed below.
The research work has been identified and developed a parallel programming model through the Java Native Interface. It provided a prototype model to incorporate the features of another language to the Java language.
Java Native Interface (JNI) is a robust aspect of the Java. JNI designate a method for controlling the program written in the Java programming language to jointly make effort with the native program that is written in C/C++. JNI permits accurate methods of Java classes to be applied natively and are still be entitled and used as normal Java methods. The Native Thread is scheduled by the operating system that is hosted in the virtual machine. There were challenges in the model implementations, which are listed below.
The parallel programming model has been developed for both task and data parallelism on Desktops, Laptops and Android mobile devices. The task parallelism are carried out using Just Peculiar Algorithm (JPA), Java Native Access (JNA), Native Thread for win32, Native PThread for win32 and Native PThread for Android, whereas the parallel programming model developed for the data parallelism on multicore processor uses Native Intel TBB. The data parallelism model of GPU is GPGPU computing. Most of the research works focus on native thread for Java on windows 32-bit platform. The listed future directions enable the researchers to enhance the developments of parallel programming models for Java on windows 64-bit. The researchers can attempt to implement boost threads, C++ 11 threads, and Intel Cilk Plus thread features for Java on windows 32 bit as well as on windows 64 bit platforms. It is not limited; the researchers have got opening to enhance other features.

