Handwritten Character Recognition is a crucial part of Optical Character Recognition (OCR) through which the computer understands the handwriting of individuals automatically from the image of a handwritten script. From a decade, OCR becomes the most important application of Pattern Recognition, Machine Vision and Signal Processing for the rapid growth of technology, which can be described as the Electronic or Mechanical conversion of the captured or scanned image. The image is converted into the machine encoded form that can be further used in machine translation, text to speech conversion, text mining and the storage of data. Selections of appropriate feature extraction and classification methods are the crucial factors for achieving a higher rate of recognition with greater level of accuracy for handwritten characters to accurately achieve recognition of each and every letter. Here, in this paper the authors attempt to give a more elaborative image for a comprehensive review that has been proposed to achieve a deep study of the handwritten characters recognition, and this data will be useful for the readers working in the field of handwritten character recognition.
The field of pattern recognition and machine learning has become one of the broad areas for the researchers. The goal of researchers is to find out the algorithms that can solve on the problems of handwritten character recognition, to the incorporate human functions of character recognition to the computers [42]. As the handwritten character recognition is the subfield of the OCR, basically the purpose of OCR is to convert an image of typewritten or printed, and handwritten text into the understandable form so that the computer can be easily able to recognize the text patterns. Consequently, the OCR system can be applied in various domains with several applications such as: bank check processing, digital libraries, mail sorting, postal code recognition, security system, and various document indexing systems [6]. However, handwritten character recognition system development is a nontrivial task because a word can be depicted in many styles, this is because each and every person has their own way of writing or representing something that can be dissimilar to others like there are many fonts to represent the same thing, and there are many styles like bold, italic, underlined, etc. with different complex layouts. Depending on the type (manual script or printed) of writing that a system should recognize, operations to be performed and the outcomes can vary depending on the type (manual script or printed) of the writing. In this paper, the objective is to cover the handwriting character recognition system, for the captured/scanned images [34]. And also the authors are covering a concise survey of the available handwritten characters recognition Methodologies, different types of feature extraction methods and different types of classifiers that are being used to classify the characters [4] .
Initially, the idea of retina scanner came up with the invention of retina scanner, which is basically an image transmission system uses a mosaic of photocells in order to recognize [11]. By the invention of Nipkow's sequential scanner, the technology of today's reading machines and television was introduced in 1890. The OCR was basically examined to provide help to the blind people, but nowadays, the OCR is the vast field for researchers to give their opinions for the growth of development in Technology.
In the patent filing of Tauschek in Germany, 1929, the first evidence of optical character recognition system is available [13]. After this, in 1935, he was given the US Patent and the Handel was given independently in 1933. [39] .
The present commercial OCRs can be classified into four generations according to their robustness, efficiency and versatility. The first generation of OCRs was employed in 1960, in which the reading of selected fonts and shapes of characters can be done. IBM 1418 was the first generation commercial OCR [36], in which the method of logical template matching was there. The second generations OCRs was able to recognize the characters, printed by machine and handwritten as well. This generation OCRs were more powerful than the first generation's OCRs. IBM 1287, was the first OCR of the second generation that was the fusion of analog and digital technology [50]. In the field of character recognition, many researchers has provided their opinions and proved with their results, some of them are as follows (Table 1):
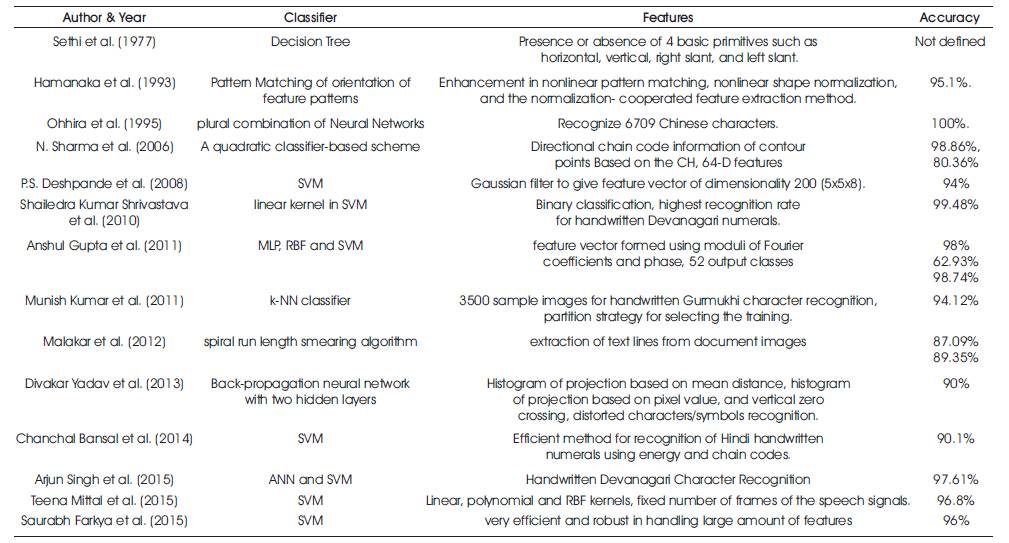
Table 1. Literature Review
Sethi and Chatterjee (1976) carried out Devanagari numeral recognition with the help of the presence or absence of the vertical, horizontal, right slant, left slant Based primitives. Recognition was performed. The main method used was the decision tree. After this, they have attempted to recognize constraint hand printed Devanagari characters using the same method [56] .
Sinha and Mahabala (1979) performed Devanagari script recognition using syntactic method with an embedded picture language. It is a prototype context based recognition [58].
Hamanaka et al. (1993), suggested an offline character recognition method that can also be operative in the online Japanese characters recognition. The traditional method that was used previously was confined to the number of strokes and their orders. The offline character recognition procedure removes these constraints on the basis of pattern matching or the orientation of featured patterns. With the increment in various feature extraction methods like: nonlinear shape normalization, nonlinear pattern matching and normalized cooperation, the recognition of characters can be improved. The rate of accuracy attained was 95.1% [25].
Ohhira et al. (1995), suggested that for automatically recognition of 6709 Chinese characters, plural combination of neural networks can be used. The plural combination of neural network basically contains four parts as: rough classification part, recognition part, fine classification part, and auto judgment part. The input data are classified by method of the characters density at rough and fine classification part. The multi-layered NN is used to recognize the characters at the recognition part of characters recognition and the auto judgment part judges and provide output for the values. The method attained an accuracy efficiency of 100% [38].
N. Sharma et al. (2006) used information of the contour points of the characters in order to achieve the handwritten Devanagari characters recognition. Based on 64-D, features for recognition of characters was demonstrated. They suggested the scheme on the basis of quadratic classifier in order to recognize of handwritten characters and the achieved accuracy was 98.86% and with the 11270 data set size, they attained a 80.36% recognition accuracy [33].
P. S Deshpande et al. (2007) proposed a Gaussian filter to provide a feature vector for the dimension of 200 (5x5x8), and the accuracy achieved was 94% with Support Vector Machines (SVM) as the classifier [40].
S. Arora et al. (2010) proposed a system for recognizing the offline handwritten Devanagri numerals using SVM and ANN classifiers. Here, in this classification step, the recognition takes place under two stages. In the first stage, the numerals are classified using MLP and then the unrecognized characters are fed to the second stage to be classified by SVM. The proposed method was tested on 18300 data samples and achieved 93.15 % accuracy of recognition [55].
Shailedra Kumar Shrivastava and Sanjay Gharde (2010) implemented the Binary classification approach of the Support Vector Machine and the linear kernel function is applied in SVM This linear SVM produces 99.48% overall recognition rate, which is the highest among all of the methods applied on the handwritten Devanagari numeral recognition system [51].
Brijmohan Singh et al. (2011) proposed two different methods for extracting features from the handwritten Devnagari characters, the Curvelet Transform, the Character Geometry, and the large dimensional features space which is handled by PCA and their recognition performances using two different classifiers were compared. Those are: the the k-Nearest Neighbour (k-NN) and Support Vector Machine (SVM) with Radial Basis Function (RBF) classifier. Different classification accuracy measures, such as False Positive (FP) Rate, True Positive (TP) Rate, Recall and F-Measure, and Precision, are used for the purpose. Gained Results show that the Curvelet that features with k-NN classifier executes the best, yielding accuracy as high as 93.21% [7].
Anshul Gupta et al. (2011) suggested feature vectors, which are generated with the use of moduli of fourier coefficients and the phase produces an accuracy of 98.74% by using the SVM classifier for the training of datasets for their final procedure, and three combination of fourier descriptors was used in parallel. In their character recognition network, there was 52 output classes. For upper and lower case characters, separate classifiers was used, and they have also tested the MLP and RBF neural networks to recognize the characters and on the same features, they tried SVM classifier and got 62.93% of accuracy on test data and finally chosen the SVM because it is better than MLP and RBF [5].
Munish Kumar et al. (2011) have conducted research based on k-NN classifier using diagonal features for offline handwritten recognition of the Gurumukhi character and used the samples of the offline handwritten Gurumukhi characters from 100 different writers. In their proposed work, the partitioning strategy has been tested and 3500 sample images of Gurumukhi characters were used to achieve training and testing. The overall accuracy attained was 94.12% using diagonal features and k-NN classifier [27].
Mohammad Abu Obaida et al. (2011) suggested a method that consisted of : i) Before performing the character recognition process, the classification of words to a language has been done, ii) For the separation of vertical connected text lines, an improved statistical methodology has been applied, iii) To recognize interword and intra-word distances and to judge vertical projection, hybrid word segmentation method was adopted. This method was tested on 173 handwritten documents. 91% accuracy was achieved while processing a large sized document and the time consumed was high than processing a single bit [32] .
Malakar et al. (2012) proposed that the extraction of text lines using spiral run length smearing algorithm from the document images is the most essential step of an OCR system. In the handwritten document images skew, touching and overlapping of text lines makes the recognition process a real obstacle. The method was able to extract 87.07 % and 89.35% text lines successfully from the desired database [29].
Divakar Yadav et al. (2013) have proposed that in order to improve the recognition rate, the histogram of project on the basis of mean distance, histogram projection crossing based on pixel value, and vertical zero can be used. These features extraction methodologies are also powerful to extract the feature of distorted characters symbols. For the classification purpose, a Back Propagation Neural Network with two hidden layer is used. 90% correct recognition rate of performance is attained for printed Hindi texts, and the classifier is trained and tested for the above data [12].
Gaurav Y. Tawde et al. (2014) Obtained the recognition accuracy by their proposed method of about 60% to 70%. According to them, wavelet decomposition allows observing the image at hierarchical resolution levels [13].
Chanchal Bansal and Arif Khan, (2014) proposed an efficient method for recognition of Hindi handwritten numerals, with the use of energy and chain codes. For classification purpose, the SVM is used for classification. The average recognition of 90.1% is achieved using four segment methods [8].
Rekha Singh, (2014) proposed and implemented a Feed Forward Back Propagation Network for character recognition system. Using this method, the improvement in performance of the feed forward back propagation network is achieved and the result attained was above 80% for the handwritten sample data for the untrained sets [43].
Arjun Singh and Kansham (2015) got 97.61% result using SVM and ANN for the Handwritten Devanagari Character recognition. The accuracy/recognition rate has been obtained for different size of the images by ANN and SVM classifiers [4].
Teena Mittal and Rajendra kumar (2015) implemented SVM for recognizing the linear, polynomial and RBF kernels that have been used. In the first phase, for the fixed number of frames of the speech signal, the best strategy was found. The recognition rate was highest using the linear kernel strategy. Next, in order to know LPCs and MFCs, the number of frames was diverse and the highest accuracy achieved was 96.8% [61].
Saurabh Farkya et al. (2015) described in their paper that when a whole document was scanned and passed to OCR, the rate of recognition slightly decreases to 96%. This happens mainly due to the overlapping of characters. According to them, the surveys on Support Vector Machines found to be extremely efficient and robust in handling large amount of features, as SVM was used for the purpose of classification [57].
Handwritten Character Recognition is a field of Pattern matching for recognizing characters. The objective of handwritten character recognition system is to build an intelligent system that will allow successful extraction of characters from the handwritten documents, to digitalize and translate the handwritten texts into machine readable texts. Variations in handwriting style, which are completely different from different writers, especially for mixed languages is still a complex task in the area of handwritten character recognition [31]. Figure 1 Shows the block diagram for Handwritten Character Recognition.
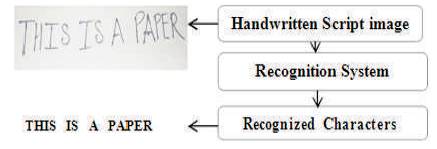
Figure 1. Handwritten character recognition
According to the working procedure of handwritten characters recognition system, there are two broad categories [34]:
Under this variety of handwritten character recognition, the characters that are in creation or when the user is writing, the recognition is achieved by the device. The hardware device used to recognize data is a digitizer tablet or PDA which is electromagnetic, touch sensitive or pressure sensitive. Successive movements of the pen are transformed on the device to a series of electronic signals, when a user forms some pattern of characters on the tablet. The obtained signals are then converted to letter codes by the transducer, which are operative within the computer and the text-processing applications for further processing.
This variety of handwritten character recognition requires handwritten documents before performing the task of recognition. After which the document is scanned or captured, stored in the computer and then further processing for recognition is performed on that image [28]. It is more difficult to recognize the offline handwritten characters, because different people have different handwriting styles [26].
In professional or nonprofessional environments like libraries, homes, offices, publishing houses, etc. thousands of documents and books are scanned on regular basis for backup and storage purposes [43]. A scanner or capturing device generally takes photograph of the original paper documents and provides the imagebased scanned or captured documents as the output [8]. As the document contains one big image file, rather than the individual text characters, the major concern with processing and storing these kinds of large volumes of scanned or captured documents have inabilities to search for a specific name or phrase inside that file and the text cannot be highlighted, copied, or modified [6] . A large amount of time can also be saved through this process, since manual interface and human errors do not come into the play directly.
The working of Handwritten Character Recognition is directly proportional to the method of recognition adopted generally. Handwritten Character Recognition consists of the following stages as given in Figure 2. The output of each stage is used as the input to the next stage [34] .
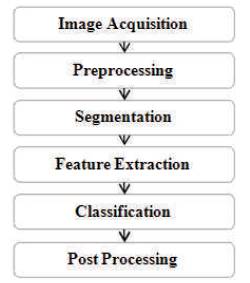
Figure 2. Stages of Handwritten Character Recognition System
In this phase, the image is taken through a camera or a scanner as an input. The input captured may be in the from of gray level image, color image or Binary image from the scanner or digital camera.
Preprocessing involves several operations over the scanned or captured image, and so the further processing on the input image becomes suitable and comfortable for applying. Basically, the objective of preprocessing is to improve the quality of the scanned or captured input images [55]. Some of the preprocessing methods are: Gray Scale Conversion of colored image, Noise Removal, Binarization, Skew and slant detection or correction [25].
Noise may be introduced due to any writing mistakes or disturbances during writing on a document. Sometimes, when images are scanned or captured, some scanning and capturing devices also introduce noises like bumps and gaps in line of characters, filled loops, and disconnected lines. Removing the noise is necessary for Reorganization purposes [27]. The noise can affect the image depending on the type of disturbances, to a different extent. Noise reduction techniques can be categorized in three major groups as filtering, morphological operations and Noise Modeling [53] .
The basic aim of this operation is to remove noise and diminish spurious points, which are introduced by poor sampling rate of the data acquisition device or by an uneven writing surface. Various spatial and frequency domain filters can be designed for this purpose. Filters can be designed for removing the colored background or slightly textured [35], contrast adjustments [31], and smoothing & sharpening [34], and thresholding [5] purposes from an image.
The morphological operations basically aimed to filter the document image to replace the convolution operations by the logical operations. To decompose the connected strokes [18], connect the broken strokes [6], thin the characters, smooth the contours, prune the wild points, and extract the boundaries [34], and thus various morphological operations can be designed. Therefore, the morphological operations can be successfully used to remove the noise on the document images due to erratic hand movements, as well as the low quality of paper and ink.
Some calibration techniques are applied to remove the noise, if a model for this were available. However, modeling of the noise is not possible in most of the applications. Till now, only few works have been done on modeling the noise, that is introduced by optical distortion, such as blur, [34] speckle, and skew. Nevertheless, it is possible to remove the noise to a certain degree, and assess the quality of the documents as suggested in [64].
Normalization is an important phase of handwritten character recognition, Where it allows converting an image with an arbitrary size to a fixe sized image. It is generally used to reduce or eliminate the variability related to the difference in sizes and styles as much as possible [28].
Binarization is performed on an image before the character recognition phase. Ideally, an input character to the recognition phase should have two tones i.e., black and white pixels (represented by 1 and 0, respectively) [35]. In image binarization, an image of up to 256 gray levels can be converted into a two toned image. The goal of this binarization step is to identify a threshold value dynamically that would help to distinguish between the image pixels, those that belong to the background and that belong to the text. The threshold value identified would be completely dependent on the nature, the contrast level, the properties of the documents, the difference of contrast between the foreground and background pixels and their concentration in the document [28]. There are various methods for binarization techniques available in image processing, out of which many researchers have found Otsu's technique to be adequate for thresholding the handwritten characters [5].
Skew and Slant are two different important terms related to the handwritten characters. In any handwritten character recognition system, the main aim is to find out the accurate result. Skew detection/correction and Slant detection/correction are important perspectives relating to correction of the handwritten image. The amount of skew and slant in an document may depend on different factors like writing surface and material, psychological, physical state of a person and environmental factors [2].
While the scanning or capturing process of writing styles, some inaccuracies may occur, the writing may be slightly curved or tilted within the image. This can hurt the effectiveness of later phases and, therefore, skew within an image should be detected and corrected. Methods of baseline extraction for skew detection include, using the projection profile of the image, a form of nearest neighbors clustering, cross correlation method between the lines [22], and using the Hough transform. Out of them in terms of speed, the nearest neighbor method achieves the fastest method, and based on accuracy, the projection profile gives the best angle estimation accurately. After skew detection, the character or word is translated to the origin, stretched, or rotated until the baseline is horizontal and retranslated back into the display screen space.
One of the important measurable factors of different handwriting styles is the slant angle between the longest stroke in a word and the vertical direction of the word. Slant detection is used to normalize all the characters to a standard form [33]. The most common method for slant estimation in a document is the calculation of the average angle of the near vertical elements. The start and end point coordinates of each line element provides the slant angle. Slant correction is the process which tries to normalize the slant of the characters in a line or paragraph to the vertical.
The aim of segmentation stage is to decompose an image into sub-images of individual characters. In more complex cases of handwritten text, the segmentation becomes much more difficult to process as the letters tend to be, overlapped or distorted, and connected to each other [28]. Segmentation is done to break the single text line to single word and single character from the input documents. For isolated characters, numerals and symbols, segmentation task is not that difficult. However, more advanced techniques required to be employed for joint and complex strings. Segmentation is one important step in layout analysis and it is particularly difficult when dealing with complex layouts [34]. Layout analysis is accomplished in two stages: structural analysis is the first stage, which is concerned with segmentation of the image into blocks of document components (paragraph, row, word, etc.). Functional analysis is second one, in which, the size, location and various layout rules to describe the functional content of document components are considered. After this, by finding the textured regions in gray scale or color images, Page segmentation is implemented [31].
Feature extraction is an important methodology of Handwritten character recognition to find out the characteristics of the handwritten patterns [64]. With feature extraction, further classification for characters, recognition process can be done efficiently and effectively. A good survey for the available feature extraction methods for character recognition in presented in [1].
Feature extraction methods for documents image is categorized under three major groups.
Generally, a continuous signal contains more information that needs to be represented for the purpose of classification. By a linear combination of a series of simpler well-defined functions, a signal can be represented for discrete approximations of continuous signals, which may be true. For feature extraction, a compact encoding known as series expansion, and transformation, is provided by the coefficients of the linear combination. Under global transformation and series expansion, invariants are Deformations like translation and rotations. The following are the methods used in common transform and the series expansion for handwritten characters recognition field [35] [64].
The ability to recognize the position-shifted characters, when it observes the magnitude spectrum and ignores the phase, and the general procedure is to choose magnitude spectrum of the measurement vector as the features in an n-dimensional Euclidean space is one of the most attractive properties of the Fourier transform [44] [68].
This is one of the variant of the windowed Fourier transform method. Generally, in this terminology, the window used for transformation is not a discrete size but defined by the Gaussian function [34].
It is a series expansion technique, which allow the users to represent the signal at different levels of resolutions. The segments of document image are represented by wavelet coefficients, which may correspond to letters or words for various levels of resolution. After this, these coefficients are then fed to a classifier for recognition purpose [72]. The local difference in handwriting as opposed to MRA with high resolution can be consumed by the representation in Multi Resolution Analysis (MRA) with low resolution. However, the important details for the recognition stage would be lost by the representation in low resolution.
Various moments like central moments, Legendre moments, and Zernike moments form a compact representation of the original image of the document that make the process of recognizing an object scale, invariant, rotation and translation [70], [66]. In this type of feature extraction, the original image can be completely reconstructed from the moment coefficients, so the moments are considered as a series expansion representation.
Basically, this is an eigenvector analysis, which tries to reduce the dimension of the feature set by creating new features that are the linear composition of the genuine ones. In terms of information compression, Karhunen–Loeve expansion is the only ideal transformation. It is used in various pattern recognition problems such as, face recognition. At National Institute of Standards and Technology (NIST), it is also used in OCR system for form-based handprint recognition [23]. The use of Karhunen–Loeve features in CR problems is not widespread, because it requires computationally complex algorithms. However, by the increase of the computational power, it will become a realistic feature for CR systems in the next few years [71].
For Statistical Representation, Statistical distributions of the point, takes care of style variations to some extent for the representation of a document image [63]. It is used for reducing the dimension of the feature set providing high speed and low complexity, although this type of representation does not allow the reconstruction of the original image [39].
For character representation, the following are the major statistical features used:
In this method, the frame containing the character is divided into various overlapping or non-overlapping zones of smaller fragments of areas. Some features in different regions or the densities of the points are analyzed and form the representation. For example, the bending point features, represent high curvature points, terminal points, and fork points [63]. Another example is contour direction features, that measure the direction of the contour of the character [21], which is generated by dividing the image array into rectangular and diagonal zones and computing the histograms of chain codes in these zones.
A widespread statistical feature is the line segment in a specified direction, for calculating number of crossings of a contour [37]. In this, the character frame is partitioned into a set of regions in various directions and after this, by the powers of two, the black runs in each region are coded. Another study encodes number of transitions and the location from background to foreground pixels along with vertical lines throughout the word [22]. The statistical features used are the distance of line segments from a given boundary, such as the lower and upper portion of the frame [37]. These features imply that, a horizontal threshold is established, below, above and through the center of the normalized script. The number of times a threshold is crossed by the script, it becomes the value for that feature. The main motive is to catch the ascending and descending portions of the script.
By projecting the pixel gray values onto lines in various directions, Characters can be represented. This representation creates a one-dimensional signal from a two-dimensional image, which can be further used to represent the image of characters [69], [21].
In this technique, it is assumed that all the characters are oriented vertically. In this, each characters are divide into four equal quadrants, the scanning and calculation of zero to one transition of each division is taken place in both the vertical and horizontal directions [63] .
Various local and global properties of characters can be represented by geometrical and topological features with style variations and high tolerance to distortions.
Various categories under which the topological and geometrical representations can be grouped are:
A predefined structure is searched in a character or word in this group of representation. A descriptive representation forms the number or relative position of these structures within the character. Common primitive structures in this are the strokes, which make up a character. These primitives can be as simple as arcs (c) and lines (l), which are the main strokes of Latin characters and can be as complex as the curves and splines making up Chinese or Arabic characters. In online CR, a stroke is also defined by the line segments from pen-down to penup [9]. Successful representation of Characters and words can be done by extracting and counting the topological features such as, the maxima and minima, extreme points, openings to the right, cusps above and below a threshold, left, up, and down, loops, cross (x) points, branch (T) points, line ends (J), inflection between two points, isolated dots, a bend between two points, direction of a stroke from a special point, symmetry of character, straight strokes between two points, ascending, descending, horizontal curves at top or bottom, middle strokes and relations among the stroke that make up a character, etc. [73], [46], [45].
In many studies (e.g., [62] and [1]), by the measurement of the geometrical quantities like the ratio between height and width of the bounding box of a character, the characters can be represented. The relative distance between the last point and the last y-min, the relative vertical and horizontal distance between first and last points, distance between two points, comparative lengths between the two strokes, width of a stroke, and word length, upper and lower masses of words were analyzed. The change in the curvature or curvature is a very important characteristic measure [36]. Among many methods for measuring the curvature information [15] , one is suggested to measure the local stroke direction, for measuring distribution of the directional decomposition to the directional distance of the character image. By a more convenient and compact geometrical set of features, the measured geometrical quantities can be approximated. A class of methods includes polygonal approximation of a thinned character [16]. Cubic spline representation is a more precise and expensive version of the polygonal approximation [22].
In this, one of the most widespread coding scheme is Freeman's chain code. This coding is essentially obtained by mapping the strokes of a character into a two dimensional parameter space, which is made up of codes. There are various versions of chain coding. As an example, in [74], the character frame is divided to left–right sliding window and each region is coded by the chain code.
Characters or words are first partitioned into a set of topological primitives, such as strokes, cross points, loops, etc. Then, these primitives are further represented using attributed or relational graphs [67]. There are two types of image representation by graphs ,the first one uses the coordinates of the character shape [14]. The second type is an abstract representation with nodes corresponding to the strokes and edges, and relationship between the strokes [65]. Trees can also be used to represent the words or characters with a set of features, which have a hierarchical relation [47] [48] . In [17], from the raw data, feature extraction and selection is defined as extracting the most representative information, which minimizes the class pattern variability while enhancing between the class pattern variability. For selecting the k-best features out of N features, feature selection can be formulated as a dynamic programming problem as for a cost function like Fisher ’s discrimant ratio. By using principal component analysis or a NN trainer, feature selection can also be accomplished. In [29], the performance of different types of feature selection methods for characters recognition are explored and compared. Selection of features using a methodology as mentioned here most of the time supplies a suboptimal solution [42], and requires expensive computational power. Therefore, the feature selection is, mostly, done by intuition or by heuristics for a specific type of the CR application.
Handwritten character recognition system broadly uses the methodology of pattern recognition, which assigns an unknown sample to a predefined class. Several techniques for handwritten character recognition are investigated by the researchers [62], [34]. Classification techniques can be classified as follows.
The above approaches are not necessarily independent or disjoint from each other. Occasionally, a CR technique in one approach can also be considered to be a part of other approaches.
It is a easiest way of character recognition, based on matching the stored prototypes against the character or the word to be recognized. The degree of similarity between two vectors (group of pixels, shapes, curvature, etc.) is determined, by the matching operation. With a standard set of stored prototypes a gray-level or binary input character is compared, according to a similarity measure (e.g. Euclidean, Jaccard or Yule similarity measures, Mahalanobis, etc). A template matcher can unite multiple information sources, including match strength and k-nearest neighbor measurements from different metrics. Rate of recognition of this method is extremely sensitive to noise and image deformation. Deformable Templates and Elastic Matching are used for improved classification [18].
Statistical decision theory is focused on statistical decision functions and a set of optimality criteria, to maximize the probability of the considered patterns for given model for a certain class [41]. Basically statistical techniques depend on the following assumptions:
The measurements collected from n-features of all the words unit can be thought to represent the vector and n-dimensional vector space, whose coordinates correspond to the taken measurements, represent the original word unit. The various main statistical methods, applied in the OCR field are Nearest Neighbors (NN) [49], [61], Likelihood or Bayes classifier [2], Hidden Markov Modeling (HMM) [59], Clustering Analysis [37], Quadratic Classifier [33], and Fuzzy Set Reasoning.
Human beings can recognize characters in the documents by their learning and experience and the classification of characters problem is related to heuristic logic. Hence neural networks which are more or less heuristic in nature are highly suitable for this type of problem. Various types of neural networks are used for the handwritten character recognition classification. A computing architecture which consist the massively parallel interconnection of adaptive 'neural' processors is a neural network [20]. Compared to the classical techniques, it can perform computations at a higher rate because of its parallel nature. It can easily adapt changes in the data and learn the characteristics of input signal. Output from one node is supplied to another one and the final decision depends on the complex interaction of all nodes. Deferent type of approaches exist for training of neural networks viz. Boltzman, error correction, competitive learning, and Hebbian. They cover binary and continuous valued input, as well as supervised and unsupervised learning. Neural network architectures can be categorized as, feed-forward and feedback (recurrent) networks. The multilayer perceptron (MLP) of the feed forward networks is the most usual neural networks used in the character recognition systems and one of the interesting properties of MLP is that, in addition to classifying an input pattern, they also provide a confidence in the classification [3]. These confidence values may be used for rejecting a test pattern in case of doubt. MLP is applied by [49] [61]. A detailed comparison of various NN classifiers is made by M. Egmont-Petersen et al. [24]. They have shown that, Feed-forward, perceptron higher order network, Neuro-fuzzy system are better suited for character recognition. K. Y. Rajput and Sangeetha Mishra [19] used back propagation type NN classifier. In English, genetic algorithm based feature selection and classification along with combination of NN and Fuzzy logic has been reported [59], [56] .
It is a supervised type of classification method in the discipline of statistical learning theory, which has been successfully applied in the domains of bioinformatics and pattern recognition applications like text, face and voice recognition. In order to maximize the distance of the separating boundary between the two or more classes, SVM tries to maximize the distance of the separating planes from each of the feature vector whether the feature vector belongs to class c1,c2 and so on. In SVM, the optimization criteria is the width of the margin between the classes, i.e., empty area around the decision boundary specified by the distance to the nearest training pattern [3]. These patterns, called support vectors, finally describe a classification function. By maximizing the margin, their number is minimized. Many researchers applied SVM successfully viz., Arjun Singh and Kansham [4], C. V. Jawahar et al. [10], Sandhya Arora et al. [58], P. S Deshpande et al. [40] , Chanchal Bansal and Arif khan [8], Teena Mittal and Rajendra kumar [60], Saurabh Farkya et al. [57], Umapada Pal et al. [62] for characters recogiton .
All the classification methods have their own merit and demerits. To solve a given complex classification problem, multiple classifiers are combined together in order to provide better results. Different classifiers trained on the same data may not only vary in their global performances, but they also may show strong local differences. Every classifier may have its own zone, where it performs best in the feature space. Some classifiers such as, neural networks show different results with various initializations due to the randomness inherent in the training procedure. Instead of choosing the best network and discarding the others, one can unite various networks, thereby taking advantage of all the attempts to learn from the data [3].
Especially, if the individual classifiers are largely independent, a classifier combination is useful. Different types of resampling techniques such as, bootstrapping and rotation can be used to produce artificial variations, to increase and improve the rate of classification, if this is not already guaranteed by the use of different training sets earlier [3].
Combiners can be distinguished from others by the method of adapting, training and the need for the output of individual classifiers. Various combiners are used like sum (or average), voting, and the fixed type which does not require training while others are trainable. The trainable combiners provide better improvements in the system as compared to the non-trainable or static ones. On the basis of input patterns, some of the combination schemes are adaptive in the sense that the combiner can analyze (or weighs) the decisions for different types of classifiers. In contrast, all the input patterns are treated same by the non-adaptive combiners. Some combination classifiers that have been used in Indian scripts are ANN and HMM [61], K-Means and SVM [54], MLP and SVM [54], MLP and minimum edit, SVM and ANN, fuzzy neural network [36], NN, fuzzy logic and genetic algorithm [52]. Pawan Kumar [30] used five different classifiers (two HMM and three NN based) to obtain a better accuracy.
It is a step that has been performed after the scanning and recognition of the captured image of handwritten characters. While processing this step, there can be two types of errors.
This type of error is meaningful, but contains a nonrequired word for the particular sentence. Those type of errors are the complex ones and can disturb the overall syntax and semantic of the sentence. For the detection, human involvement is necessarily required because automatic correction of syntax and semantics for this type of errors can be a critical task for a program or machine. For example, when -what are you doing is recognized by the handwritten characters recognition system as -what are your doing , here-your is considered as a real word error because -your is correct but grammatically incorrect for this sentence [41].
This type of errors doesn't have any particular meaning in the sentence. There are many algorithms that have been proposed by the researchers for the detection and to provide suggestion words for the correction of the recognized contents. Algorithms like spell-checker are commonly used for this type of errors. For example, when - Are you happy is fed to the recognition by the handwritten character recognition system as, -Are you appy, here in this sentence -appy is the non-word error [36], [37].
In this paper, the authors have presented a detailed discussion about the handwritten character recognition, which contains various concepts that are being applied in this field. The rate of handwritten characters recognition accuracy basically depends on nature and shape of the handwritings of individuals. In this field, the current research is concentrated on recognition of cursive handwritings, multilingual mixed type handwritten characters and for the child written characters, for which high supervision is needed. From various research papers, the authors have found that the selection of appropriate feature extraction and classification methodologies personate a vital role for the performance and accuracy of the handwritten characters recognition.

