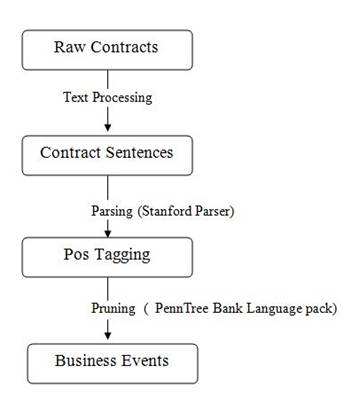
Figure 1. Overall Pipelining Process
The authors perform the investigation of the problem of business service, selection and categorization based on an expanded notion of reputation and trust. It is widely recognized now that the collaborative design of the significance of the services is the central principle of computing services. Specifically, the importance of understanding human behavior as a basis for service science is well-recognized, but is not necessarily reflected in the technical approaches. In particular, the quality of a service engagement depends on the mutual anticipations of the participants. In specific, the quality of experience that a customer derives from a service engagement would depend on how the customer potentials are refined and met by the provider during the service engagement. Indeed, this is well-known in marketing theory as the service quality GAPS model, as a basis of customer satisfaction. Here we propose a post mining process for mining business service contract agreements.
The quality of a service engagement would depend on the mutual anticipation of the participants. In specific, the quality of experience that a customer derives from a service engagement would depend on how the customer requirements are refined and how well they are met by the provider during the service engagement [5]. The authors postulate that incorporating expectations play a vital role in business service selection. We examine the notion of expectations from a computational viewpoint [3]. We claim that
Advanced Business service engagements are evolving progressively and more convoluted. We address service engagements in the broad sense. Therefore, we encompass not just traditional examples of service engagements, such as clientele connection management or business process outsourcing, but furthermore other business interactions, such as constructing and programs authorizing [4]. Because service engagements are specified via enterprise agreements, the expansion of the significance of service engagements in current business is seen in a multiple number of agreements [5,6].
The transparency of the business tendency reveals some new broad challenges in service computing [9]. The first dispute is how, during enactment, a contractual party can realize an agreement so as to work out its activities (and design its IT schemes) to support its participation in the service commitment. Specifically, would it be able to guide the development of its business processes and monitor its interactions? That is, would the party be adept to consign its part of a service commitment and determine what to anticipate from its partner in service engagements [2].
The second challenge is how, during negotiating a service engagement, a party can examine and draft agreements in a kind that incorporates the general practices of the relevant domain. The difficulty of identifying, taking up, and enacting a service commitment is exacerbated by the fact that contracts are conveyed in natural language. Farther, often the persons who discuss and those who apply a contract have distinct skill groups. Accordingly, we are choosing a study program that seeks to shatter the difficulty down into chunks that are amenable to computational investigation. In the second of the above trials, by mining a repository of contracts to work out the possible enterprise exceptions is recognized in different domains as addressed [1].
In this paper, we develop an approach that addresses both of the overhead trails. This approach is based on the idea of enterprise events which includes enterpriserelated activities and activities such as buy, consignment, account payment, bank interest accrual, licensing, and dispute tenacity. Enterprise events indicate the absolutely vital methods involved in a service commitment as well as the dangers and exceptions to address.
Figure 1 shows the flow of our approach as a hybrid of exterior pattern with linguistic parsing, and machine discovering methods. Agreement miner, first takes raw online contracts as input, eliminates disturbances such as HTML tags and segments the agreements into sentence collections. Second, it filters out sentences such as definitions and postal locations that obviously do not contain enterprise events. Third, it parses and prunes the residual sentences to develop nominee events. Fourth, it concerns appliance learning on localized and contextual characteristics to individually recognize factual events from the candidates. Fifth, it applies the theme modeling to extract hidden happening topics. The overall pipelining process is shown in Figure 1.
Figure 1. Overall Pipelining Process
The author divides this approach into two major tasks:
A typical service engagement agreement comprises components such as header, description, body. The vital part of an agreement are the clauses identifying mutual expectations conveyed as normative relations such as firm pledges, powers, authorizations, prohibitions, and sanctions of the participating parties. Normative relations express enterprise associations amidst the parties to a service engagement and these normative relations are constructed on top of enterprise events. In English syntax, these normative signs are often affiliated with modal verbs such as “shall,” “may,” and “must” [6]. We use modal verbs as hints to signify the incident of enterprise events. Signal phrases are broadly used in data extraction and serve as signs for pinpointing the context of the extraction.
On completing the primary cleanup activity, Algorithm 1 helps to identify the vital sentences of the agreement which comprise the hint expressions as event contender, parses every contender to stimulate the syntax tree, then prunes the syntax tree, and lastly builds an attribute vector for every contender by means of the attributes wheedle out of the syntax tree.

Algorithm 1. Business Events Extraction
By means of the Stanford Parser [7], we parse each event contender sentence to generate its syntax tree that links every token with a POS(parts-of-speech) tagging, as well as every phrase by means of a phrase label as of the Penn Treebank [8]. Algorithm 2 shows the syntax tree pruning.
We mine the topics of the business event sentence contender as well as then notice if such pinpointing terms emerge in the topic. Algorithm 3 illustrate our technique intended for wheeling out the topic as of an event contender sentence. In addition Algorithm 3 crumbles a compound event contender into various event contenders.

Algorithm 2. Syntax tree pruning

Algorithm 3. Subject extraction
In precise, we utilize the qualities from two sources local and logical. Local characteristics are taken from the sentence syntax tree of the event comment. Event subject and indicator statements are local characteristics and rely upon the event representation itself. Context oriented characteristics, for example proviso and counter condition indicates hinge on upon the heading or subordinating provisos. We utilize the Weka toolbox's [10] characterization bundles to distinguish the accurate occasions. In the wake of building the characteristic vectors for all the event hopefuls and clarifying them by hand, we apply different machine studying strategies. Past studies show that the Logistic Regression is adequate in comparative errand.
Exception Significance Evaluation and Classification is described in detail. Table 1 represents the notations used in ESE Approach. This process is done manually depending on the domain of the business and the business domain classes are indicated by the domain expert.
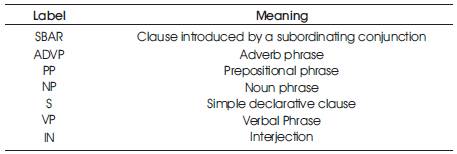
Table 1. Different phrasal chunks
Class Descriptor: The domain expert classifies the attributes involved in business rules into different categories. The process of classification is as follows:
Note: All related classes of a sub class also related to its parent class.
An xml based attribute class descriptor will be prepared. Figure 2 shows an example descriptor. Notation description equation can be found in Table 2.

Table 2. Notations used in Exception Significance Evaluation Approach

ESEC Algorithm
No of attribute properties are matched to number of class properties to which that attribute belongs to [Table 1 row: 8].
Indicates the ratio of properties matched to class level properties [Table 1 row: 9].
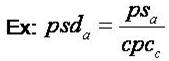
; here a is an attribute of class c [a∈c]
Indicates the strength of the relation between two attributes of an itemset that are considered as pair for equation [see Table 1 row: 11, 13].
Total number of two attributes sets; here these attribute sets must be unique [see Table 1, row 17, 18]
It is an itemset level measurement representing average relation strength of the attributes that belong to an itemset [see Table 1 row: 24]
It is a rule level measurement and concludes the relation strength between left hand side itemset and right hand side itemset of a given rule [see Table 1 row: 29]
This segment focuses mainly on extracting business events from enterprise agreements and providing evidence on asserting that the proposed post mining approach is competent enough to momentously classify service events of the business contracts. There is the involvement of an enhanced occurrence and a probability reduction in the memory exploitation rate with the aid of the trait equivalent prognosis and also rim snipping of the Service Exception Extraction with SESEC. This is on the basis of the surveillance done which concludes that SESEC implementation is far more noteworthy and important in regard to categorize the service events in business contracts. JAVA 1.6_ 20th build was employed for the accomplishment of the ARA, along with PEPP under inference analysis. A workstation equipped with core2duo processor, 2GB RAM and Windows XP installation was made use of for investigation of the algorithms. The parallel replica was deployed to attain the thread concept in JAVA.
We used same experiments platform described in [1]. To evaluate the effectiveness in extracting business events, we manually annotate the following five (arbitrarily selected) manufacturing contracts from the Onecle repository. We consider a corpus of contracts from Onecle for some evaluations.
We employed well known evaluation metrics [10] precision, recall, and F-measure was used in the information retrieval field as performance measures (Table 3). These additional measures are defined using Eq1, Eq2 and Eq3.. We measured the event extraction accuracy as follows:
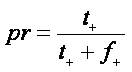
Here in Eqn.1 the pr indicates the precision t+ , indicates the true positives and f+ indicates the false positive
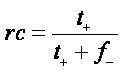
Here in the Eqn. 2, the 'rc' indicates the recall, ‘f ' indicates - the false negative.
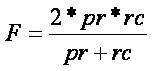
Here in Eqn.3, 'F' indicates the F-measure.
Initially we automatically produce the characteristics as avowed and extracted all event contenders. Then we make use of Logistic Regression as of Weka for evaluation. By means of ten-fold cross validation, we attain results. Here, each weighted average is calculated according to the proportion of instances in each class.
Table 3 gives Precision, recall and F-measure values for event significance evaluation, and categorization is done by human perception and by proposed approach.
The compatibility of the proposed approach with existing process by domain experts is optimistic and considerable (Figure 3). Hence, the proposed approach is a reliable text mining process to evaluate and categorize the events of the business contracts.
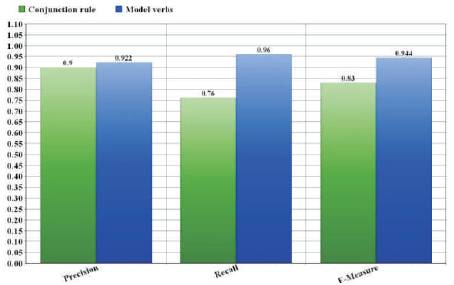
Figure 3. Performance of proposed Approach

Table 3. Precision, Recall and F-measure
Here in this paper, a novel post mining process is proposed to evaluate the significance and categorize the events in business contracts. The process of extracting events from business contracts is the most reliable approach for Event extraction, which is originally a text mining process that relies on NLP. Further we devised a post mining process called Service Event Significance Evaluation and that evaluates the significance of the extracted events and categorizes the same. The experimental results explored the performance of the proposed approach as reliable and stable. Further this work can be extended to devise a machine learning model that scores the complexity of the business agreement by depending on the event categories and significance.