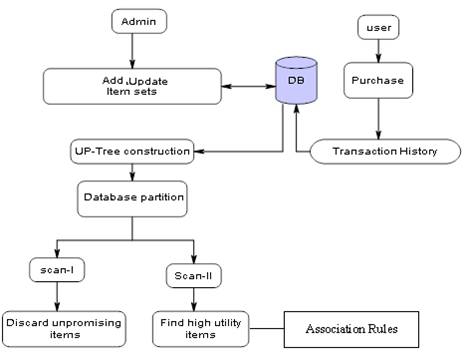
Figure 1. Architecture Diagram
Data mining aims at extracting only the useful information from very large databases. Association Rule Mining (ARM) is a technique that tries to find the frequent itemsets or closely associated patterns among the existing items from the given database. Traditional methods of frequent itemset mining, assumes that the data is centralized and static which impose excessive communication overhead when the data is distributed, and they waste computational resources when the data is dynamic. To overcome this, Utility Pattern Mining Algorithm is proposed, in which itemsets are maintained in a tree based data structure, called as Utility Pattern Tree, which generates the itemset without examining the entire database, and has minimal communication overhead when mining with respect to distributed and dynamic databases. Hence, it provides faster execution, that is reduced time and cost.
Data mining is a widely used approach to transform data into useful pattern. Handling and mining huge amount of records seems to be difficult with traditional data mining techniques. The process of mining data into useful patterns took longer duration. After finding out the association rules, filtering out the best rules is really challenging [1].
There exists an imbalance in the current data mining techniques from the performance perspective like Algorithm imbalance, Pattern imbalance, and Decision imbalance. Therefore, to find the best rules out of the huge rule set, several Rule Interestingness measures were considered. There are two basic interestingness Measures, Subjective and Objective measures. Subjective measures of Interestingness states the belief of the user. Objective measures work on the data and the structure of rule in a discovery procedure. Support and Confidence are objective measures.There exists many association rule mining algorithms like Apriori, FP-Tree [2], Dynamic Hashing and Pruning, Dynamic Item Set Counting, SEAR and SPEAR, PEAR, Eclat, MaxEclat etc. After which various upgradations to frequent pattern mining and high utility mining [7] came into existence.
Y.Liu, W-K.Liao, A.Choudhary proposed a two phase algorithm to find high utility itemsets. Only two database scans were needed to find frequent itemsets. The first database scan finds the 1-itemset wu(transaction weighted utilization) and from this 2-itemsets transaction weighted utilization can be found. The second database scan, finds the 3-itemsets based on 2-itemsets. The drawback of this approach is level wise candidate generation and test methodology which consumes time [3].
J Hu et al developed a paper for an algorithm for frequent item set mining that identifies high utility item combinations. The goal of this algorithm is to find segments of a data, defined through combinations of some items (rules), which satisfy certain conditions as a group and maximize a predefined objective function. In contrast to the traditional association rule and frequent item mining techniques, the high utility pattern mining conducts rule discovery with respect to individual attributes as well as with respect to the overall criterion for the mined set, attempting to find groups of such patterns that contribute the most to a predefined objective function [4].
Liu Jian-ping, Wang Ying, Yang Fan-ding et al (2010) proposed an algorithm for tree based incremental association rule mining algorithm. It is based on a FUFP (fast update frequent pattern) mining method. The advantage of FUFP is that it reduces the number of candidate set while moving on to updating procedure. In FUFP all links are bidirectional. Due to this, addition/removal of child node would be easy without much reconstruction of tree structure. The algorithm classifies the items into the three categories: frequent, infrequent and pre-large. Pre-large itemsets has two supports threshold value (i.e. upper and lower threshold). The drawbacks of this approach is that the entire procedure is time consuming as it requires multiple passes for its processing [5], [6].
Shih-Sheng Chen et al (2011) proposed a method for finding frequent periodic pattern using multiple minimum supports which is based on real time event. The items in the transactions are arranged according to their minimum item support. Another approach PFP (periodic frequent pattern) was used which is similar to FP-Growth and using the conditional pattern base the frequent items are generated. This algorithm is more efficient in terms of memory space, reducing the number of database scans [8].
Figure 1 shows general block diagram of proposed high utility mining method. A user can purchase the items and all purchased items are stored in transaction history which contains day to day transaction. Based on it Utility pattern tree is constructed based on the algorithm described below. Find the promising and unpromising items based on the user specified threshold and consider only the promising items for pattern mining. Based on the frequent patterns obtained, generate association rules and then filter those rules as there may be redundant rules based on the confidence.
Figure 1. Architecture Diagram
Consider a Transaction database T={T100 ,T200,T300 …Tn } and every individual transaction consists of various Items and the total items present in the entire database be represented as I={I1 ,I2 ,I3 ,…Im}.
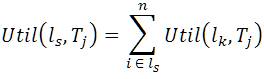
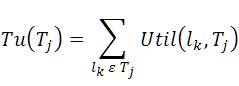
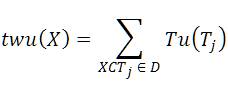
From Table 1, the internal utility of Item I3 in the transaction T300 is 5, external utility is 7 and Util is 5*7=30. The tu(T300) = Util(I1 ,T300) + Util(I2 ,T300) = (10*3)+(2*4)=38.
There are three phases of mining. The phase 1 explains the tree construction. Phase 2 states the creation of conditional pattern base and condition FP-tree, from which the frequent patterns are generated. Phase 3 explains the mining of high utility patterns.
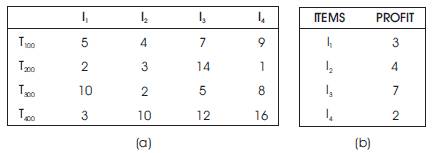
Table 1. Sample of (a) Transaction Database and (b) Utility Table
The FP-Tree is constructed in the following steps:
The FP Tree is mined by calling FP-Growth (FP_Tree, null), which is implemented as follows.
Procedure FP-Growth (Tree, α)
The promising items obtained as a result of the algorithm are a1, a3, a4. Next, the rules are generated by the promising items only.
Figure 2 gives the pictorial representation of the best rules generated by the ARM. Out of 98 rules generated only rules 2, 10, 12, 1, 9, 11 (total=6) were concluded as the best rules.
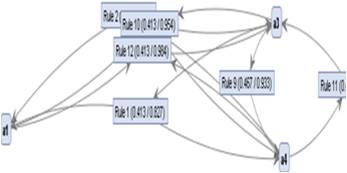
Figure 2. Generated Rules
Figure 3 indicates that out of all the items present in the database a4 is the actively participating node and the rules generated by it are rule 1, 2, 12, 10. That is a4 contributes more while generating and filtering rules. It has provided 4 best rules from a total of 6 best rules and filtration of rules.
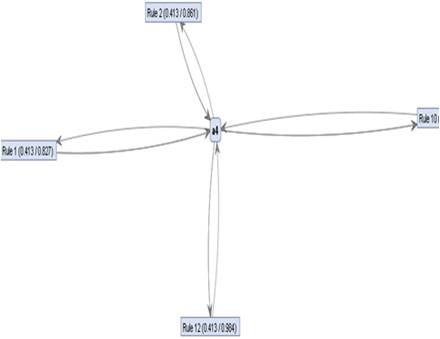
Figure 3. Most Promising item and its rules
The rules are filtered based on various interestingness measures like lift, support, confidence, LaPlace, Gain. P-S, Conviction etc.
Figure 4 shows the filtered best rules where the conclusion is the item a3. And these are the best combinations as these rules have a lift >1 and confidence >80% and support >40% and conviction>4 and p-s >0.1.
Figure 5 shows the filtered best rules where the conclusion is the item a4.
Figure 6 gives the filtered best rules where the conclusion is the item a1.
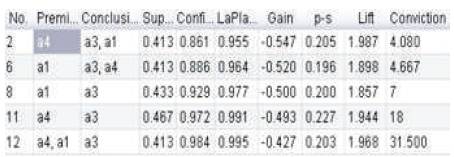
Figure 4. Filtered rules of item a3
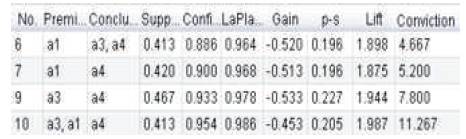
Figure 5. Filtered rules of item a4
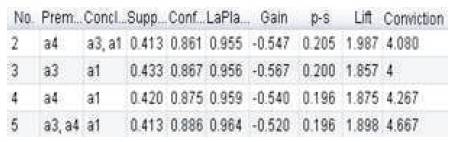
Figure 6. Filtered rules of item a1
The algorithm offers a better performance when compared to the basic methods available. As a future enhancement, parallelization of the task and incremental mining can be appended. As the size of the tree grows, it becomes difficult to mine the frequent pattern from such a huge tree, so if it can be done in parallel, then the total execution time would be reduced. And as the transactions would be continually increasing and may be the same items already present in the tree would reappear in next few transactions, a better algorithm that mines only the incremented tree structure may be required to yield a better performance.