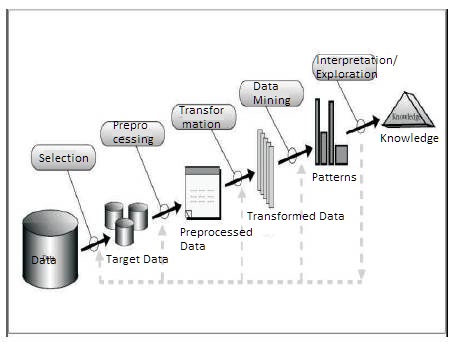
Figure 1. Knowledge Discovery Process
Data mining is the process of extracting patterns from data. Basically Data mining is the analysis of observational data sets to find unsuspected associations and to sum up the data in new ways that are both clear and useful to the data owner. It is seen as an increasingly important tool by modern business to transform data into business intelligence giving an informational advantage. The automated, prospective analyses offered by data mining move beyond the analyses of past events provided by retrospective tools typical of decision support systems. This review paper discusses few of the data mining techniques, algorithms and some of the organizations which have adapted data mining technology to improve their businesses and found excellent results. Data mining tools can answer business questions that traditionally were too time consuming to resolve. Data mining is becoming increasingly common in both the private and public sectors. Industries such as banking, insurance, medicine, and retailing commonly use data mining to reduce costs, enhance research, and increase sales. To be successful, data mining still requires skilled technical and analytical specialists who can structure the analysis and interpret the output that is created.
Data mining is the withdrawal of hidden predictive information from large databases. It allows us to find the needles hidden in our haystacks of data. It is a prevailing new technology which has great potential to help companies that focus on the most important information in their data warehouses. Tools of data mining predict future trends and behaviors, allowing businesses to make proactive and the knowledge-driven decisions. Data mining offers the automated, prospective analyses beyond the analyses of past events provided by retrospective tools typical of decision support systems. Data mining tools can answer business questions that traditionally were too time consuming to resolve. They search databases for hidden patterns, finding analytical information that experts may miss because it lies outside their expectations. It is playing increasingly important role in both private and public sectors. E.g. the insurance and banking industries use data mining applications to detect fraud and assist in risk assessment. Data mining can be used in a predictive manner for a variety of applications. Data Mining is also popularly known as Knowledge Discovery in Databases (KDD). Usually data mining and knowledge discovery in databases are taken as synonyms, but in actual data mining is part of the knowledge discovery process. The Knowledge Discovery in Databases process comprises of following steps leading from unprocessed data collections to some form of useful knowledge [1,2].
In this phase noise data and irrelevant data are removed from the whole collection.
In this phase, multiple data sources, often mixed, may be combined in a common source.
In this phase the data relevant to the analysis is decided on and retrieved from the data collection.
In this phase in the selected data is transformed into forms appropriate for the mining procedure
It is the vital step in which knowledgeable techniques are applied to extract patterns potentially useful.
In this step, firmly interesting patterns representing knowledge are identified based on given measures.
Knowledge representation is the last phase in which the discovered knowledge is visually represented to the user. This essential step uses visualization techniques to help users understand the data mining results. Normally some of the above steps are being combines.
For example, data cleaning and data assimilation can be performed together as a pre-processing phase to generate a data warehouse. Data assortment and data transformation can also be combined where the consolidation of the data is the result of the selection, or, as for the case of data warehouses, the selection is done on transformed data. This is an iterative process. Once the discovered knowledge is presented to the user, the evaluation measures can be enhanced, the mining can be further refined, new data can be selected or further transformed, or new data sources can be integrated, in order to get different, more appropriate results (Figure 1).
Figure 1. Knowledge Discovery Process
In the KDD process, the data mining methods are for extracting patterns from data. The patterns that can be discovered depend upon the data mining tasks applied. Generally, there are two types of data mining tasks:
Descriptive data mining tasks that describe the general properties of the existing data, and predictive data mining tasks that attempt to do predictions based on available data. Data mining can be done on data which are in quantitative, textual, or multimedia forms.
Data mining applications can use different kind of parameters to examine the data. They include association (patterns where one event is connected to another event), sequence or path analysis (patterns where one event leads to another event), classification (identification of new patterns with predefined targets) and clustering (grouping of identical or similar objects).Data mining involves some of the following key steps[3,4] (Figure 2).
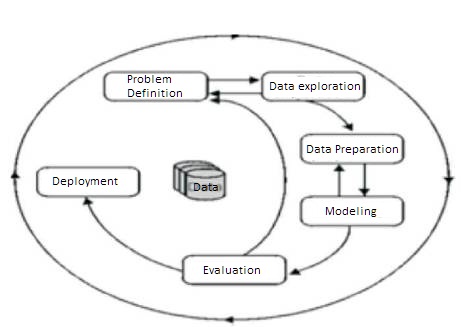
Figure 2. Data Mining Process Representation
Problem definition: The first step is to identify goals. Based on the defined goal, the correct series of tools can be applied to the data to build the corresponding behavioral model.
If the quality of data is not suitable for an accurate model then recommendations on future data collection and storage strategies can be made at this. For analysis, all data needs to be consolidated so that it can be treated consistently.
The purpose of this step is to clean and transform the data so that missing and invalid values are treated and all known valid values are made consistent for more robust analysis.
Based on the data and the desired outcomes, a data mining algorithm or combination of algorithms is selected for analysis. These algorithms include classical techniques such as statistics, neighborhoods and clustering but also next generation techniques such as decision trees, networks and rule based algorithms.
Based on the results of the data mining algorithms, an analysis is conducted to determine key conclusions from the analysis and create a series of recommendations for consideration.
Nowadays, large quantities of data are being accumulated. The amount of data collected is said to be almost doubled every 12 months. Seeking knowledge from massive data is one of the most desired attributes of Data Mining. Data could be large in two senses. In terms of size, e.g. for Image Data or in terms of dimensionality, e.g. for Gene expression data.
Various algorithms and techniques like Classification, Clustering, Neural Networks, Association Rules, Decision Trees, Genetic Algorithm and etc., are used for knowledge discovery from databases [5,6].
Classification is the most commonly applied data mining technique, which employs a set of pre-classified examples to develop a model that can classify the population of records at large. Fraud detection and credit risk applications are particularly well suited to this type of analysis. This approach frequently employs decision tree or neural network-based classification algorithms. The data classification process involves learning and classification. In Learning the training data are analyzed by classification algorithm. In classification test data are used to estimate the accuracy of the classification rules. If the accuracy is acceptable the rules can be applied to the new data tuples. For a fraud detection application, this would include complete records of both fraudulent and valid activities determined on a record-by-record basis.
The classifier-training algorithm uses these pre-classified examples to determine the set of parameters required for proper discrimination. The algorithm then encodes these parameters into a model called a classifier.
Clustering can be said as identification of similar classes of objects. By using clustering techniques it have further identify dense and sparse regions in object space and can discover overall distribution pattern and correlations among data attributes. For example, to form group of customers based on purchasing patterns, to categories genes with similar functionality.
Regression technique can be adapted for predication . Regression analysis can be used to model the relationship between one or more independent variables and dependent variables. In data mining independent variables are attributes already known and response variables are what we want to predict. Unfortunately, many real-world problems are not simply prediction. For instance, sales volumes, stock prices, and product failure rates are all very difficult to predict because they may depend on complex interactions of multiple predictor variables. Therefore, more complex techniques (e.g., logistic regression, decision trees, or neural nets) may be necessary to forecast future values. The same model types can often be used for both regression and classification. For example, the CART (Classification and Regression Trees) decision tree algorithm can be used to build both classification trees and regression trees. Neural networks too can create both classification and regression models.
Association and correlation is usually to find frequent item set findings among large data sets. This type of finding helps businesses to make certain decisions, such as catalogue design, cross marketing and customer shopping behavior analysis. Association Rule algorithms need to be able to generate rules with confidence values less than one. However the number of possible Association Rules for a given dataset is generally very large and a high proportion of the rules are usually of little (if any) value.
Neural network is a set of connected input/output units and each connection has a weight present with it. During the learning phase, network learns by adjusting weights so as to be able to predict the correct class labels of the input tuples. Neural networks have the remarkable ability to derive meaning from complicated or imprecise data and can be used to extract patterns and detect trends that are too complex to be noticed by either humans or other computer techniques. Neural networks are best at identifying patterns or trends in data and well suited for prediction or Forecasting needs.
Decision trees use real data mining algorithms. Decision trees help with classification and spit out information that is very descriptive, helping users to understand their data. A decision tree process will generate the rules followed in a process.. These decision trees are very similar to the first decision support (or expert) systems
To set up a data set then give the GA ability to do different things for whether a direction or outcome is favorable. The GA will move in a direction that will hopefully optimize the final result. Gases are used mostly for process optimization, such as scheduling, workflow, batching, and process re-engineering.
Data mining is a relatively new technology that has not fully matured. Despite this, there are a number of industries that are already using it on a regular basis. Some of these organizations include retail stores, hospitals, banks, and insurance companies. Many of these organizations are combining data mining with such things as statistics, pattern recognition, and other important tools. Data mining can be used to find patterns and connections that would otherwise be difficult to find. This technology is popular with many businesses because it allows them to learn more about their customers and make smart marketing decisions. Here is overview of business problems and solutions found using data mining technology[7,8].
Data mining has importance regarding finding the patterns, forecasting, discovery of knowledge etc., in different business domains. Data mining techniques and algorithms such as classification, clustering etc., helps in finding the patterns to decide upon the future trends in businesses to grow. Data mining has wide application domain almost in every industry where the data is generated that's why data mining is considered one of the most important frontiers in database and information systems and one of the most promising interdisciplinary developments in Information Technology.