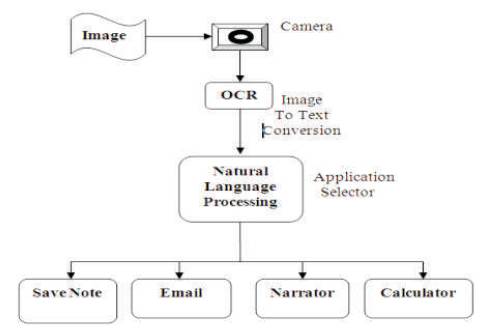
Figure 1. Reference Model for the system
This paper proposes a generic font description model for optical character recognition. It is based on concept of evolutionary computing architecture. This is user interface application software which works on learning and recognizing the handwritten text of the particular user. The project allows user to write his command for the computer on blank paper and control the operations of the computer via conversational creature. The purpose is to design an easy interface with the computer for computer illiterate persons. Text written by the user will be available to computer for further processing like text editing, narrating, and messaging.
Proposed system has manifold application in government offices for storing lacks of files of record, in business meetings for maintaining review of discussion, in educations for converting professors' notes into soft copies etc. Blind people can be highly benefited from this system as it supports narrator application. The authors proposed the algorithm to avoid the ambiguity. The system is tested by giving the handwritten character and sentences of different user. The system recognizes all character and sentences of all users correctly. The user written command on the paper are also recognized and executed by the system. It is found that the performance of the system is approximately is equal to 92%. This system is cost effective as it requires very less hardware support like camera or scanner.
Optical Character Recognition (OCR) is a type of document image analysis where scanned digital image that contains either machine printed or handwritten script input into an OCR software engine and translating it into an editable machine readable digital text format. Development of OCRs for Indian script is an active area of research today. Optical Character Recognition is the process of converting image of printed text into computer understandable format. Handwriting is most natural form of communication interface that has been learned by us as part of our educational system. The aim of the project is to make computer applications more user friendly for computer illiterate people. 'Recognizing handwritten text and processing the user request to accomplish tasks are at the core of the project.
The Optical Character recognition systems are the hot research area in computer engineering. The Optical Character Recognition (OCR) is used to analysis the scanned image that may contain the printed or hand written scrip by OCR software engine. After analysis the engine translated it into an editable machine readable digital text format. (Soumya Mishra, Debashish Nanda & Sanghamitra Mohanty (2010 December)) mentioned that it is very difficult to implement the OCR that works under all possible conditions and gives highly accurate results. The input to the OCR is normally image of hand written or oriented characters or digits. The main challenge in the field of image processing is to recognize both printed and handwritten document. There are two main methods of image processing in OCR.
There are two types of template matching methods: one is one dimensional and second is two dimensional. In one dimensional method, the template matching can be divided into two main processes, i.e. superimposing an input shape on predefined template and measuring the degree of coincidence between the input shape and the predefined template. The projection can be taken in horizontal or vertical direction which makes the superposing processes position invariant in one direction. The template matching is done by taking the total sum of differences between each input sampled value and corresponding template value. (Snumji Mori, Ching Y.Suen & Kazuhiko Yamamoto (1992 July)), stated that the near difference value is considered as the input shape is same as template.
There is main problem of registration in template matching and can be used for printed characters. It is very difficult to create templates for various shapes of printed and handwritten characters. This method marks a continuation of logical template matching. The mathematical principles are not used in the structural analysis. The certain information strategies are used in this method. The image can be broken into small part and they can be described by the features relationships. This method is totally depending on the feature exaction method used in image processing
Current software applications provide typing (keyboard) and pointing (mouse) as basic mechanisms for user interaction with system. Operating systems are based on text based (DOS) or GUI based (Windows) processing of user query. It limits the system users as it is necessary to learn keyboard and mouse. So we invent a system which controls different computer services by processing handwritten test of user.
Handwriting recognizers are broadly divided into two categories.
On-line recognizers run, and receive the data, as the user writes. Generally, they have to process and recognize the handwriting in real- to near real-time. Off-line recognizers run after the data have been collected, and the image of the handwriting, for analysis, is given to the recognizer as a bitmap. Online recognition system: Quickies (detect pen motion through special hardware to recognize text) Offline recognition system: ASPRISE OCR, TOCR (convert standard fonts scanned images into computer understandable format). The problem with handwritten text recognition is that user may write his query in his own handwriting and each user has a different handwriting style. Even each user may use different keywords for specifying different applications like 'evaluate', '=?', 'calculate', 'find' to solve a mathematical calculation.
(Snumji Mori, Ching Y.Suen & Kazuhiko Yamamoto (1992 July)), the concept of Optical Character Recognition firstly is presented by Tausheck in 1929 of Germany and Handel of U.S... We found many papers which were very useful in writing this paper. We have discussed some of these papers in short as below. We thanks to all authors of papers which are citied in this paper for their valuable information in developing this software.
(Hsin-Chia Fu and Hung-Yuan Chang (2000)), have mentioned that user dependent system usually give better performance than user independent system because of availability of sufficient amount of data for training. So, we are proposing user dependent approach for our system.
(Le Anh Cuong, Ngo Tien Dat, Nguyen Viet Ha (2010)), have presented the paper on reorganization of isolated handwritten Vietnamese character. The most optical character recognition is a classification problem. In this paper they have presented the process of feature extraction for Vietnamese characters. They investigated gradient, structural, and concavity characteristics of the character images for feature extraction. In classification the image of each character or word is considered as a set of features. After extraction of feature a machine learning method is used to train a classifier. There is a main problem of extracting the useful features and designing effective machine learning methods. Many machine learning algorithms can be used in OCR such as neural networks, Hidden Markov model, and Graph-based method. The different classifiers can be used for classification. The authors have found that Multiple Classifier Systems examine how individual classifiers can be combined to obtain a better classification system for handwriting recognition. They have derived some combination rules based on OWA operators and Naive Bayesian inference. These rules are applied on classifiers which are based on features sets. While conducting the experiments, the authors have observed that the combination of Gradient feature extraction, Structural feature extraction and Concavity feature extraction feature gives the best result and SVM algorithm produces the best result. They have described the process of extracting the features in very detail.
(L.Pratap Reddy, T.Ranga Babu, N.Venkata Rao and B.Raveendra Babu (2010)), have proposed the statistical behavior of the cursive script, Telugu in this paper. The Cursive scripts are more complex possessing a large number of overlapping and touching objects. The segmentation of individual components of the script is the most challenging task of character recognition. The Topology and geometry is the important information of any script. The statistical properties with regard to topology can improve the segmentation. The authors have studied the statistical behavior of the topological properties extensively for achieving highest accuracy. The topological properties of syllables are studied and adopted in the segmentation process. The authors have evaluated the statistical behavior of cursive components. They also proposed Split Profile Algorithm while handling touching components and the proposed algorithm evaluated on different fonts and sizes.
The OCR system for Oriya language is developed [by (Soumya Mishra, Debashish Nanda and Sanghamitra Mohanty (2010)). There are many challenges of image processing for recognizing character both in printed and handwritten format. In this paper, author argues that a number of automatic and semi-automatic tools can ease the development of recognizers for new font styles and new scripts. They have discussed that the automatic and semi-automatic tools can be used to build new OCRs for the purpose of recognizing Oriya script. The Back propagation Neural Network for efficient recognition is used for to correct.
The denoising procedure with the edge preservation capability is developed by (Chih-Yu Hsu, Hsuan-Yu Huang, and Lin-Tsang Lee (2010)). The Optical Character Recognition (OCR) system is a very sensitive to noise. The Image noise means blurred image decreases the accuracy of the recognition of documents by OCR (optical character recognition) software. The denoising method is used to reduce the noise and o increase signalto- noise ratio (SNR) in an image. The paper is to develop a denoising procedure with the edge preservation capability. The main contribution of this paper is to propose a procedure to smooth the noisy or denoised image with any kind of denoising algorithm for desired edge preservation.
A new algorithm for the adaptation of HMM models have presented by (Kamel AIT MOHAND, Thierry PAQUET, Nicolas RAGOT, Laurent HEUTTE (2010)) that jointly and iteratively adapts the HMM structure and the GMMs. The algorithm can be applied for recognition of printed characters. This algorithm is useful for adaptation of new poly font the character which never seen during training. They have used the MAP adaptation principle in their research which increases the performance in character reorganization.
(Greg Little and Yu-An Sun (2011)), have used the OCR system for human interaction with the computer. The authors presented human computation process for performing human OCR on hand-completed forms which is relatively complicated. They performed OCR on handwritten forms by taking a set of scanned forms and generating a spreadsheet of the data on the forms. The system is developed in three phases. In first phase a set of rectangles covering the form is provided. Then, in second phase such rectangle is labeled. In third phase, for each rectangle of each scanned form is cropped and prompted them to write what is written there using Human OCR.
(Sobia T. Javed, Sarmad Hussain, Ameera Maqbool, Samia Asloob, Sehrish Jamil and Huma Moin (2010)), have proposed method which allows successful recognition of Nastalique Script/ Urdu . There are different styles of writing Urdusuch. Nastalique, Nash, Kofi, sals, devani and Raka. Nastalique and Naskh are most commonly used script. The Nastalique is context sensitive and cursive nature so it is very complex. Due to the absence of baseline in the language and complex mark placement rules makes the situation even more worst. So the extraction of Nastalique text from the image is not a very difficult task. The proposed algorithm by authors extract the Nastalique texts successfully with good result.
(U. Pal and B. B. Chaudhuri (2001)), have presented an automatic technique for the identification of printed Roman, Chinese, Arabic, Devnagari and Bangla text lines from a single document which contain several script. The concept of water reservoir has been used for identification of script.
(G S Lehal and Chandan Singh (2002)), have presented a multi-font Gurmukhi OCR for printed text. They have discussed the potential solutions by also addressing the problems in the various stages of the development of a complete OCR for Gurmukhi script discusses potential solutions. The system operates at connected component level. The segmentation process used to decompose the text image into connected components. Then the features are extracted of each component and are fed to a classifier which recognizes the connected component.
The connected components are then combined to form Gurmukhi characters.
The main objective of the system is to design generalized optical character recognition system which converts the input handwritten text image into character feature vectors and intelligently learn vectors to recognize what user wants to communicate to the system. Using this system user can request computer to:
Our system is an attempt to make computer system easily usable in day to day life. It has put the concepts of science fiction into reality. Though it does not provide any general intelligence, it provides a framework with which any application can be modeled as an emulation of human behavior. As our system allows users to send Email, the user is required to provide the password. This information should be kept secured and for that we use different encryption techniques. Unauthorized user should be prevented from sending E-mail. The System can be used for any application that makes it generic. One can use it for depending on the demand of clients. A fully functional system will be equivalent to an Operating System Service Pack. The system is presently designed to work on any Windows Based Operating System. We have limited the scope of the system to following applications such as Calculator, E-mail, and Narrator. The problem of user dependent handwriting has been solved by training the system with samples of user written text. While natural language processing problem has been solved by groping all synonyms into classes and map them to computer applications like 'calc', 'note' applications.
The goal of the system is to achieve reliable and robust handwritten text recognition (Figure 1).
Figure 1. Reference Model for the system
The camera captures the image of the handwritten text and gives it to OCR (Optical Character Recognition). (Rym AMEUR & Jean-Claude HEUDIN (2006)), the recognized characters form the computer understandable and editable text on which Natural Language Processing is done which identifies the user's intentions and invokes the relevant applications for user such as Email, Narrator and Calculator.
Figure 2 depict the systematic diagram of the system.
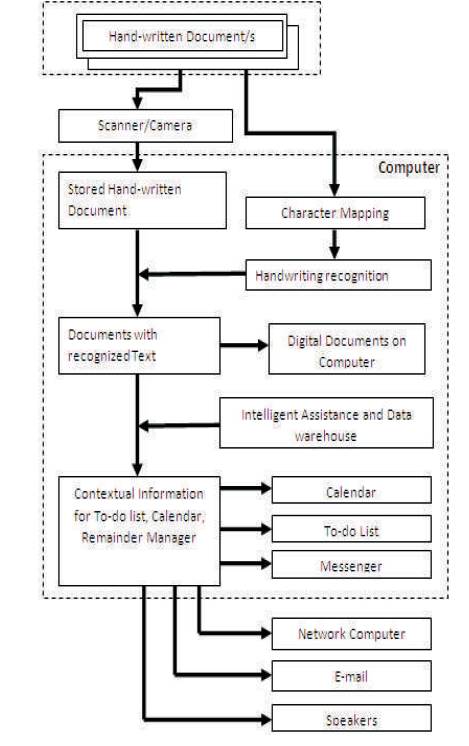
Figure 2. Schematic diagram of the system
The software is based on the concept of OCR (Optical Character Recognition) and SVM (Support Vector Machine). It will be trained with samples of user written characters. OCR is used for printed text only but our software will be able to recognize text written by particular user in his own handwriting. User needs to provide a mapping of handwritten character with ASCII character. User can also add his own symbols giving special meanings to them. Physical documents are captured into a computer using a digital hardware (Camera/Scanner). Our system stores the handwritten notes as bitmaps and converts the stored handwritten notes into computer understandable text using handwriting recognition algorithms. The recognized text will be processed by an Intelligent Assistant which understands the user intentions to take the required action like web browsing, messaging using AI techniques. This software will maintain a database of character patterns for different users of the system. Later, the computer program can use its understanding of the user's intentions, content and the context of the notes to provide the user with reminders, alerts or messages. The system will attempt to link handwritten notes to the mobile phone, digital calendars, task lists, email and messaging clients.
A Support Vector Machine (SVM) is a concept in computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification. The standard SVM takes a set of input data and predicts, for each given input, which of two possible classes the input is a member of. There are two types of SVM:
Given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that assigns new examples into one category or the other.
Our system comprises of evolutionary Non-linear SVM i.e. definition of character classes improve with training [Datong Chen (2001)]. While training, it required to assure that, newly added character is not similar to already known characters.
To assure loss of ambiguity in character definitions, we have developed an algorithm.
If (dist (newChar, ClosestChar) < Threshold)
Known Character
Else if (dist (newChar, ClosestChar) < 2*Thresh)
Learn Character as Closest Character
Else Set Character as suggested by user
The major steps [Mikael Laine & Olli S (2006)] taken by system during Handwritten character recognition are decribed as given in Figure 3.
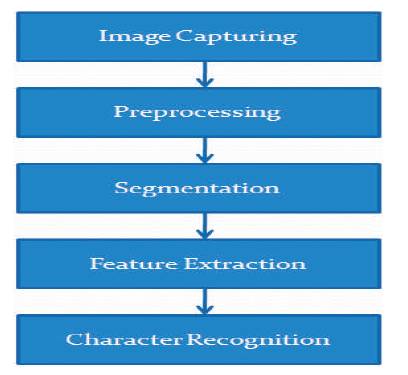
Figure 3. Major steps in OCR
Image Capturing: Camera captures the image of user's notes (Figure 4).

Figure 4. Image Capturing
Preprocessing: In preprocessing phase binarization of the image is done. The resultant image is in two colors black and white as shown in (Figure 5).

Figure 5. Image binarization
Figure 6. Horizontal Histogram
Segmentation: In this phase vertical and horizontal Histograms of the image is taken. The system first separates lines of text then characters in each line (Figure 7)

Figure 7. Segmentation
Feature Extraction: The separated characters are scaled to fit into a virtual matrix. This is then used for feature extraction of a character (Figure 8).

Figure 8. Extracted Character
Character Recognition: The feature vector formed in above step is compared with the one which is stored in database and recognized character is returned (Figure 9).

Figure 9. Recognized Character
The accuracy and precision of the system is calculated by using the following formulae.
Accuracy: At the initial stage, the accuracy for the new authorized user is less. But after a sufficient training, the accuracy will become high. Hence accuracy is defined as the ratio of number of correct characters to the total number of characters. The following equation is used to calculate the accuracy of the system.

We get 60% accuracy at the initial stage of training. But after second time training, we get 80-85% accuracy. And so on the accuracy reaches a max of 92% accuracy.
Precision: When the symbol is mapped to the database then it checks that the total number of character is matched with the database. Precision is defined as the ratio of number of characters that is recognized correctly to the total number of recognitions of the same symbol.

We get 65% precision at the initial stage of training. But after second time training, we get 80-85% precision. And so on the precision reaches a max of 90% precision.
User Dependent Handwriting Recognition software was tested extensively to operate in the real world and resulted in remarkable success. This software provided user-friendly and robust interface with computer for technical, non technical as well as less skilled people. User's handwritten text can be accurately converted into computer understandable format which is easily saved, edited and processed for applications like narrator, calculator, email sending etc. Proposed system has manifold application in government offices for storing lacks of files of record, in business meetings for maintaining review of discussion, in educations for converting professors' notes into soft copies etc. Blind people can be highly benefited from this system as it supports narrator application. This system is cost effective as it requires very less hardware support like camera or scanner. In future, this project can be used effectively in mobiles. It can also be used to process images containing diagrams.