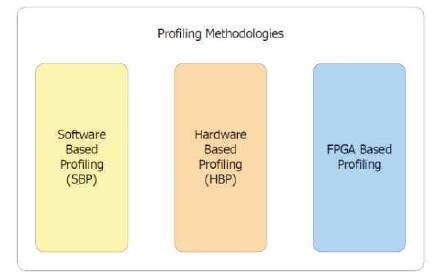
Figure 1. Profiling methods category
In this paper, a System-on-a-Chip (SoC) based hardware acceleration solution for low power mobile operating systems is proposed. In mobile communication systems, it is very costly to transform the entire software application into a hardware solution. However, some applications may have such a need due to their high performance and low power requirements. These software systems consist of several kind of functions and some of these functions will be invoked at a very high frequency. The speed and energy consumption are two major concerns for modern system development, thus it is important for designers to balance the tradeoff between these two factors. If the system can process very high-speed operations and consume less energy, it is an efficient design. The basic idea of this paper is to only transform those highly used functions into hardware by using the proposed profiling and hardware acceleration methodology. The solution that this paper will demonstrate is to convert the system into a cost effective hardware-software co-design. Experimental results show that with the proposed profiling method and hardware acceleration platform, mobile operating systems could solve the same problem within shorter period of time (4.3 times speedup) and lower energy consumption (around 76% reduction).
According to the ITRS road map [1] and the continuation of Moore's Law [2],the number of transistors on a chip will continue to increase for at least another decade. In order to benefit from the growing integrated chip, engineers have developed a new technique to manage the increased complexity in large chips, called System-on-a- Chip (SoC). SoC refers to integrating all components of a computer or other electronic systems into a single integrated circuit [3]. Bandwidth is a very critical parameter in the SoC system level design. For a balanced bandwidth design, people need to consider not only the heat dissipation and power consumption but also maximum throughput of the whole system any welldesigned SoC system must consider any possible balance-breaking aspect which may lead to system architecture re-design and increased costs [4, 5].
Modern embedded computer systems have grown rapidly due to the increasing capability of processing power while the hardware circuits are still kept in a small size. These systems have become more important in our daily lives especially in mobile communication and operating systems, such as cell phones, game consoles, as well as some larger-scale design of sophisticated products, for example; cars, medical instruments, space shuttle, etc. In order to meet the requirements of shorter response time and faster processing speed, people begin to study how to get more speedup and less energy consumption by analyzing the data of the embedded computer system, thus promote the system performance.
People always want to run the applications as fast as possible but modern processors cannot always gain the performance improvement by only increasing the frequency of the CPU. Even with the multi-processor architecture, some sophisticated applications requiring huge data calculation still cannot meet expectations because software applications written in high level language (i.e. C language) are usually sequential processed. When the application is calculation intensive, it consumes much more time and power to fulfill the task. Therefore, people implement special purpose properties, the so-called “hardware accelerator”, to execute dedicated functions of the application. Notable performance improvements can be obtained by using hardware accelerators with special design tools.
This paper addresses the challenges of implementing a cost-effective hardware-software co-design, optimizing the trade-off of the system, thus increases performance of the whole system while having little overhead. Application profiling techniques as well as hardware accelerator design scheme are used in order to create low power SoC systems.
The remainder of this paper is organized as follows: software profiling theory will be reviewed in section 1, the proposed hardware acceleration design scheme is discussed in section 2, the significance of this research is mentioned in section 3, the corresponding methodology is explained in section 4, experiment results will be presented in section 5, and lastly, the paper is concluded.
Profiling tools are used to detect the performance bottlenecks and the result is used to determine which software parts are suitable to be converted to hardware in order to achieve the performance improvement. After balancing the tradeoff between the hardware and software components, there will be a speedup based on the overall system performance [6].
Performance analysis platforms for software have been researched for years. Currently, there are several types of profiling methods: software, hardware and FPGA based profiling methods [As shown in Figure 1]. They have different profiling abilities and support applications written in different languages.
Figure 1. Profiling methods category
Software based profiling methods are mostly used to evaluate the performance of applications written in programming language [6]. Basically, there are two ways of SBP analysis:
This method will simulate application codes running on the virtual environments [7], and the behaviors of the processor will be monitored. Viewing the entire data flow movement during the simulation will benefit the designers in identifying the bottleneck of the applications as it keeps tracking all the processes inside the microprocessor. However, by using this method to simulate large software programs or SoC designs [8], it is time-consuming and can lead to inaccurate profiling data of the performance of each function.
The profiling tool will be attached to the execution files so that the performance statistics can be collected during the run-time [9]. This method is widely used on Linux and UNIX workstations. It inserts instrumentation codes to fetch the performance data of the running CPU and reads the number of program counters (PCs) to collect the number of called functions. The execution time of a program is obtained by reading the value of the PCs at the specified time frame However, since the execution time greatly depends on the frequency of the PCs, its accuracy is not guaranteed [10].
Advanced processors such as Sun Ultrasparc [11], Intel Pentium [12]and AMD Processors [13] utilize on-chip hardware counters to profile the performance of a CPU. These types of hardware counters aim for some specific events when the applications are executed, such as cache hit, cache miss, memory accesses, etc. Sun Untrasparc microprocessor has hardware counters that could be utilized by software profiling tools. To generate the profiled information, the hardware counter overflows need to be detected.
The advantages of using hardware counters to profile the behavior of applications are that the hardware counters does not touch the application code and that these counters add little performance overhead since the data is collected during the run-time. Nevertheless, it also has several drawbacks:
Due to the rapid evolution of the modern technology, FPGA provides more and more resources to be utilized. FPGA based embedded systems usually consist of a softcore processor, bus, and several kinds of Intellectual properties (IPs). These processors are used as the central component of embedded systems [15]. The soft-core processor is used to collect the performance data, and the on-chip profiling hardware gathers all the necessary data when the application code is executed. These tools keep latency and performance overhead at a minimum level, and little processor computation is required because the sampling techniques are not usually used. SnoopP [16] is an on-chip function level profiler that is used to implement designs based on Xilinx MicroBlaze core [17]. In Figure 2, the number of counters is provided so that users can use them to profile the performance of the application. SnoopP is non-intrusive to the code but its deficiency is that the number of counters is limited by the on-chip resources. Thus, the complexity of the whole system and the number of functions user wants to profile will also be limited.
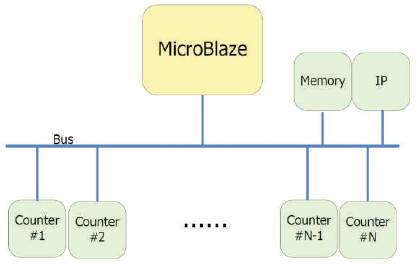
Figure 2. SnoopP Architecture
Implementing hardware accelerators in embedded computer system design can provide great performance improvement. Though implementing the whole algorithm to hardware consumes less time, it is also the least flexible and the most expensive[18]. Hence, it is important to balance the trade-offs when constructing hardware accelerators. The solutions are different depending on methodology, design environment, etc.
Currently, there are three major types of hardware acceleration methods:
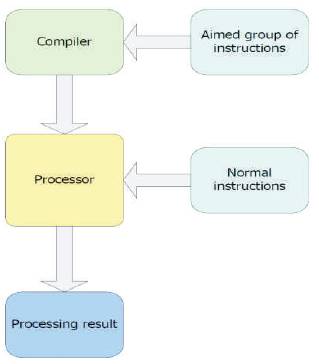
Figure 3. The hardware acceleration method using new created instruction
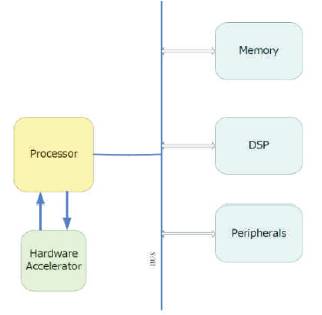
Figure 4. The hardware acceleration method using co-processor design
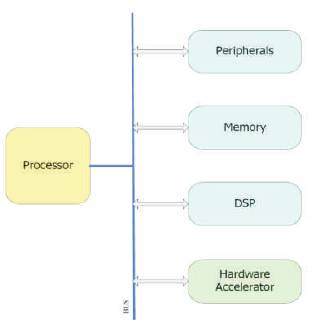
Figure 5. The hardware accelerator method connected to the system bus
A designer need to choose some aimed instructions that represent different functions. These functions should be chosen because they have high percentage occupation when software applications have been executed. The aimed instructions will be sent to the compiler specifically for the corresponding type of ISA. Multiple instructions will be compiled into one or few instructions then sent to the processor to be combined with normal instructions. The execution time of a CPU to process one instruction is fixed so the fewer the instructions, the fewer the execution time, thus, the lower the power consumption.
The major difficulty in this method is that in order to compile a new instruction, the compiler must be modified to recognize this group of instructions. The other difficulty is that the number of the chosen instructions should be confined to a limited size. If an instruction is executed many steps in the processor, other applications or functions will be interrupted leading to reduction in CPU efficiency.
A designer will first identify highly used functions of the whole software application called “hot spot”. After successfully profiling the application, hardware description languages such as VerilogHDL or VHDL will be used to transform the hot spot functions to hardware. The designed hardware part will be wrapped as an IP then attached to the processor directly from the processor's high-speed interfaces.
Compared to the former method, this method does not require the designer to modify complicated compilers. Also, since the IP is directly connected to the processor, the data transfer rate between the processor and the attached IP is very high. Moreover, if the processor has enough high-speed interfaces, the designer can attach more than one IPs to the processor. This design is very efficient when the data transmission between the IP and the processor is not very huge because when the data needed to be processed by the IP exceeds the capacity of the processor's cache capacity, the data will be fetched from the on-chip memory and sent through processor to the dedicated IP. Thus, it will have a great impact on the processor because the processor cannot process any other requests at that time. As a result, the efficiency will be very low. Besides, the total number of attached IPs is limited by available high-speed interfaces of the processor; the processor's resources may not meet the IP's demand.
A designer will do the first several procedures as in the coprocessor design method. After that, the designer will profile the software code and use the hardware description languages to convert hot spot functions to specific IP where the IP are connected directly to the system bus not to the processor.
There are several benefits by connecting the IP directly to the system bus. First, this method resolves the communications issue between the IP and the on-chip memory. If the processor sends an instruction to the IP to execute a function while the processed data is stored in the on-chip memory, the IP can fetch the data directly from the memory. This is very efficient especially when a large data set is processed because all the interactions happen among the memory, IP and bus. The processor can now have spare time to acknowledge other requests from other peripherals or devices. Nonetheless, this method has some limitations. Because all the communications between devices go through the system bus, the performance improvement will be greatly affected by the speed of the system bus and the bus protocol. When a lot of requests are made, the bus protocol will choose the highest priority request, which probably is not a request from the IP. Besides, the communication between the IP and the processor is not as fast as the co-processor method since when the processor sends a command to the IP, or when the IP acknowledges an instruction from the processor, there is a response time interval caused by the processor and bus's own behavior; if there are many requests on the bus, the time interval will get worse.
To sum up, hardware acceleration methods are evolving at a rapid speed and every method has its own advantages and disadvantages. In order to choose the right method, the designer should make a decision based on the full evaluation of the demand by considering the system configuration, the goal of the project, the complexity of the design, etc.
Nowadays, there are two major concerns of our modern processing element design.
First, even our general purpose processing element can reach a higher frequency and thus can process the applications in a relatively short time. Because the nature of our current CPU type, the speed of this kind of design is relatively low.
Second, special purpose processing element is developed to meet the speed requirement for some special applications, but the price of doing this is that we can't make the design as flexible as possible.
In order to make the design run at a higher speed while keep the design to fit as many application as possible. We propose to isolate part of the highly used function of an application, and transform it to hardware accelerator to get the speedup. It is not necessary to transform all the application into hardware accelerator. Some of the functions are naturally sequential code thus they are difficult to be accelerated, some of the functions are memory based so they are not suitable to be selected. If we only transform some selected parts of an application into the hardware accelerator, the execution time of this application will be greatly reduced. Usually, the chosen functions needs intensive calculation and they are often used as different transformation and digital processing, so the flexibility of this kind of design is better than the pure special purpose processing element.
The desire that make the processor execute more data in a shorter time interval is always the first priority of our designers. We here propose to accelerate the software application by using hardware acceleration theory. We will emulate the software application by substituting the software part with the corresponding hardware part, so the data flow will automatically neglect the software function but go through the hardware accelerator.
We will first profile the software application by using the hardware profiling method. The hardware counters in our Intel Pentium machine allow us to profile the statistic of the software application with little performance overhead. The software source code is untouched so that there will be no intentional interrupt when the compiled application source code is running. After the profiling process, we analyze and classify the profiling result and finally choose the function which will cost the most execution time and has very intensive calculation steps. Then the selected function will be transformed to corresponding hardware using the hardware description language. We use the Xilinx Virtex 5 FPGA board [20] as the SoC platform. Xilinx MircoBlaze soft processor will be used as our CPU. In this system, hardware part will be wrapped as an IP which is connected to the system PLB bus. The PLB bus allows the communication between the processor and the customized IP. The software source code will be executed in the MicroBlaze but the chosen function will be replaced by the hardware IP. By providing the driver which will lead the data stream to the IP, and send the result back to the processor, the total execution time will be reduced greatly.
Speed and the energy consumption are the two major concerns for modern system development. Designers must balance the tradeoff of these two factors. If the design has very high speed but also huge energy consumption, it is definitely not a good design. After the installation of the customized IP, we will exam the energy consumption of the whole system with and without the IP. In our methodology, the system with the IP will consume more power than the system without the IP since the extra IP will cost more transistors. But because the execution time of the system with customized IP will cost much less time than the system without the customized IP, the total energy consumption will be reduced if the system with the customized IP runs long enough. The longer the software application runs, the less the energy consumption of the system with the customized IP. Usually, the energy consumption will have a threshold depending on the requirement of the system standard, if the energy consumption could not meet the requirement, then the whole hardware IP should be optimized to fulfill the task until the energy consumption meet the requirement. In this scenario, the designer must keep an eye on the hardware IP and use some optimization method to lower the energy consumption. Figure 6 shows the flow chart of our methodology.
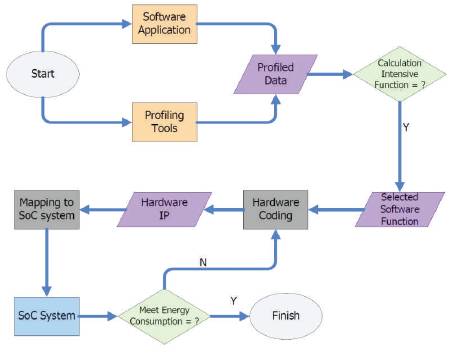
Figure 6. The methodology flow chart
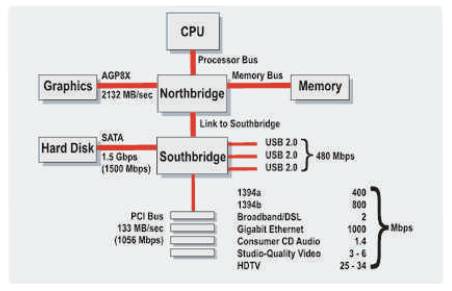
Figure 7. A typical North/Southbridge Layout
Nowadays HD video formats (1080p and 720p) are used all over the world and people enjoy these types of formats because of their high depth resolutions. However, to compress them into portable formats such as H.264 and MPEG4 is a complicated task because real-time encoding can use up to 3600 Giga Instructions per Second (GIPS) and 5570 Giga Bytes per Second (GBPS) of computation overhead.
There are some companies such as Elgato [21] who released USB drives that use H.264 hardware accelerator. However, the bandwidth of the USB bus is only 240mbps ~ 30MB/s while the bandwidth of Northbridge can take up to 2132MB/s as stated in the following chart in Figure 7. It is clear that Northbridge is about 700 times faster than the USB bus as a peripheral bus. If the chip can be applied into the Northbridge, it will solve a lot of compatibility as well.
We use the method of connecting the IP to the system bus to accelerate the H.264 application. First, we profile the H.264 application using special tools and a prepared HD video; then, we analyze and isolate the hot spot function from the H.264 application; third, we implement the isolated function to the FPGA platform as a special hardware IP; finally, we test our platform and balance the speedup and energy consumption.
For H.264 aspect, we use the famous official standard C model of H.264 (called “JM”) to setup the H.264 environment. The procedures we implement are as follow:
For profiling aspect, we use the Intel VTune [22] to analyze the whole processing procedure of H.264 compressing. We will choose the highly used function to perform a hardware acceleration to rise up the speed of the H.264 software process.
In image compression function, such as Hadamard, we found another function called “iabs,” which is the essential core of Hadamard and is the second hot spot function of H.264. The iabs function uses almost 30% of the whole processing resources, approximately 36 billion cycles. We isolate the Hadamard C function and write the corresponding Hadamard IP using the Verilog HDL. Then we build them onto Xilinx Virtex-5 FPGA platform. The customized Hadmard IP is attached onto the PLB v4.6, and the C code of the Hadamard function is compiled and placed automatically to BRAM. After the whole system is set up, we put the hadamard software and hardware solutions into main function of the C code to improve the efficiency of the overall system.
We analyze and classify the profiling result and choose a function that consumes the higher execution time and has very intensive calculation steps. The selected function will be converted to a corresponding hardware using the hardware description language. In this research, Xilinx Virtex-5 FPGA board and Xilinx MircoBlaze soft processor are used as the SoC platform and CPU, respectively. The software source code will still be executed in MicroBlaze but the chosen function will be replaced by the hardware IP. By providing the driver, which will lead the data stream to the IP and send the result back to the processor, the total execution time will be reduced.
Normally, the energy consumption has a threshold depending on the requirement of the system standard. If the energy consumption cannot meet the requirement then the whole hardware IP should be optimized to fulfill the task until the energy consumption meets the requirement. In this scenario, the designer must keep an eye on the hardware IP and uses some optimization method to lower the energy consumption. Figure 7 shows the flow chart of our methodology.
For platform expendability aspect, the hardware acceleration is based on a general function of video/image compression. It is from but not limited to H.264. The general function (Hadamard transform) that we will accelerate is widely used in many image and video compression. As an acceleration module, it can be reused and reconfigured in many ways.
Four groups of input data sets are used to generate the behavior of the design as detailed as possible. The number of clock cycles and energy consumption are monitored when the data sets are executed. As shown in Table 1, the speedup of the hardware acceleration method is around 4.3 times compared to the pure software method. Meanwhile, because the customized hardware IP will occupy the on-chip transistors of the board, so the power consumption of the hardware method is greater than the software method. But the customized hardware IP will execute the data much faster than the software solution, so if we consider the total energy consumption of the whole design, the hardware acceleration way will consume much less than its opponent. The total energy consumption reduced around 76 percent when compared the hardware acceleration method to the software method as shown in Table 2.
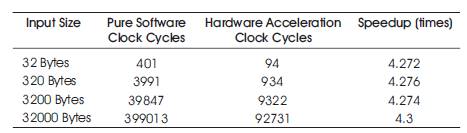
Table 1. Speedup comparison between software and hardware acceleration methods
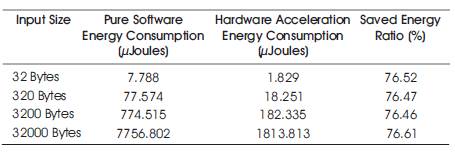
Table 2. Energy consumption comparison between software and hardware acceleration methods
Mobile devices require low power consumption to achieve a long battery life. The popularity of these mobile devices has increased the demand for low-power, lowcost systems. A methodology for designing a low power mobile operating system using hardware accelerator is proposed in this paper. It demonstrates that the energy consumption of the whole system could be reduced while having a speedup by transforming parts of the application into hardware accelerator. Thus effectively convert the system into a cost-effective hardwaresoftware co-design. This paper addresses the challenges involving profiling method in determining which part of the system should be performed using software based functions and which software part should be converted into hardware. The experimental results of the softwarehardware platform shows that with correct profiling method and the hardware accelerator, the system could reduce the Hadamard transform process of the standard H.264 compression by a factor of 4 times emulation results. And the energy consumption is also greatly reduced at the same time. This methodology targets for a SoC platform used in mobile devices to process at a high speed while maintaining the energy consumption at a reasonable level due to the fact that energy consumption is a critical parameter in electronic portable system design where excess power dissipation can lead to expensive and less reliable systems. Future works may include studying and analyzing the data to optimize the software-hardware co-design platform. By profiling and analyzing the characteristics of different functions of an application, we want to find the possibility of whether a function is suitable to be transformed to hardware accelerator. We also want to balance the trade-off between the speedup, power consumption and gate counts of the design.