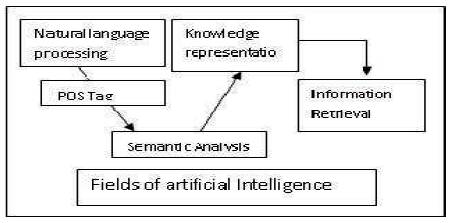
Figure 1. Inter relation of domains of artificial Intelligence
Extraction of semantics from a text is vital application covering various field of artificial intelligence like natural language processing, knowledge representation, machine learning and so forth. Research work is being carried for languages in international platform like English, German, Chinese etc. In India also, research associated with Indian languages like Hindi, Tamil, Bengali and other regional languages is developing faster. In this paper, the researchers have emphasized upon the use of Sanskrit language for semantic extraction. Sanskrit, being an order free language with systematic grammar gives an excellent opportunity for extracting semantic with higher efficiency. Panini, an ancient grammarian has introduced six Karakas (cases) to identify the semantic role of word in a sentence. These karkas are analyzed and applied for semantic extraction from the Sanskrit text. Input sentences are first converted into syntactic structure, these syntactic structures are then used for semantic analysis. The syntactic structures are present in Part of Speech (POS) tagged form and various features of this tagged data is analyzed to extract semantic role of the word in a sentence. Finally, semantic label of each word of a sentence are stored in frames called case frames, which act as a knowledge representation tool. So mapping of input POS tagged data to semantic tagged data is done and case frames are generated. Such system are useful in building question-answer based applications, machine learning, knowledge representation and information retrieval.
Knowledge representation in the field of artificial intelligence, are techniques for facilitating extraction of semantics, so that meaning from the language can be deduced. Such representations are useful in drawing inferences and reasoning with the system. In most of the situations, semantic analysis is followed by syntactic analysis as grammatical information of a language gives a platform for further analysis. One of the representations of syntactic information of language is Part of Speech (POS) tagging .For input text, it identifies the noun, verb, adjective in a sentence with respect to grammar of that language. Using the parameters of POS tags, semantic information can be deduced and stored for information retrieval. This complete process is shown in Figure 1. Storehouse of knowledge representations are then used for reasoning and information retrieval. Many knowledge representation tools like frames, semantic net, conceptual dependencies are used for same. Out of these, semantic net and conceptual dependencies represent the semantic relation of words with action entity, verb. Some of the semantic relations are agent, object instrument etc. All these tools are developed for English language. These concept can be extended to other languages too, and many research organizations of India like JNU, CDAC, IIT Hyderabad, IIT's are making effort in same direction. Dependency trees are also semantic representation of input text of any language. Building lexicalized parser for same is given by Oliver(2008). Dependency structures are also the means of semantic analysis. A graph based model has also been introduced by Sangal.
Sanskrit is one of the ancient languages with very strong grammatical structure as given by Panini [Bharati(2007), Huet (2003),Kak(1987). It has also been shown that this language is rule based language, hence very efficient for computer processing and semantic analysis. Knowledge representation using Sanskrit is efficiently explained by Brigs(1995). Nearly 4000 rules(sutras) are give in Panini AsthdhyayiHuet (2003) ,Kak (1987). Through this paper an effort is made to analyze POS tagged data and generate a knowledge representation structure called case frames. POS tagged data developed at Jawaharlal University is used.
This paper focuses on analysis of POS tags of Sanskrit text for case frame generation which stores the role of word in sentence as agent, object etc. These case frames can then be used for information retrieval like question answer based system.
For the generation of case frames, rules are identified and implemented during semantic extraction of the POS tags. Algorithm is designed for the same and tested for corpus of data.
The guideline of the tagset is as given by Dr Chandrashekhar, JNU, Jha (2007). For annotating Sanskrit text with Parts-of-Speech (POS) tags, a hierarchical POS tags set framework is designed at Special Centre for Sanskrit Studies, JNU, New Delhi (Jha (2007)). The brief description of the tagset used is given in Table 1.
Figure 1. Inter relation of domains of artificial Intelligence
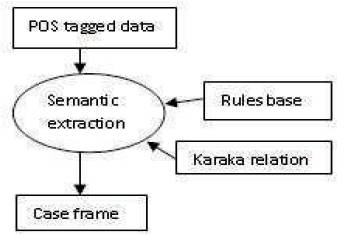
Figure 2. Architecture for System
Algorithm: Algorithm for semantic tagging of data is achieved by scanning the data from left to right and picking up the parameters from POS tagged data. These parameters include grammatical information of the words like category, gender, vibhakti, number etc. They are analyzed and rules are framed for semantic analysis for generation of case frames, which is a knowledge representation tool. These case frames can be gathered and processed for the information retrieval. Such tool can be used to develop a better understanding of the language and can assist in developing applications like question answer system, machine learning etc.
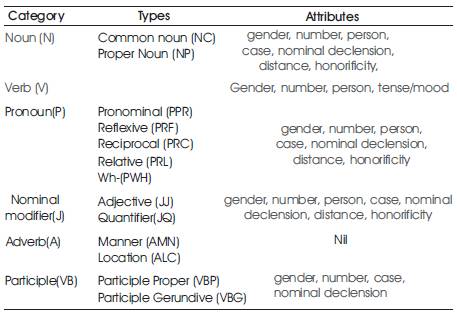
Table 1. JNU tagset - a brief summarization
Two scans are required for semantic analysis, in first scan the action word is determined and tagged as action entity. In subsequent scan, other words such as, noun and adjective are analyzed to find the semantic relation of the word with verb. The semantic role of the word is then stored in case frames. Semantic roles are given to most of the words in a given sentence. As explained above, the structure of the word in POS tagged sentence can be represented as follows:
< Word >< \> < Category-subcategory > < attributes > < flag >
Each category can further be represented as follows:
< w o r d > < \ > < N P / N C > < a 1 . a 2 . a 3 . a 4 > w h e r e a1=gender, a2=number, a3=case, a4=declension
< word > <\ > < JJ/JQ > < .a2.a3.a4.a5.a6.a7 > where meaning of attributes is same as in PPR.
Where \ acts a delimiter between the word and its attributes. Every sentence ends with | marked as PU(Punctuation) in tagged set. Sentence under process may be simple sentence or compound sentence which is identified by the fact that it can have one or multiple verbs. However algorithm incorporates both conditions in one algorithm.
While processing such sentence, algorithm searches for action word which will have a category beginning with the letter V, hence any word in the sentence with category of form V* is identified as action agent. This word is given the semantic role of 'action'. Relation of other words with the action word is done in second scan. In the second scan words with following category N*, J*, P* are examined for their semantic roles. As soon as the word's semantic role is identified and it is placed in case frame, it will not be considered in further scans. Algorithm will handle occurrence of single and multiple verbs in a sentence.
During the first scan, action words are identified and sentence is divided into components such that each component contains one action word and all other words are related to it. In most of cases, these words precede action word. Each component is then analysed for semantics. If sentence contains only single verb, one component is formed, otherwise multiple components are formed. All the words preceded by action word form a component as shown on Figure 3.

Figure 3. Formation of component in a sentence.
For k components in a sentence S of n words, algorithm for construction of case frames is given below where wc_comp[j] stores the number of words in a component j and verb of each component is stored in case_frame.action[j]. Likewise all other words of components are stored in their respective indices.


In a case frame, multiple action words are stored as list such as case_frame.action[i]. Each member of this list is action agent for one component. Hence the case frame for such sentence will be of form as shown in Figure 4.
Each field of case_frame becomes semantic tag of the word in a sentence.
Sanskrit: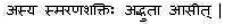

In the given sentence verb is  as it is tagged with V* and when preceding words are checked
as it is tagged with V* and when preceding words are checked 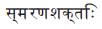
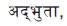 both have their 4th component as 0. Hence all three words together form verb phrase. During the second scan
both have their 4th component as 0. Hence all three words together form verb phrase. During the second scan 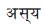 takes the genitive case and as per rule in algorithm it becomes the agent of action (verb phrase). Hence the case frame generated is shown in the Figure 5.
takes the genitive case and as per rule in algorithm it becomes the agent of action (verb phrase). Hence the case frame generated is shown in the Figure 5.

Figure 4. Sample case frame one and multiple verb

Figure 5. Case Frame for single verb
Example of multiple verb
English:Hearing the prosperity of Lord Shiva, he started fasting on Shivratri
Sanskrit: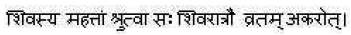

During the first scan, two verbs are identified 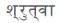 and
and 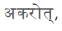 hence sentence is decomposed into two components with action as
hence sentence is decomposed into two components with action as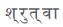 and
and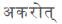 respectively. As explained in the algorithm, case frame generated will be as shown in Figure 6.
respectively. As explained in the algorithm, case frame generated will be as shown in Figure 6.
While processing POS tagged data, it is observed that there are multiple consecutive case occurrence (MCCO) in a sentence. Mostly these multiple cases occur in two consecutive words. This implies that semantic role should be given to group of words rather than a single word under MCCO. In the DSST, MCCO condition is included by merging the semantic role in step 2. Following example illustrates the MCCO case
ExampleEnglish: Moolshankar was born in village named tankara in Kathiyavad district.
Sanskrit:

Here 2nd and 3rd word have same value of attribute as 4, hence in current algorithm both words will be tagged for location case. In above example case frame generated will be as shown in Figure 7.
However this is restricted to only two consecutive occurrences of the multiple cases, which is sufficient as most of the multiple occurrences are found with two words only.

Figure 6. Case Frame for multiple verb

Figure 7. Case frame with Multiple case occurrence
The POS tagged data gives the cases, as given by Panini , an ancient Indian Sanskrit grammarian, which are described in Table 2. Each of these map direct semantic roles, except for genitive case which may act as relation or agent, with subsequent or previous word. Occurrence of genitive case is quite common as observed in the data set. There are situations where words with genitive case are associated with next word in the sentence as the relation of case. It is explained in the following example:
English:Jumping of mouse on Shivling reflected instability of life and developed the saintly feeling within him.
Sanskrit:
Case of next word like realtion(loc/ins/agent/others). This is single verb sentence with multiple case occurrence of genitive case in a non-consecutive manner.Every genitive case is associated with its next word.

Case frame for such sentence is given in Figure 8.

Figure 8. Case frame for multiple genitive case
If there are n sentences with an average of m words per sentence, as every sentence require two scan, number of comparison will be of order of n(2m) which is O(n.m ) with the generation of n case frames in the system. Hence efficiency of the system depends on two parameters, number of words in sentence-m, number of sentence-n. As n or m increases, execution time increases proportionally. This algorithm considers only indirect speech .Conversation or direct speech is not included as POS tagged data was not available for same.
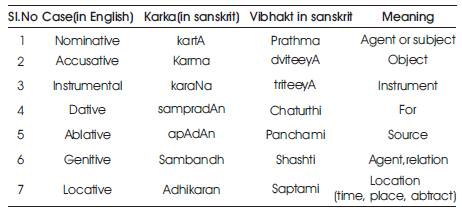
Table 2. Case mapping

Frequency of occurence of each of these cases with sample data of nearly 150 words, taken from JNU is as follows:
| Case | Frequency of occurrence |
| Genitive | 18% |
| Location | 15% |
| Nominative | 18.6% |
| Accusative | 12.6% |
Rest of the words contribute in verb phrase formation. Out of these cases, genitive case acts either as agent or relation with subsequent word. Algorithm was tested on 100 sentences taken from JNU and following results were obtained :
Proposed system analyses POS tagged sanskrit text for semantic roles and generated a case frame as knowledge representation tool. Such case frames can be generated for large text and then used in information retrieval and question-answer based system. DSST algorithm shows how efficiently semantic can be extracted using the POS tagged data. Though sanskrit is not visualised as natural language and its usage is limited to school studies, however it can be seen as language for computer processing as extraction of semantic is done easily. Hence it can be used in any system where knowledge representation and information retrieval are the key issues.