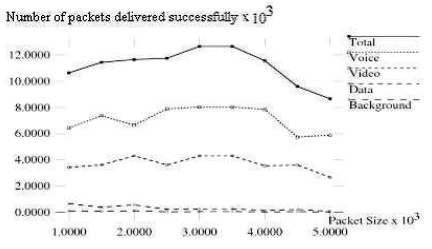
Figure 1. Number of Packets Transmitted by Original Version of IEEE 802.11e
Quality of service is how well the network satisfies the user requirements. IEEE 802.11e is the quality of service extension of wireless LAN standard IEEE 802.11. IEEE 802.11e achieves quality of service by service differentiation using the parameters Arbitration interframe space and contention window. They are set to different initial values for different flows to achieve service differentiation. But the procedure used to change contention window is same for all the flows. In this paper the contention window is adjusted differently for different flows to improve the performance of voice. Network simulator, NS2, is used for simulation.
Quality of Service is not supported in the IEEE 802.11 design [1]. Applications such as audio-on-demand, video-on-demand, voice over IP, and real time applications demand QOS. Distributed Coordination Function (DCF) which is the medium access method for adhoc networks does not have any provision to support QOS. But in DCF, access to the channel is by contention and all nodes have equal chance of transmitting i.e. no differentiation between nodes (sources) or flows. Reserving resources or differentiating nodes/flows is a step towards achieving QOS. Resource reservation is difficult to achieve in adhoc networks and hence active research is concentrated on service differentiation.
IEEE 802.11e, which is the QOS extension [2] of IEEE 802.11, provides QOS with two medium access methods Enhanced Distributed Channel Access (EDCA) and Hybrid Coordination Channel Access (HCCA), both backward compatible with the legacy DCF and PCF respectively. The HCCA integrates DCF and PCF with enhanced QOS specific features. HCCA supports both Contention free period (CFP) and Contention Period (CP). EDCA operates in the contention period and HCCA operates in the contention free period. Since HCCA requires infrastructure, it can not be used in adhoc mode of WLAN or adhoc network.
EDCA achieves service differentiation using three parameters[3].
The first parameter is Arbitrary Inter Frame Space (AIFS), which is the amount of time a flow should find the channel idle. If the channel is idle for AIFS time, then a node may transmit its data. In EDCA each node has its own AIFS value.
The second parameter is the backoff-interval. The backoff-interval is the amount of time a node defers transmission after finding the channel idle for AIFS interval. The backoff-interval depends on contention window size (CW). CW in turn depends on CWMin and CWMax. By choosing different CWMin and CWMax values, each node may backoff for different time interval.
The third parameter is Transmission opportunity (TXOP). TXOP is an interval of time for which a node can hold the channel after capturing the channel.
Although originally designed for data services, the Internet also supports real-time traffic such as voice and video. Voice over Internet Protocol (VOIP), also known as Internet telephony, IP telephony, or packet voice, enables real-time voice conversations over Internet[4]. It has attracted much interest from academia and industry because of the following facts:
As an extension of DCF, the Enhanced Distributed Channel Access (EDCA) provides a priority scheme to distinguish different traffic categories. Neither DCF nor EDCA is effective or efficient to support delay-sensitive voice traffic. Their contention-based nature and binary exponential backoff mechanism cannot guarantee that a voice packet is successfully delivered within the delay bound.
To meet the strict delay requirement [5] of voice traffic, it should be guaranteed that voice traffic can access the channel successfully during the contention period when needed. EDCA applies different initial and maximum contention window sizes, and different inter frame space values to provide differentiation to different types of traffic. However, it provides only statistically rather than deterministically prioritized access to high-priority traffic such as real-time voice. In other words, prioritized access for high-priority traffic is only guaranteed in the long term, but not for every contention.
In EDCA, since each station continues to count down its backoff timer once the channel becomes idle for an inter frame space, a low-priority packet with a large initial backoff timer will eventually count down its backoff timer to a small value, most likely smaller than the backoff timer of a new backlogged high priority packet. Then the lowpriority packet grabs the channel, resulting in the highpriority packet waiting a long time for the next competition. With such statistically prioritized access it is hard to satisfy the delay requirement of each voice packet. Furthermore, when applying EDCA, with the increase of low-priority traffic loads, the collision probability seen by high-priority traffic increases. Highpriority traffic can suffer performance degradation due to low-priority traffic offering heavy loads.
EDCA technique resets the CW of each station after each successful transmission to CWmin. In case of highly congested channels there is a high probability of collisions. These collisions entail CW into acquiring higher values. Consequently it is more favourable that CW values are accustomed to the channel state therefore getting values distant from CWmin whenever the channel is congested and values close to CWmin whenever the channel is free. Besides, this adaptation scheme should also be relative to CWmax therefore CW should acquire values close to CWmax whenever the channel is congested and values distant from CWmax whenever the channel is free.
Enhancing the EDCA technique [6] to adapt CW values to the channel state has many advantages over original EDCA technique of IEEE 802.11e. Such enhancement will avoid the waste of time (backoff time) since the original EDCA keeps increasing CW to a value that would allow transmission. In this section the proposed modifications to the original IEEE 802.11e reconfigures the parameters of IEEE 802.11e and also dynamically tunes the parameters to favour the voice traffic and video traffic under high congestion conditions.
Initialization
| For Voice and Video: | |
| CW = CWMIN | |
| For Data and Background: | |
| CW = (CWMIN + CWMAX) / 2 |
On Successful transmission
| For Voice and Video: | |
| CW = CWMIN |
For Data and Background:
| CW = CW / 2 |
On Un Successful transmission
For Voice:
| CW = CW + CW * 0.25 |
For Video:
| CW = CW + CW * 0.5 |
For Data and Background:
| CW = 2 * CW |
Protocol evaluations are based on simulation using NS- 2.26. Simulation environment consists of 50 wireless mobile nodes forming an adhoc network, moving about over a 500m X 800m flat space for 100 seconds of simulation time. The physical radio characteristics of each mobile node's network interface, such as the antenna gain, transmit power, and receiver sensitivity, are chosen to approximate the Lucent WaveLAN Direct sequence spread spectrum radio. The adhoc network routing protocol used is Destination Sequenced Distance Vector (DSDV).
Nodes in the simulation move according to a model called “random waypoint” mobility model. The random waypoint model is commonly used mobility model in research community. At every instant, a node randomly chooses a destination and moves towards it with a velocity chosen randomly from [0, V_max], where V_max is the maximum allowable velocity for every mobile node. After reaching the destination, node stops for a duration defined by the pause time parameter. After this duration, it chooses a random destination and repeats the whole process again until the simulation ends.
Among the 50 wireless mobile nodes, four nodes act as traffic sources. All the four nodes generate four kinds of traffic: Voice, Video, Data, and Background traffic. The TXOP limit, for voice and video is 0.3 sec. No traffic bursting is used for data and background traffic. The metrics used are Throughput, Normalized Throughput, Number of Packets Delivered Successfully, and Average End-to-End Delay. Normalized throughput is the number of bytes of data transferred from source to destination divided by the number of bytes of data input into the network.
The simulation is classified in to two cases.
Case 1: Identical packet size and traffic rate are used. The packet sizes used are (1000, 1500, 2000, 2500, 3000, 3500, 4000, 4500, 5000) bytes.
Case 2: The packet size of voice traffic is 160 bytes and of video is 1000 bytes. Rate of transmission of voice is 64Kbps, and of video is 1Mbps. Packet size and rate of transmission of both data and background are 1000 bytes and 1Mbps respectively.
Figures 1 and 2 shows the number of packets delivered successfully by original version and modified version of IEEE 802.11e respectively. In modified version case Voice traffic transmits more number of packets even at higher values of packet size. The number of packets transmitted by voice traffic is almost constant independent of the packet size. The performance of video, data and background traffic is similar in both the cases. The variation of number of packets delivered successfully with time by modified version is shown in Figure 5. Significant difference in performance of Voice traffic is observed and number of packets transmitted by modified version is more than that of original version.
Figure 1. Number of Packets Transmitted by Original Version of IEEE 802.11e
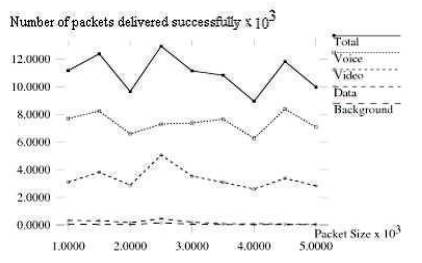
Figure 2. Number of Packets Transmitted by Modified Version of IEEE 802.11e
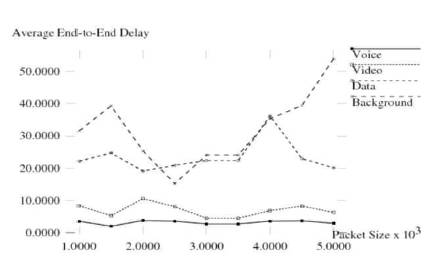
Figure 3. Average End-to-End Delay of Original Version of IEEE 802.11e
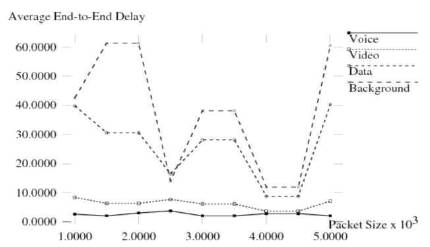
Figure 4 Average End-to-End Delay of Modified Version of IEEE 802.11e
As shown in Figures 3 and 4, significant difference in performance is observed when delay is considered as metric. For voice traffic, modified version of IEEE 802.11e performs far better than the original version. For video, data and background traffic not much difference in performance is observed.
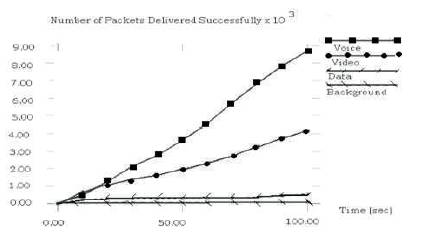
Figure 5 Number of packets delivered successfully by Modified version of IEEE 802.11e
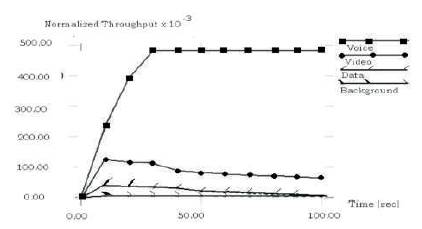
Figure 6 Normalized Throughput of Modified version of IEEE 802.11e
Normalized throughput of modified version is shown in Figure 6. Normalized throughput of original version is shown in Figures 9 and 10. As clearly shown in figures, modified version of IEEE 802.11e performs better. Normalized throughput of voice traffic of modified version is better than voice traffic of original version. Normalized throughput of video traffic is similar in both the cases.
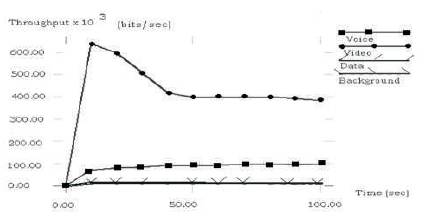
Figure 7. Throughput of Original version of IEEE 802.11e
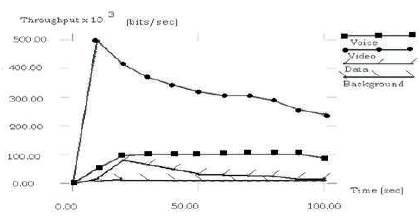
Figure 8. Throughput of Modified version of IEEE 802.11e
As shown in Figures 7 and 8 the throughput of voice in modified version of IEEE 802.11e is uniform and also is more than data and background traffic. The throughput of voice traffic is almost constant. But throughput of video traffic is more than that of voice as the data rate of video is more.

Figure 9 Service Differentiation of IEEE 802.11e with out Contention Free Bursting (Normalized Throughput Vs Time)
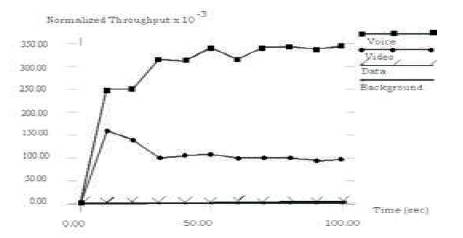
Figure 10 Service Differentiation of IEEE 802.11e with Contention Free Bursting (Normalized Throughput Vs Time)
The proposed modification to changing CW value improves the performance of IEEE 802.11e. Aggregate normalized throughput and also voice throughput of modified version are better than original version. Significant improvement in Average End-to-End delay of voice traffic is observed and modified version performs better.