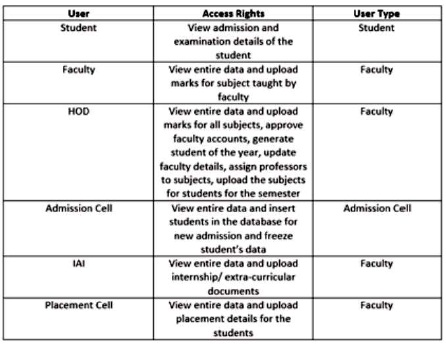
Figure 1. Access control table
With the advent of Information Technology in today's time, there is no dearth of increasing requirements for storing and retrieving data. As the data produced per year increases at an explosive rate, storing this data and representing it in a well-structured format and in a timely manner is one of the biggest issues today for the organizations and institutions. This paper proposes an approach to manage and access large amounts of distributed unstructured data of an organization in an efficient manner. Hence, a web-application has been designed to efficiently access and manage the data and to save precious time spent in accessing the distributed data. This system also makes an attempt to solve the problem of data availability and data accessibility, both of which are very important from an organization's point of view that works with data on a day-to-day basis. Data security for organizations is very important and hence the system also incorporates a security feature with the help of the SSL technology, which will ensure that data transfer remains private and integral over the internet during the client and server communication. Also the paper proposes the methodology which describes the basic features provided by the web-application along with a set of special features that can help reduce effort and provide useful analysis and data visualization based on the data of the organization.
Today, in most of the institutions and organizations, the major problems relating to the maintenance of physically documented data and their storage is becoming more and more cumbersome and labor intensive. Many institutions use physical documents to manually feed in the data. The amount of time and resources spent in creating, storing, and maintaining this physical data is an issue of concern. This major problem relating to physical data can be divided into the following categories,
The crux of the matter is that the data is not available and accessible at all times to the authorized individuals.
Providing a solution to these problems is very important for the organizations and institutions so that they can reduce the time spent on data retrieval, reduce physical effort of the employees of the organization or institutions, reduce or eradicate the human errors involved in manual entries and spend more time on the productive work.
A few decades ago, these problems were considerably difficult to circumvent due to the limited expertise and technological limitations. In today's time, considering the technological advancements in the technological sector, most of these problems can be solved to a great extent. An ERP system can prove to be a solution to the above problems. At the core, this system will integrate, organize, and standardize the data of the organization or institution. The system will be hosted on the internet. As a result, the ERP system will provide the following,
The users can access the data whenever they wish to, simply by authenticating themselves. The users of the system will have different roles. Following are the different users the system consists of,
Since there are many users, each with their user rights hence, they will also have access rights to the system. This is important from a security standpoint. No user will be given full access to the system's data. Figure 1 shows the access rights to the systems data as per the user.
Figure 1. Access control table
Structured Data vs. Unstructured Data
Why did we use unstructured data? What are the problems if we use structured data?
Structured data is a type of data that has a fixed format and follows a predefined structure of storage and predefined data model. The structured type of data is usually stored in Relational Databases (RDBMS) and data warehouses. Data such as phone numbers, Social Security Numbers (SSN), or ZIP codes are stored in the form of length-delineated data. Also string in the form of variables like names are stored in relational databases. This type of data can be human or machine generated. This, wellstructured format of storage makes it very easy to access the data with the help of structured queries also called as SQL queries.
Unstructured data is a type of data that may not have a fixed format and no pre-defined data model. These characteristics of unstructured data allows the different types of data to be stored. These types of data can be text, videos, sound, or other formats. On the other hand, these characteristics make data retrieval and searchdifficult. Unstructured data is typically stored in NoSQL databases, data lakes, and data warehouses. Again this type of data can be human or machine generated. The type of queries that are required to access this data are called unstructured queries or NoSQL type of queries.
Why this project utilizes unstructured form of storage?
Unstructured form of storage is considered for this project for many reasons. The system under consideration requires the following aspects.
The first reason for considering this type of storage is that the considered ERP system requires that the data be retrieved at a quick pace and in an efficient manner. The second reason is that the data format for the system may change over time. So the data may have to adapt to the system requirements in the future. The third reason is that the data may increase in a linear or exponential manner in the near future.
All of these requirements are satisfied by unstructured form of storage. The first requirement of quick retrieval of data is satisfied as the querying is pretty fast and efficient. The second requirement is adaptability. Since the data model is not predefined the change in the storage format or the data model can be incorporated in the system quite easily. The third requirement that is satisfied is scalability. The system that have the ability to handle unstructured data can scale-up. Scaling-up, which is also called vertical scaling involves in deploying faster serves with higher processing speeds and much more memory.
Why would structure prove to be incompatible with the systems requirements?
Due to the very nature of structured data storage, the system requirements will surpass what the data model will be able to provide. Following are a series of reasons why structured form of storage will prove to be incompatible with the system requirements:
Python vs. Java
Why python is better than Java?
Java is a compiled language whereas Python is an interpreted language. Python can perform the same function as of Java in fewer lines. There is not much configuration required for python flask, but any java framework (example: Spring MVC) requires lot of configuration and boilerplate code.
MongoDB support in Java and Python
The MongoDB driver for Java seems to be directly derived from JavaScript, but the usability and efficiency suffers a bit because Java does not have literals for maps/objects like JavaScript does. Whereas python does have literals for maps. Hence python has an advantage over Java for MongoDB.
Python supports efficient meta programming through powerful introspection features that allow programs to inspect and modify code at runtime. Java's introspection is quite poor and inflexible and thus meta programming requires writing preprocessors resulting in increased cost and complexity of implementing the ERP5 system.
Python can be used for both scripting and core development thus reducing complexity and increasing the flexibility of the system, whereas Java can only be used only for core development. With Java, it becomes necessary to provide a separate scripting environment based on different language such as Python or ECMA Script in order to allow flexible configuration at run time by ERP administrators.
The web technologies that are used for the development of the system are HTML, CSS, Bootstrap, and JavaScript along with the python MVC framework Flask.
Following are the reasons for the use of the above mentioned technologies.
The objective of the study is to find a solution to bring the data distributed across organization at one place and provide an ease of access to this data. The data should be easy to visualize and the proposed system should contain access rights similar to those of the current system.
Liu, Du, Li, and Yang (2017) have proposed heterogeneous Learning Resources Integration and Cross-Database Retrieval. An architecture was proposed to integrate multiple databases and provide an access, which is transparent to repositories. Cross database retrieval uses the metadata to integrate the data and achieve interoperability, which is good for querying. The architecture of the system is layered and the design follows principle of modularity and low coupling to achieve good scaling and compatibility. But it does not provide a way of accessing the unified source with a good user interface and does not implement any security standards required for the management of the unified data. The architecture gives the output in standard XML format and the user has read only access and hence cannot interact and update the data.
XML format has some disadvantages, i.e. syntax of XML is verbose and redundant compared to JSON like other textbased data transmission formats.
When the volume of the data becomes large, this redundancy causes higher storage and transportation costs. Compared to JSON like other text-based data transmission formats, XML is less readable and arrays are not supported in XML.
Inglés, Perek, Orlikowski, and Napieralski, (2015) have presented a simple multithreaded C++ framework for high-performance data acquisition system. They explain how the data acquisition or retrieval takes place when realtime monitoring systems are concerned. They contrast many different C++ frameworks, which use the technology of multi-threading and the concept of ringbuffer data structure on basis of the time interval between the moment when the data is produced and the time when the data is collected. Although C++ is a good language as far as simplicity is concerned, it is not very secure, prone to many errors, and is platform dependent. Instead of C++, the data acquisition systems can be implemented in much better languages such as Java or Python which are more secure and robust.
Lee and Zheng (2015) have studied about revitalizing information management systems in Afghan settings through not only SQL (MongoDB) technology.
Gharanai, Gh, and Ahmadi (2016) explained that structured Databases cannot handle huge data efficiently and effectively. Therefore, they propose the use of unstructured database management system namely MongoDB to replace the structured databases and to solve the issue of efficiency. They also gave an overview of MongoDB and explains its various features such, as scaling out, sharding, and replication. Further, the author compares MongoDB and MySQL on the basis of its features and CRUD operations. MongoDB is faster than MySQL since it took only 0.5 seconds to insert 20000 users, whereas MySQL took 880 seconds. They conclude by encouraging developers to use and promote non-relational databases paradigm due to its features such as scalability and availability, which are a must for Big Data Organizations.
Hanine, Bendarag, and Boutkhoum (2016) analyzed the Post-Implementation Evaluation of a University Management Information System (UMIS).
Symeonaki, Papoutsidakis, Tseles, and Sigala (2016) conduct a post-implementation evaluation of a Student Information System at Piraeus University of Applied Sciences based on D&M IS success and Technology Acceptance (TAM) models and Wixom and Todd Framework. A thorough evaluation of the system was conducted by processing and analyzing the research objectives scores, the comment responses, and the respondents' demographic profiles. The concerned Student Information System consists of modules, such as Students Records - Secretariats Management, Student Club, Personnel Management, Financial, and Assets Management, Procurement Management, Electronic Protocol and Workflow Management, and Information subsystem. The data for evaluation of system was collected using questionnaire provided to a small group of users. The parameters used for IS Success model is Information Quality and System Quality and those used for TAM model are Usefulness, Ease of Use Intended use and Experience. They have used Cronbach Alpha technique for reliability analysis and face validation for validation analysis. The outcomes of this research suggest that PUAS and its academic community could be greatly benefitted by the implementation of the Student Information System in terms of strategy planning, distributing resources as well as organizational success. The system improves the provided services to students and minimize their contact with the Secretariats of their Departments.
Babu and Surendran (2017) explain the relational to NoSQL Database Migration. They speak about how relational databases are not able to keep up with the exponential increase in the data storage requirements that can be of the order of terabytes and petabytes. Today most of the data is in semi-structured or unstructured format. With a large variety of data that needs to be stored, there are a lot of challenges to be faced with storing such data, which does not find solution in RDBM systems. The author encourages the use of NoSQL databases and contrasts three NoSQL type databases namely,
The comparisons between these NoSQL databases are based on the following characteristics possessed by each of the databases. Following are the aspects under which the comparisons have been performed.
The author provides the following migration methodologies from RDBMS to NoSQL.
Veen, Waaij, and Meijer (2012) compared Cassandra and MongoDB and proved that MongoDB does perform better than Cassandra when using a single server instance. On the other hand, Cassandra is considered because of its horizontal scalability.
The research work is designed as a web based system to provide high accessibility, remote access, and availability of data.
The web based system uses appropriate access control system for accessing and updating the data on the system. The students can only view their data. The faculty and staff can view data of any student and upload data in accordance with the provided access rights. The faculty teaching a subject can upload the term test marks and practical marks of that subject. The data of newly admitted students, which will contain student's name, caste, category, and other basic details which will be required by institution will be uploaded by admissions cell. The placement cell will upload the student's internship details, certificates, and placement details. The examination department will upload the End Semester exam marks of the student. The different college committee's faculty advisor will upload the list of students that are part of the committee. The account of the faculty is approved by the HoD/respective administrator before the user can login.
The system allows the records of students to be frozen according to the year of admission making the frozen records non-editable by any user. The system is built for educational institutes to move from the traditional approach to an ERP approach with unified system to store and access the data as and when required. The database will store the entire details of the student from admission to the academic data such as student's marks and extracurricular and co-curricular achievements such as internships, member of any organization and committee, any competitions and certificates. The website consists of user friendly layout to read the data and the update of the data is done with the help of Excel sheets, which are converted to .csv formats before storing in the database. The framework used is the flask micro framework with support of Python and Pymongo as the language to access the Mongo DB database used in the application. Python supports the necessary libraries required for the application. The application features the support for storing the data on the cloud with the google drive cloud service. The data supported for cloud storage are pdfs and other necessary documents.
The application provides the user with search of a record based on the name, roll number, and email address of the student. The search requests are fulfilled using AJAX call made to the server and the response is displayed in the format of a table, which is easy for the user to read and distinguish the necessary details. The filters are provided with easy search of the necessary details for the user. The filters are based on department of the student, the current year of the student and the cgpa of the student and others. The application supports printing the data displayed on the web page as a document in user readable format.
The data can be visualized as graphs in form of bar graphs. The data of admissions based on the numbers of admissions in the past five years, the numbers of students in different categories and branches for the current Year can be visualized. The data uploaded in the excel format is dynamic in the way the application is able to map different column names to the required keys in the database.
This is achieved by checking the different supports the column headers with different names than specified, which is searched by the system in the background with the use of permutations and combinations of the desired name in the header. The header is then mapped with the actual header and if no match is found then the uploaded sheets need to be changed in the headers by the user.
An additional feature of the system is that when the data is uploaded in excel format, the pre-defined header strings of the system with be compared to the permutations and combinations entered in the corresponding headers of the excel sheets by the faculty. If a particular header of the excel sheet does not match with the corresponding pre-defined header string of the system for that column of data, then the header of the excel sheet is considered invalid and the faculty will be requested to re-upload the excel sheet. Hence, the faculty will have to provide the valid header name for that column of data and then reupload it. As mentioned above, the new feature of the system is the dynamic headers concept. The dynamic headers will allow the faculty to enter the data without worrying about the format of each column. Flexibility is given to the faculty to enter the data into the excel sheets with respect to the name of the headers as well as those headers in different columns. Refer Figure 2 for the concept of dynamic headers.

Figure 2. Dynamic Headers Algorithm
The new feature of the system is the student of the year. This feature of the application provides the user with a list of students, who have performed excellently throughout the year. This feature works in the following manner.
Figure 3 shows the proposed algorithm for “Student of the year” functionality. The application will also provide a feature to freeze the data of the alumni students. This data of the passed out students also called as alumni students will be frozen. In other words, the data of these types of students will be finalized and no changes to the data will be allowed by any alumni.

Figure 3. Student of the Year Algorithm
From the perspective of security, the system is also implemented with SSL for the web-application to provide trust certificate and end-to-end encryption between the client and server and to prevent man-in-the-middle attacks. It also helps to increase the SEO score of webapplication. We have used Let's Encrypt, a free, automated, and open Certificate Authority (CA) to generate the certificate and private key. Certbot is a Automatic Certificate Management Environment (ACME) client for generating SSL certificate using Let's Encrypt. Let's Encrypt will bind the generated certificate and private key to a domain name. For this web-application, the authors have used AWS EC2 to host the application and freenom.com to get free domain name.
The screenshot of the secure connection to the portal is given in Figure 4.
Figure 4. SSL Secure Connection
The steps to generate certificates using Certbot on AWS EC2 Amazon Linux 2 AMI are as follows,
Prerequisite: Connection to AWS EC2 server using putty or SSH.
sudocertbotcertonly --standalone –d domainname
This section provides the visuals of the system. All the different web pages of the web-application are provided along with their brief descriptions of the functions.
Figure 6 for faculty home page, which renders the unstructured data shown in Figure 5. Unstructured storage helps in storing multiple nested values with ease. It is an extended version of the student home page where the faculty will be able to view the data of all the students in the database as opposed to the student home page, where the student will only be able to view his data and no other student's data. Also, the faculty will be provided with the search option along with the filtering functionality. The filtering functionality with its pre-defined filter strings will allow the faculty to filter out the student data depending upon the requirements. Figure 7 shows the student home page layout. The students after logging in to the application will be directed to their homepage. On the homepage, they will be able to see all the data pertaining to them such as personal details, academic details, extracurricular and co-curricular details in sectional format.
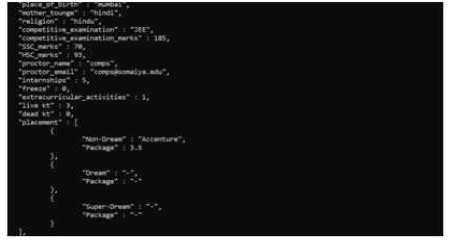
Figure 5. Storing Data in Unstructured Format
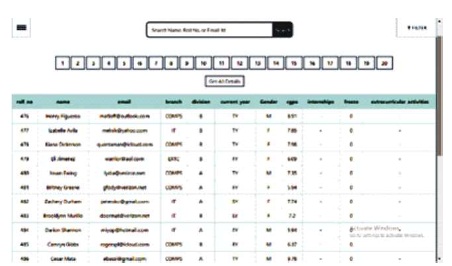
Figure 6. Faculty Home Page

Figure 7. Student Home Page Figure
Figure 9 shows the student examination details. Figure 8 shows the unstructured format for storage of the examination details in the database. Referring to the unstructured data the data is highly nested, which is rendered to a structured format for ease of view to the user.
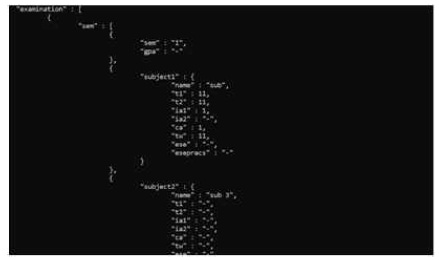
Figure 8. Student Examination Details in Unstructured Format

Figure 9. Student Examination Details Page
The student can click on examination details option in navigation bar to view his/her detailed examination records. The detailed examination records will show the student his/her marks per subject, final GPA per year, and overall cgpa of all his/her semesters.
The graph data will provide the information to the user in the form of data visualization technique, which will be in the form of bar graphs. These bar graphs will provide a representation of the admission data over the past five years. The total admissions for a particular year irrespective of the departments will be represented by a single bar graph.
Figure 10 is an example of graphical view of the students in different categories during a particular admission year. Various other types of graphs have been included in the system for data visualization.
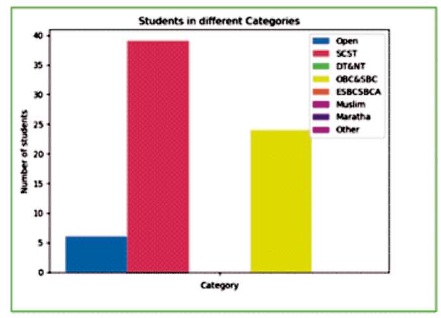
Figure 10. Plot of Students Category Wise
The print table will provide the feature of exporting the current table data into a PDF document. Figure 11 shows a table being saved as pdf format. The page allows to select from saving the document and even sending the request to print the document.
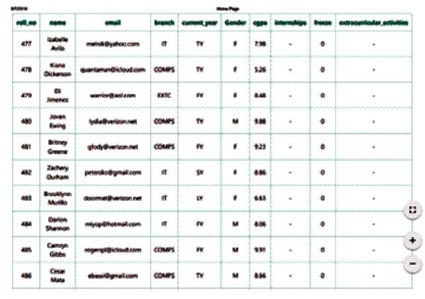
Figure 11. Save as pdf
The design and the different functionalities of the ERP System for this application has proved to be an ideal approach for satisfying requirements for the organizations and educational institutions. The results and outputs generated by the system have successfully solved the data problems such as data availability and data accessibility. The system has also provided the requirements such as speed, efficiency, scalability, and adaptability. Also this system will provide ample room for further advancements of this system in the future. So, a system like this can keep up with the organizational needs and will go a long way in helping the educational institutions in integrating, retrieving and maintaining their student's data.
Currently, the application provides a scalable solution for merging and accessing the distributed data of Educational Institutions remotely. Certain facilities can also be added to make it more useful and efficient.