
Figure 1. Big Data
In the recent research years scientists regularly encounter limitations due to large data sets in many areas. Big data is high-volume, high-velocity and high-variety information assets that demand cost effective, innovative forms of information processing for enhanced insight and decision making and it refers to data volumes in the range of Exabytes (10 ) and beyond. Such volumes exceed the capacity of current on-line storage systems and processing systems. Data, information, and knowledge are being created and collected at a rate, that is rapidly approaching the Exabyte range. But, its creation and aggregation are accelerating and will approach the Zettabyte range within a few years. Data sets grown in size in part because they are increasingly being gathered from ubiquitous information-sensing mobile devices, aerial sensory technologies, software logs, cameras, microphones, Radio- Frequency Identification (RFID) readers, and Wireless Sensor Networks. Big data usually include data sets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process the data within a tolerable elapsed time. Big data sizes are a constantly moving target, as of 2012 ranging from a few dozen Terabytes to many Petabytes of data in a single data set. Big data is difficult to work with using most Relational Database Management Systems and desktop statistics and visualization packages, requiring instead "massively parallel software running on tens, hundreds, or even thousands of servers". This paper analyze the issues and challenges of the recent research activity towards big data concepts.
Big data is an all-encompassing term for any collection of data sets so large and complex that it becomes difficult to process using on-hand data management tools or traditional data processing applications. The challenges include capture, curation, storage, search, sharing, transfer, analysis and visualization. The trend to larger data sets is due to the additional information derivable from analysis of a single large set of related data, as compared to separate smaller sets with the same total amount of data, allowing correlations to be found to "spot business trends, prevent diseases, combat crime and so on" [1].
The world's technological per-capita capacity to store information has roughly doubled every 40 months since the 1980s; as of 2012, every day 2.5 Exabytes (2.5×1018) of data were created. The challenge for large enterprises is determining who should own big data initiatives that straddle the entire organization. If your organization is like many, you're capturing and sharing more data from more sources than ever before. As a result, you are facing the challenge of managing high-volume and high-velocity data streams quickly and analytically. Big Data is all about finding a needle of value in a haystack of unstructured information. Companies are now investing in solutions that interpret consumer behavior, detect fraud, and even predict the future McKinsey released a report in May 2011 stating that, leading companies are using big data analytics to gain competitive advantage. They predict a 60% margin increase for retail companies who are able to harvest the power of big data. To support these new analytics, IT strategies are mushrooming; the newest techniques include brute force assaults on massive information sources, and filtering data through specialized parallel processing and indexing mechanisms. The results are correlated across time and meaning, and often merged with traditional corporate data sources. New data discovery techniques include spectacular visualization tools and interactive semantic query experiences. Knowledge workers, and data scientists sift through filtered data asking one unrelated explorative question after another. As these supporting technologies emerge from graduate research programs into the world of corporate IT, IT strategists, planners, and architects need to understand them both and ensure that they are enterprise grade. Planning Big Data architecture is not about understanding just what is different. It's also about how to integrate what's new to what you already have – from database-and-BI infrastructure to IT tools, and end user applications. Oracle's own product announcements in hardware, software, and new partnerships have been designed to change the economics around Big Data investments and the accessibility of solutions. The real industry challenge is not to think of Big Data as a specialized science project, but rather integrate it into mainstream IT [2]. Figure 1 shows the Big Data.
Figure 1. Big Data
Big data varies depending on the capabilities of the organization managing the set, and on the capabilities of the applications that are traditionally used to process and analyze the data set in its domain. For some organizations, facing hundreds of Gigabytes of data for the first time may trigger a need to reconsider data management options. For others, it may take tens or hundreds of Terabytes before data size becomes a significant consideration. In 2001 research report and related lectures, META Group (now Gartner) analyst Doug Laney defined data growth challenges and opportunities as being three-dimensional, i.e. increasing volume (amount of data), velocity (speed of data in and out), and variety (range of data types and sources). Gartner, and now much of the industry, continue to use this "3Vs" model for describing big data. In 2012, Gartner updated its definition as follows: "Big data is high volume, high velocity, and/or high variety information assets that require new forms of processing to enable enhanced decision making, insight discover y and process optimization”. Additionally, a new V "Veracity" is added by some organizations to describe it.
If Gartner's definition (the 3Vs) is still widely used, the growing maturity of the concept fosters a more sound difference between big data and Business Intelligence, regarding data and their use [3] [4]:
Big data can also be defined as "Big data is a large volume unstructured data which cannot be handled by standard database management systems like DBMS, RDBMS or ORDBMS".
Data volume measures the amount of data available to an organization, which does not necessarily have to own all of it as long as it can access it. As data volume increases, the value of different data records will decrease in proportion to age, type, richness, and quantity among other factors.
Data velocity measures the speed of data creation, streaming, and aggregation. E-Commerce has rapidly increased the speed and richness of data used for different business transactions. Data velocity management is much more than a bandwidth issue; it is also an ingest issue.
Data variety is a measure of the richness of the data representation – text, images video, audio, etc. From an analytic perspective, it is probably the biggest obstacle to effectively use large volumes of data. Incompatible data formats, non-aligned data structures, and inconsistent data semantics represents significant challenges that can lead to analytic sprawl.
Data value measures the usefulness of data in making decisions. It has been noted that “the purpose of computing is insight, not numbers”. Data science is exploratory and useful in getting to know the data, but “analytic science” encompasses the predictive power of big data.
Complexity measures the degree of interconnectedness (possibly very large) and interdependence in big data structures such that a small change (or combination of small changes) in one or a few elements can yield very large changes or a small change that ripple across or cascade through the system and substantially affect its behavior, or no change at all.
The Large Hadron Collider experiments represent about 150 million sensors delivering data 40 million times per second. There are nearly 600 million collisions per second. After filtering and refraining from recording more than 99.999% of these streams, there are 100 collisions of interest per second [5].
The Square Kilometer Array is a telescope, which consists of millions of antennas and is expected to be operational by 2024. Collectively, these antennas are expected to gather 14 Exabytes and store one Petabyte per day. It is considered to be one of the most ambitious scientific projects ever undertaken [6].
Mastering Big Data of CFO Strategies to Transform Insight into Opportunity from Oracle and FSN (2012). The various big gaps of knowledge in the field of Internet from Snijders, et al. (2012). The various big data challenge involves more than just managing volumes of data from Beyer et al. (2011). The importance of Big Data concepts fom Laney et al. (2012). The current big data deal from Kalil et al (2012). The various defense big data across the Federal Government from White House., USA (2012). The various story of how big data analytics helped Obama win from Lampitt et al. (2014). The current leading priorities for big data for business and it. E-Marketer from (2014). The various big data for development in Information to Knowledge Societies from Martin Hilbert et al. (2013). "NSF Leads Federal Efforts In Big Data" from National Science Foundation (2012). The current 'Big Data' Researchers Turn to Google to Beat the Markets from Warner (2013). "Manufacturing: Big Data Benefits and Challenges from TCS Mumbai, India (2014)”, by Graham M. (9 March 2012). Big data and the end of theory from Graham (2012). The age of big data from Lohr (2012).
It is helpful to look at the characteristics of the big data along certain lines — for example, how the data is collected, analyzed, and processed. Once the data is classified, it can be matched with the appropriate big data pattern: Figure 2 depicts the various categories for classifying big data. Key categories for defining big data patterns have been identified and highlighted in the future research. Big data patterns, are derived from a combination of these categories [7].
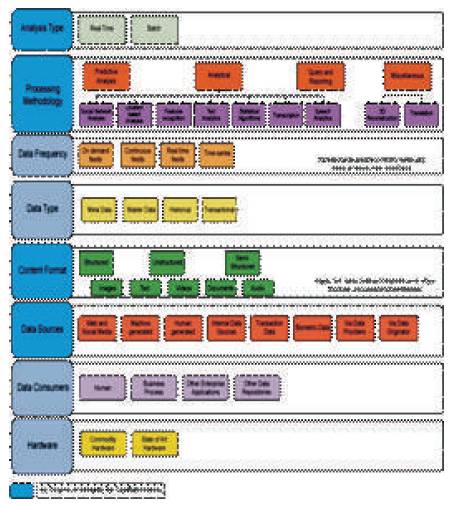
Figure 2. Big Data Classification
Whether the data is analyzed in real time or batched for later analysis. Give careful consideration to choosing the analysis type, since it affects several other decisions about products, tools, hardware, data sources, and expected data frequency. A mix of both types may be required by the use case:
The type of technique to be applied for processing data (e.g., predictive, analytical, ad-hoc query, and reporting). Business requirements determine the appropriate processing methodology. A combination of techniques can be used. The choice of processing methodology helps identify the appropriate tools and techniques to be used in your big data solution.
How much data is expected and at what frequency does it arrive. Knowing frequency and size helps determine the storage mechanism, storage format, and the necessary preprocessing tools. Data frequency and size depend on data sources:
Type of data to be processed; transactional, historical, master data, and others. Knowing the data type helps segregate the data in storage.
Format of incoming data; structured (RDMBS, for example), unstructured (audio, video, and images, for example), or semi-structured. Format determines how the incoming data needs to be processed and is key to choose the tools and techniques as well as defining a solution from a business perspective.
Sources of data (where the data is generated); web and social media, machine-generated, human-generated, etc. Identifying all the data sources helps determine the scope from a business perspective. Figure 2 shows the most widely used data sources.
A list of all of the possible consumers of the processed data are,
The type of hardware on which the big data solution will be implemented; commodity hardware or state of the art. Understanding the limitations of hardware helps inform the choice of big data solution [8].
Big data require exceptional technologies to efficiently process large quantities of data within tolerable elapsed times. A 2011 McKinsey report suggests suitable technologies include A/B testing, crowd sourcing, data fusion and integration, genetic algorithms, machine learning, natural language processing, signal processing, simulation, time series analysis and visualization. Multidimensional big data can also be represented as tensors, which can be more efficiently handled by tensor based computation, such as multilinear subspace learning. Additional technologies being applied to big data include Massively Parallel-Processing (MPP) databases, search-based applications, data-mining grids, distributed file systems, distributed databases, cloud based infrastructure (applications, storage and computing resources) and the Internet.
Some but not all MPP relational databases have the ability to store and manage Petabytes of data. Implicit is the ability to load, monitor, back up, and optimize the use of the large data tables in the RDBMS. DARPA's Topological Data Analysis program seeks the fundamental structure of massive data sets and in 2008 the technology went public with the launch of a company called Ayasdi.
The practitioners of big data analytics processes are generally hostile to slower shared storage, preferring Direct-Attached Storage (DAS) in its various forms from Solid State Drive (SSD) to high capacity SATA disk buried inside parallel processing nodes. The perception of shared storage architectures Storage Area Network (SAN) and Network-Attached Storage (NAS) is that they are relatively slow, complex, and expensive. These qualities are not consistent with big data analytics systems that thrive on system performance, commodity infrastructure, and low cost. Real or near-real time information delivery is one of the defining characteristics of big data analytics. Latency is therefore avoided whenever and wherever possible. Data in memory is good data on spinning disk at the other end of a FC connection is not. The cost of a SAN at the scale needed for analytics applications is very much higher than other storage techniques [9].
Many datasets have certain levels of heterogeneity in type, structure, semantics, organization, granularity, and accessibility. Data representation aims to make data more meaningful for computer analysis and user interpretation. Nevertheless, an improper data representation will reduce the value of the original data and may even obstruct effective data analysis. Efficient data representation shall reflect data structure, class, and type, as well as integrated technologies, so as to enable efficient operations on different datasets.
Generally, there is a high level of redundancy in datasets. Redundancy reduction and data compression is effective to reduce the indirect cost of the entire system on the premise that the potential values of the data are not affected. For example, most data generated by sensor networks are highly redundant, which may be filtered and compressed at orders of magnitude.
Compared with the relatively slow advances of storage systems, pervasive sensing and computing is generating data at unprecedented rates and scales. Confronted with a lot of pressing challenges, the current storage system could not support such massive data. Generally speaking, values hidden in big data depend on data freshness. Therefore, a data importance principle related to the analytical value should be developed to decide which data shall be stored and which data shall be discarded.
The analytical system of big data shall process masses of heterogeneous data within a limited time. However, traditional RDBMSs are strictly designed with a lack of scalability and expandability, which could not meet the performance requirements. Non-relational databases have shown their unique advantages in the processing of unstructured data and started to become mainstream in the big data analysis. Even so, there are still some problems of non-relational databases in their performance and particular applications. A compromising solution can be found between RDBMSs and non-relational databases. For example, some enterprises have utilized a mixed database architecture that integrates the advantages of both types of database (e.g., Facebook and Taobao). More research is needed for the in-memory database and sample data based on approximate analysis.
Most big data service providers or owners at present could not effectively maintain and analyze such huge datasets because of their limited capacity. They must rely on professionals or tools to analyze such data, which increase the potential safety risks. For example, the transactional dataset generally includes a set of complete operating data to drive key business processes. Such data contains details of the lowest granularity and some sensitive information such as credit card numbers. Therefore, analysis of big data may be delivered to a third party for processing only when proper preventive measures are taken to protect such sensitive data, to ensure its safety.
The energy consumption of mainframe computing systems has drawn much attention from both economy and environment perspectives. With the increase of data volume and analytical demands, the processing, storage, and transmission of big data will inevitably consume more and more electric energy. Therefore, system-level power consumption control and management mechanism shall be established for big data while the expandability and accessibility are ensured.
The analytical system of big data must support present and future datasets. The analytical algorithm must be able to process increasingly expanding and more complex datasets.
Analysis of big data is an interdisciplinary research, which requires experts in different fields cooperate to harvest the potential of big data. Comprehensive big data network architecture must be established to help scientists and engineers in various fields to access different kinds of data and fully utilize their expertise, so as to cooperate to complete the analytical objectives.
Here are a few general guidelines to build a successful big data architecture foundation [10]:
The key intent of Big Data is to find hidden value - value through intelligent filtering of low-density and high volumes of data. As an architect, be prepared to advise your business on how to apply big data techniques to accomplish their goals. For example, understand how to filter weblogs to understand ecommerce behavior, derive sentiment from social media and customer support interactions, understand statistical correlation methods and their relevance for customer, product, manufacturing, or engineering data. Even though Big Data is a newer IT frontier and there is an obvious excitement to master something new, it is important to base new investments in skills, organization, or infrastructure with a strong business driven context to guarantee ongoing project investments and funding. To know if you are on the right track, ask yourself, how does it support and enable your business architecture and top IT priorities?
McKinsey Global Institute wrote that one of the biggest obstacles for big data is the skills shortage. With the accelerated adoption of deep analytical techniques, a 60% shortfall is predicted by 2018. You can mitigate this risk by ensuring that Big Data Technologies, considerations, and decisions are added to your IT governance program. Standardizing your approach will allow you to manage your costs and best leverage your resources. Another strategy to consider is to implement appliances that would provide you with a jumpstart and quicker time to value as you grow your in-house expertise.
Use a Center of Excellence (CoE) to share solution knowledge, planning artifacts, oversight, and management communications for projects. Whether big data is a new or expanding investment, the soft and hard costs can be an investment shared across the enterprise.
Another benefit from the CoE approach is that, it will continue to drive the big data and overall information architecture maturity in a more structured and systematic way.
It is certainly valuable to analyze Big Data on its own. However, by connecting high density Big Data to the structured data you are already collecting can bring even greater clarity. For example, there is a difference in distinguishing all sentiment from that of only your best customers. Whether you are capturing customer, product, equipment, or environmental Big Data, an appropriate goal is to add more relevant data points to your core master and analytical summaries and lead yourself to better conclusions. For these reasons, many see Big Data as an integral extension of the existing business intelligence and data warehousing platform. Keep in mind that the Big Data analytical processes and models can be human and machine based. The Big Data analytical capabilities include statistics, spatial, semantics, interactive discovery, and visualization. They enable your knowledge workers and new analytical models to correlate different types and sources of data, to make associations, and to make meaningful discoveries. But all in all, consider Big Data both a preprocessor and post-processor of related transactional data, and leverage your prior investments in infrastructure, platform, BI and DW.
Discovering meaning in your data is not always straightforward. Sometimes, we don't even know what we are looking for initially. That's completely expected. Management and IT needs to support this “lack of direction” or “lack of clear requirement.” So, to accommodate the interactive exploration of data and the experimentation of statistical algorithms, high performance work areas are in need. Be sure that 'sandbox' environments have the power they need and are properly governed.
Big Data processes and users require access to a broad array of resources for both iterative experimentation and running production jobs. Data across the data realms (transactions, master data, reference, summarized) is part of a Big Data solution. Analytical sandboxes should be created on-demand and resource management needs to have a control of the entire data flow, from preprocessing, integration, in-database summarization, post-processing, and analytical modeling. A well planned private and public cloud provisioning and security strategy plays an integral role in supporting these changing requirements.
Research on the effective usage of information and communication technologies for development (also known as ICT4D) suggests that big data technology can make important contributions but also present unique challenges to International development. Advancements in big data analysis offer cost-effective opportunities to improve decision-making in critical development areas such as health care, employment, economic productivity, crime, security, and natural disaster and resource management. However, longstanding challenges for developing regions such as inadequate technological infrastructure and economic and human resource scarcity exacerbate existing concerns with big data such as privacy, imperfect methodology, and interoperability issues.
Big data has increased the demand of information management specialists in which, Software AG, Oracle Corporation, IBM, , Microsoft, SAP, EMC, HP and Dell have spent more than $15 billion on software firms only specializing in data management and analytics. In 2010, this industry on its own was worth more than $100 billion and was growing at almost 10 percent a year: about twice as fast as the software business as a whole. Developed economies make increasing use of dataintensive technologies. There are 4.6 billion mobilephone subscriptions worldwide and there are between 1 billion and 2 billion people accessing the internet. Between 1990 and 2005, more than 1 billion people worldwide entered the middle class which means more and more people who gain money will become more literate which in turn leads to information growth. The world's effective capacity to exchange information through telecommunication networks was 281 in 1986, 471 Petabytes in 1993, 2. 2 Exabytes in 2000, 65 Exabytes in 2007 [8], and it is predicted that the amount of traffic flowing over the internet will reach 667 Exabytes annually by 2014. It is estimated that, one third of the globally stored information is in the form of alphanumeric text and still image data, which is the format most useful for most big data applications. This also shows the potential of yet unused data (i.e. in the form of video and audio content).
Encrypted search and cluster formation in big data was demonstrated in March 2014 at the American Society of Engineering Education. Gautam Siwach engaged at Tackling the challenges of Big Data by MIT Computer Science and Artificial Intelligence Laboratory and Dr. Amir Esmailpour at UNH Research Group investigated the key features of big data as formation of clusters and their interconnections. They focused on the security of big data and the actual orientation of the term towards the presence of different type of data in an encrypted form at cloud interface by providing the raw definitions and real time examples within the technology. Moreover, they proposed an approach for identifying the encoding technique to advance towards an expedited search over encrypted text leading to the security enhancements in big data [15].
In March 2012, The White House announced a national "Big Data Initiative" that consisted of six Federal departments and agencies committing more than $200 million to big data research projects [16].
The initiative included a National Science Foundation "Expeditions in Computing" grant of $10 million over 5 years to the AMPLab at the University of California, Berkeley. The AMPLab also received funds from DARPA, and over a dozen industrial sponsors and uses big data to attack a wide range of problems from predicting traffic congestion to fighting cancer.
The White House Big Data Initiative also included a commitment by the Department of Energy to provide $25 million in funding over 5 years to establish the Scalable Data Management, Analysis and Visualization (SDAV) Institute, led by the Energy Department's Lawrence Berkeley National Laboratory. The SDAV Institute aims to bring together the expertise of six National Laboratories and seven Universities to develop new tools to help scientists manage and visualize data on the Department's supercomputers.
The U.S. state of Massachusetts announced the Massachusetts Big Data Initiative in May 2012, which provides funding from the State Government and private companies to a variety of research institutions. The Massachusetts Institute of Technology hosts the Intel Science and Technology Center for Big Data in the MIT Computer Science and Artificial Intelligence Laboratory, combining government, corporate, and institutional funding and research efforts [18]. The European Commission is funding the 2-year-long Big Data Public Private Forum through their Seventh Framework Program to engage companies, academics and other stakeholders in discussing big data issues. The project aims to define a strategy in terms of research and innovation to guide supporting actions from the European Commission in the successful implementation of the big data economy. Outcomes of this project will be used as input for Horizon 2020, their next framework program.
The British government announced in March 2014 the founding of the Alan Turing Institute, named after the computer pioneer and code-breaker, which will focus on new ways of collecting and analysing large sets of data [17].
At the University of Waterloo Stratford Campus, Canadian Open Data Experience (CODE) Inspiration Day, it was demonstrated how using data visualization techniques can increase the understanding and appeal of big data sets in order to communicate a story to the world.
In order to make manufacturing more competitive in the United States (and globe), there is a need to integrate more American ingenuity and innovation into manufacturing ; Therefore, National Science Foundation has granted the Industry University cooperative research center for Intelligent Maintenance Systems (IMS) at University of Cincinnati to focus on developing advanced predictive tools and techniques to be applicable in a big data environment. In May 2013, IMS Center held an industry advisory board meeting focusing on big data where presenters from various industrial companies discussed their concerns, issues and future goals in Big Data environment.
Computational social sciences — Anyone can use Application Programming Interfaces (APIs) provided by Big Data holders, such as Google and Twitter, to do research in the social and behavioral sciences. Often these APIs are provided for free. Google Trends data to demonstrate that Internet users from countries with a higher per capita Gross Domestic Product (GDP) are more likely to search for information about the future than information about the past. The findings suggest there may be a link between online behaviour and real-world economic indicators. The authors of the study examined Google queries logs made by ratio of the volume of searches for the coming year ('2011') to the volume of searches for the previous year ('2009'), which they call the 'future orientation index'. They compared the future orientation index to the per capita GDP of each country and found a strong tendency for countries in which Google users enquire more about the future to exhibit a higher GDP. The results hint that there may potentially be a relationship between the economic success of a country and the information-seeking behavior of its citizens captured in big data.
Tobias Preis and his colleagues Helen Susannah Moat and H. Eugene Stanley introduced a method to identify online precursors for stock market moves, using trading strategies based on search volume data provided by Google Trends. Their analysis of Google search volume for 98 terms of varying financial relevance, published in scientific reports, suggests that increases in search volume for financially relevant search terms tend to precede large losses in financial markets.
Big data is the “new” business and social science frontier. The amount of information and knowledge that can be extracted from the digital universe is continuing to expand as users come up with new ways to massage and process data. Big data refers to large datasets that are challenging to store, search, share, visualize, and analyze. At first glance, the orders of magnitude outstrip conventional data processing and the largest of data warehouses. Big Data analysts and research organizations have made it clear that mining machine generated data is essential to future success. Compare again to a conventional structured corporate data warehouse that is sized in Terabytes and Petabytes. Big Data is sized in Peta-byte, Exa-byte, and soon perhaps, Zetta-bytes! And, it's not just about volume, the approach to analysis contends with data content and structure that cannot be anticipated or predicted. These analytics and the science behind them filter low value or low-density data to reveal high value or high-density data. As a result, new and often proprietary analytical techniques are required. Embracing new technologies and techniques are always challenging, but as architects, you are expected to provide a fast, reliable path to business adoption. As you explore the what's new across the spectrum of Big Data capabilities, one can contemplate about their integration into your existing infrastructure. In this paper, current research has reviewed on the big data concept, big data model, big data technology, big science and research and big data current research activities.