
Table 1. Checklist for Enabling Greater Comprehensiveness and Comparability Among Different Validators' Arguments Based on the Same Test and Same Test Scores
This study compares the psychometric properties of reliability in Classical Test Theory (CTT), item information in Item Response Theory (IRT), and validation from the perspective of modern validity theory for the purpose of bringing attention to potential issues that might exist when testing organizations use both test theories in the same testing administration. It was found that reliability, instead of using corrected item-total test score correlations, and item information functions are similar and their conjoint use should be compartmentalized in the processes of test assembly, pre-testing, and scoring. For validity, only minor differences attributable to scoring processes are conceivable, but the main problem is that too much subjectivity by way of different arguments being constructed using the same test and test scores engenders a lack of consensus in the meaning of arguments. A checklist is presented for consideration by test validators that will produce greater consensus of arguments by improving argument comprehensiveness.
Testing in an educational system depends on a number of functions. The results of these tests can be used to make essential decisions in education. It is well known in education literature that, testing is a vital element of education. To utilize effectively the tests in educational policies and quality assurance its validity and reliability estimates are necessary. There are generally two acceptable frameworks used in assessing the quality of tests in educational and psychological measurements, these are; Classical Test Theory (CTT) and Item Response Theory (IRT).
Not only are Classical Test Theory (CTT) and Item Response Theory (IRT) used separately in test development, test analysis, and reporting of test scores, but of late these two test theories are used together in the same test administration. Because only limited attention has been paid to comparing reliability in CTT and information in IRT (Fan, 1998) for an empirical comparison of item and test score statistics for these two measurement theories, it is important for those conducting reliability and validity studies to understand how these test characteristics differ in terms of underlying psychometric properties. Furthermore, the measurement literature contains explanations of how these test characteristics are each derived in CTT and IRT as well as the theoretical relationship between the theories (MacDonald, 1999), these explanations have not kept pace with practice when both theories are used in the same testing administration.
The major distinction between CTT and IRT is that for IRT the existence of invariant item parameters and sample free estimates of ability serve as the basis for characterizing what is referred to as item and test information. With CTT it is reliability rather than test information that is captured. With CTT, examinee ability and test difficulty are confounded so reliability has only one value for the test based on the totality of the test's true score variance. In contrast, with the iterative estimation processes of IRT, item and test information are obtained at different levels of examinee ability. Yet, there is a coefficient in CTT called the Conditional Standard Error of Measurement (CSEM) originally conceived by Mollenkopf (1949) and an IRT estimation procedure for it developed by Hambleton and Swaminathan (1985). The CSEM, can function in a manner similar to the Test Information Function (TIF) (Fan, 1998).
In comparing validity in CTT and IRT, the evolving nature of the concept of validity reached a point that differences in defining validation transcended these two theories (Angoff, 1988). Earlier literature on validity in CTT consisted of item discrimination indices, the use of expert judgment for assessing content validity, correlations of test scores with external criteria and factor analysis. More recent conceptions of validity, which can be applied to both CTT and IRT stem from the works of Cronbach (1971), Messick (1989), and Kane (2006) all who address the validity of interpretations of test scores. For this modern-day approach, validation is an interpretive argument (Kane, 2006, 2013). Criticism of this modern-day approach has recently been put forth by Borsboom, Cramer, Kievit, Scholten, and Franic (2009) stating that by focusing so much attention on interpretations of test results, we are taking attention away from the test we are validating. It is expected that considerably small differences exist for validation of test score interpretations between validity conceptions in CTT and IRT. For both test theories, validation is an ongoing process for the marshalling of evidence to support claims regarding the interpretation of test scores (Messick, 1975). The exceptions are that different metrics are used for characterizing ability and that test scores to be interpreted likely differ due to whether CTT or IRT procedures are used for equating, item analysis Differential Item Functioning (DIF), and even standard setting.
A number of testing programs around the world have begun to use both CTT and IRT for the same test administration in test construction, scoring, item and test analysis, scaling, equating, and reporting of scores. In addition, a number of textbooks and articles delve into definitions of reliability, test information, and validation in these separate theories. Reliability in CTT is derivable from three alternative test administration designs: test-retest, parallel forms, and internal consistency, the latter of which is most popularly used for purposes of convenience as in the case of Cronbach's (1951) alpha coefficient, which is equivalent to the average of all possible split-half correlations. This quantity reduces to 1 – (error variance) / (total variance) based on assumptions about true scores. It should be noted that internal consistency in CTT is not considered to be reliable by all psychometricians (Rogosa & Ghandour, 1991). With IRT, the most comparable concept to classical reliability is the test information function. One goal in this study is to isolate common elements of reliability in CTT and test information in IRT for single test administrations so that consumers of these seemingly disparate test characteristics, with typical working knowledge of their basic differences, can benefit from acquiring a greater appreciation for how these measurement models undergird their concurrent use.
Although less complex than comparisons of reliability and test information, a comparison of validation processes in CTT and IRT represents the second goal of the study-illuminating distinctions in CTT and IRT conceptualizations of validation.
According to Biddle (2006), the computation and subsequent use of the SEM should be restricted unless there is consistency of error variance throughout the score range.
Instead, the CSEM, which more accurately reflects the precision of variation throughout the score range, has greater sensitivity as a test statistic partly due to its similarity to the IRT test information function.
The estimation of the CSEM and the item information function are derived using different psychometric procedures. Although there may be some degree of similar sensitivity, the CSEM and TIF provide qualitatively different measurements. However, through using slope intercept parameterization methods one can derive item parameter and ability estimates in IRT from CTT item statistics.
While it would first appear that since arguments and interpretations of test score data serve as the basis for validation, there are differences in how scores are interpreted when using these two measurement theories separately and in combination. If the scaling method used to produce the scores is different, then the scores that are subject to interpretation may necessarily be different. Furthermore, since validity arguments for the interpretation of test score data can vary depending on the background, capability and judgment of the individual validator, modern day validation approaches may not only suffer from too much subjectivity but also from an open-endedness in the absence of consensus among validators with respect to a presented argument.
A set of guidelines are proposed in the form of a checklist, not intended for standardizing validation arguments thereby diminishing the value of uniquely developed arguments, but for facilitating more comprehensive arguments by availing validators with a list of some of the more primary, and secondary elements of what should preferably be included as part of validation argument. Table 1 presents the list of recommended elements for validators to consider in developing validation arguments.
Table 1. Checklist for Enabling Greater Comprehensiveness and Comparability Among Different Validators' Arguments Based on the Same Test and Same Test Scores
By attempting to initiate the development of an exhaustive listing of sound validation practices for argumentation, greater consensus among individual validators who use the same test scores and the same test is more likely to be achieved, while at the same time promoting the comprehensiveness of arguments and preserving the meaningfulness of those individual validators' arguments. The checklist in Table 1 is still under development and is presented as a tool for use by measurement practitioners to aid in avoiding divergent arguments.
Since both test theories serve as concurrent foundations for operational testing, it is very important to determine how reliability and validity are viewed with these theories both as separate models and with concurrent use. A number of textbooks and articles delve into definitions of reliability and validity in these separate theories but little, if any, attention has been paid to comparing these two psychometric concepts in CTT and IRT. In a sense, the literature has offered definitions of the concepts but this has not kept pace with practice when both theories are used in the same operational administration. With IRT, the most comparable concept to classical reliability is the test information function. One of the goals of this paper was to isolate a commonality between these two concepts for single test administrations: CTT reliability and IRT test information.
Using a disclosed form of the Graduate Record Examinations (GRE) General Test, Quantitative Reasoning section, consisting of 40 items from a dataset containing n=5502 examinees, IRTPRO was used for estimating item and ability parameters after first checking on dimensionality and local independence assumptions. Because the assumptions were not satisfied, a bi-factor model was estimated. For CTT, alpha reliability, and CSEMs were computed, when possible. However, only a limited number of CSEMs were able to be reported, such comparative analyses of CTT and item information functions were excluded.
In comparing CTT reliability and IRT test information, different procedures were employed in reconstructing the form based on the same item and test statistics from the two theories, which was accompanied by the inclusion of different sets of items selected from the GRE Quantitative Reasoning section. Classical item and test statistics computed on the entire disclosed GRE form (e.g., reliability and CSEMs), and IRT item and test information functions were separately used in reconstructing and comparing two forms using CTT and IRT, respectively. Relatively minor variations can typically be found among Cronbach reliability coefficients for the same test, due to the practice of excluding item scores when calculated item-total test correlations are corrected. Accordingly, corrected item- total test score correlations were used in comparisons with IRT item information functions.
From the resultant test scores produced with CTT and IRT, validity interpretations and the related arguments underwent the process of “framing” for the same particular use to determine if qualitatively different interpretations and arguments existed among different validators. Since test scores were used to predict success in graduate school, the validity of score interpretation and how they were set up in validity arguments rested with how well the GRE Quantitative Reasoning Test was able to predict student success (Zwick, 2018). No follow-up study could feasibly be conducted in this study because the lag in time between predictor and criterion measures. However, the test score interpretations using CTT and IRT as well as the processes involved in framing these interpretations and arguments are planned for study through within-validator comparisons (same validator using CTT score data and IRT score data, respectively) and between-validator comparisons (two different validators using CTT score data only and two different validators using IRT score data only). For the latter set of comparisons, one validator in each of the pairs of two validators in this proposed design is to use the checklist in Table 1, which lists the elements for a comprehensive validation argument while the other validator in each pair is not planned to use the checklist.
Because of the usual expected open-ended nature of validation arguments in general, there is an unsurmountable difficulty in assessing differences between arguments. Therefore, since the complications involved in clearly measuring argument similarity, we thought we could introduce a similar design but with greater parsimony using less restricted quasi-experimental control by instead attempting to assess expected larger expected differences in validation arguments. Because qualitatively different comparisons would not be subjected to statistical hypothesis testing anyway, only using a simple objective metric, it does not matter if highly similar comprehensive arguments or highly dissimilar arguments were chosen.
The standardized Cronbach (1951) alpha reliability for the 40-item test was 0.874. Based on Lord's Method IV for computing the CSEM as also described by Cowell (1991), CSEMs were computed for a small number of right score. Table 2 presents for each of the 40 items the “corrected” item-total test score correlation. The set of figures in Figure 1 contain Item Information Functions (IIFs) overlaid with Item Characteristic Curves (ICCs) one for each of the 40 items. Figure 2 contains an overlay plot of the Test Characteristic Curve and the Test Information Function.
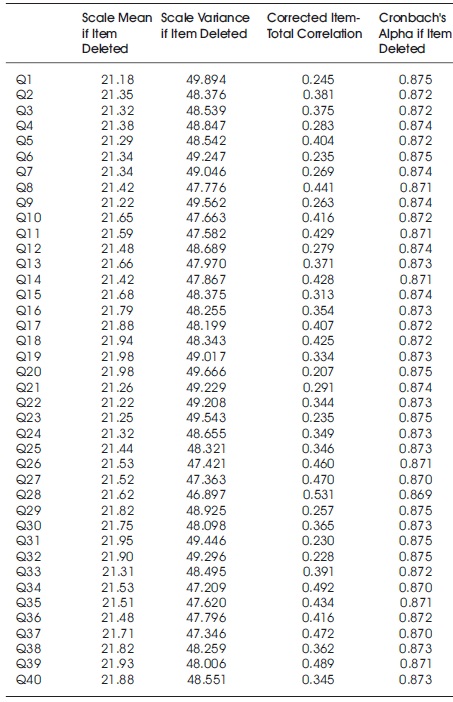
Table 2. Item Statistics for GRE 40 Item Test Including Corrected Item-Total Test Correlations and Cronbach Alpha Reliabilities
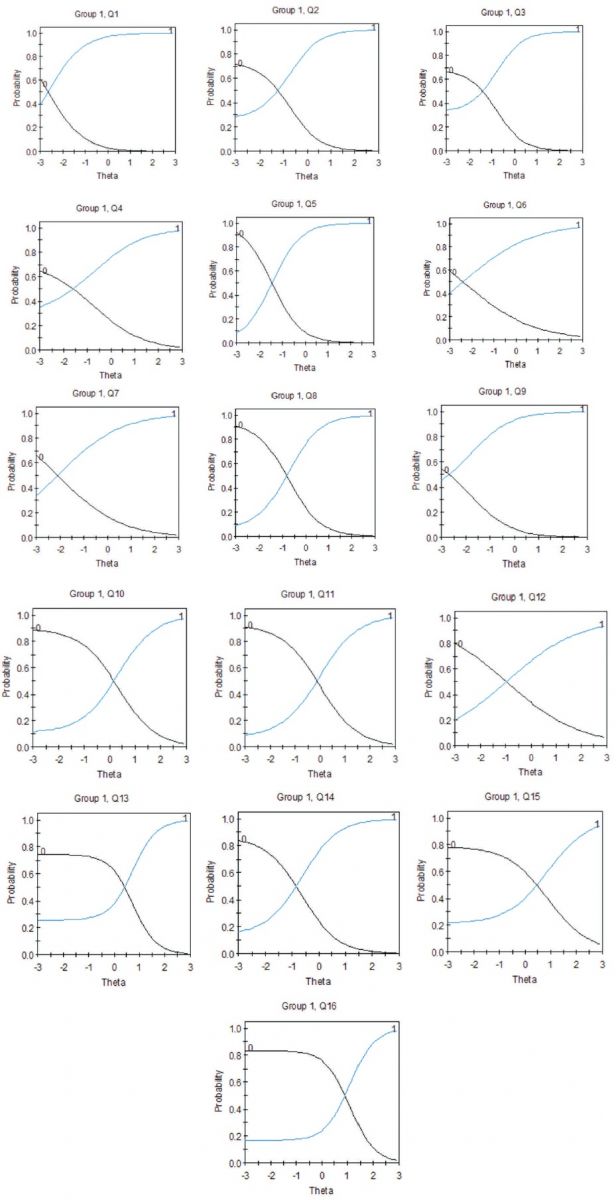
Figure 1. Graphs of ICCs and IRFs for the 40 GRE Math Items
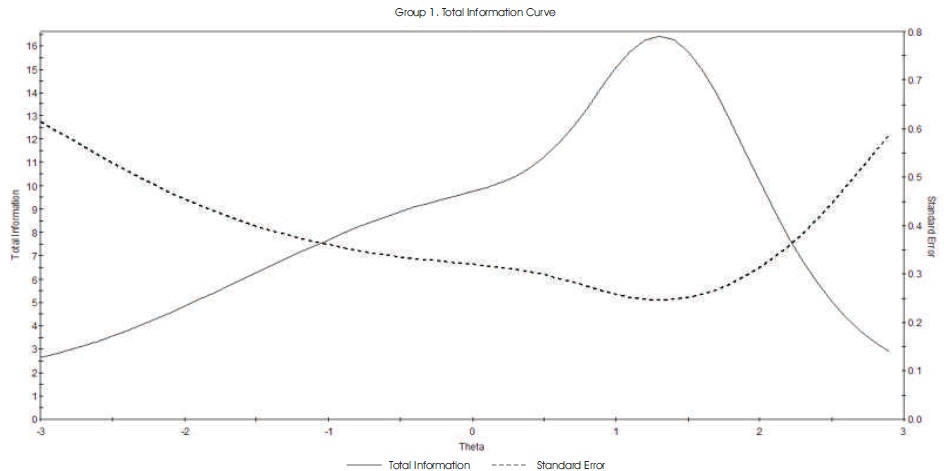
Figure 2. Graph of Test Information Function with Standard Errors
As can be seen in Figure 1, Items Q1 – Q4, the items at the beginning of the test are expected to be easy items and therefore the item information functions for these items provide little information over most of the range of theta; some information is provided at low levels of ability. The same item information plots are characteristic of item 23 and item 24. In contrast, item 19 has an information function substantially covering the range of ability, theta. In comparison, there is what can be called a generally similar trend as the IIFs. However, only a weak relationship can be inferred from comparing item-total test correlations and IIFs. While there is some similarity in terms of magnitude for these respective CTT and IRT item statistics, relying on one of these statistics as a proxy for the other would be a big mistake as the similarity is hardly precise.
As for validation, interpretations of CTT and IRT test scores were framed according to a more well-defined process than currently exists in the measurement literature.
Toulmin (1958) and House (1980) works served as the basis for theorizing about validity arguments, which Kane (2013) describes as interpretive arguments, the authors have presented a design for demonstrating that the actual framing of test score interpretations for actual item and test score data producing open-ended, independent arguments can result in greater validation argument consensus with the use of a checklist of elements for similar validation argument created by fostering greater comprehensiveness among arguments.
The estimates of test item validity and reliability depend on a particular measurement model used. It is vital for a test developer to be familiar with the different test development and item analysis methods in order to interpret the results of the tests appropriately and fairly.
The study demonstrates that different test outcomes result when using CTT and IRT with respect to reliability, information, and validity. The implications are that testing programs need to find ways to equate and report scores in a fair and equitable manner when switching from CTT to IRT or vice versa. In this way, when CTT and IRT can be used together without standardizing the structural order for how they are employed, testing programs may suffer from inconsistent and perhaps unfair use, possibly affecting the outcomes and decisions made from score usage and as a result the test consequences from employing different theories, different models, and different methods.
Therefore, a checklist is suggested to be used to foster greater comprehensiveness of arguments that will lead to greater consensus among validity arguments. In addition, it is suggested that a new, perhaps hybrid test theory be developed to combine the theories without sacrificing the positive features of each theory as they are presently formulated.
The psychometric concepts of reliability and validity have been explored for the two main test theories: CTT and IRT for calling attention to and facilitating further study of the differences that exist for these two concepts with respect to these theories. Further study is especially important in light of the fact that CTT and IRT are being used together in the same test administrations to a greater extent by testing organizations. For reliability, the conclusion is that comparability between reliability in CTT and item information functions in IRT are only grossly comparable when corrected item-total test score correlations are substituted for reliability coefficients for items when the item score is deleted. For differences between validity arguments are subjected to study using modern psychometric theory, no big differences emerge between CTT and IRT. However, conceptual problems arise when different arguments are constructed by different validity practitioners who use the same test with the same test score data. A checklist was presented to foster greater comprehensiveness of arguments that will lead to greater consensus among validity arguments. As such, divergent argumentation can be avoided, however, CTT reliability and IRT item information functions are intended to indicate different things and when it comes to being used conjointly in the same test administration, it is wiser to compartmentalize CTT reliability and IRT information in the test assembly, pretesting, scoring and its many facets, and analysis, until a new, perhaps hybrid, test theory is developed by combining the theories without sacrificing the positive features of each theory as they are presently formulated.
A check list is suggested to foster greater comprehensiveness of arguments that will lead to greater consensus among validity arguments. As such, divergent argumentation can be avoided, however, CTT reliability and IRT item information functions are intended to indicate different things when it comes to being used conjointly in the same test administration. It is wiser to compartmentalize CTT reliability and IRT information in the test assembly, pre-testing, scoring and its many facets, and analysis, until a new, perhaps hybrid, test theory is developed that combines the theories without sacrificing the positive features of each theory as they are presently formulated.