Figure 1. The Components of Loads Balancing System [52]
The rapid development in computing resources has enhanced the performance of computers and reduced their costs. This availability of low cost powerful computers coupled with the popularity of the Internet and high-speed networks has led the computing environment to be mapped from distributed to Grid environments. Grid is a type of distributed system that supports the sharing and coordinated use of geographically distributed and multi- owner resources independently from their physical type and location in dynamic virtual organizations that share the same goal of solving large-scale applications. A computational grid is a hardware and software infrastructure that provides dependable, consistent, pervasive, and inexpensive access to high-end computational capabilities. Grid computing is concerned with “Coordinated resource sharing and problem solving in dynamic, multi-institutional virtual organizations”. The key concept is the ability to negotiate resource-sharing arrangements among a set of participating parties (providers and consumers) and then to use the resulting resource pool for some purpose.
The sharing concern is not primarily file exchange, but rather direct access to computers, software, data, and other resources, as is required by a range of collaborative problem solving and resource-brokering strategies emerging in industry, science, and engineering. This sharing is, necessarily, highly controlled, with resource providers and consumers defining clearly and carefully just what is shared, who is allowed to share, and the conditions under which sharing occurs. A set of individuals and/or institutions defined by such sharing rules form what we call a virtual organization.
The current computational power demands and constraints of organizations have led to a new type of collaborative computing environment called grid computing [27], [58]. A computational grid is an emerging computing infrastructure that enables effective access to high performance computing resources. End users and application see this environment as a big virtual computing system. The systems connected together by a grid might be distributed globally, running on multiple hardware platforms, under different operating systems and owned by different organizations. While simultaneous resource allocation can be done manually with privileged accesses to the resources, such environments need certain resource management strategy and tool that can provide security and coordination of the resource allocations [31], [59].
There are many potential advantages to using grid architectures, including the ability to simulate applications, whose computational requirements exceed local resources and the reduction of the job turnaround time through workload balancing across multiple computing facilities [28], [60].
The grid load balancing problem, an essential aspect of load balancing system is overviewed to provide a global image of the load balancing process. A distributed system will have number of resources working independently with each other. Some of them are linked by communication channel, while some are not.
Resource management and load balancing are key grid services, where issues of local balancing represent a common concern for the most grid infrastructure developers [29], [30]. In fact, it would be inaccurate to say that the computing power of any system increases proportionally with the number of resources involved. Care should be taken so that some resources do not become overloaded and some others stay ideal [31] .
The essential objective of a load balancing consists primarily in optimizing the average response time of applications, which often means maintaining the workload proportionally equivalent on the whole resources of a system [31].
Load Balancing based on the idea of migration of excess load from heavily loaded node to lightly loaded ones. The problem starts with to determine when to migrate a process or task. This solution is typically based on local load situation [35]: for example, a simple procedure may be the comparison of the load between various nodes with those of the neighboring node and a determination of the node to which the task is to be migrated. But the two nodes, each one having two task may not be equally loaded as in distributed environment; the nodes are of heterogeneous nature. Now, Load balancing algorithms vary in their complexity where complexity is measured by the amount of communication used to approximate the least loaded node. The most significant parameter of the system was found to be the cost of transferring a job from one node to another. It is cost that limits the dynamic algorithms [26], but at the high end of complexity, the dynamic algorithms which do collect varying amounts of information. Potentially, the more information an algorithm can collect, the better decision it will make. Load balancing is usually described in the literature, as either load balancing or load sharing. These terms are often used interchangeably, but can also attract quite distinct definition.
This is the coarsest form of load distribution [33]. Load may only be placed on ideal resources and can be viewed as binary, where a resource is either idle or busy.
Load sharing is the coarsest form of load balancing attempts to ensure that the workload on each resource is within a small degree, or balance criterion, of the workload present on every other resource in the system [35], [61].
Load leveling introduces a third term to describe the middle ground between the two extremes of load sharing and load balancing rather than trying to obtain a strictly even distribution of load across all resources, or simply utilizing idle resources, load leveling seeks to avoid congestion on any one resource [36].
Other issues related to load balancing is that a computing job may not arbitrarily divisible leading to certain constraints in dividing tasks. Each job consists of several tasks and each of those tasks can have different execution times. Also, the load on each resource as well as on the network can vary from time to time based on the workload brought about by the users. The resource capacity may be different from each other in architecture operation system, CPU speed, memory size, and available disk space. The load balancing problem also needs to consider fault-tolerance and faulty-recovery. With these entire factor taken into account, load balancing can be generalization into four basic steps [34], [62].
Grid is a type of distributed system which supports the sharing and coordinated use of resources, independently from their physical type and location, in dynamic virtual organizations that share the same goal [1]- [6]. This technology allows the use of geographically widely distributed and multi-owner resources to solve large scale applications like meteorological simulations, and data intensive applications. In order to fulfill the user expectations in terms of performance and efficiency, the Grid system needs efficient load balancing algorithms for the distribution of tasks.
Load balancing algorithms in classical distributed systems, which usually run on homogeneous and dedicated resources, cannot work well in the Grid architectures [5], [63]. Grids has a lot of specific characteristics, like heterogeneity, autonomy, scalability, adaptability and resources computation-data separation, which make the load balancing problem more difficult [6]- [9].
Load balancing/sharing exploits the communication facility between the servers of a distributed system, by using the exchanging of status information and jobs between any two servers of the system in order to improve the overall performance.
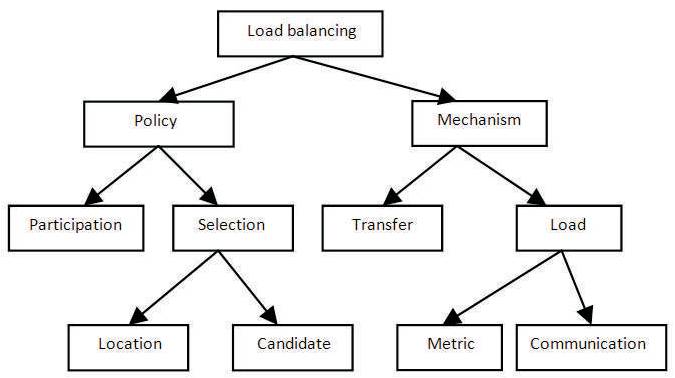
There are two basic issues in the design of load balancing system. The policy issue is the set of choices that are made to balance the load (which tasks should be executed remotely and where). The mechanism issue carries out the physical facilities to be used for task remote execution and provides any information required by the policies [17]- [25]. The division of policy and mechanism can be continued, breaking any load balancing scheme into a set of distinct, but interdependent components [32] [64]. Figure 1 illustrates a suitable decomposition with each leaf representing a distinct component of a load distribution scheme. The emphasis is on the components of the policy and the provision of information to the policy.
Figure 1. The Components of Loads Balancing System [52]
Specifies what load information to be collected, when it is to be collected and from where [7].
Determines the appropriate moment to start a load balancing operation.
Classifies a resource as server or receiver of tasks according to its availability status and capabilities.
Uses results of the resource type policy to find a suitable partner for a server or receiver.
Defines the tasks that should be migrated from overloaded resources (source) to most idle resources (receiver) and coordinating their use to execute a set of tasks [32].
To harness the computational power of a grid, a load balancing policy is used. Such policies attempt to balance the load with the end result of maximizing resource utilization and hence optimizing performance. Per formance may be significantly impacted if information on task and machine heterogeneity is not taken into account by the load balancing policy [10] , [65].
Load Metric Mechanism: The load metric is the representation used to describe the load on a resource This determines the type of information that makes a load index (queue CPU length, memory size) and the way such information is communicated to other loaders (broadcasting, focused addressing, polling).
Load Communication Mechanism: Load communication defines the method by which information, such as the load on a resource, is communicated between the resource and the load distribution policy and mechanisms [22]. The load communication policy can also include the communication between cooperating distributed policies.
Transfer Mechanism: The transfer mechanism is the physical medium for transferring tasks between resources. This leaf can be further expanded to include branches for initial placement and process migration [28], [29].
The load balancing process can be defined in three rules: the location, distribution, and selection rule. Zomaya and Yee-Hwei [8] described that the location rule determines which resource domain will be included in the balancing operation. The domain may be local, i.e. inside the node, or global, i.e. between different nodes. The distribution rule establishes the redistribution of the workload among available resources in the domain, while the selection rule decides whether the load balancing operation can be performed preemptively or not [8].
Load balancing is done basically to do following advantages and disadvantages.
In traditional distributed systems in grid architectures following properties that characterize [15], [16], [37]- [42], [66],[67]:
A Grid involves multiple resources that are heterogeneous in nature and might span numerous administrative domains across a potentially global expanse [22] .
A Grid might grow from few resources to millions. This raises the problem of potential performance degradation as the size of a Grid increases.
In a Grid, a resource failure is the rule, not the exception. That means that the probability of some resources fail is naturally high. Resource managers must tailor their behavior dynamically so that they can extract the maximum performance from the available resources and services [47].
This characteristic facilitates the information flow through the tree and well defines the message traffic in the strategy.
It is totally independent from any physical architecture of a grid that the transformation of a grid into a tree is a univocal transformation. Each grid corresponds to one and only tree.
These properties make the load balancing problem more complex than in traditional parallel and distributed systems, which offer homogeneity and stability of their resources. Also interconnected networks on grids have very disparate performances and tasks submitted to the system can be very diversified and irregular [45], [46].
Grid is a system of high diversity, which is rendered by various application, middleware components and resources. A load balancing process in the grid in generalized, into three stages: information collection, resource selection, and tasks mapping [68], [69].
Information collection is the basis for providing current state information of the resources. It should be performed during the whole course of system running. A load balancing system can either construct its own information collection infrastructure, or employ existing information services systems, enabled by middleware's. It is desired that the overhead introduction by the process of information collection is as small as possible.
In principle, resource selection is performed in two steps. In the first step, the initial filtering is done with the goal of identifying a list of authorized resources that is available to a given application. Possibly, the initial list of authorized resources can be further refined by filtering according to the coarse-grained application requirements, such as hardware platform, operating system, minimum memory, and disk space.
In the second step, those resources are aggregated into small collection such that each collection is expected to provide performance desired by the given application. The number of ways that the resources could be aggregated would be extremely large when the number of feasible resource is large. To overcome the complexity, different heuristics may be introduced [44].
The third phase involves mapping the given set of tasks onto a set of aggregated resources including both the computational resources and network resources. Various heuristics may be used to reach a near-optimal solution. The effort of mapping in conjunction of resource selection produces a set of candidate submission. Once the set of candidate submission is ready; the balancer starts to selects the best submission subject to the performance goal [45], based on mechanisms provided by the performance model.
Some estimate of a computer's load must be provided to first determine that a load imbalance exists [13], [70]. Estimates of the workloads associated with individual tasks must also be maintained to determine which tasks should be transferred to best balance the computation.
Once the loads of the computers have been calculated, the presence of a load imbalance can be detected. If the cost of the imbalance exceeds the cost of load balancing, then load balancing should be initiated.
Based on the measurements taken in the first phase, the ideal work transfers necessar y to balance the computation are calculated.
Tasks are selected for transfer or exchange to best fulfill the vectors provided by the previous step. Task selection is typically constrained by communication locality and task size considerations [14].
Once selected, tasks are transferred from one computer to another; state and communication integrity must be maintained to ensure algorithmic correctness. By decomposing the load balancing process is split into distinct phases.
A distributed system consists of independent workstations connected usually by a local area network. Static load balancing don't fulfill the requirements for load balancing [25]. As in static load balancing, number of jobs at a station is fixed. Dynamic load balancing does the process while job are in execution. Jobs are allocated to host or node. Load at each post is calculated (as number of process, structure of node, network bandwidth, etc.) dynamically. As sender initiated or receiver initiated approaches are available to find the desired load for transferring the load [47]- [53] .
As shown in Figure 2, initially processes restored in queue or process can be allotted as they arrive. If these are placed in queue, processes are allotted one by one to primary nodes. Processes are migrated from heavily loaded node to light weighted node. Process migration is greatly affected by the network bandwidth and work load. In order to reduce the traffic, nodes are grouped into clusters. First a light weighted node is checked in the same cluster, if suitable node is not found then nearby cluster is searched and after getting a required node transfer takesplace if a protocol is satisfied for load transfer [10].
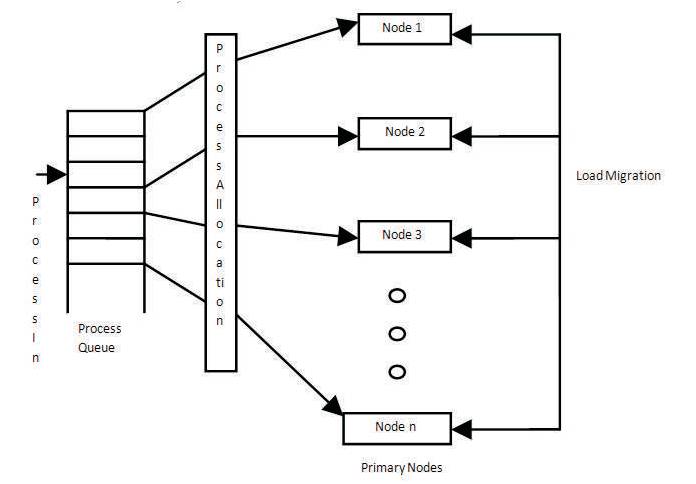
Figure 2. Simple Dynamic Load Balancing to avoid Overload on Heavily Loaded Node by Transferring Process to Light Weighted Node
Whenever a heavily loaded node don't find node in its cluster and due to congestion in network, node fail to search the node far away cluster. It would be better if heavily loaded node finds a temporary node in same cluster to handle the overload. So, in centralized approach, one centralized node is provided in each cluster. Whenever a primary node is overloaded, first it searches the other light weighted primary nodes, if such primary node is available, load transfer takes place between these two nodes and load is balanced, otherwise, one centralized node is available to accommodate the overload of a primary node. This centralized node is assigned in process when primary node is overload; Centralized node has some better structure as compared to other nodes in the cluster. To avoid network delay traffic between centralized node and primary nodes are kept minimum.
As in Figure 3, the overload from nodes is transferred to centralized node to increase output of each node.
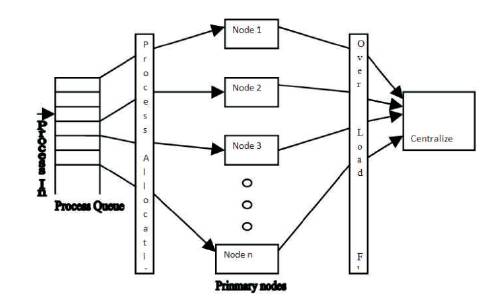
Figure 3. Centralized Node Based Load Balancing
Load balancing problem description knew a proliferation of the terminologies, sometimes even contradictory, making difficult the qualitative analysis of the various methods suggested. Thus, it had become necessary to have a taxonomy which makes it possible to standardize the terminologies for a better description of these approaches and their comparison. Casavant and Kuhl [37] proposed a largely adopted taxonomy, because very complete, for scheduling and load balancing algorithm in general-purpose parallel and distributed computing systems.
Load balancing mechanisms can be broadly categorized as centralized or decentralized, dynamic or static [10], [11], [12]. Here the authors have compared centralize with decentralize and dynamic with static algorithm by comparing some common parameters. On the basis of literature survey, following comparisons have been made (as shown in Tables 1 and 2).
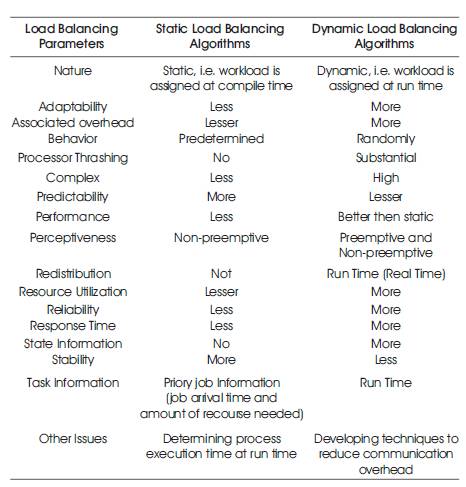
Table 1. Comparison between Dynamic and Static Load Balancing Algorithm
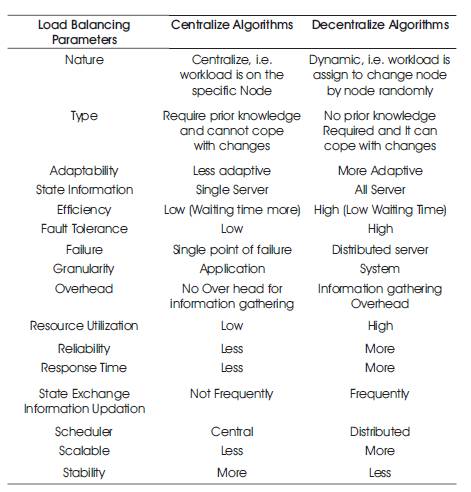
Table 2. Comparison between Decentralized and Centralize Load Balancing Algorithm
After extensive literature survey, various research gaps come to picture for the current research work in the area of grid computing and load balancing. Load balancing in grid environment is significantly complicated by the unique characteristics of grids. The reason can be found be going through the assumption underlying traditional system.
In grid computing, many unique characteristics make the design of load balancing algorithm more challenging as explained below [ 70-78].
For load balancing strategy that needs to balance load of a Data Grid in such a judicious way that computation and storage resources in each site are simultaneously well utilized for a variety of data-intensive applications.
Load-balancing strategy can achieve high performance for data- intensive jobs in Data Grid environments.
Building a model to estimate the response time of job running at a local site or remote site to confirm that new load balancing approach can achieve high performance for data-intensive jobs running on a resource-sharing Data Grid. Response time was realized with a reduction of communication cost between clusters.
With the help of Load balancing global throughput of these software environments, workloads have to be evenly scheduled among the available resources.
The search of load balancing algorithm across a grid is the lack of scalability and the need to acquire system wide knowledge by the nodes of such a system to perform load balancing decisions.
To overcome a single point of failure, scalability, fault tolerance, the communication overhead incurred by frequent state information exchange between machines decentralize mechanism is used, it significantly reduces the communication overhead, while quickly updating the state information in a decentralized fashion.
Grid Computing solving of massive computational problems by making use of unused resources of a largely heterogeneous collection of computers in a distributed infrastructure. A heterogeneous computational grid mainly has two categories of resources: First networks, that are used to interconnect these computational resources, may be differing significantly in terms of their bandwidth and communication protocol. Second, computational resources may have different hardware and also different software, such as instruction set, computer architectures, number of resource, physical memory size, CPU speed, different OS, and so on.
Site autonomy greatly complicates the design of effective grid load balancing. A site is an autonomous computational entity. It usually has its own scheduling policy, which complicate the prediction of a job in the site. A single overall performance goal is not feasible for a grid system since each site has its own performance goal and scheduling decision is made independently of other sites according to its own performance goal.
It is another important issue. Certain classes of job have higher priority only on certain specific resources. For example, it can be expected that local jobs will be assigned higher priorities, such as local jobs will be better served on the local resources.
Resource usage contention is a major issue. Competition may exist in both computational resources and interconnection network. Due to the non dedication of resources, a resource may join multiple grids simultaneously. The workload from local user and other grid share the recourse, concurrently the underlying interconnection network is shared as well. One consequence of contention is that behavior and performance can vary over time in WAN using the internet protocol suite, network characteristics, such as latency and bandwidth may be varying over time. Under such an environment, designing an accurate performance model is extremely difficult.
The problem arises because the grid applications are from a wide range of users, each having its own special requirements. For example, some application may require sequential execution, some application may consist of asset of independent jobs and others may consist of a set of dependent jobs, in this context; building a general-purpose load balancing system seems extremely difficult. An adequate load balancing system should be able to handle a variety of application.
11.12 Dynamic Behavior
In traditional distributed computing enviroments (cluster), the pool of resources is assumed to be fixed or stable. In grid environment, dynamic exist in both the networks and computational resources. First, a network shared by many parities cannot provide guaranteed bandwidth in WAN. Second, both availability and capabiity of computation resources will exhibit dynamic behaviour. On one hand, new resouces may join the grid and on the other hand, some resorces may become unavialable due to network failure problem. After a new resource joins the grid, the dynamic behavior of load balancing should be able to detect it automatically and leverage the new resource in the later balancing decision making.
In traditional systems, executable code of applications and input/output data are usually in the same site, or the input sources and output destinations are determined before the application is submitted. Thus the cost is a constant determined before execution and load balancing algorithm need not consider it but in a grid which consists of a large number of heterogeneous computing sites (from supercomputers to desktop) and storage sites connected via WAN, the computation sites of an application are selected by the grid load balancer according to resource status and certain performance models.
In a grid, the communication bandwidth of the underlying network is limited and shared by a host of background loads, so the inter domain communication cost cannot be neglected, but the data staging cost is considerable because of data intensiveness of grid applications. This situation brings about the computation data separation problem, the advantage brought by selecting a computational resource that can provide low computational cost may be neutralized by its high access cost to the storage site.
Load balancing problem becomes more challenging because of some unique characteristics belonging to grid computing. It is often difficult to make comparisons between distinct efforts because each load balancing is usually developed for a particular system environment or particular greedy application with different assumptions and constraints.
These challenges pose significant obstacles on the problem of designing an efficient and effective load balancing system for Grid environments. Some problem resulting from the above are not solved successfully yet and still open research issues. As a result, new load balancing frame work must be developed for Grid, which should reflect the unique characteristics of grid systems.
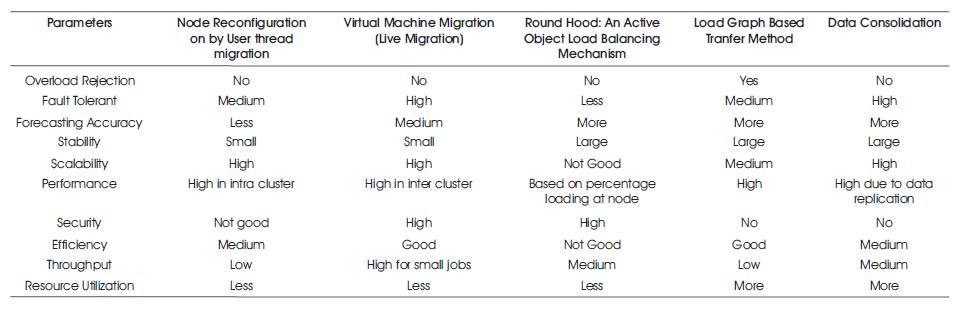
In this section comparative study of load balancing algorithms has been done on the basis of some parameters like, scalability, security, throughput, migration time, efficiency, fault tolerance, overload rejection, resource utilization, forecasting accuracy and stability etc. Table 3 lists the comparative study of all the Existing Algorithms.
Node reconfiguration mechanism makes application workload migrate from source node to destination node, and then let source node depart from original computing environment. There are two implementation fashions of node reconfiguration, first one is synchronous method and the other is asynchronous method. Best performance can be obtained by maintaining the order of node reconfiguration messages [55-56].
In Virtual machine, migration snapshots of machine are sent to other machine by using two migration method, live migration and regular migration. An important aspect of this mechanism is to make the run-time job migration with non-dedicated shared resources in dynamic grid environment and also provides high isolation, and security [57-58].
Robin Hood algorithm is totally non-centralized mechanism, using the proactive library for the migration of jobs, and a multicast channel for node coordination. It improves the decision time in non-centralized environment and uses the non-centralized architecture and non-broadcasting of the balance of each node to reduce the overload in network [59-60].
Load based graph method is based on network graph where each node is represented with its load, whereas load can be the number of users, average queue length or the memory utilization. It uses analytic model and single load determination policy throughout the system and load is determined on the basis of memory utilization and average queue length. The major parameter, network partitioning issues along with inter-cluster and intra-cluster transfers for decision making of load balancing for the transfer is considered here [61- 62].
In Data Consolidation algorithms, data replication technique is considered here which provide fast access and reliability by reducing the scheduling of task and data management. This is the main optimization technique, that provide fast data access and reliability. Data Consolidation (DC) is the combine name of task scheduling and data migration. DC can be considered as the dual of the data replication problem, where from one site, the data are scattered to many repository sites. Through this dual relationship the authors show that DC can also provide, by reversing the procedure, data replication services [63-64].
The above comparative study shows that all the characteristics are fulfilled by any single load balancing algorithm as this is very difficult to achieve. Parameters like performance, throughput, resource utilization, and efficiency are mandatory and therefore should be considered always while developing dynamic load balancing algorithms. In the proposed algorithm, the parameters have been considered to a large extent for a grid environment.
The work has analyzed the load balancing technique in existing distributed environments and a dynamic, decentralized load balancing and scheduling policy in heterogeneous grid Environments. The author also has reviewed the job migration technique in load balancing algorithm based on the framed policy. The time optimization, and cost efficiency of the algorithm were discussed, including various load balancing challenges.