
Figure 1. The Hardware setup of the Voice Command System
The purpose of this research is to demonstrate how a Voice Command System is implemented. The primary input of a user's voice is used in this method. We were able to convert voice as an input to text with speech to a text engine. The resulting text is used to process questions and collect relevant information. After collecting the information, it was converted to speech using speech-to-text and the correct output was delivered to the user. This research has realized a public API based speech recognition system with Raspberry Pi and USB microphone as hardware and several python programming languages. Osun State Polytechnic Iree has many different offices and lecture halls and the directory is done by signposts and asking people around the campus and there has been a great problem as some signposts have fallen off. While the signposts can only give a directive to buildings, it can't give the directive to offices inside the building and some visitors get embarrassed by the way they are replied to, some may be given the wrong direction while some may not get being replied at all. These prompts to design a system that gives visitors direction to offices and lecture rooms in Engineering building. The research covers the hardware specification of the speech recognition system and also maps an application of public speech APIs and shows a realization using appropriate hardware.
A Voice Command System is a device that processes voice as an input, decodes or understands the meaning of the input, and provides a suitable voice output. Any voice command system requires three basic components that are text-to-text, query-to-text, and textto- specific. The speech is also a very necessary aspect of contact. Since sound and voices are processed faster than written text, vocal control systems in computer devices are omnipresent. In the field of speech recognition, there have been some good advances. The wide use of big data and in-depth learning in this area are some of the new developments (Van Der Aalst,1998). Such advances were attributed to deep learning methods in the development and usage of some of the speech recognition systems in the technology industry. Using large-scale data on speech systems, Google has lowered the number of word errors by 6% to 10%, for a system with a word error rating of 17% to 52% (Almomani et al., 2018).
This study aims to develop a system that gives direction to visitors within the SET building. Towards the achievement of this goal, the study addresses the following objectives:
Traditional phonetic-based approaches, for example, both HMM-based language approaches, as well as acoustic and pronunciation-based approaches, involve a variety of components and preparations. It is necessary because the planning and deliver y process is streamlined. The models are common in terms of spelling errors and need to clean up the transcripts using a specific language model. Models are based on a growing approach for CTC models (World Health Organization, 2018).
The first component is to translate the numbers into written format and abbreviations. This is also known as email normalization. The second segment involves in the transformation of the signal into a comprehensible one (Amusat, 2009).
Recognition of speech is the machine's ability, for example, to understand words and phrases in all languages (Anusuya & Katti,2009). Such words or phrases are then translated according to a format that the computer can understand. The basic method of speech recognition is vocabulary systems (Panwar et al., 2017). such as small vocabulary system and Large Vocabulary- Small user system may be a voice recognition system (Olupohunda, 2012).
A computer or program has the ability to receive and interpret dictation, or to recognize and execute spoken commands is voice or speech recognition. Analog audio can be converted to digital signals for the use with computers. It has to be transformed from analog to digital. To decode the signal, a machine should have a digital dictionary of terms or syllables or a vocabulary to compare this information easily with the signals. When running the program, the talk patterns are stored on the hard disk and loaded into the memory. A comparator tests certain stored patterns for A / D converter output. The pattern, called Listen, Attend and Spell (LAS), "attracts attention" for different parts of the signal. Compared to CTC models, attentive models are not conditionally autonomous and should investigate specifically all the aspects of speech, visual, and language recognition. For example, this means that a language model is not needed during implementation, so it is practical for lowmemory applications (Javale et al., 2013) The superior performance of the CTC (with or without external language) models was good at the end of 2016.
Many changes were suggested following the original LAS model. Carnegie Mellon University, MIT, and the Brain Google have introduced latent sequence decompositions (LSDs) to handle lip reading for the first time and to tackle human achievement (Nan et al., 2017). The Oxford University and the DeepMind Google extended LAS to include the "Spelling, Viewing, Listening" In addition to the home automatics focussed on acoustics to address physical challenges, this study focuses on the design and implementation of Sound Intelligence as part of the broad perspective of the Raspberry Pi framework for the operations and control of remote sensors, motion detection and video cameras. The failure to access and track equipment from a remote location is one of the main reasons for energy loss. Users are driven by Ios or Android applications on these systems. This network uses a variety of networking mechanisms including WLAN, GSM, Bluetooth, and ZigBee. For current systems, there are various control mechanisms and configurations. So many locations for a range of applications have already found these systems. This work includes an analysis of both of these structures (Karan et al., 2017). Some researchers outlined the use of wireless technologies such as ZigBee, which can minimize the cost and ensure a stable and safe communication of the cabling of the home automation network. ZigBee is a wireless network with low data rate requirements and having features such as low-cost, low power consumption, and fast responses. ZigBee is most suited for networks such as homes in small areas. This program applies a Microsoft Protocol (SAPI), to allow voice recognition when a user commands the program. This system is a Microsoft protocol and it system consists of 3 main components: i) ZigBee module smart home server, ii) Smart environment sensor modules and iii) Module control of voice order.
To successfully implement the visitor directive system, the following procedure was used for data acquisition.
The new system suffers from the limitation of being able to store pre-defined voices and restricted voices. Therefore, the user cannot obtain all the details reliably.
The hardware setup of the voice command system is shown in Figure 1.
Figure 1. The Hardware setup of the Voice Command System
This research work eliminates the hectic process of tiring configurations and setups and overheating of the system, which ultimately affects the performance. The conversation of natural languages to the system and its response makes the user to feel like he is talking to another human and makes him to ignore the fact that a system performs all the tasks.
Figure 2 shows the architecture of the proposed system. The work initially seemed difficult as a whole. It was divided into modules to make the work easier and also for debugging. The three modules are as follows:
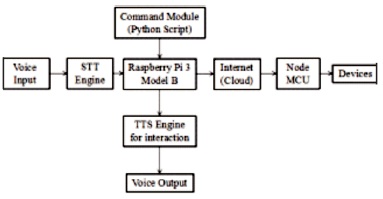
Figure 2. Architecture of the Proposed System
For consistency and accuracy, a data collection protocol was designed. The protocol defines speaker selection process, keywords, recording parameters (sampling frequency and quantization rate), and the format of output audio files. The specific recording requirements/materials are enumerated below:
First, the user uses a microphone to submit the feedback when he begins the program. (Figure 3) Essentially, it takes the user's sound data and is fed to the machine for further process. Then the sound entry is transmitted to a text-totext converter, which translates audio input to text output that can be recognized and processed by the computer. Then the text will be evaluated and keywords scanned. Our voice control system is built around the keyword method where you scan for the appropriate keywords. when keywords are matched, the corresponding output is given. The result is in text type. This is then transformed to speech output by an optical character recognition (OCR) device using a text to a speech converter. OCR categorizes and understands the text and then translates it to the audio output by the wording engine. This signal is transmitted via the speakers connected to the raspberry pi audio jack.

Figure 3. Flow of Events in Voice Command System
The above-mentioned modules were systematically implemented using the necessary hardware and software and tested. The results were promising and consists of snapshots of some of the results.
Figure 4 is the environment of the RASBIAN operating system. The environment indicate that the developed program is ready to start operation.
Figure 4. RASBIAN Desktop Environment
Figure 5 illustrates the voice directive environment. The user calls the name of the Lecturer and the directive will be displayed on the panel while the speaker voice out the response.

Figure 5. Voice Directive Environment
The Raspberry Pi needs a 5V/2A power supply to function properly. Any changes in the voltage rating affects the board such as rebooting often, not performing efficiently, etc., So it is necessary to give a proper power supply to it. The peripherals used in this prototype does not need a separate power supply as they get their power from the USB ports of the Raspberry Pi.
Machine Learning should be implemented completely into this system. That way, the system can able to learn new processes by itself and adapt to the user based on its past experiences. This makes it easier for the user to interact with the assistant. Memory can be improved and let the system store the new information gathered from the user and use it in the future if required. Many more modules can be created based on the necessities. Another important improvement done is the addition of native languages. It is a hectic process, yet it will be useful to all the people who do not understand English. It makes this device usable by almost all of the people in the world. By the addition of native languages, the device becomes much more user friendly and easily accessible.