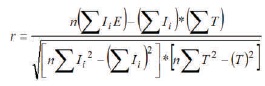
Credit card fraud detection is an important aspect of financial institutions that provide various online payment services to its customers. One of the criteria which affect the performance of credit card fraud detection models is the selection of variables. This paper studies the effects of feature engineering on two sets of feature ranked imbalanced credit card fraud datasets for four classifier techniques. This paper employs the credit card fraud datasets (Taiwan and European bank) obtained from UCI and ULB repositories containing 30,000 and 284,807 transactions, respectively. Feature ranking on the sets of datasets is carried out using correlation analysis technique. Algorithms of four classifiers are produced and used on feature and raw ranked data. The algorithms of the classifiers are run in Matlab. The performance metrics applied in assessing the effects of the four classifiers on the feature and raw ranked datasets are specificity, precision, Matthews correlation coefficient, sensitivity, accuracy, and balanced classification rate. Results from the comparative analysis show that decision tree variant classifiers outperform Naïve Bayes, support vector, and neural network radial basis function techniques. The feature ranked and raw datasets of the European credit card fraud data recorded highest performance metrics for decision trees. The paper investigates the effect of feature ranking of two imbalanced credit card fraud data on four machine learning techniques using filter approach. Credit card fraud detection is an important aspect of financial institutions that provide various online payment services to its customers. One of the criteria which affect the performance of credit card fraud detection models is the selection of variables. This paper studies the effects of feature engineering on two sets of feature ranked imbalanced credit card fraud datasets for four classifier techniques. This paper employs the credit card fraud datasets (Taiwan and European bank) obtained from UCI and ULB repositories containing 30,000 and 284,807 transactions, respectively. Feature ranking on the sets of datasets is carried out using correlation analysis technique. Algorithms of four classifiers are produced and used on feature and raw ranked data. The algorithms of the classifiers are run in Matlab. The performance metrics applied in assessing the effects of the four classifiers on the feature and raw ranked datasets are specificity, precision, Matthews correlation coefficient, sensitivity, accuracy, and balanced classification rate. Results from the comparative analysis show that decision tree variant classifiers outperform Naïve Bayes, support vector, and neural network radial basis function techniques. The feature ranked and raw datasets of the European credit card fraud data recorded highest performance metrics for decision trees. The paper investigates the effect of feature ranking of two imbalanced credit card fraud data on four machine learning techniques using filter approach.
Credit card transaction data is a growing source of financial data which requires adequate measures to gain important information, pattern, and trends. Credit card transactions are not safe from occurrence of fraud. Fraud is perpetuated in order to acquire financial gain. Credit card fraud is a type of financial scam perpetuated through the use of credit card as the fraudulent means of acquiring monetary gains in transaction. It is an identity theft which involves unsanctioned use of another individual's credit card information for personal gain. This area of financial computing deals with the classification of large credit card transactions data into legitimate and fraudulent transactions. The relatively small amount of fraud occurrence in this type of data makes the accuracy of detection more difficult. Financial institutions have focused on machine learning techniques to build detection models to curb this menace. Apart from application of machine learning techniques to detection of credit card fraud, the performance accuracy of hybrid sampling of the imbalanced credit card fraud dataset has been carried out (Awoyemi, Adetunmbi, & Oluwadare, 2017). In this research, the effect of feature ranking and selection is studied.
Machine learning techniques learn from data and its features in order to predict future outcome of the systems. A number of machine learning techniques applied to detecting credit card fraud includes; Genetic Algorithm (Kalyani & Devi, 2012; Meshram & Bhanarkar, 2012), Support Vector Machine (Singh, Gupta, Rastogi, Chandel, & Riyaz, 2012), Naïve Bayes (Bahnsen, Stojanovic, Aouada, & Ottersten, 2014), neural network (Ogwueleka, 2011), frequent itemset mining (Seeja & Zareapoor, 2014), migrating birds optimization algorithm (Duman, Buyukkaya, & Elikucuk, 2013), logistic regression (Ng & Jordan, 2002; Shen, Tong, & Deng, 2007), decision tree (Patil, Somavanshi, Gaikwad, Deshmane, & Badgujar, 2015), and random forest (Bhattachar yya, Jha, Tharakunnel, & Westland, 2011). Detecting Credit card fraud is made possible by looking at the spending behaviour of the card holders. The authors' previous paper (Awoyemi et al., 2017) highlights some challenges connected with the detection of credit card, such as the dynamic nature of fraudulent behaviour profile; rare availability of transaction datasets, and skewness of data, amongst others. In this paper, the effect of feature ranking on credit card fraud datasets is investigated.
Feature Engineering involves transformation of raw data into features that better represent the underlying problem to the model, which results in improved model performance on unseen data. Feature engineering deals with how well the input to a model is designed. A feature is an attribute that is useful to a particular problem to be modelled. The features in data directly influence the accuracy of models. Better feature selection leads to simpler and less complex models. Features are important for every modelling task. Feature importance is the measurement of usefulness of a feature. Feature importance can be carried out by assigning scores to features and subsequently ranking them. The features with highest scores are selected for model building. A feature is highly important if it is correlated to the target (dependent) variable. Feature learning involves the automatic identification and use of features in processed data. Feature construction, mainly manual process, deals with the construction of new features from raw dataset, while the automatic construction of new features from feature set data is known as feature extraction. Feature selection carries out selection of relevant features from a pool of features depending on their importance. Feature selection selects a subset of relevant features for model development.
This paper investigates the effect of feature ranking and selection on the fraud detection models. A comparative assessment of the four techniques (support vector engine, decision tree, neural network, and Naïve Bayes classifier methods) on detection of credit card fraud using feature ranked and raw dataset was done. This paper extends their previous work (Awoyemi et al., 2017) on comparative study of credit card fraud detection using machine learning techniques. Two sets of credit data from Taiwan and European Banks are used in the study. The filter method of feature selection was used to assess feature importance, rank features, and select the relevant ones for model building. The performance evaluation is done based on specificity, precision, Matthews correlation coefficient, sensitivity, accuracy, and balanced classification metrics.
Neural network detecting credit card fraud was presented in (Ghosh & Reilly, 1994). This paper aims to develop credit card fraud discovery for Mellon bank using neural network scheme. The aim of the network training process is to attain a fraud score, which gives the finest rank of the transactions in the credit card.
The major contribution of this work is that significant number of fraud accounts were detected with fewer false positive alarms. In (Brause, Langsdorf, & Hepp, 1999), a neural data mining approach for detection of credit card fraud is presented. This paper has indicated the compatibility of data mining methods and neural network algorithm in achieving a high fraud coverage connected with low false alarm rate. The approach used in this paper involves a combination of associative rule mining and neural network technique. The paper further showed that this methodology has to be based on the imbalanced classification problem caused by the very low rate of scam for genuine transaction. In (Maes, Tuyls, Vanschoenwinkel, & Manderick, 2002), it was shown that good results can be obtained by using ANN and BNN in detecting fraud. The BNN outperforms the ANN by discovering fraudulent transactions 8% more than the ANN. The study showed the importance of good preprocessing of data and trade-off selection between different parameters (parameter tuning) for the neural network. A survey of fraud detection techniques was presented in (Kou, Lu, Sirwongwattana, & Huang, 2004), where fraud detection in three application areas, namely credit card fraud detection, telecommunication, and computer intrusion detection were explained. The study discussed the features of fraud categories, how essential fraud detection systems are, resent fraud detection methods in use, and likely suggestions for future studies.
Support Vector Machines (SVM) and neural networks as methods of detecting credit card fraud was presented in (Chen, Shu-Ting, & Shiue-Shiun, 2006). SVM and ANN are utilized in detecting scam in credit card transactions. The study shows that both Back-Propagation Neural network (BPN) and SVM can offer good solutions. The SVM had better prediction performance than BPN when the data is limited. However, an average rise in prediction accuracy is realized when the ratio of training to total data is 0.8. This can be improved further upon with adequate feature ranking. The paper (Shen, Tong, & Deng, 2007) have studied the application of classification models on credit card fraud detection. This paper examines the importance of employing different types of models to fraud detection problems.
A paper on “Real-time credit card fraud detection using computational intelligence” was presented by (Quah & Sriganesh, 2008). This paper analyses risk scoring and behavioral pattern detection using neural networks. Neural network methodology was employed in resolving credit card scam detection. The proposed approach makes use of self-organization chart in analysis and filtering of consumer attributes for fraud detection. In (Patidar & Sharma, 2011), neural network and Genetic Algorithm (GA) are fused together to detect credit card fraud. Super vised learning feed for ward back propagation algorithm is used in the training of the neural network. The GA is used to select optimal parameters neural network model. In (Şahin & Duman, 2011), decision trees and SVM based classification models were designed and used on fraud detection. It is pertinent to note that as the size of the training datasets increases, detection performance of SVM models equal that of decision tree, but the amount of frauds detect by SVM techniques were lower than decision tree methods.
In (Zareapoor, Seeja, & Alam, 2012), a comparative analysis of nine fraud detection techniques used in credit card fraud detection were done. Each method was assessed on certain design criteria. These methods include; Artificial Immune System, Decision Tree, Support Vector Machine, Neural Network, Bayesian Network, Genetic Algorithm, k nearest neighbour, Hidden Markov Model, fuzzy neural network, and fuzzy Darwinian system. The work helped in the development of a hybrid approach for credit card fraud classification difficulty with variable misclassification costs and greater accuracy. Behaviour based credit card fraud detection using Support Vector Machines is presented (Dheepa & Dhanapal, 2012). The work undergoes behaviour based classification approach using SVM technique while an efficient feature extraction method was also applied. Only the behaviour features are selected for training. Effective feature extraction system was employed to resolve problem of handling large amount of data. Credit card fraud detection applying decision tree for locating email and IP address was presented (Dhanapal & Gayathiri, 2012). The decision best split criteria for classification is based on measures of Gini index, entropy and information gain ratio in the feature set. The paper by (Rao & Singh, 2013) aims at conducting experiments on detection of banking scams using ensemble tree learning methods and genetic algorithm. The study further investigates decision tree algorithms applying ID3, C4.5, ensemble methods and wrapper systems.
In (Abdelhamid, Khaoula, & Atika, 2014), the authors apply supervised learning methods to classify normal and abnormal consumers' behaviours for credit card fraud detection. “Credit card fraud detection using neural networks” was presented in (Murli, Jami, Jog, & Nath, 2014). The work used neural network to discover credit card scams which was implemented in Neuroph IDE. Another work on “Hybrid Approach to Detect Credit Card Fraud” was presented in (Abdulla, Rakendu, & Varghese, 2015). The paper describes a simple fraud detection mechanism by hybridizing Genetic Algorithm (GA) and SVM. The GA together with K-nearest neighbour is applied for feature selection. The performance of five data mining techniques to predict credit card fraud was investigated (Zareapoor & Shamsolmoali, 2015), which includes; SVM, Bayesian Network, K-nearest neighbour, and Bagging Ensemble classifier. Results from the study showed that bagging classifier based on decision tree algorithm performs favorably with fraud. In (Patil, Somavanshi, Gaikwad, Deshmane, & Badgujar, 2015), a new costsensitive decision tree method that decreases the sum of misclassification costs, while choosing the splitting attribute at individual non-terminal node was presented.
In (Kamboj & Gupta, 2016), the authors proposes a unique credit card fraud detection method based on the integration of SVM. The work investigated the performance of advanced data mining techniques, support vector machines, together with RBF kernel. A paper on “Credit Card Fraud Detection using SVM and Reduction of False Alarms” was presented (Demla & Aggarwal, 2016), which employs incremental learning technique to minimize misclassification rate and false alarms. In (Nipane, Kalinge, Vidhate, War, & Deshpande, 2016), fraudulent detection for credit card system using decision tree induction algorithm and support vector machine algorithm was proposed. The paper presented a comprehensive composition of structures for effective fraud detection. A system which detects fraud in credit card transaction processing applying a decision tree with combination of Luhn's algorithm and Hunt's algorithm was also proposed (Save, Tiwarekar, Jain, & Mahyavanshi, 2017).
The experimental study focuses on the data preprocessing stage with special emphasis on feature selection. The feature selection method used in this work is filter method. Correlation coefficient scoring of the features is carried out to evaluate the feature importance. Pearson correlation coefficient analysis is used to evaluate the feature importance. Features with high scores are ranked higher, thus low ranked features are irrelevant and are pruned off. The relevant features are included in the model construction. The two sets of credit card fraud data are described in the next sub section.
The first dataset is Taiwan credit data, which is sourced from UCI Machine Learning Repository (Lichman, 2013). It spans a period of 6 months between April 2005 and September 2005 and consists of 25 features and 30000 rows. The last variable is the target variable which holds either 1 (default credit) or 0 (good credit) value. These variables and their description were shown (Lichman, 2013). The second dataset is European bank credit card fraud data obtained from ULB Machine Learning Group, with detailed description as seen in (Dal Pozzolo, Caelen, Johnson, & Bontempi, 2015). 284,807 credit card transactions were contained in the dataset. The fraud issues make up about less than 1% of the credit card transactions data. The data has a total of 31 features, 30 input features, and 1 target feature. Feature 'class' is the target group for the binary classification and it takes value 1 for fraud case and 0 for non-fraud (Awoyemi et al., 2017).
Data preparation is carried out by selecting and converting the target field (symptoms) in dataset into useable format for feature selection and model construction. The feature data types are defined and made uniform. All the features are converted into numeric types while the target feature field holds only two types of data value, namely “0” and “1” representing positive and negative classes. This pre-processing stage ensures the ease of mix and match between algorithms and data.
Feature selection is quite different from feature reduction. In most literature, the latter is referred to as dimensionality reduction. These methods aim to decrease the number of features in the dataset, but a dimensionality reduction method tends to do this by generating new combinations of features, whereas feature selection methods include and exclude features present in the data without changing them (Brownlee, 2014). The importance of feature selection is mainly three-fold. It enhances the performance of predictive models, provides faster and flexible prediction (or classification), and offers better understanding of the underlying process, which generates the model outcome. Feature importance is done using correlation coefficient analysis technique. This filter method ranks the features based on their coefficient scores. Features with high coefficient scores are ranked higher and are more relevant for model construction. Optimal selection of features from the feature set is carried out using correlation coefficient formula, which finds how strong a relationship is between each input variable and the target variable. A value between -1 and 1, is returned by the expression where
The correlation score (relationship strength) is the absolute value of the correlation coefficient. This means the larger the coefficient, the higher the ranking of the feature. Pearson's correlation analysis is carried out on the two sets of dataset (Taiwan and European credit data) in SPSS Statistical Package. Results of Pearson correlation coefficient scores of the feature set is shown section 3. The formula for Pearson's correlation coefficient r is given by,
where
r = Pearson correlation coefficient
Ii = values of credit input features
T = values of the target feature
n = total number of instances
The four classifier techniques under study are; Decision Tree, Naive Bayes, Neural Network, and SVM techniques.
Decision Trees (DT) are a non-parametric based supervised learning technique suitable for mainly regression and classification purposes. Models based on decision tree technique predict the outcome by learning simple IF ELSE rules inferred from the input features. Support Vector Machine (SVM) is another supervised method. This is a discriminative classifier formally defined by a separating hyperplane (Patel, 2017). The Naïve Bayes classifier carries out its classification with respect to conditional probabilities of the positive and negative instances. Neural network is inspired by the structure and functionality of the human nervous system. It can be used in modelling any serious non-linear problem, like the credit card fraud detection difficulty (Syeda, Zhang, & Pan, 2002).
The algorithms for the classifiers are developed and run in Matlab IDE. The evaluation metrics are done with respect to accuracy, sensitivity, specificity, precision, Matthews Correlation Coefficient (MCC), and Balanced Classification Rate (BCR) as described in (Cheruku, Edla, & Kuppili, 2017). The correlation analysis coefficient for the feature ranking and selection process for the two sets of datasets is shown in Table 1. Table 1 presents the results of the experimentation of feature ranking and selection using the two datasets on the four classifiers. This is based on significance of correlation. After the feature ranking and selection process, 17 out of 24 input features are selected for the Taiwan bank credit data while 28 out of 30 input features are selected for the European bank credit card data, respectively.
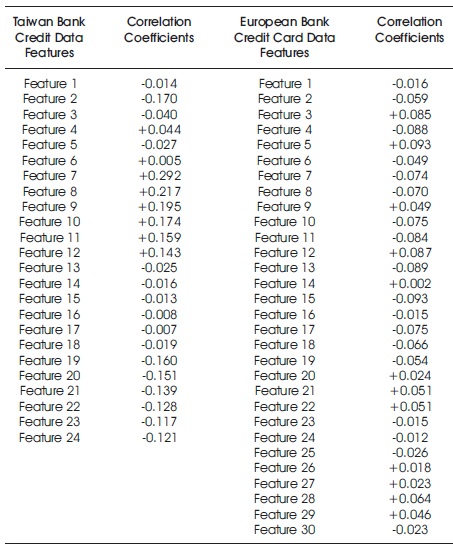
Table 1. Dataset Feature Correlation Coefficient
Tables 2 and 3 show the accuracy metric results of decision tree classifier (variants) on raw original and feature ranked Taiwan dataset, respectively. While the simple decision tree showed better performance on the raw data, it performed better only in terms of specificity and precision for the feature ranked dataset.
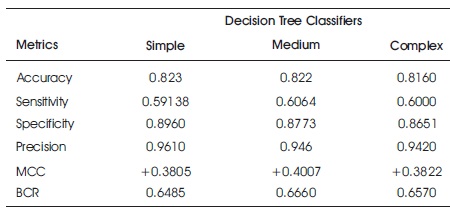
Table 2. Accuracy Results for Decision Trees on Raw Taiwan Bank Credit Data (Thandar & Khine, 2012)
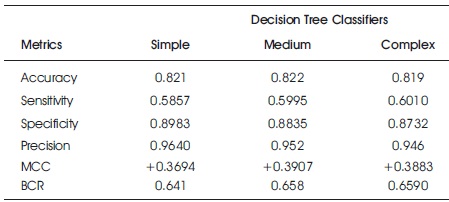
Table 3. Accuracy Results for Decision Trees on Feature Ranked Taiwan Bank Credit Data
Tables 4 and 5 show the accuracy metric results of decision tree classifier (variants) on raw original and feature ranked European bank credit card dataset, respectively. The medium and complex decision tree performed better than the simple type in all metrics. It could be observed that there was no significant change in performance for the raw and feature ranked European bank credit card dataset.
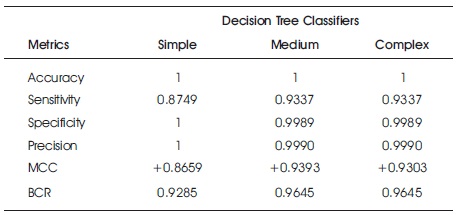
Table 4. Accuracy Results for Decision Trees on Raw European Bank Credit Card Data
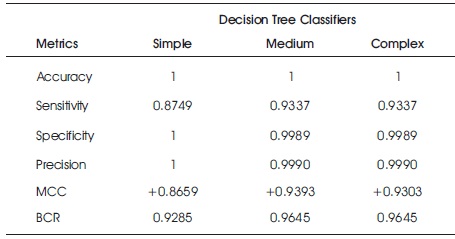
Table 5. Accuracy Results for Decision Trees on Feature Ranked European Bank Credit Card Data
Tables 6 and 7 depict the results of Support Vector Machine classifiers on raw and feature ranked Taiwan bank credit datasets, respectively. Medium Gaussian performed better in all metrics except specificity for both raw and feature ranked Taiwan credit data.
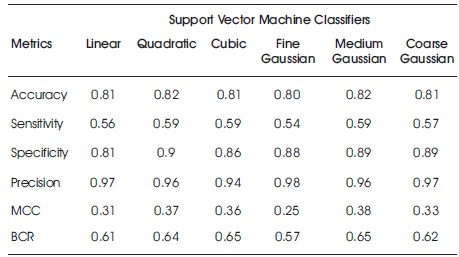
Table 6. Accuracy Results for Support Vector Machine on Raw Taiwan Bank Credit Data
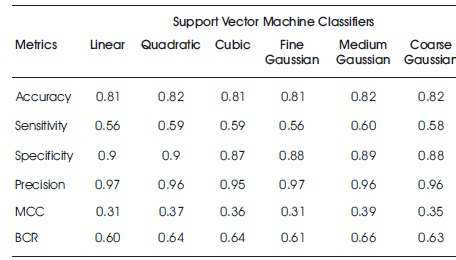
Table 7. Accuracy Results for Support Vector Machine on Feature Ranked Taiwan Bank Credit Data (Prathiba, Balasingmoses, Devaraj, & Karuppasamypandiyan, 2016)
Tables 8 and 9 show the accuracy metric results of SVM classifier (variants) on raw original and feature ranked European bank credit card data, respectively. There are little or no improvements of performance of raw and feature ranked data. For both raw and feature ranked data, the cubic SVM showed better performance than the rest for all evaluation metrics.
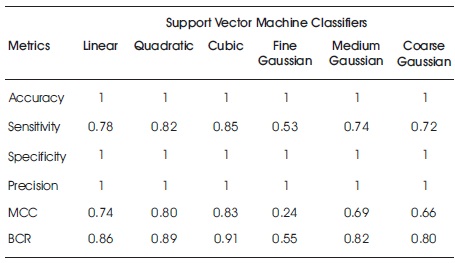
Table 8. Accuracy Results for Support Vector Machine on Raw European Bank Credit Card Data
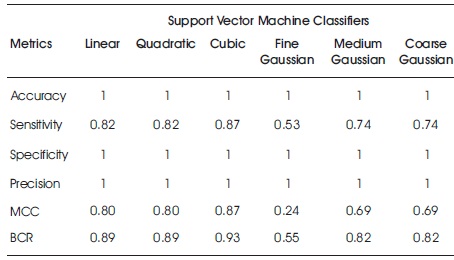
Table 9. Accuracy Results for Support Vector Machine on Feature Ranked European Bank Credit Card Data
Tables 10 and 11 show the accuracy metric results for Naïve Bayes and Neural network RBF classifiers on raw original and feature ranked Taiwan bank credit and European credit card data, respectively. From the Taiwan credit data, the Naïve Bayes classifier on raw data performed better than the feature ranked data while the neural network RBF showed better performance on feature ranked data than the raw data. For the European bank data, Naïve Bayes performed better on raw dataset while neural network RBF had no significant improvement between the two datasets.
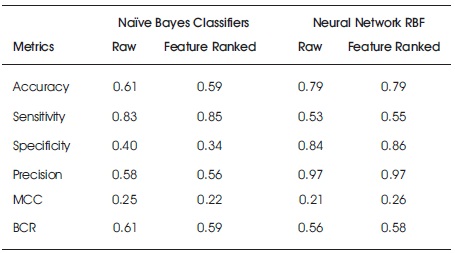
Table 10. Accuracy Results for Naïve Bayes and Neural Network RBF on Raw and Feature Ranked Taiwan Bank Credit Data
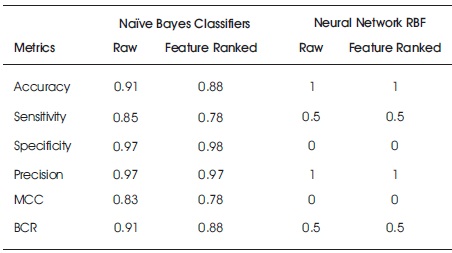
Table 11. Accuracy Results for Na ve Bayes and Neural Network RBF on Raw and Feature Ranked European Bank Credit Card Data
The optimal performance of the four classifiers is evaluated. The plot of Decision Tree, Naïve Bayes, Neural Network (RBF), and Support Vector Machine classifiers on Taiwan and European bank credit data is shown in Figure 1.
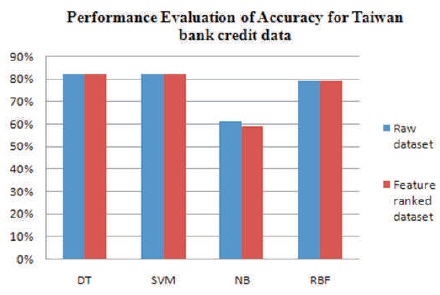
Figure 1. Performance Evaluation Plot of Accuracy for Taiwan Bank Credit Data
Figure 2 shows the performance evaluation plot for European bank credit card data. It can be seen that all classifiers except Naïve Bayes performed optimally well on both raw and feature ranked data for the European bank credit card data.
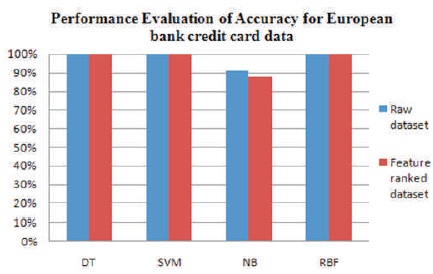
Figure 2. Performance Evaluation Plot of Accuracy for European Bank Credit Card Data
From the experiments, it could be observed that the European bank credit card data showed excellent performance across various metrics than the Taiwan credit data. For both data, there is slight improvement in overall accuracy between raw and feature ranked dataset, but significant changes in specificity, precision, MCC, BCR, and sensitivity. SVM, decision tree and neural network RBF's performance on the raw and feature ranked European credit card data remained unchanged mostly for accuracy, specificity, and precision metrics. This can be attributed to the fact that the European credit card data prior to this study had undergone PCA (Principal Component Analysis) transformation as at the time of data sourcing. However, notable improvements are recorded in terms of specificity, precision, Matthews correlation coefficient, sensitivity, and balanced classification rate for the Taiwan credit data.
Detection of fraud in credit card transactions is an intrinsic part of financial computing. Investigating various conditions that achieve high performance of fraud detection is paramount in this area of research. This paper investigates the effect of feature selection technique, filter method, in detecting credit card fraud using two sets of credit data sourced from Taiwan and European bank. The results show that feature selection (filter method) has slight improvements on overall performance of the four classifiers on the two data used. Decision trees showed overall performance than neural network RBF, support vector machine and Naïve Bayes classifiers in this study. Other feature selection methods would find promising results when used on credit card fraud data.
However, results from the evaluation show that the filter method (correlation analysis) used in this study had significant effect on the Taiwan credit data than the European bank credit card data. The paper further shows that the European bank credit card data reported unchanged optimal performance for raw and feature ranked dataset because the data had undergone PCA transformation prior to use.
Further studies can be done to investigate other feature selection techniques on credit card fraud data, especially the PCA method.