
Figure 1. Conventional Machine Learning Approach
Content based Music Information Retrieval (MIR) has been a study matter for MIR research group since the inception of the group. Different pattern recognition paradigms are used for the diverse application for content-based music information retrieval. Music is a multidimensional phenomenon posing severe investigation tasks. Diverse tasks, such as automatic music transcription, music recommendation, style identification, music classification, emotion modeling, etc., require quantitative and qualitative analysis. In spite of noteworthy efforts, the conclusions revealed show latency over correctness achieved in different tasks. This paper covers different feature learning techniques used for music data in conventional audio pattern in different digital signal processing domains. Considering the remarkable improvements in results for applications related to speech and image processing using deep learning approach, similar efforts are attempted in the domain of music data analytics. Deep learning applied for music analytics applications are covered along with music adversaries reported. Future directions in conventional and deep learning approach with evaluation criteria for pattern recognition approaches in music analytics are explored.
Music is a complex structure of musical ingredients with diverse genres and musical dimensions. Music dimensions, include melody, harmony, rhythm, timbre, tempo, etc. The vast opus of music evolved through centuries includes different music forms. It covers all sorts of music demonstrated and generated in different parts of various countries since its origin. It is a continuous process and the novel musical forms are presented by the performers to add new dimensions to it. Popular music typically includes Rock, hip hop, pop, country, EDM, etc. Various cultural traditions include Indian and western classical forms, Turkish makam music, Beijing Opera, Arabic music, etc. (Serra, 2014). These musical genres are like various languages spoken around the world and music has a potential to convey message or emotions despite of familiarity with the genre. Each form of music has its own unique appeal and specific composition rules. Fusion of different forms generates new musical form. This generates many potential features and musical patterns. Musical features are of different types, such as genre specific, generic, low level, high level features, harmonic, rhythmic or melodic features, and so on enriches the feature set along with new feature inventions for specific applications. Musical patterns can not only relate to melodic, rhythmic, or harmonic, but to discover new relationships among different musical parameters such as co-relation of pitch and intensity, use of specific instrumentation and melodies to represent signature of composer, etc.
With the use of social websites and internet, music data generated by users is growing at enormous speed. Huge data shared and uploaded by users in various formats such as audio or video poses serious challenge for storage and retrieval. Music generated by computers with artificial intelligence is adding more opportunities and challenges to handle this big data. Unavailability of proper annotation tags for music makes the retrieval task more difficult. Involving human efforts for tagging is time consuming and getting experts with musical knowledge is another challenge in human involved process. With gigantic fast development of music information, including people to deal with this enormous information turns into the discounted alternative. Automatic tagging with content-based analysis remains the only viable approach. Intelligent music analytics to build intelligent systems without human intervention is the need of today and new challenges of music big data in the future is likely to make use of intelligent music analytics inevitable. MIR researchers have applied different signal processing approaches and algorithms in last decade or so to carry out different tasks for music audio processing and analysis. Different machine learning techniques are proposed and successfully used to solve specific problems in computational musicology. Despite of extensive research in last few years, lot of new challenges and research directions are opening up in this domain with growth of digital music over internet.
Conventionally the research in music Pattern Recognition (PR) domain uses typical machine learning approach as shown in Figure 1. Conventional or traditional approach mentioned here refers to the era before deep learning approach. It involves extracting features from the music audio signal and supplying these features to the classifier used in various applications.
Figure 1. Conventional Machine Learning Approach
Figure 2 represents deep learning approach which involves no human intervention and the end to end approach makes the entire process automatic right from musical data to application to get the desired output. Huge musical dataset is prerequisite of the deep learning approach. Features are learned from the data itself. Automatic feature learning replaces feature extraction or hand-crafted features used in the conventional system. This approach involves pre-training and fine tuning of various parameters of the deep neural network used. Trained neural network acts as a classifier; however, training of neural network generally involves huge computational efforts and substantial time. Deep learning approach is also referred as black box approach by some researchers as it works on the basis of relevant unknown features learned over a period of time.
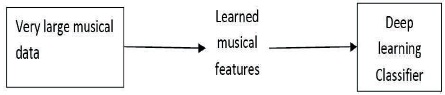
Figure 2. Deep Learning Approach
The paper covers comparative analytical approach of conventional and deep learning for music analytics.
Conventionally, Music feature engineering uses different digital signal processing techniques to the musical audio acoustic data to generate feature values associated (Muller, Ellis, Klapuri, & Richard, 2011). Digital signal processing in time or frequency domain are generally used approaches to extract relevant features. In case of noisy audio samples, noise removal methods using digital filters are used (Roads & Strawn, 1996; Apte, 2013).
Melodic pattern recognition using conventional feature engineering for pitch extraction is as shown in Figure 3. The figure shows pitch information captured for 57.03 seconds as marked on the X axis. Y axis with the range of 75 to 500 Hz represents the pitch values extracted. It can be observed from the figure the pitch pattern with variations in pitch values on different time instance. Similar looking melodic patterns can be observed and it is interesting to explore these similar looking patterns for pattern matching. Different tools are developed by researchers to support various features and allow several parameter settings, such as MIR toolbox, Librosa, Praat, etc. Praat was developed mainly for speech and used successfully for melodic pattern identification for voice audio samples (Ramesh, 2008). List of different tools along with the features supported are given in Table 1.
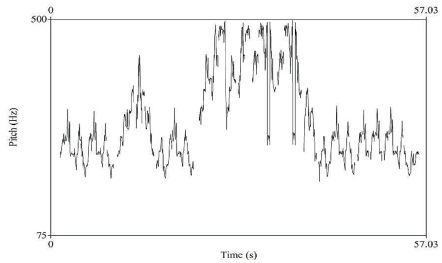
Figure 3. Pitch Contour Melodic Pattern Extraction using Conventional Approach
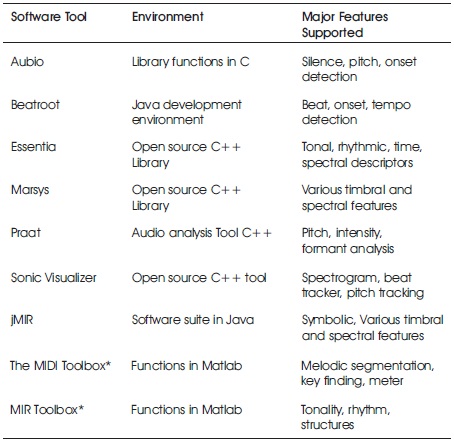
Table 1. Software Tools and Features Supported for Music Pattern Recognition
Most of the software tools mentioned is under general public license and are available on their respective web domains for free download and usage. Tools developed for Matlab requires Matlab as essential prerequisite, which is not under general public license. Various feature values are directly obtained using such ready-made tools. Information related to details about different features, formats supported by specific tool is available in the respective documentation. Various applications are proposed and successfully attempted using the conventional feature engineering, such as query by humming (Makarand & Parag, 2018), music recommendation systems (Rosa, Rodriguez, & Bressan, 2015), etc. A novel approach for music search based on content-based similarity and human perception was proposed as an alternative to present metadata-based search (Makarand & Sahasrabuddhe, 2014).
Visible musical patterns such as melodic (Figure 3) or rhythmic (Figure 4) patterns can be represented using the tools available. Figure 4 shows the part of audio clip and beats identified shown as B at different time instances using beat finder algorithm. This helps to identify beats at specific time instance and Beats Per Minute (BPM) for the musical audio clip. Hidden musical patterns are some relationships or associations within musical piece. These are not directly visible and statistical analysis of the feature data or unsupervised learning approach helps to find such musical patterns. Feature vectors are the feature values of the features considered for the specific application.
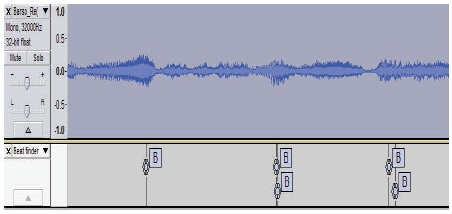
Figure 4. Rhythmic Pattern with Beat Finder
Automatic instrument identification is a typical application in music analytics. Pattern recognition approaches can be classified according to the domain from which we extract features such as time domain or spectral domain. Time domain features for instrument identification include the shape of the note, which is represented using ADSR envelope. The features measured are attach time (A), decay time (D), sustain time (S), and release time (R) of the note for different instruments to model the feature vectors. Spectral features include features such as spectral flux (rate of change of power spectrum), spectral centroid (provide impression of brightness of sound), spectral Roll-off, MFCC (Mel frequency cepstral coefficients), etc. Detail discussion with sample programs in Matlab is available (Apte, 2013) for interested readers.

Typical feature vector with different features extracted can be seen with sample feature vector with features and values extracted from one nursery music file is as shown above in XML format. The feature vector is represented as feature name and corresponding value or values is/are extracted using a tool jAudio. The feature vector can be represented in csv or arff file format, which are generally used for many machine learning tools.
Deep learning is a recent approach developed with neural networks for pattern recognition. Deep learning terminology refers to the framework in which the entire process from the input data to the output of an application is learned from the data. This approach reduces the requirement of prior knowledge about domain and problem. It slashes overall engineering efforts and human intervention in feature generation and other tasks related to the application. Artificial Neural Network (NN) is a parallel computational model consists of variable interconnections of simple units to simulate human brains. The success depends on quality of training data and the algorithms used for a specific application. The increasing acceptance of neural network models to solve PR problems has been mainly due to their capacity to learn intricate non-linear input-output relationships, little dependency on domain-specific knowledge, and availability of efficient learning algorithms.
Many variants of NN have been used successfully for different PR problems in music.
Use of dynamic programming and recurrent NN with hidden states is found superior with 80.6% accuracy relate to other models tested using 10-fold cross validation approach (Boulanger-Lewandowski, Bengio, & Vincent, 2013). Convolutional NN trained using spectrogram features showed encouraging results for automatic boundary recognition in musical patterns with improvisation in F-measure from 0.33 to 0.46 for tolerances of ± 0.5 seconds (Ullrich, Schlüter, & Grill, 2014). NN are being used for pattern generation along with recognition successfully in the music synthesis by many researchers (Baratè, Haus, & Ludovico, 2005; Klinger & Rudolph, 2006; Mozer, 1994; Eck & Schmidhuber, 2002; Liu & Ramakrishnan, 2014). Automatic feature extraction is an essential component of deep learning. Deep learning approach gaining popularity with considerable success in speech and image processing is likely to be useful for music PR and research is going on in similar directions in computational music analytics.
Deep learning attempts to model data abstraction using multiple hidden layers of the neural network as shown in Figure 5. Music audio files in image format are presented as an input in convolutional neural network. Convolutional layers attempt to abstract the high-level features from the music image. Fully connected layer attempts to map high level features abstracted to the classes and provides probabilities of different n classes shown as P1, P2, … Pn. The class with higher probability is likely the classification of input data. Music classifications for genre, artist, instrument, emotions are different applications being attempted using deep convolutional neural network. It replaces need of handcrafted features using feature learning and extraction algorithms. It transforms input data through multiple layers with artificial neuron as a processing unit, which are trained using algorithms such as back propagation algorithm which is widely used.
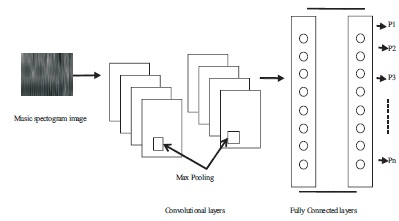
Figure 5. Deep Convolutional Neural Network for Music Classification
Deep learning approach was successfully used in the applications such as self-driving cars recently (Bojarski et al., 2016). This approach is expected to learn patterns or structures on their own and fine tune the performance of the system over a period of time. Some artificial Intelligence researchers believe that system's ability to design and learn can outperform human abilities in the complex and parallel processing environment. Considering millions of available music tracks and exploratory growth of music over internet, tasks such as music pattern analysis and retrieval for the huge growing data will be a challenge in coming years. Deep learning approach will be better and may be better alternative in such situations.
Deep learning approach investigated to apply feature learning to raw audio using convolutional neural network show feasibility of approach, but failed to achieve the performance levels compared to spectrogram-based approach. Area under the ROC curve was the performance measure compared with spectrogram-based approach value as 0.8815 and raw audio value as 0.8487 (Dieleman & Schrauwen, 2014). Deep learning has been applied to music classification since 2009 with probably the initial attempts were from Lee with maximum accuracy of 73.1% for specific training data (Lee, Pham, Largman, & Ng, 2009). They used convolutional Deep Belief Network (DBN) for audio recognition task of speaker identification and shown improved test accuracy. In music domain, results for genre classification and artist identification using DBN were better as compared to raw and MFCC features. Similar approach used by Hamel (Hamel & Eck, 2010) around same year shown that feature learning using DBN outperformed timbre and temporal feature set for the task of auto tagging for genre identification. Convolutional neural network for musical pattern features was alternative suitable model suggested and revealed the need of enlarged data set for robust performance (Li, Chan, & Chun, 2010). The initial research work (Lee et al., 2009; Hamel & Eck, 2010; Li et al., 2010) stated the need to reduce training time for the model using deep neural network and shown promising results with the novel approach.
Since then many researchers have applied deep feature learning approach for various different tasks. Music recommendations with ROC as 0.77 with CNN (Van den Oord, Dieleman, & Schrauwen, 2013), playlist generation with convergence time as 3.3 seconds over 12 seconds with normal approach for large dataset with 1,50,000 data items (Aucouturier & Pachet, 2002), automatic transcription (Ewert, Pardo, Müller, & Plumbley, 2014) are some of the applications attempted along with most frequent tasks such as genre and mood identification (Sturm, 2014; Bertin-Mahieux, Eck, & Mandel, 2011; Yang & Chen, 2011). Deep learning approach has shown encouraging results recently for different problems (Deng & Yu, 2014; Goodfellow, Bengio, Courville, & Bengio, 2016). Some adverse results are reported for neural networks-based approach by few researchers also. Szegedy et al. (2013) show how PR system can be misleading in the neural network classifier to show improper results with strong confidence. The explanation about such hostile results provided as a possible effect of small perturbation in each dimension at input layer getting magnified at output layer (Goodfellow, Shlens, & Szegedy, 2015). Similar contrary results are reported for image PR using neural networks recently (Nguyen, Yosinski, & Clune, 2015; Dalvi, Domingos, Sanghai, & Verma, 2004). Deep learning for music adversaries covered in detail gives word of caution and need of more investigations in the directions suggested (Kereliuk, Sturm, & Larsen, 2015).
Despite of some opposing results, deep learning is gaining popularity among researchers due to availability of free open source codes, efficient machine learning methods for deep networks and no need of any prerequisite of expert domain knowledge. Deep learning approach is useful for computational music due to some inherent properties of music and adaptability to the deep learning architecture. It supports hierarchic musical representation for notes or chords in frequency domain and rhythm or onset in time domain. Input data for deep learning can be in any form such as spectrogram image or raw audio for feature learning. Short-time or long-time duration musical features such as note and musical structure respectively can be analyzed using variants of convolutional and recurrent neural networks. It supports different music representations in the form of images such as symbolic data in sheet music, spectrograms, etc.
Emotion recognition is considered as a tough task in speech and music. The cross-channel architecture coupled with convolutional neural network has shown improved results for speech and music emotion detection problem for different datasets. Accuracy achieved with cross-channel architecture was 83.9%, 82.9%, and 22.4% for GTZAN, SAVEE, EMOTIW datasets, respectively (Barros, Weber, & Wermter, 2016). Intelligent systems are not yet advanced to solve such difficult task, which is a hard challenge for humans ourselves. Recurrent neural network with deep learning approach proven better than previous approaches on the same recorded large database for task of event detection in polyphonic music with F1 score of 65.5 improvement of 6.8% (Parascandolo, Huttunen, & Virtanen, 2016). Feature adapted convolutional neural network model trained proposed for downbeat tracking applied for 9 different datasets have shown better results using F measure as a comparing parameter for evaluation over all improvement of 17.1 percentage (Durand, Bello, David, & Richard, 2016). The model based on hybrid recurrent neural network for automatic music transcription shown improved performance with 74.45 F measure value for real time application to convey suitability of model and reported the possible limitation of the model and unexplored research challenges (Sigtia, Benetos, & Dixon, 2016).
Deep Convolutional Neural Networks (CNN) used successfully for prominent instrument identification in polyphonic music with performance upgrading over recent approach, but also mentioned the need to applying musical knowledge in design of the system to improve performance. The proposed convolutional network architecture obtained an F1 measure of 0.602 for micro and 0.503 for macro, respectively, achieving 19.6% and 16.4% in performance improvement compared with other state-of-the-art algorithms (Han et al., 2017). 5-layer CNN based on the inverse-transformation of deconvolved spectrograms used (Choi, Fazekas, & Sandler, 2016) shown that in the deep layers, the features are learnt to capture textures, the patterns of continuous distributions, to genre classification with the variations of key, chord, instrument, etc. Unsupervised feature learning using deep NN proposed (Xu et al., 2017) for automatic environmental audio tagging showed improved results with reduction in equal error rate EER by 6.7% compared to other models such as GMM and SVM. To adapt deep learning for music, a novel CNN strategy proposed by (Pons & Serra, 2017) consists of representing musical concepts by modeling diverse time-scale contexts within the first layer. DNN named Triplet MatchNet (Lu, Wu, Duan, & Zhang, 2017) proposed to learn metrics directly from raw audio signals with help of supervised approach as human annotated triplets of music excerpts display the method considerably beats other 3 state-of-the-art music metric learning approaches. Convolution recurrent neural network proposed by (Choi, Fazekas, Sandler, & Cho, 2017) for music classification uses CNN for local feature extraction and Recurrent Neural Networks (RNN) for temporal summary of features extracted shown robust results considering the number of constraint and training time, signifying the usefulness of its hybrid structure for extraction and music feature summary. These examples illustrate potential use of deep learning approach with CNN in the domain of computational musicology.
Music can be viewed as an abstract image, which can be interpreted differently by different listeners with diverse musical and cultural background. Music signal generally has rich harmonics and have huge variety with different time varying motifs. Deep learning approach needs to bridge a wide semantic gap between music audio signal and user preference. Audio signal representation in domains, such as time, frequency, or cepstral domain needs to derive listener expectations, such as genre, artist, instrument, tune, rhythm, mood, popularity, lyrics, time, location, etc. Deep learning approach produces serious research challenges in the MIR community considering multifaceted and multidimensional music signal.
Conventional feature engineering approach has been successfully used for various applications and it has been the favourite method by many researchers since last few years. In case of small data and standard computational resources availability, this approach is more suitable. Deep learning requires huge data and heavy computational power for the desired results in faster way. Training of deep learning is quite time consuming. For some applications in which features are distinctly noticeable and captured successfully, conventional approach is more suitable and likely to provide better results.
Automatic feature abstraction and learning using deep learning approach is a recently developed method. Deep learning with multiple hidden layers of artificial neural network is a promising learning tool, which has shown remarkable accuracy improvements recently in the fields like speech recognition, image processing (Hinton et al., 2012; Simonyan & Zisserman, 2014). Deep learning is more suitable for multimedia data like images, audio, video in which the features are readily not available in numbers. Music data is an excellent candidate for deep learning and researchers are exploring new approaches for music data. Hybrid approach using both handcrafted features and features from deep learning have improved the results in application such as music recommendation (Wang & Wang, 2014). The full deployment of this approach in computational music is still awaited and we may get exciting results and applications in near future.
Real challenge is to achieve computational intelligence in musicology is music modelling. We humans ourselves have not able to judge the entire musical aspects in true sense to model it for further processing. Modelling human perception and fast feature learning scalable parallel algorithms will lead further progress in the domain. Interesting end to end applications for various tasks using more advanced music recognition systems are likely to dominate in coming years. Structural approaches along with statistical methods as a combined technique may be more useful for the musical applications as music is a felt phenomenon and not only just numbers. Although quantitative evaluation dominates the present research, mixed methods with combining qualitative and quantitative analysis can be more useful for music analytics. Human perception is subjective in nature and differences in perspectives lead to limited inter-rater agreement. These levels of inter-rater agreement illustrate a natural upper bound for any sort of algorithmic approach.
Incorporation of human music perception and cognition in feature engineering will provide better results. Musical knowledge and pattern representation using advanced visualization techniques to model and simulate human system will advance in coming years with more insight into human music decoding. Considering millions of available music tracks and enormous growth of music over Internet, tasks such as music pattern analysis and retrieval for the huge growing data will be a challenge in coming years. Numerous innovative learning algorithms can be proposed in near future for efficient music retrieval. Modelling human perception and fast adaptive learning algorithms will be the key in designing future intelligent systems.