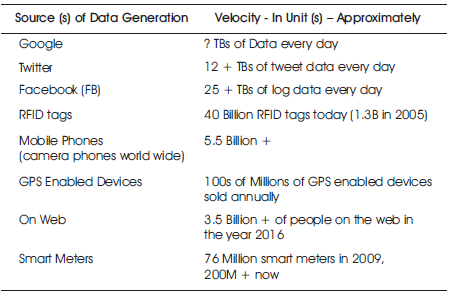
Table 1. Rapid Growth of Data (Big Data) Generation with its Velocity
This review attempts to comprehend the insights and foresights into the grasping power of data science, data quality, data process, data pre-process, big data, big data process and analysis, analytics, BD (Big Data) and analytics lifecycle, file storage, platforms/technologies supported, Hadoop concepts, eco-system components, and design principles. Principle and philosophy behind computations are also explained through flow diagram. Various analytics based on its solutions, cluster computing based platforms like Apache Spark (its architecture – core, other components, and utilities), MLlib package – Machine Learning (ML) methods/ tasks and detailed supported algorithms are exclusively elucidated, to understand the concepts of these pinpoints. The explored comprehensive contents would definitely be useful and provide core understanding knowledge in the large scale ML dependent algorithms process, suitable to build the relevant application solutions (may be predictions/ classifications/ segmentations/ recommendations) via Apache – Spark environment.
Big Data will be the next front runner for any innovation since data is embedding with modern human life style. According to National Association of Software and Services Companies (NASSCOM), Big Data analytics sector in India is expected to witness eight fold growth to reach $16 billion by 2025 from the current level of $2 billion. The current sector has huge growth potential by 2025; India will have 32 percent share in the global market. Core methodology of data analytics is ML, which is a highly important component to deliver the right model in the line of BD applications. It is mandatory to understand the nook and corner of data process to ML large scale processing knowledge through BD technologies/ platforms with Hadoop/ Spark tools. All possible contents, detailed in a step by step manner, to reach out the right model development by handling high growth data, is being rapidly penetrated from various sources and are shown in Table 1.
Table 1. Rapid Growth of Data (Big Data) Generation with its Velocity
DA (Data Analysis) is a science (Nair and Ganesh, 2016), which is used to examine the raw data and for drawing conclusions about the information. It is a real-world use of Big Data. Data Science is about two aspects such as extracting deep meaning from the data and creating “data products” (Software system). It combines the traditional scientific methods with the ability to crunch, explore, learn, and gain deep insight for Big Data. There will be an increasing demand for Big Data Analytics (BDA) in Data Science Age due to evolution of streaming data.
Data Science process is explained in a flow manner so as to understand the meaning (concepts) of raw data, data quality, data preprocessing, data processing, data analysis, and analyzing the same through BD platforms/ using technologies or tools, to model the specified Data analytics.
Data→ Kinds of Data (un/semi) structured data→ Data Quality (data understanding/ examining the data)Data preprocessing: Data [Clean, Integration, Transformation, Aggregate, and Reduction] Imperfect Data: Missing, Noisy etc., Reduce Dimensionality... → Data processing [Explore, Represent, Link, Learn from Data, Deliver insights...]→ Data Analysis [By Machine Learning -(Classification, Clustering, Regression, DT, Association, Visual Analytics etc., )] Data analytics/ Type of analytics-via BD Platforms/ Technologies / Tools.
According to Harvard Business Review, Data Scientist is a high-ranking professional with the training and curiosity to make discoveries in the world of Big Data. Data Scientist needs to have deep knowledge of a domain area, as well as the technical knowledge of computer science, statistical techniques, data analytics, and modeling methods like Data Mining and Machine Learning, and also soft skills.
Big data is high-volume and high-velocity and/ or highvariety of information assets, that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation. Big Data, also referred to as “Data Intensive Technologies”, are targeting now to process highvolume, high-velocity, high-variety data (sets/ assets) to extract intended “data value” and ensure high veracity of original data. Health Big Data Analytics (HBDA), would become “Healthier Analytics” (Saravanakumar and Hanifa, 2017) in decision making to improve the quality of patient's life, predict epidemics and reduce preventable deaths.
With Big data, the ability to collect data will only increase but ability to analyze the data will only improve.
The following are the different definitions in connection with big data.
Accessing, analyzing, securing, and storing big data are done using one of the most alleviating technologies called, “Big Data Technology”. Related platforms are listed below.
Apache Hadoop (can per form data-intensive applications), Apache Spark (fast cluster computing platform), Apache Flink (faster than Apache spark), Apache Hive, Apache Flume, Apache Sentry (Hadoop Security), IBM Infosphere, Apache S4, RHadoop (ML Packages), Horton Hadoopworks, Twitter's Storm, Dremel by Google's Big Query services, Lambda Architecture, epiC. Hadoop's Core and Eco-systems potency can be considered as a “Dispensing Pipeline”.
Four aspects of classification are categorized in a bulky scale data (Verma et al., 2015) as given below.
Hadoop is a software framework for distributed processing of large datasets across large clusters of computers. It can handle large datasets (terabytes/ petabytes of data) and large clusters (hundreds or thousands of nodes). It is based on a simple data model, any data will fit in. Hadoop does not support updating of data once the file is closed, but rather supports appending in the file. In 2005, Doug Cutting and Michael J. Cafarella developed Hadoop to support distribution for the Nutch search engine project.
Hadoop tools can help and solve real problems. Figure 1 presents the detailed understanding of each tool.
The tools used for various purpose are listed below.
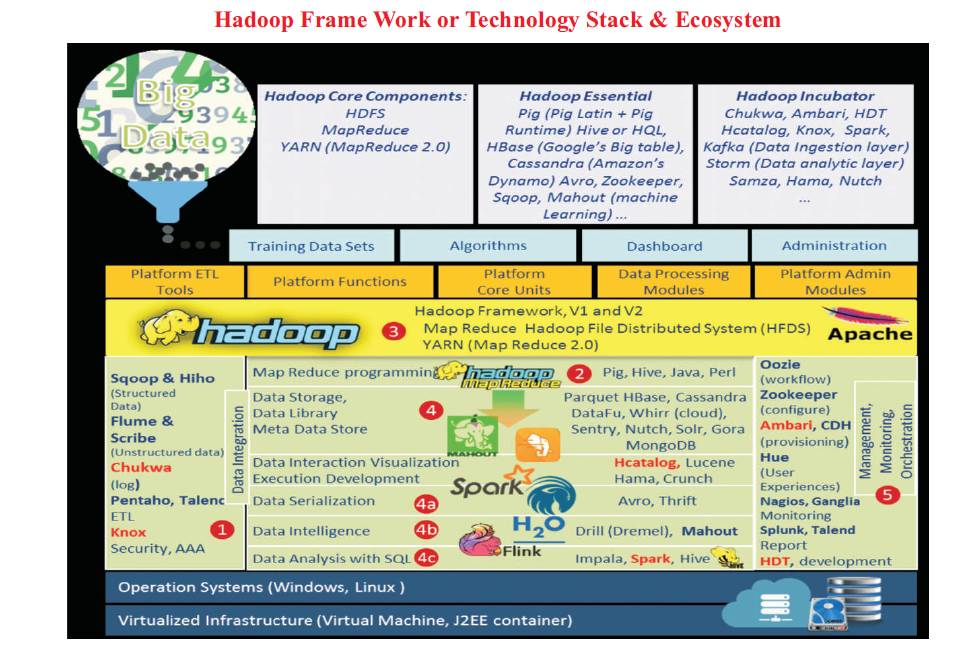
Figure 1. Hadoop Framework Stack and Ecosystem
Hadoop is promising to adhere the design principles so as to deliver the right applications to the end-user. The following are the important principles to be adopted, when executing the design.
Hadoop Architecture (Master/ Slave model) consists of Hadoop Common and has three core components such as Hadoop Distributed File System (HDFS), MapReduce (MR), and YARN (Yet Another Resource Negotiator). Hadoop is concerned with three types, such as Apache Hadoop, RHadoop, and Hartonworks Hadoop. MapReduce (MR) Framework allows massive scalability and processing of extremely large file. MR is the heart of Hadoop, where the processing is carried out by assigning the tasks to various clusters. All complex components can be combined as a Big Data Ecosystem (BDE) as shown in Figure 1. Their deals with the evolving data, models, and supporting infrastructure during the whole “Big data life cycle” is given in Table 2.
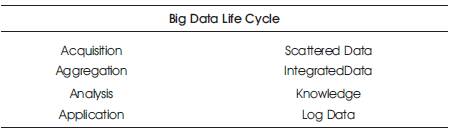
Table 2. Big Data Life Cycle
Storage is a critical component in data centres, which continues to grow in their size to accommodate the volume of data. Data Storage is the place, where data is held in an electromagnetic or optical form for access by a computer processor. In modern enterprises, data storage becomes the best business technology especially in large scale data like big data which are detailed below.
It is a terminology, which deals with storage technologies, especially for large scale data, represents long-term persistent storage and retrieval of both structured and unstructured data of geographically dispersed locations
HDFS is a DFS designed, to be fault tolerant and deployed on low cost hardware. It provides high throughput access to the data, suitable for applications with large scale datasets, and also supports the streaming access to file system data. Hadoop implements Google' s MapReduce, using HDFS.
MapReduce (Dean and Ghemawat, 2008) is a batch query processor and data-parallel programming model (consists of four steps like Input files Splitting, Mapping (Distribution), Shuffling + Sorting =Reducing (Parallelizing), and Aggregating Output files], hides complexity of distribution and fault tolerance (where Map = Distribute, Aggregate, Collaborate, and Reduce = Parallel processing). MapReduce divides applications (input data) into many small blocks of work. HDFS creates multiple replicas of data blocks for reliability, placing them on compute nodes around the cluster. Resilient to hardware failure, moving computation closer to the data, portable across all platforms developed in Java are the mail goals of Hadoop.
Python (can write minimum code), Scala, Java, Ruby, R (better visualization) and Clojure are the BD supported languages or Application Programming Interfaces (API), by using them, wonders can be done in the model development. Moreover, one must familiarize in Unix shell commands along with SQL commands to deliver better applications.
The overall life cycle behind big data is illustrated in Table 2.
Analytics technology refers to the systematic computational analysis of transforming data into information; it is described as "data-driven decision-making(Saravanakumar and Hanifa, 2017)
The main goal of analytics technology is to capture data collected from different sources and analyze these data to reach an optimal decision. Analytics ("Data Analytics") refers to the organized computational analysis to transform....
Data->into->Information->Knowledge->Intelligence, called "Data-driven decision-making".
Bring computer to data rather than bringing data to computer.
i.e., understanding the method by which data can be preprocessed is important to improve data quality and the analysis results. Prior to data analysis, data must be well constructed.
Divide and Conquer (i.e., Data Partitioning) for large datasets.
The above mentioned is the philosophy of computation.
The purpose of using Big Data or BDA is to gain;
Hindsight - metadata patterns emerging from historical data
Insight - deep understanding of issues or problems
Foresight - accurate prediction in near future
Based on the solutions, analytics can be classified into four, (Refer Table 3)

Table 3. Types of Analytics based on its Solutions
There will be a sequence (phase) of processes called “Project Life Cycle” for developing a better (conceiving) big data analytics to visualize its performance with the stakeholders satisfaction, called “BD Analytics Project Life Cycle” which is detailed in Table 4.
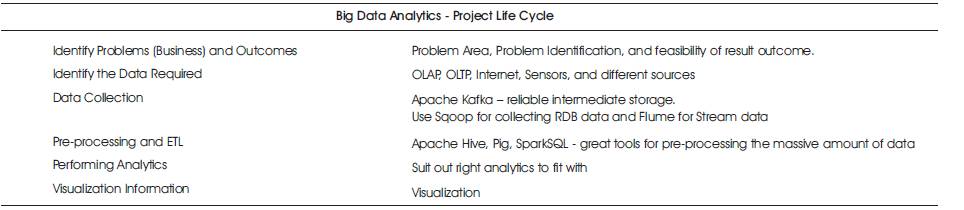
Table 4. BD Analytics - Project Life Cycle
Different dimensions of BD are elevated from 3 V's to 6 V's (Coined by various vendors) followed by 10 V's (Figure 2) and BD value chain, starting from data acquisition to data usage is depicted through figurative form in Figure 3.
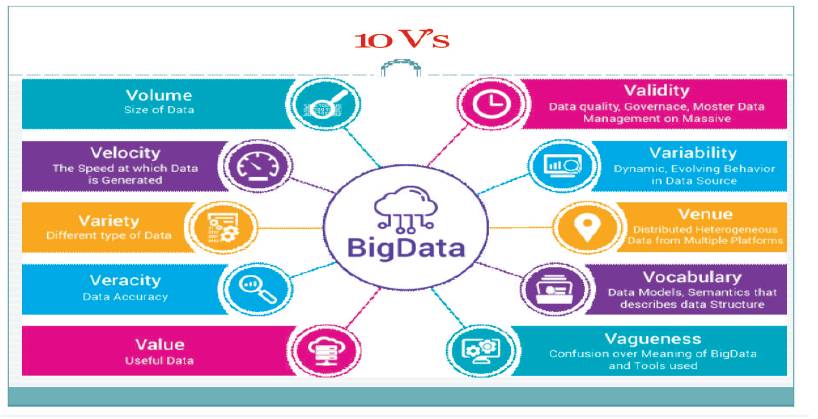
Figure 2. BD Dimensions (10 V's)
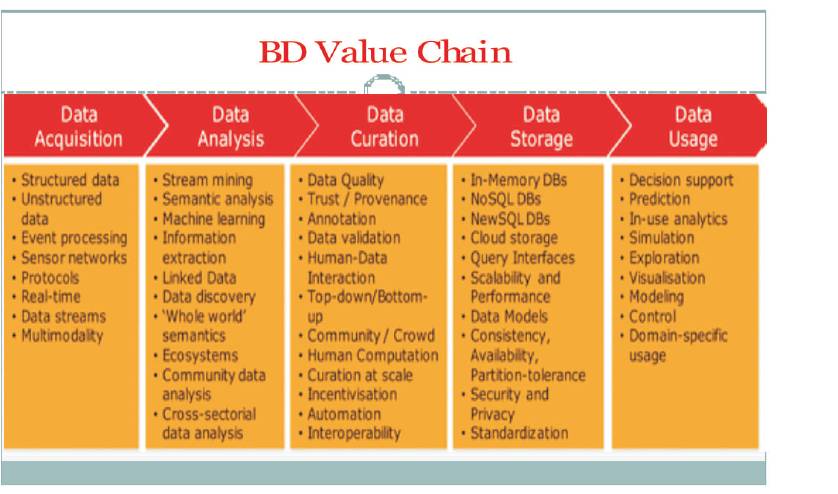
Figure 3. BD Value Chain
Spark, cluster computing architectural model to Big Data solution works in both in-memory and on-disk since it holds intermediate results in memory instead of writing data on disk. It is the most active open source project in big data and has a calibre to replace Map Reduce (MR) (Need not write MR code). It is a flexible in-memory data processing for Hadoop in the line of easy development, flexible, extensible API and fast batch and stream processing. Supporting of lazy evaluation of big data-queries helps in optimization of the data processing workflows. Resilient Distributed Datasets (RDD) is one of the key programming abstractions for parallel programming model in Spark. It helps in backtracking and completing a task instead of starting everything from the scratch.
Spark consists of seven major components such as Spark Core Data Engine, Spark Cluster Manager, (includes Hadoop, Apache Mesos, and built-in standalone cluster manager), SparkSQL, Spark Streaming, Spark MLlib, Spark GraphX, and Spark Programming Tools.
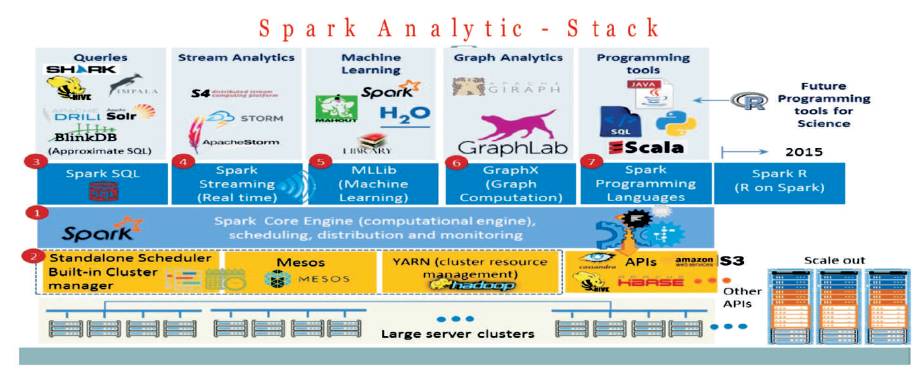
Figure 4. Spark Analytics - Stack
To analyze the massive data set, it is essential to have suitable hardware, software. i.e., it must have effective computing platforms, developing tools and algorithms. Huge datasets are analyzed with respect to data volume, band width of network used and different constraints of computations like end-user locations, algorithms/ techniques used etc., Four computational platforms are used to perform large data set analysis like Super computing, Grid computing, Cloud computing, and Heterogeneous computing (it uses computational processors such as GPP (General Purpose Processors) and GPU (Graphics Processing Unit).
There are two levels of scaling such as;
Machine Learning (ML) is the science of making machines to work without programming – predefined rules and learning from data. It involves training or fitting a model on historical data and using the trained model to leverage predictions for new data (unknown data) using testing file. The core methodology in Data Analytics (DA) is Machine Learning (ML); it is an area of computer science, that aims to build delivery systems and algorithms that learn from large datasets, and meeting out analytic tasks through required algorithms are also one of the essential parts of BDA. The essence of ML is an automatic process of Pattern Recognition by a Learning Machine. ML uses data to make any inferences or predictions to the specified tasks. Historically, many terms to describe the equivalent meaning of ML, such as “Learning from data”, “Pattern Recognition”, “Data Science”, “Data Mining (DM)”, “Text Mining” or even “Business Intelligence” etc. One of the major techniques of ML is Data Mining (DM) where, the following patterns of data are looked into.
Spark is a general-purpose big data platform. MLlib is a standard component of spark providing machine learning primitives on top of spark. MLlib built on Apache spark is a fast and general engine for large-scale data processing and specialized in large-scale machine learning. It runs programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. It also writes applications quickly in Java, Scala, or Python.
These are comprehensively explained in Table 5 to understand the spark.ml package by the application developer(s). MLlib consists of ML algorithms for faster execution of programs.
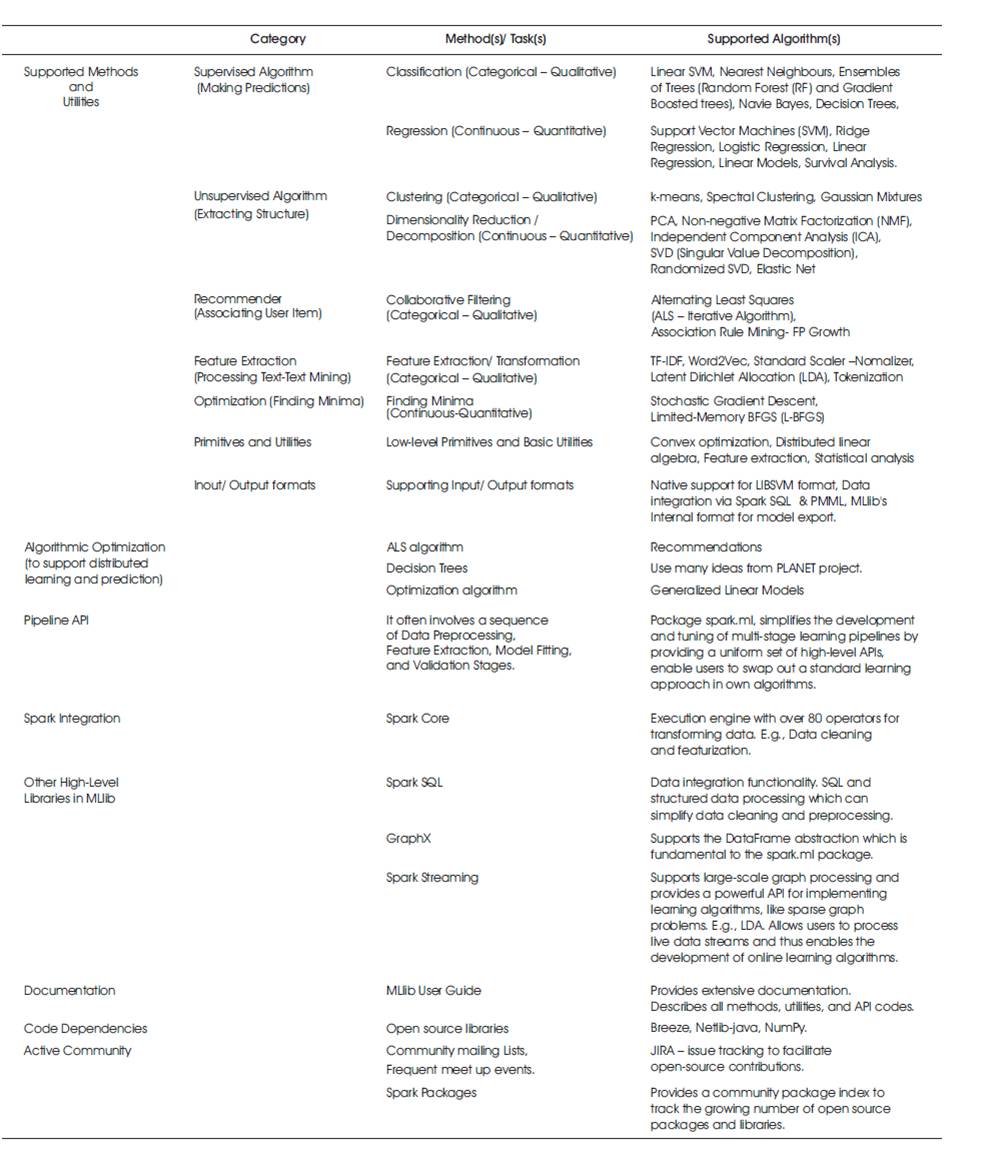
Table 5. List of MLlib - Apache Spark Supported Algorithms
Apache Mahout is ML library built on top of Hadoop, now integrated with Apache Spark to provide “in-memory” performance and avoid scalability issues (Table 6).

Table 6. Apache Mahout in ML Library
Table 7 describes the complete details on Spark components and core benefits of in-memory computing called Apache Spark to build any BD analytical applications.

Table 7. Spark Components
ML based Recommendation Systems (RS) have become very popular and are necessary in recent years for a variety of applications. Recommendation is the key to success for discovering and retrieval of content in the era of huge data and is a proven case of BD. BD allowed us to do recommendations in a new scale that have not seen before. RS belongs to a research area in health care domain and is a classical example for Machine Learning (ML) applications by providing quality recommendations (Katarzyna, 2006). Applications of RS in health domain are still emerging and are widely used in health care industry to facilitate better health services to patients like food recommendation on diabetes mellitus, immune system disorders, and also to assist doctors and hospital personnel to make decisions.
The key role play by collective-intelligence RS in health care is greatly increasing and used to find behavioural changes for a wide range of health conditions (Wiesner and Pfeifer, 2014; Sadasivam et al., 2016). There are two broad categories of recommender engine algorithms (Verma et al., 2015) such as user-based and item-based recommenders. These recommendations are based on two filtering techniques namely collaborative and content-based filtering techniques. Collaborative filtering is used to understand the future behaviour of a patient with respect to the disease and has tremendous future applications.
Taxonomy of Remote Sensing techniques converges into three levels such as Collaborative Filtering (CF); (Memorybased CF and Model-based CF, and Content-based filtering. The taxonomy of recommender agents which is very worthy to mention and refer the Recommender Techniques such as Information Filtering Techniques [Demographic (Interest-filtering), Content-based, Collaborative filtering] and Matching Techniques [User Profile-Item Matching (Standard Keyword Matching, Cosine Similarity, Nearest Neighbour, Classification) and User-Profile Matching (Find similar users, Create a neighbourhood, Compute Prediction based on selected neighbours)]. Alternating Least Squares (ALS) algorithm is suitable and leveraged to find the appropriate recommendations for users, as in Apache Spark, substantially faster than Mahout.
Cloud Computing (Table 8) plays a critical role in BDA process as it offers subscription-oriented access computing infrastructure, data, and application services (Buyya et al., 2013). The original objective of BDA was to leverage commodity hardware to build computing clusters and scale out the computing capacity for web crawling and indexing system workloads.
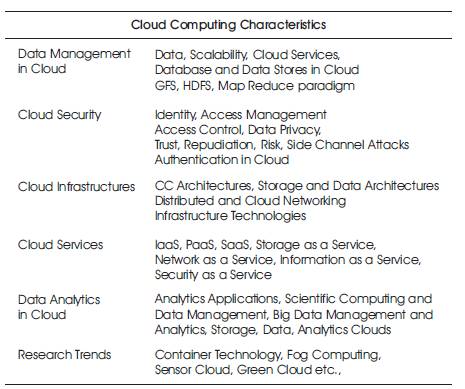
Table 8. Cloud Computing – An Outlook
The implementation of cloud computing were underpinned with three service models, four deployment models, and - five Characteristics (Caesar and Buyya, 2015), which is so called 3S-4D-5C definition, and is given below.
This review attempt assists the novice researchers' in understanding the A to Z of data, data quality, data preprocessing, data processing through large scale processing engines on selecting, applying, and evaluating the right ML supported algorithms (which are existing in the MLlib – Apache Spark platform). Along with that, design principles of Hadoop are explored in a comprehensive sense to attain the better solutions (building best data analytics) in BD environment.