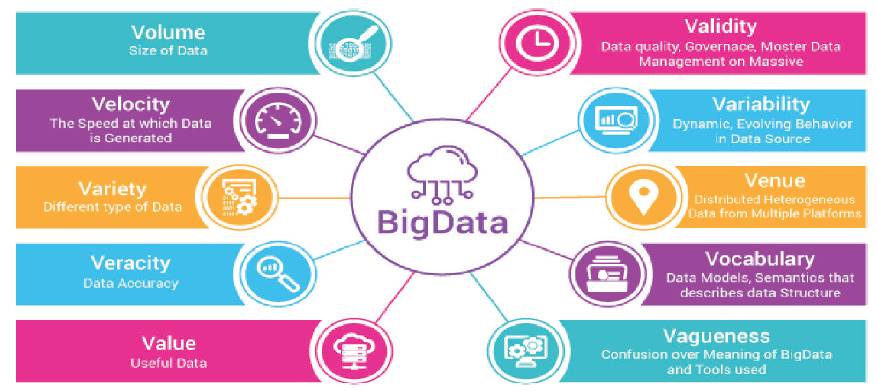
Figure 1. 10 V's of Big Data [3]
With the emergence and huge transformational potential capability of Big Data Storage (like store, manage and analyse huge amounts of heterogeneous data), finally derives the benefit of data-driven society and economic impacts. Since, the new wave of heterogeneous data rises from different sources, such as the Internet of Things (IoT), Sensor Networks, Open Data on the Web, data from mobile applications, and social networking, comprising that the natural growth of datasets available within the organisations, that certainly creates a demand for new data management storage strategies provide a new scales of data environment. Health sector is a first-rate scenario in this regard, to provide better health services to the society through the way of best integration and analysis of health related data by using current state-of-the-art in Big Data Storage (BDS) technologies, which identifies data-store related trends and capable of handling massive data. This survey paper discusses about the various emerging paradigms connected with BDS technologies, which gives options to both Hadoop and Spark, a fast and newly impacted computing avatar [i.e. In- Memory cluster (Multiple computers linked together, through a fast LAN, that effectively function as a single coputer) Computing] by replacing capacity of MapReduce through Resilient Distributed Datasets (RDD). It forecasts the entire features and availability options behind BDS, to deliver better data model in any Big Data (BD) dependent applications.
Big Data provides new opportunities to store and index previously unusable unstructured data for surplus uses by health care stakeholders. Analytics creates new business value by transforming this previously unusable data into fresh predictive insights and actionable knowledge. Dhanapal and Hanifa [6] review the importance of early intervention in Diabetes Retinopathy (DR) through retinal images, potential use of BD analytics and empowerment of BD ecosystems (where BDS is a kind of component for storage) towards prognosis strategy. Big Data is a term used to describe a massive collection of data sets from different sources with ten (10 V's) characteristics / properties (Refer in Figure 1) such as Volume (Size of data), Velocity (Speed - Generation of data ), Variety (Different types of data), Veracity (Data accuracy), Value (Usefulness of data), Validity (Data quality), Variability (evolving behaviour in data source), Venue (Distributed data from multiple platforms), Vocabulary (Data models and semantics that describe data structure), Vagueness (confusion over meaning behind big data tools) - are all newly emerged characteristics).
Figure 1. 10 V's of Big Data [3]
Big Data storage is a kind of big data infrastructure / platform concerned with storing and managing data in an accessible way by satisfying the required applications access to the data. A storage system consists of file systems, Big Data Management (NoSQL) system and Rational Data Base Management (RDBMS) system, which are discussed in detail in this paper. BDS would allow storage with a different data models, supported in the form of structured, semi structured, and unstructured data. To address the recent challenges, new storage systems are emerged.
Arrival and availability of new storage systems with a cheaper cost, this technology is empowered to process continual data in an effective manner as to transform BD in a real sense is shown in Figure 2.

Figure 2. Big Data-as-a-Service - Added Value at Each Stage
The Big Data Value Chain (Illustrated in Figure 3), can be used to model the high-level activities that comprise an information system. The Big Data Value Chain identifies the following key high-level activities, such as Data Acquisition, Data Analysis, Data Curation, Data Storage, and Data Usage.
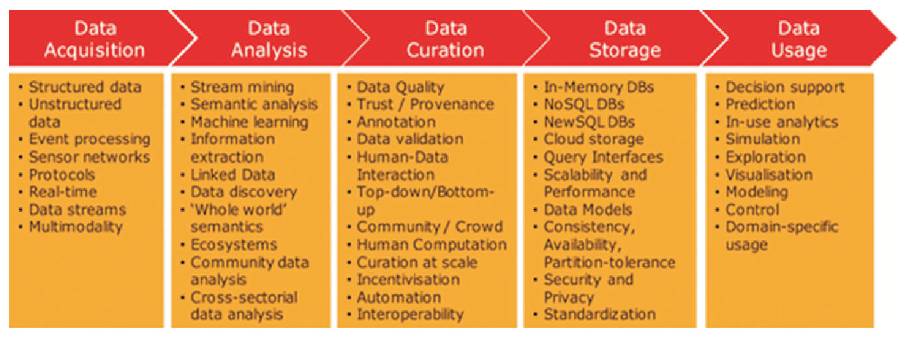
Figure 3. Data Storage in Big Data Value Chain [5]
Due to the convergence in data storage technologies, storage became a very good commodity based enterprise with a higher grade level. This ground reality evidence is offered by the use of Hadoop-based solutions provided by leading vendors like Cloudera, Hortonworks, and MapR, NoSQL2 database. By this advancement, it will improve the performance, scalability, and usability of storage technologies, which are still untapped now. Big Data Technologies possess some of the factors explained as below,
Ten properties of big data storage architecture help to formulate a vision of how big data could be managed in the long term, in cheap way that are listed as,
Four different categories of Big Data Storage Architectures are not mutually exclusive; fewer organizations utilize more than one in their execution.
During the last decade, (Turner et al., 2014) scale-up towards scale-out approaches led to flare-up of new big data storage systems, that shifted away from traditional relational database models. Big data stores are used in similar ways as traditional relational database management systems, e.g. for On-Line Transactional Processing (OLTP) solutions and data warehouses over structured or semi-structured data. Inbuilt strengths are in handling unstructured and semi-structured data at large scale and identify data store related trends. Following are differing types of storage systems.
File system that allows access to files from multiple hosts across network as Network File System (NFS), it tuned for file sharing than distributed computation. DFS application like HADOOP – is a tightly coupled DFS, provides single global namespace across all nodes and supports file parallelism. Example,
It is a family of BD storage technologies of NoSQL database management systems, use data models from outside the relational world, that do not necessarily adhere to the transactional properties of Atomicity, Consistency, Isolation, and Durability (ACID). Classifications of NoSQL DBs and its types are explained in Table 1. Eric Brewer proposed (2000) CAP Theorem (Consistency, Availability, Partition-tolerance) used as principle for designing NoSQL DBs. ACID guarantees for processing of DB transaction reliability and its mechanism must satisfy its characteristics like Atomic, Consistent, Isolated, and Durable.

Table 1. Types of NoSQL Database
It is next-Generation Scalable Relational Database Management Systems (RDBMS) for OLTP, that will deliver scalable performance of NoSQL systems for read/write workloads, as well as maintaining the ACID (Atomicity, Consistency, Isolation, Durability) properties, which guarantees of a traditional database system. The features of NewSQL database system is given in Table 2.

Table 2. Features of NewSQL Database
Big Data query platforms provide some simple data stores that typically offer an SQL-like query interface for accessing and managing the data, but vary in their approach and performance.
Hive provides an abstraction on top of the HDFS that allows structured files that are translated into an SQL-like query language and executes in MapReduce (MR) jobs in scale-out (add servers to increase capacity) manner. The Hadoop columnar store HBase is supported by Hive as shown in Figure 4.
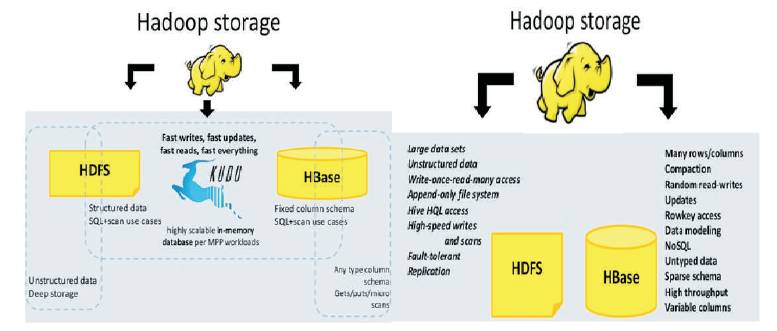
Figure 4. Hadoop Storage Architecture
Spark was designed to support for in-memory storage and efficient fault recovery, to face interactive queries and iterative algorithms. Spark provides primitives for Inmemory cluster computing, allows user programs to load data into cluster's memory and query it repeatedly, making it well-suited to Machine learning algorithms. Spark architecture are 10 times faster than Hadoop diskbased Apache Mahout. Spark's storage levels provide different trade-offs between memory usage and CPU efficiency. RDD storage should not be repeated, until fast fault recovery is needed. In-Memory processing access disk storage is used for storing processed intermediate data and also read data from disks which are not good for fast processing (Figure 5).
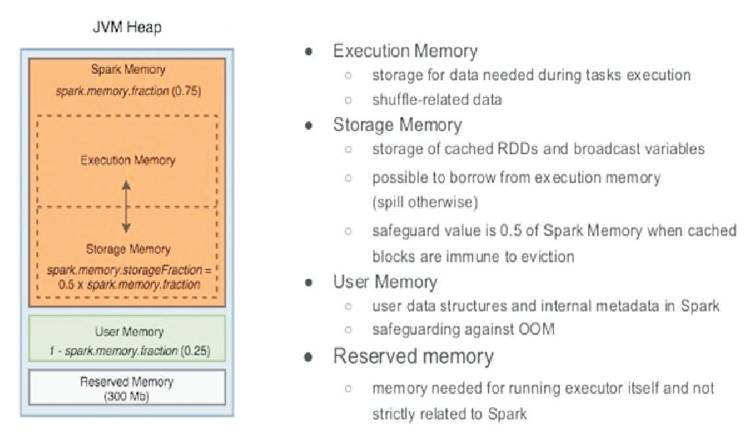
Figure 5. Batch Processing in Hadoop Ecosystem
With a swift influence and usage on Big Data, Cloud Computing grows in popular. Amazon, Microsoft, and Google build on their own cloud platforms, other companies like IBM, HP, Dell, Cisco, Rackspace, etc., build their proposal around OpenStack, an open source platform for building cloud systems (OpenStack, 2014). According to International Data Corporation (IDC), by 2020, 40% of the digital universe will be touched by cloud computing, and as much as 15% digitization will be maintained in a cloud. In general, Cloud and Cloud Storage can be used by enterprises and end users as well. Cloud enables data access from everywhere, from every device in a reliable way to the satisfaction of end-user needs.
The vital requirements of big data storage can handle very large amounts of data and keep scaling to keep up with growth, and can provide the Input/Output Operations Per Second (IOPS) necessary to deliver data to analytics tools. The largest big data practitioners, such as Google, Facebook, Apple, etc., run what are known as “hyper-scale computing environments”. It comprises vast amounts of commodity servers with Direct Attached Storage (DAS). Hyper-scale computing environments can preserve the largest web-based operations to-date, but it is highly probable that such computing/ storage architectures will elevate into more mainstream enterprises in the years to come.
To manage futuristic BDS, three key areas are identified, which includes standardization of query interfaces, increasing support for data security and protection of users' privacy, and the support of semantic data models [11].
(i) Commons and Social Norms;
(ii) Data Privacy;
(iii) Data Tracing and Provenance; and
(iv) Sandboxing and Virtualization.
There are several new paradigms emerging for the storage of large and complex datasets.
Privacy and security are well-acceptable challenges in the area of big data. The Cloud Security Alliance (CSA) Big Data Working Group [14] published a list of Top 10 Big Data Security and Privacy Challenges. The following challenges more important for big data storage are explained as below.
There are two kinds of BD analytical requirements that can support storage and distinguish the way data is processed and they are listed as,
Data is analysed in real-time or near real-time, the storage should be optimized for low latency and data can be processed in two ways are as follows.
A pure online processing system for online analytic. Apache Storm and YARN are suitable for requiring realtime processing, machine learning, and continuous monitoring of operations as shown in Figure 6.
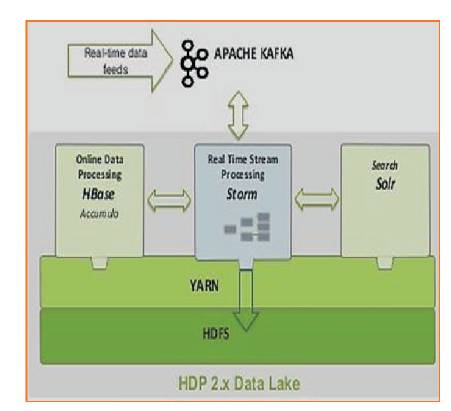
Figure 6. Spark Storage and Memory Partition
Two processes of real-time data processing are as follows.
In this technique, distributed memory storage is used to efficiently minimize the computation time of MapReduce (MR) to execute the jobs faster (in seconds). Two ways used through distributed memory storage are,
It uses procedure storage layouts, aggregation, and join techniques from parallel DBMS. It is an optimized and efficient technique for real-time input queries. The following are the rapid techniques based solutions in realtime queries over big data: Cloudera Impala, Apache Drill.
Examples of near real-time big data analytics are listed below.
Frameworks used: Apache Spark, Gridgain, XAP, Spacecurve, Cloudera.
Apache Spark is an in-memory data processing engine [1], allows data workers to efficiently execute streaming, machine learning or SQL workloads which require fast iterative access with respect to data sets are as shown in Figure 7. Apache Flink is an open-source framework for distributed stream processing that provides accurate results.

Figure 7. In Real Time and Near Real-Time Processing
Two different types of Streaming Processing are explained below.
Technology is used in: Impala, Spark, spark SQL, Tez, and Apache Drill.
Popular frameworks: Apache Storm S4 (It is a unique programming model), Twitter Heron, Apache Ignite, Apache Flink.
Data is captured, recorded, (by sensors, Web servers, point-of-sale terminals, mobile devices, etc.) and analyzed in batch and the way in which data processed
It is an efficient way of processing in a high volume of data (cluster of transactions is collected). Apache SQOOP can be used to extract data from Hadoop and export it into external structured data stores as shown in Figure 8. It supports relational databases, such as Teradata, Netezza, Oracle, MySQL, Postgres, and HSQLDB. The processing of Big Data storages are shown in Figure 9.
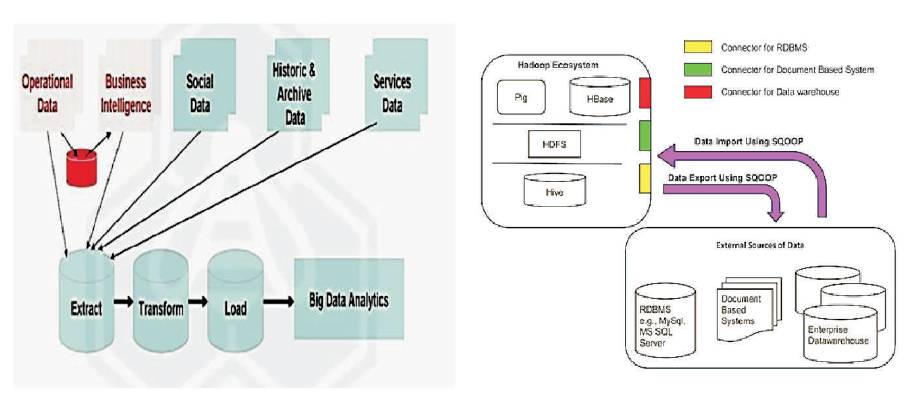
Figure 8. Stream Processing-Spark
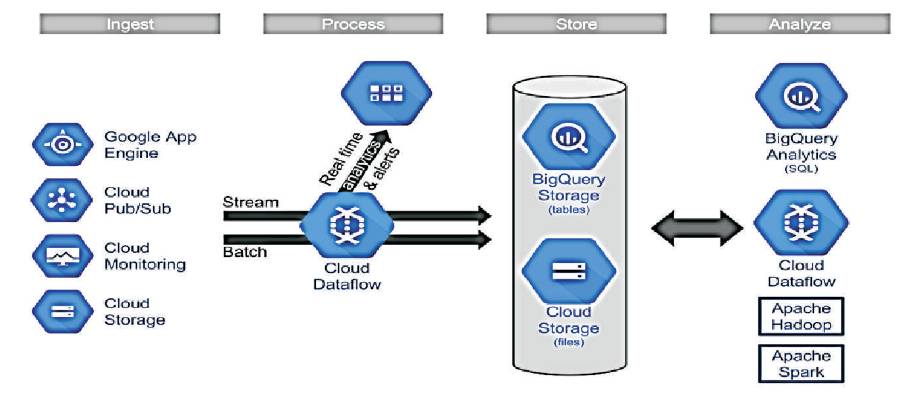
Figure 9. Processing of Big Data (Batch, Real-time, and Stream Processing)
Technology is used in: MapReduce, Hive, Pig.
It is data processing architecture, designed to handle batch and stream processing methods. It cracks balance latency, throughput, and fault tolerance in batch processing to provide accurate views of batch data.
BDS is concerned with storing and manging data in a scalable way, satisfying the requirements of applications. BDS system typically addresses the volume challenge by making use of distributed cluster computing architecture. An ideal BDS system would allow storage of a virtually unlimited amount of data, coping both with high rates of random write / read access, efficiently deal with a different data models to be developed. For instance, a novel row-based storage technology offer better scalability at lower operational, complexity, cost, and Graph databases are suitable storage systems to address many challenges in the line of BD characteristics. Hence, this survey paper is focused the key advance frameworks in resolving BD problem with the emergence of an alternative database technology (called as Non-Relational database).