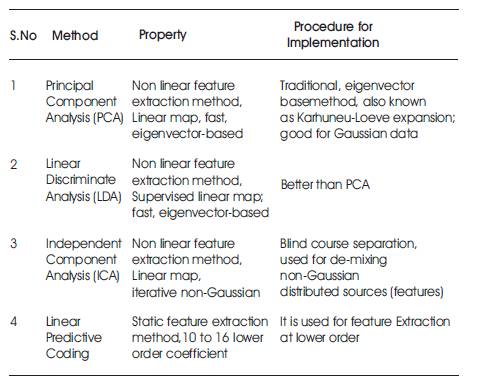
Table 1. List of techniques with their Properties for Feature extraction
The design of Speech Recognition system has careful attention in the following issues: classification of various types of speech classes, speech representation, and feature extraction techniques. The purpose of this paper is to summarize and compare some of the well known methods used in different stages of Speech Recognition system and identify research topic and applications which are at the front position of this stimulating and challenging field. Speech is the most famous and primary mode of communication among human beings. The communication among human and computer is called as human computer interface. Speech has been the important mode of interaction with computer . This paper gives an overview of major technological viewpoint and approval of the primary progress of speech recognition, and also gives an overview of the techniques developed in each stage of speech recognition.
Speech is the primary mode of communication among human beings and also the most natural and capable mode of exchanging information among them. So it is reasonable that, the next technical development of an usual language speech recognition is (Human Computer Interaction) HCI. Speech Recognition [1] can be defined as the procedure of converting speech signal to a series of words by means of an Algorithm implemented as a computer generated program. Speech processing is one of the stimulating areas of signal processing. The goal of speech recognition area is to develop a technique and a system with speech as input to the mechanism based on main advancement in statically modeling the speech. Automatic speech recognition [1] today finds itself as a well-known application for the tasks that require human machine interface such as automatic call processing [3] . Since 1960s, computer scientists have been researching the ways and means to make computers able to record, read and understand human speech. Throughout the decades, this has been a discouraging task. Even the most basic problem such as digitalizing voice was a massive challenge in the early years. It took until the 1980s before the first systems arrived which could actually translate speech. Of course, these early systems were very partial in range and control. Communication among human beings is conquered by spoken language, therefore it is natural for people to expect speech interfaces with computer which can speak and identify speech in national language [2]. Machine recognition of speech involves generating a progression of terms which are the best matches to the given speech signal. Some of the known applications contain effective reality, Multimedia searches, auto-attendants, travel Information and condition, translators, natural language understanding and many more.
Speech Recognition systems can be divided into different classes by relating to the types of elegance they can identify.
Isolated word recognizes speech which typically requires expression to have quiet on both sides of sample windows. It accepts single words or single utterances at a time. This is having “Listen and Non Listen state”. Isolated utterance may be a better name of this class.
Connected word systems are similar to isolated words, but allow the divided utterance to run together in the smallest amount of gap between them.
Continuous speech recognizers allow the users to speak naturally, while the computer decides that the content Recognizer with continuous speech capabilities are most complex to be created because they use special methods to conclude utterance limits.
At a basic level, it can be thought of as a speech that is of usual sounding and not rehearsed. An ASR [4] System with natural speech capability should be able to handle a range of natural speech aspect such as words being run mutually.
The goal of speech appreciation is for a machine to "hear,” understand," and "act upon" any spoken information. The preliminary Speech Recognition [1] systems were first attempted in the early 1950s at Bell Laboratories. Davis, Biddulph and Balashek urbanized a lonely digit appreciation system for a sole speaker. The aspiration of standard speaker recognition [3] is to observe and pull out distinguished and identified information concerning the speaker itself. The speaker admiration system may be viewed as in a row of four stages:
1. Examination
2. Modeling
3. Taxing
4. Feature Extraction
Speech data includes unusual type of information that shows the speaker’s individuality. This includes the speaker’s explicit information due to oral tract, excitation basis and concert feature. The information about the quality of activities also preset the signal and can be worn for speaker recognition [3]. The speech examination stage deals with the appropriate outline size for segmenting speech signal for additional analysis and extraction [7]. The speech analysis are done with the following three techniques.
In this case, speech is analyzed using the surrounding dimension and change in the collection of 10-30 ms to dig out speaker information. Studies were made in the used segmented scrutiny to pull out the speaking expanded information of speaker recognition.
Speech analyzed using the outline volume and budge in collection of 3-5 ms is well-known as secondary segmental breakdown. This modus operandi is worn to primarily examine and dig up the typical type of excitation condition.
Here, speech is analyzed with the outline amount. This procedure is worn principally to consider and is typically payable to the performance disposition of the speaker.
The aim of the modeling method is to produce speaker models with speaker defined quality vector. The speaker modeling method is separated into two catalogs, namely speaker detection and speaker discovery. The speaker detection method robotically recognizes who is talking on the basis of personality information integrated in speech pointer. The speaker recognition is also separated into two parts, namely, capital speaker ward and speaker self governing. In the speaker self-governing style of speech recognition, the computer is ought to disregard the speaker’s exact self of the speech hint and haul out the proposed memo. On the other hand, in case of speaker recognisation, engine should dig out speaker distinctiveness in the auditory signal [5]. The key aspiration of the speaker’s discovery is to compare a speech warning sign from an unfamiliar spokesman to a record of an identified speaker. The system can identify the speaker, which has been qualified with an amount of speakers. Speaker recognition can also be separated into two methods - passage-reliant and passage free methods. In passage reliant method, the speaker speaks input words or sentences having the same passage for both exercise and gratitude trials, while passage free method does not rely on explicit texts being spoken. Following are the modeling methods which can be used in the speech recognition process.
This method is really possible and has been considered in vast intensity for more than 40 years. This comes within reach based upon the assumption of auditory phonetics and postulates [5]. The earliest approaches to speech recognition were based on ruling speech sounds and given apposite labels to these sounds. This is the source of the auditory phonetic approach (Hemdal and Hughes 1967). Which are the postulates that survive fixed, unique phonetic units (phonemes) in spoken idiom and are roughly characterized by a set of acoustics properties that are manifested in the speech signal over time?. Eventhough the acoustic properties of phonetic units are vastly up-and-down, both with speakers and with adjacent sounds (the so-called co articulation effect), it is tacit in the acoustic-phonetic that comes close to the rules leading the unpredictability and are undemanding and can be willingly learned by a machine [6]. Official evaluations conducted by the National Institute of Science and Technology (NIST) in 1996 demonstrated that, the most winning approach to automatic Language Identification (LID) uses the phonotactic comfort of a speech signal to categorize amid a set of languages [7] . In Phone-based systems, such as those described in [1] and [2], there are three techniques that have been functional to the language detection which are Problem phone recognition, Gaussian mixture modeling, and support vector machine classification [2,3]. Using IPA Methods, we can discover the similarities for probabilities of content ward acoustic model for original language [4]. The acoustic phonetic approach has not been broadly used in most profit-making applications [5].
The pattern-matching approach involves two necessary steps namely, pattern preparation and pattern contrast. The necessary feature of this approach is that, it uses a healthy formulated mathematical structure and establishes unswerving speech pattern representations, for the dependable pattern contrast, from a set of labeled preparation samples via an official guidance algorithm. A pattern appreciation approach has been developed over two decades, with much customary notice and functionalities covering up extensively too many practical pattern recognition problems [5]. A speech pattern illustration can be in the form of a speech cut-out or an arithmetical model and can be applied to a sound (smaller than a word), a word, or a phrase. In the pattern comparison stage of the approach, a direct comparison is made between the unidentified speeches (the speech to be recognized) with each likely model learned in the training stage in order to determine the identity of the unknown speech according to the goodness of match of the patterns. The pattern-matching approach has become the predominant method for speech recognition in the last six decades.
Pattern based approaches consider the identical unidentified speech and compare besides a set of prerecorded words (templates) in order to find the best Match. This has a benefit by means of absolutely exact word models. Pattern based approach to speech appreciation has provided a family of techniques that have sophisticated the field noticeably through the preceding six decades. The primary idea is easy. A set of perfect speech patterns are stored as situation patterns on behalf of the vocabulary of the candidate’s words. Respect is then passed out by an alike unknown spoken speech with each of these situation templates and the grouping of the best identical pattern is selected. Habitually, templates for entire words are constructed. This has the improvement that, errors due to segmentation or organization of smaller and acoustically more variable units such as phonemes can be avoided. In turn, each word must have its own full reference template; template grounding and identical becomes prohibitively luxurious or unworkable as the language size increases away from a few hundred words. One key idea in template method is to gain archetypal sequences of speech frames for a pattern (a word) via some averaging modus operandi, and to rely on the use of local ethereal reserve measures to compare patterns. Another key idea is to use some form of energetic programming to momentarily align patterns to account for differences in speaking rates across talkers as well as across repetitions of the word by the same talker. However, it also has the disadvantage that the pre-recorded templates are fixed, and so variations in speech can only be modeled by using many templates per word, which eventually becomes impractical.
Dynamic Time Warping (DTW) is an algorithm for measuring two sequences in parallel, which may vary in time or speed. For instance, similarities on foot patterns would be detected, even if in one video, ‘the person was on foot leisurely’ and if in another, ‘he or she was walking more speedily,’ or even if there were accelerations and decelerations during the course of one inspection. DTW has been useful to video, audio [13], and graphics definitely; any data which can be curved into a linear depiction can be analyzed with DTW. A fine known function has been a habitual speech recognition, to cope with poles apart speaking speeds. In general, DTW is a process that allows a computer to discover a best match between two given sequences (e.g. time series) with confident limitations. The sequences are "twisted" non-linearly in the time dimension to establish a determination of their parallel independent non-linear variations in the time aspect. This sequence position method is often used in the background of unseen Markov [14] models. DTW is such an archetypal draw, near to a template based approach matching for speech recognition and also DTW stretches and compresses a variety of sections of word so as to find position. This results in the best possible match between the template and utterance on frame-by frame basis. By "frame", we mean a short piece (10 -30 ms) of speech signal which is a basis of stricture vector working out, and "match" defined as a sum of frame-by frame distances between pattern and input speech. Pattern with contiguous match defined in style is chosen as recognized word. To engross aural variations, numerical methods can be incorporated into DTW approaches. DTW is rather resourceful for inaccessible word recognition and can be tailored to allied word recognition. One exemplar of the limits compulsory on the matching of the sequences is on the monotonicity of mapping in time dimension. Continuity is less important in DTW than in other pattern matching algorithms; DTW is an algorithm particularly suited to matching sequences with missing information, provided there are long enough segments for matching to occur. The optimization process is performed using dynamic programming, hence the name.
Authority information on variations in speech is given as codes into a system. This has the benefit of clear modeling variations in speech; but unhappily, such specialist knowledge is hard to gain and use successfully. Thus, this approach was judged to be not practical and automatic learning modus operandi was sought instead. Vector Quantization (VQ) is often applied to ASR. It is useful for speech coders, where efficient data decrease occurs. Since broadcast rate is not a major issue for ASR, the efficacy of VQ here lies in the efficiency of using compact codebooks for reference models and codebook searcher in place of most costly evaluation methods. For IWR, each vocabulary word gets its own VQ codebook, based on the training sequence of several repetitions of the word. The test speech is evaluated by all codebooks and ASR chooses the word whose codebook yields the lowest distance measure.
Variations in speech are modeled statistically, using automatic, statistical learning procedure. Classically the out of sight are Markov Models, or HMM. The approaches represent the present state of the art. The main difficulty of the statistical models is that, they must obtain priori modeling assumptions, which are responsible to be mistaken, or handicapping the system performance. In recent years, a new approach for the demanding problem of informal speech recognition has emerged that shares a promise to defeat some primary limits of the straight Hidden Markov Model (HMM) [14] approach (Bridle et al., 1998 [8]; Ma and Deng, 2004 [7]). This new approach is sweeping and leaving from the current HMMbased arithmetic modeling approaches. Text independent speaker recognition uses left-right HMM for identifying the speaker from simple data, and also HMM having the advantages based on Neural Network and Vector Quantization.
The HMM is an admired statistical tool for modeling a large range of time series data. In Speech recognition area, HMM has been functional with vast success to problem such as part of speech classification.
A slanted Hidden Markov [14] Model HMM algorithm and a subspace outcrop algorithm are proposed in, to speak about the favoritism and the strength issues for HMM based speech recognition. Word models were constructed for combining phonetic and fenonic models. A new-fangled hybrid algorithm based on grouping of HMM and learning vector were proposed in. Learning Vector Quantization (LVQ) method shows an important donation in producing highly discriminative reference vectors for classifying static patterns. The ML inference of the parameters via FB algorithm [16] was a wasteful method for estimating the parameters values of HMM. To defeat this problem, the paper proposed a remedial training method that minimized the number of errors of parameter estimation.
A novel approach for a hybrid connectionist HMM speech recognition system based on the use of a Neural Network as a vector quantizes, has been proposed. This shows the important innovations in training of the Neural Network. Next, the Vector Quantization approach showed much of its significance in the drop of Word error rate. MVA method obtained from modified Maximum Mutual Information (MMI) is shown in this paper.
Nam So Kim et.al. have access to a variety of methods for estimating a vigorous output Probability Distribution(PD) in speech recognition based on the discrete HMM in their paper. A conservatory of the viterbi algorithm made the second order HMM computationally efficient when compared to the obtainable viterbi algorithm. A universal stochastic model that encompasses most of the models planned in the writing, pointing out similarities of the models in terms of connection and stricture time assumptions, and drawing analogies amid segment models and HMMs have been described. A replacement VQ method in which the phoneme is treated as a cluster in the speech space and a Gaussian model was estimated for each phoneme. The results showed that, the phoneme-based Gaussian modeling vector quantization classifies the speech space more effectively and the significant improvements in the performance of the DHMM system have been achieved. The flight folding phenomenon in HMM model is to conquer using incessant Density HMM, which considerably reduced the Word Error Rate over continuous speech signal. A new concealed Markov model showed the mixing of the sweeping dynamic mark parameters into the model structure which was urbanized and evaluated using Maximum-likelihood (ML) and Minimum-Classification- Error (MCE) pattern recognition approaches. The authors have designed the loss function for minimizing the error rate specifically for the new model, and derived an analytical form of the gradient of the loss function.
The K-means algorithm is also used for statistical and clustering algorithm of speech [8,9,10], based on the feature of data. The K in K-means [16] represents the number of clusters, the algorithm should return in the end. As the algorithm starts, K points known as cancroids are added to the data space. The K-means algorithm is a means to cluster the training vectors to get feature vectors. In this algorithm, the vectors are clustered based on the attributes into k partitions. It uses the k means of data generated from Gaussian distributions to cluster the vectors. The purpose of the k-means is to reduce total intra-cluster variance.
To defeat the difficulty of the HMMs, machine learning methods could be introduced such as neural networks and genetic algorithm programming. In those machine learning models, overt rules (or extra area expert knowledge) do not need to be given as they can be learned robotically through emulations or evolutionary process.
The artificial intelligence approach attempts to automate the recognition procedure according to the way a person applies his brain in visualizing, analyzing, and finally producing a decision on the measured auditory features. Specialist system is used broadly in this loom (Mori et al., 1987)). The Artificial Intelligence [17] approach is a mixture of the auditory phonetic approach and pattern recognition approach. In this, it exploits the ideas and concepts of Acoustic phonetic and pattern recognition methods. Data based approach uses the information about linguistic, phonetic and spectrogram. Some speech researchers’ urban recognition system used acoustic phonetic knowledge to develop organization rules for speech sounds. While pattern based approaches have been very effective in the intend of a variety of speech recognition systems, they provided little insight about human speech processing, thereby making error analysis and knowledge-based system enhancement difficult. On the other hand, a large body of linguistic and phonetic literature provide insights and understanding of human speech processing. In its pure form, knowledge engineering design involves the direct and explicit incorporation of expert’s speech knowledge [18] into a recognition system. This knowledge is typically resulting from a careful study of spectrograms and is included using rules or procedures. Pure knowledge engineering was also motivated by the interest and research in expert systems. However, this approach had only limited success, largely due to the difficulty in quantifying expert knowledge.
Speech-recognition engines make a detected word to a known word using one of the following techniques (Svendsen et al., 1989 ).
The engine compares the inward digital-audio signal next to a prerecorded template of the word. This technique takes much less giving out than sub-word matching, but it requires that the user (or someone) prerecord every word that will be recognized - sometimes several hundred thousand words. Whole-word templates also require large amounts of storage (between 50 and 512 bytes per word) and are practical only if the recognition vocabulary is known when the application is developed.
The engine looks for sub-words - usually phonemes and then performs additional pattern recognition on those words. This technique takes more processing than whole- word matching, but it requires much less storage (between 5 and 20 bytes per word). In addition, the articulation of the word can be guessed from English text without requiring the user to speak the word beforehand and discuss the research in the area of automatic speech recognition, which had been pursued for the last three decades.
The speech feature extraction in a classification problem is about dropping the dimensionality of the input vector while maintaining the astute power of the signal. As we know from the original formation of speaker detection and proof system, that the number of training and test vectors needed for the classification problem grows with the dimension of the given input, we need feature extraction. Table 1 shows the list of techniques and the properties of feature extraction.
Table 1. List of techniques with their Properties for Feature extraction
Basically, there exist three approaches for speech recognition. They are,
1) Audio Phonetic Approach
2) Pattern Recognition Approach
3) Artificial Intelligence Approach
The initial approaches to speech recognition were based on decision speech sounds and providing fitting labels to these sounds. This is the basis of the audio phonetic approach which postulates that there exists limited, typical phonetic units in spoken language. These units are broadly characterized by a set of acoustics properties, which manifest in the speech [11] pointer over time.
Even though the audio properties of phonetic units are highly variable, both with speakers and with near sounds, it is assumed in the acoustic-phonetic approach that, the policy leading the changeability is easy, and can be willingly learned by a machine. The first step in the acoustic Phonetic approach is an ethereal study of the speech mutual with an attribute finding, which converts the spectral capacity to a set of features that explain the wide acoustic properties of the unusual phonetic units. The next step is a segmentation and classification phase, in which the speech signal is segmented into stable audio regions, followed by attaching one or more phonetic labels to each segmented region, consequentially in a phoneme network description of the speech. The last step in this approach attempts to establish a valid word from the phonetic label sequences formed by the segmentation to classification. In the support process, linguistic constraints on the task (i.e., the words, the grammar, and other semantic rules) are invoked to contact the word list for word decoding based on the phoneme network. The audio phonetic approach has not been widely used for more profit. Table 2 gives the different speech recognition techniques broadly.
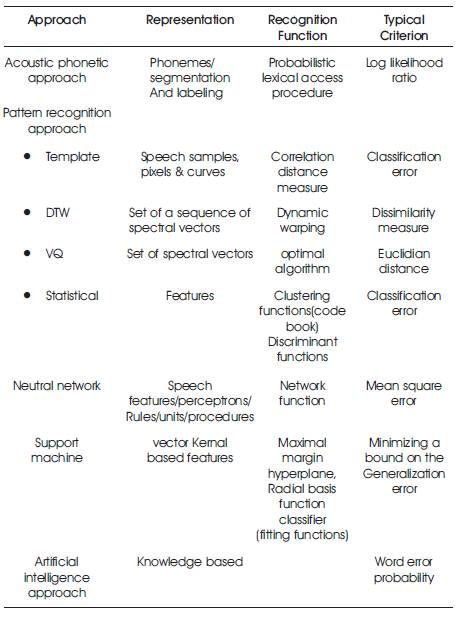
Table 2. Speech Recognition Techniques
The pattern-matching approach involves two necessary steps namely, pattern training and pattern comparison. The important quality of this approach is that, it uses a well formulated arithmetical structure and establishes regular speech pattern representation, for dependable pattern link, from a set of label preparation samples via a proper training algorithm. A speech pattern representation can be in the form of a speech template or a arithmetical model and can be applied to a sound (smaller than a word), a word, or a idiom. In the pattern-comparison phase of the approach, a direct comparison is made between the unidentified speeches (the speech to be recognized) with each likely pattern learned in the training stage in order to establish the identity of the unidentified according to the goodness of match of the patterns. The pattern-matching approach has become the main method for speech recognition in the last six decades. A block diagram of pattern recognition is presented in Figure 1.
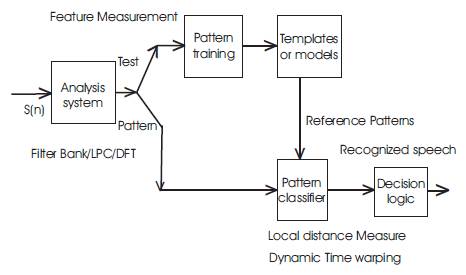
Figure 1. Block Diagram of Pattern Recognition
The Artificial Intelligence approach is a mixture of the audio phonetic approach and pattern recognition approach. In this, it exploits the thoughts and concepts of audio [13] phonetic and pattern recognition methods. Appreciative based approach uses information about linguistic, phonetic and spectrogram. Some speech researcher's residential recognition system used audio phonetic information to develop categorization rules for speech sounds. While pattern based approaches have been very efficient in the design of a selection of speech recognition systems; they provided little information about human speech processing, thereby making creation and error analysis and knowledge-based system improvements not easy. On the other hand, a large body of linguistic and phonetic text provided insights and acceptance to human speech processing. In its pure form, knowledge engineering design involves the direct and open integration of expert speech knowledge into a recognition system. This data is typically derived from a careful study of spectrograms and is included using rules or actions. Pure knowledge engineering was also provoked by the attention and research in expert systems. However, this approach had only incomplete success, generally due to the difficulty in quantifying skilled knowledge.
Another difficult problem is, the addition of many levels of human knowledge phonetics, lexical access, sentence structure, semantics, and pragmatics.
Instead, combining free and asynchronous information sources optimally remains an unsolved problem. In more tortuous forms, information has also been used to direct the aim of the models and algorithms of other techniques such as pattern similar to stochastic modeling. This form of knowledge function makes a vital difference between knowledge and algorithms that enable us to solve problems. Knowledge enables the algorithms to work better. This form of knowledge based system improvement has contributed significantly to the design of all winning strategies reported. It plays a key role in the collection of an appropriate input demonstration, the meaning of units of speech, or the design of the acknowledgment algorithm itself.
In this paper, the method developed in every phase of speech recognition system has been discussed. The effectiveness of speech recognition system has depended on the step of modeling. In modeling, the acoustic-phonetic approach was described for the purpose of extracting the features of speech data. The speech data is normally of high-dimensional nature. For fast processing, the speech data is mapped into low dimension by PCA. The speakers’ data were compared by different similarity measures such as DTW. After extraction of similarity features by DTW, the proposed method can easily recognize the particular speaker by his speech data. The future scope of this paper is to develop the proposed method by the frame work of Variational Bayesian Gaussian Mixture Model (VB-GMM) for robust results to occur in the cases of typical speech data.