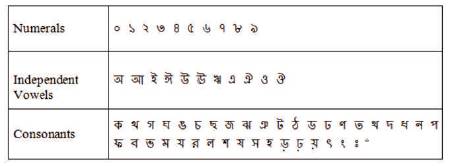
Figure 1. Whole Character Set of Bangla Alphabet
Character recognition techniques, associate a symbolic identity with the image of the character, is an important area in pattern recognition and image processing. The principal idea is to convert raw images (scanned from document, typed, pictured, et cetera) into editable text like html, doc, txt or other formats. There is a very limited number of Bangla Character recognition system, if available they can't recognize the whole alphabet set. This paper demonstrates a Character Recognition system from printed Bangla characters using MATLAB. It can also compare the character in one image file to another one. Processing steps here involved binarization, noise removal and segmentation in various levels, features extraction and recognition [1].
Character Recognition began as a field of research in Pattern Recognition, Artificial Intelligence, and Machine Vision. The different areas covered under this general term are either the online or the offline CR, each having its dedicated hardware and recognition methods. In online character recognition applications, the computer recognizes the symbols as they are drawn. The typical hardware for data acquisition is the digitizing tablet, which can be electromagnetic, electrostatic, pressure sensitive, and so on; a light pen can also be used. As the character is drawn, the successive positions of the pen are memorized (the usual sampling frequencies lay between 100 Hz, and 200 Hz) and are used by the recognition algorithm. The interested reader may refer to more references. Off-line character recognition is performed after writing or printing is completed. Two families are usually distinguished: magnetic and optical character recognition. In Magnetic Character Recognition (MCR), the characters are printed with magnetic ink and are designed to modify in a unique way, a magnetic field created by the acquisition device. MCR is mostly used in banking applications, as for example checks reading, because overwriting or overprinting these characters does not affect the accuracy of the recognition. While in optical character recognition, which is the field investigated in this document, deals with recognition of characters acquired by optical means, typically a scanner or a camera. The symbols can be separated from each other or belong to structures like words, paragraphs, figures, etc. They can be printed or handwritten, of any size, shape, or orientation.
Bangla, the mother tongue of Bangladesh, is one of the most popular scripts in the world, the second most popular language in the Indian subcontinent. About 200 million people of eastern India and Bangladesh use this language, making it fourth most popular in the world, and also the institutional language in our country. Therefore recognition of Bangla character has always a special interest, considering a massive number of official papers being scanned and processed every day. This work aims to develop a system that classifies a given input (Bangla Characters) as belonging to a certain class rather than to identify them uniquely, as every input pattern. It also performs character recognition by quantification of the character into a mathematical vector entity using the geometrical properties of the character image. Global usage of this system may reduce the hard labor of the concerning government employees.
Basic Bangla character set comprises 11 vowels, 39 consonant, and 10 numerals. There are also compound characters being a combination of consonant with consonant as well as consonant with vowel. A complete set of characters need to recognize is provided in Figure 1. In the mentioned references [6, 7], the researchers tried to recognize bangla number only.
Figure 1. Whole Character Set of Bangla Alphabet
The RGB (true-color) images are stored as three separate image matrices; one storing the amount of red (R) in each pixel, one of green (G) and one of blue (B); similar to wavelength-sensitive cone cells of human eye. While in a grayscale or grayscale digital image, the value of each pixel is a single sample that, carries only intensity information. A grayscale image is not the black-white Binary (2-leveled) image. Gray image is represented by black and white shades or combination of levels. 8 bit gray image means total 2^8 levels from black to white, 0 = black and 255 is White. While Binary images, have only two possible values for each pixel, are produced by thresholding a grayscale or color image, in order to separate an object in the image from the background.
Also, color images are described by using the following three terms: Hue, Saturation, and Lightness. Hue is another word for color and dependent on the wavelength of light being reflected or produced. Saturation refers to how pure or intense a given hue is. 100% saturation means there's no addition of gray to the hue - the color is completely pure. Lightness measures the relative degree of black or white that's been mixed with a given hue.
Adding white makes the color lighter (creates tints) and adding black makes it darker (creates shades). The effect of lightness or value is relative to other values in the composition.
Binarization:
Binarization is a technique by which the gray scale images are converted to binary images to facilitate noise removal. Typically, the two colors used for a binary image are black and white, though any two colors can be used. The color used for the object in the image is the foreground color, while the rest of the image is the background color. Binarization separates the foreground (text) and background information.
Noise Removal:
Scanned documents often contain noise that arises due to printer, scanner, print quality, age of the document, etc. Therefore, it is necessary to filter this noise before processing the image. This low-pass filter should remove as much of the noise as possible while retaining the entire signal.
Image segmentation is the process of partitioning a digital image into multiple segments (sets of pixels, also known as super pixels). The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze. Image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics or property such as color, intensity, or texture. The result of image segmentation is a set of segments that collectively cover the entire image, or a set of contours extracted from the image (or edge detection). Segmentation of binary image is performed in different levels include line segmentation, word segmentation, and character segmentation. Thresholding often provides an easy and convenient way to perform this segmentation on the basis of the different intensities or colors in the foreground and background regions of an image. In a single pass, each pixel in the image is compared with this threshold. If the pixel's intensity is higher than the threshold, the pixel is set to, say, white in the output, corresponding foreground. If it is less than the threshold, it is set to black, indicating background.
Features Extraction:
Feature extraction is a special form of dimensional reduction that efficiently represents interesting parts of an image as a compact feature vector. This approach is useful when image sizes are large and a reduced feature representation is required to quickly complete tasks such as image matching and retrieval. Feature detection, feature extraction, and matching are often combined to solve common computer vision problems such as object detection and recognition, content-based image retrieval, face detection and recognition, and texture classification [3, 8].
Image correlation and tracking is an optical method that employs tracking and image registration techniques for accurate 2D and 3D measurements of changes in images. Cross-correlation is the measure of similarity of two images. Each of the images is divided into rectangular blocks. Each block in the first image is correlated with its corresponding block in the second image to produce the cross correlation as a function of position [4].
The proposed system is developed by the following steps:
Step 1: Printed Bangla Script input to Scanner
Step 2: Raw scanned Document from Scanner
Step 3: Convert RGB image into Gray Scale Image
Step 4: Convert Gray Scale Image to Binary Image.
Step 5: Segmentation and Feature Extraction.
Step 6: Classification and Post-processing.
Step 7: Output editable text.
A scanned RGB color image is input to the system. The proposed text detection/recognition/translation algorithm (Figure 2) consists of the following steps: Binarization, Noise removal, Segmentation, Features extraction, Cross-correlation & Correlation [5] .
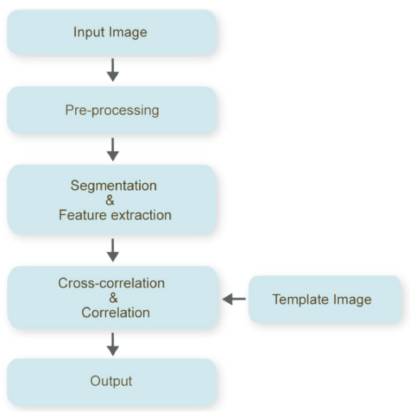
Figure 2. An Overview of the Proposed Bangla Character Recognition System
An implementation is the realization of a technical specification or algorithm as a program, software component, or other computer system through computer programming and deployment. The proposed system is implemented in MATLAB and accuracy is also tested [2].
After loading the image into MATLAB, the authors convert the color image to a grayscale image which is shown in Figure 4. Using MATLAB 'imread' function of, a noisy RGB image is loaded to the input system (Figure 3). After performing GrayScale conversion by 'rgb2gray', Figure 4 is thus obtained. 'rgb2gray' eliminates the hue and saturation information of RGB image while retaining the luminance. Figures 5-7 show outcomes after binarization (using 'im2bw') and noise-removal from this black & white image. Figures 8-10 show the process of character segmentation.
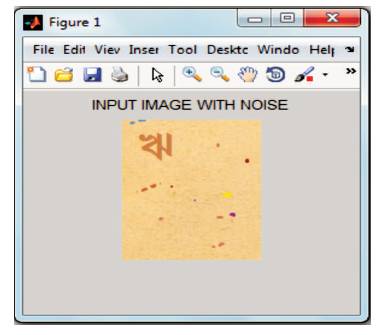
Figure 3. Input Image with Noise
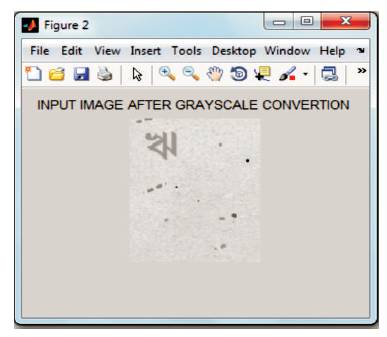
Figure 4. Image after Grayscale Conversion
Figure 5. Image after Binarization
Figure 6. Image after Noise Removal

Figure 7. Image Information for Segmentation: 0 represents Black & 1 represents White
Figure 8. Character after Segmentation
Figure 9. Selecting the Character for Computer Recognition
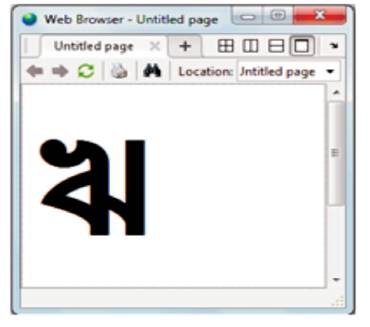
Figure 10. Computer Editable Character
Performing cross-correlation between input image and template image, the peak point is found (Figure 11). Peakpoint is a point that indicates the highest matching area based on cross correlation. Thus, the appropriate character is identified. Here Bangla Unicode Characters hex value is used to make the recognized character machine-readable. Recognized character is displayed in MATLAB built in browser (Figure 12).
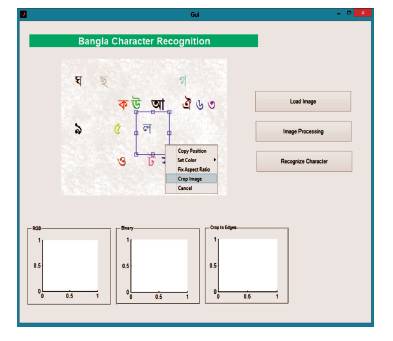
Figure 11. Character Recognition using GUI
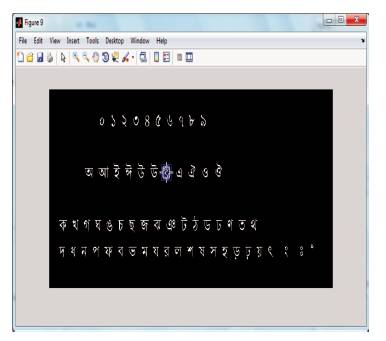
Figure 12. Recognized Character
A user-friendly Graphical User Interface is also designed in this system, where user can insert an image to recognize the character. User can load any image using “Load Image” option. After loading an image, the user can select a character using mouse pointer, crop image and process the selected character using “Image Processing” option. Following the algorithms, the system can recognize the selected character and provide it in editable format if “Recognize Character” command is executed.
The recognition rate of the proposed Bangla character recognition method is remarkable with the accuracy rate of almost 98-100%. Image processing toolbox and built in MATLAB functions have been very helpful here for single Bangla character and digit. The input images can be taken by any optical scanner or camera. The output allows saving recognized character as html, txt, etc., format for further processing. The only limitation of the system is the fixed font size of the character. Further improvement for all possible font type and size is reserved for the future. Also it is developed only for single Bangla character recognition. Multiple characters recognition at a time along with connected letters is also left open for the future. Connecting the program algorithm with the neural network may also be helpful.
A lot of commercial enterprises have already developed frameworks for document analysis and character recognition. But those frameworks are limited to recognize English or some other languages. The methodology described above also works to recognize handwritten character & convert it into digitalized form. Although different types of software have been developed to recognize printed characters, those are not good to recognize Handwritten characters. In this experiment, the authors try to recognize all bangla characters, but still a lot of research is needed for word, its semantics and lexicon.
Complex character based language like Bangla clearly need deep research to meet its goal. Recognition of Bangla character is still in intermediate stage. The proposed system is developed here using template matching approach to recognize individual character image. Even though the user-friendly GUI gives several advantages to the users, this system is still facing a number of limitations which is quite considerable. Improving the system to suit handwritten characters, all printed fonts in considerable amount of time with high accuracy is the recommended future work.