
Figure 1. Recorded Sentence
The speaker identification systems work only in a single language environment using sufficient data. Many countries including India are multilingual and hence the effect of multiple languages on a speaker identification system needs to be investigated. Speaker identification system shows poor performance when training is done in one language and the testing in another language. This is a major problem in multilingual speaker identification system. The main objective of this research work is to observe the impact of the languages on multilingual speaker identification system and identifying the variation of MFCC feature vector values in multilingual environments, which will help to design multilingual speaker identification system. The present paper explores the experimental result carried out on collected database of multilingual speakers of three Indian languages. The speech database consists of speech data recorded from 100 speakers including male and female. The Mel Frequency Cepstral Coefficients (MFCC) as a front end feature vectors are extracted from the speech signals. The minimum, maximum and mean values of the feature vectors have been calculated for the analysis. It is observed that Rajasthani language has the larger values as compared to Hindi language and Marathi Language in minimum values of the feature vectors, where as Marathi Language has the larger values as compared to Hindi language and Rajasthani language in maximum values of feature vectors. The impact of the languages on multilingual speaker identification system has been evaluated.
Most of the speaker identification system operates only in a single-language environment. Multilingual speaker identification and language identification are key to the development of spoken dialogue systems that can function in multilingual environments. Multilingual Speaker identification system refers to identifying persons from their voice. The sound of each speaker in different languages is unique because of the difference in vocal tract shapes, larynx sizes, and other parts of their voice production organs [3]. In multilingual speaker identification system, speaker specific models are trained in one language and tested with multiple languages. The spoken language mismatch is one of the factors resulting in performance degradation in multilingual speaker identification systems [5]. For multilingual speaker identification tasks, numerous speech features and modeling techniques have been proposed over the years [6], [7]. To evaluate the speaker identification system in multilingual environment, a multi-lingual speaker identification database has been developed and initial experiments were carried out to evaluate the impact of language variability on the performance of the multilingual speaker identification system [9]. Multilingual Speaker identification under limited database could be used in the following applications:
S. Sarkar, et al. [1] reported the performance of multilingual speaker recognition systems on the IITKGPMLILSC speech corpus. The standard GMM-based speaker recognition framework was used. The average language-independent speaker identification rate was 95.21 % with an average equal error rate of 11.71 %.
Nagaraja B.G. and H.S. Jayanna, [2] presented a paper in the year 2013 on speaker identification in the context of mono, cross and multilingual using the two different feature extraction techniques, i.e., Mel-Frequency Cepstral Coefficients (MFCC) and Linear Predictive Cepstral Coefficients (LPCC) with the constraint of limited data. The languages considered for the study are English (International Language), Hindi (National Language) and Kannada (Regional Language). They reported that the standard multilingual database was not available, and experiments were carried out on their own created database of 30 speakers in the college laboratory environment, who speak the three different languages. As a result, the combination of features gives nearly 30% higher performance compared to the individual features.
U. Bhattacharjee and K. Sarmah [5] reported the experiment carried out on a recently collected multilingual and multichannel speaker recognition database to study the impact of language variability on speaker verification system. The speech samples were collected in three different languages English, Hindi and a local language of Arunachal Pradesh. The collected database was evaluated with Gaussian Mixture Model based speaker verification system using Universal Background Model (UBM) for alternative speaker representation and Mel- Frequency Cepstral Coefficients (MFCC) as a front end feature vector. The impact of the mismatch in training and testing languages have been evaluated.
P. Kumar and S. L. Lahudkar [8] introduced a new method which combined LPCC and MFCC (LPCC+MFCC) using fusion output and evaluated together with the different voice feature extraction methods. The speaker model for all the methods was computed using Vector Quantization- Linde, Buzo and Gray (VQ-LBG) method. Individual modelling and comparison for LPCC and MFCC is used for the LPCC+MFCC method.
In the authors previous work [13], an attempt was made to identify the variation of pitch in multiple language of a speaker in the context of multilingual speaker identification system. Here, the statical analysis has been done on Mel-Frequency Cepstral Coefficients (MFCC) of different languages of different speakers.
For multilingual speaker identification system, the database of different speakers has been recorded in three Indian languages, i.e. Hindi, Marthi and Rajasthani. The sampling rate of recorded sentences is 16 KHz. The sentences consist of consonants, i.e. “cha”, “sha” and “jha” have been considered for the recording. Total number of speakers involved are 100 including males and females. The recorded sentences are shown in Figure 1.
Figure 1. Recorded Sentence
Obtaining the acoustic characteristics of the speech signal is referred to as Feature Extraction which is used in both training and testing phases [12]. Very first step in multilingual speaker identification system is to extract features, i.e. identify the components of the speech signal that are good for identifying the linguistic content and discarding all the other stuffs, which carries information like background noise, emotion, etc. Here, the Mel Frequency Cepstral Coefficients (MFCC) as a front end feature vectors are extracted from the speech signals.
The most relevant and dominant method used to extract spectral features of the speech signal is calculating Mel- Frequency Cepstral Coefficients (MFCC). MFCCs are one of the most popular feature extraction techniques used in speaker identification based on frequency domain using the Mel scale which is based on the human ear scale [8] . MFCCs being considered as frequency domain features are much more accurate than time domain features [7]. Mel-Frequency Cepstral Coefficients (MFCC) is a representation of the real cepstral of a windowed shorttime signal derived from the Fast Fourier Transform (FFT) of that signal. The difference from the real cepstral is that a nonlinear frequency scale is used, which approximates the behavior of the auditory system. Additionally, these coefficients are robust and reliable to variations according to speakers and recording conditions. MFCC is an audio feature extraction technique which extracts parameters from the speech signal similar to ones that are used by humans for hearing speech, while at the same time, deemphasizes all other information [4] .
The speech signal is first divided into timeframes consisting of an arbitrary number of samples [15], [16]. In most systems, overlapping of the frames is used to smooth transition from frame to frame. Each time frame is then windowed with Hamming window to eliminate discontinuities at the edges [13]. The filter coefficients w(n) of a Hamming window of length n are computed according to the formula:
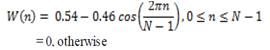
Where, N is the total number of samples of a speech signal and n is the current sample. After the windowing, Fast Fourier Transformation (FFT) is calculated for each frame to extract frequency components of a signal in the time-domain. The logarithmic Mel-Scaled filter bank is applied to the Fourier transformed frame. This scale is approximately linear up to 1 kHz, and logarithmic at greater frequencies.
The relation between frequency of speech and Mel scale can be written as:
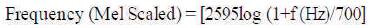
MFCCs use Mel-scale filter bank where the higher frequency filters have greater bandwidth than the lower frequency filters [10], [11], but their temporal resolutions are the same. The MFCCs calculating process as shown in Figure 2.
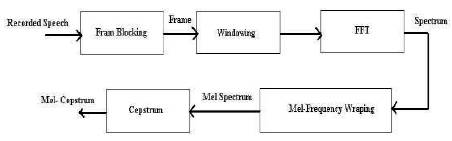
Figure 2. MFCCs Feature Extraction Process
Assume starting with a speech signal, sampled at 16 kHz.
Step 1: Frame the signal into 20-40 ms frames. 25 ms is standard through frame blocking as shown in Figure 2. This means the frame length for a 16 kHz signal is 0.025*16000 = 400 samples. Frame step is usually something like 10 ms (160 samples), which allows some overlap to the frames. The first 400 sample frame starts at sample 0, the next 400 sample frame starts at sample 160, etc., until the end of the speech file is reached. If the speech file does not divide into an even number of frames, pad it with zeros so that it does. The next steps are applied to every single frame, one set of 12 MFCC coefficients is extracted for each frame. A short aside on notation: Time domain signal s(n). Once it is framed, we have Si(n), where n ranges over 1-400 (if our frames are 400 samples) and i ranges over the number of frames. When they calculate the complex DFT, they get Si(k), where i denotes the frame number corresponding to the time-domain frame. Pi(k) is then the power spectrum of frame i.
Step 2: To take the Discrete Fourier Transform of the frame, perform the following:
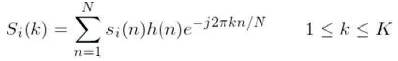
where, h(n) is an N sample long analysis window (e.g. hamming window), and K is the length of the DFT. The periodogram-based power spectral estimate for the speech frame si(n) is given by:
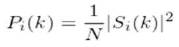
This is called the Periodogram estimate of the power spectrum. Take the absolute value of the complex fourier transform, and square the result. Generally, perform a 512 point FFT and keep only the first 257 coefficients.
Step 3: Compute the Mel-spaced filter bank. This is a set of 20-40 (26 is standard) triangular filters that apply to the periodogram power spectral estimate from step 2. Filter bank comes in the form of 26 vectors of length 257 (assuming the FFT settings from step 2). Each vector is mostly zeros, but is non-zero for a certain section of the spectrum. To calculate filter bank, energies multiply each filter bank with the power spectrum, then add up the coefficients. Once this is performed, they are left with 26 numbers that give us an indication of how much energy was in each filter bank.
Step 4: Take the log of each of the 26 energies from step 3. This leaves us with 26 log filter bank energies.
Step 5: Take the Discrete Cosine Transform (DCT) of the 26 log filter-bank energies to give 26 cepstral coefficients. For analysis, only the lower 12-13 of the 26 coefficients are kept.
The resulting features (12 numbers for each frame) are called Mel Frequency Cepstral Coefficients.
Deltas and double deltas are also known as differential and acceleration coefficients. The MFCC feature vector describes only the power spectral envelope of a single frame of a speech signal, whereas deltas and double deltas coefficients have information about the trajectories of the MFCC coefficients over time [14] . It turns out that calculating the MFCC trajectories and appending them to the original feature vector increases the performance of a multilingual speaker identification system [9].
To calculate the delta coefficients, the following formula is used:
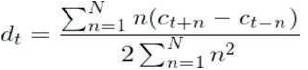
where, dt is a delta coefficient, from frame t computed in terms of the static coefficients ct+N to ct-N. A typical value for N is 2. Delta-Delta (Acceleration) coefficients are calculated in the same way, but they are calculated from the deltas, not the static coefficients.
Here, some detailed analysis are examined for Mel Frequency Cepstral Coefficients (MFCCs)-the domain features used for multilingual speaker identification. Their success has been due to their ability to represent the speech amplitude spectrum in a compact form. The analysis is done for the three utterance “cha”, “sha” and “jha” in three Indian languages. Base of the analysis is observed as the variation in mel frequency cepstral coefficients when speaker changes the spoken language. The following observations were recorded in Table 1.
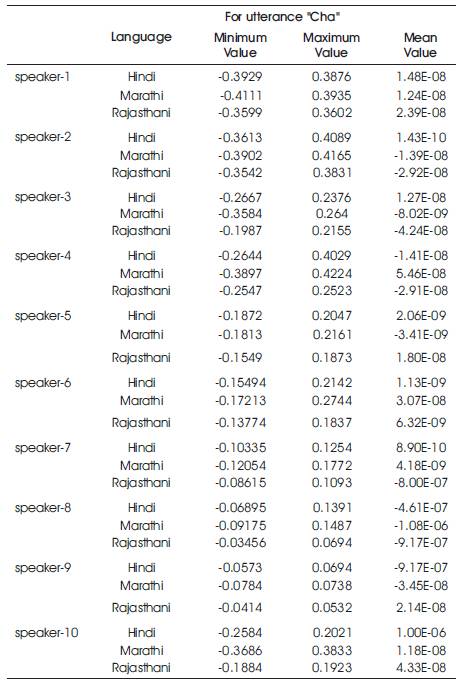
Table 1. Variation in the MFCCs Feature Vectors of a Speaker in Multilingual Environment
In Table 1, the observation of MFCCs front-end feature vectors of 10 speakers in three languages for utterance “cha” has been reported. This analysis has been done for observing the variation in coefficients of multilingual speakers. On the basis of the feature vectors reported in Table 1, Figure 3 shows the variation in feature vectors of a speaker in multilingual environment.
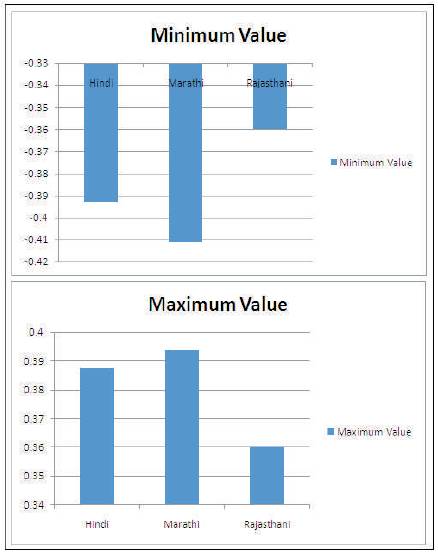
Figure 3. Variation in MFCC Feature Vectors of a Speaker in Multilingual Environment
In Figure 3, it is clearly shown that the minimum values and the maximum values of MFCCs for three languages are different. It is observed that the Rajasthani language has the larger values as compared to Hindi language and Marathi Language in minimum values of the feature vectors, whereas Marathi Language has the larger values as compared to Hindi language and Rajasthani language in maximum values of feature vectors. This analysis will help us to design such system, which is used to identify the speaker in multilingual environments.
The MFCCs feature extraction method has been implemented for multilingual speaker identification system. This system takes the multilanguage speech samples as input, computes its MFCC, delta and double delta coefficients as a feature vector have been recorded. Here, the experiment carried out on a recently collected multilingual speaker identification database to study the impacts of language variability on speaker identification system. The effect of language on the features vector of a speaker has been observed. Comparison of MFCCs are done in three languages which will be used for training and testing phase of the multilingual speaker identification system.