Figure 1. Single Path Routing
Many contemporary networks, such as datacenters, optical networks, and Multi Protocol Label Switching (MPLS) make it impossible or inefficient to supply a traffic flow with a certain bandwidth need via a single network link. In these instances, it is often feasible to increase network bandwidth utilization by distributing traffic over numerous efficient channels. While employing numerous pathways for the same data flow improves network efficiency, it uses costly forwarding resources from network nodes, such as TCAM, Ethernet/MPLS switch entries and optical switch wavelengths/lightpaths. In this work, we identify many challenges related to dividing a traffic flow across several pathways while using as few forwarding resources as possible, and we offer efficient methods for handling these difficulties.
Networking is a procedure that enables the sharing of resources and information between a group of computers and other hardware components that are linked through communication channels. A computer network, often known as a data network, is a kind of telecommunications network that enables computers to communicate and exchange data through data links. Packets are used to transport data. The nodes are connected through cable or wireless media.
The word "network" refers to computer equipment that originates transport and terminates data. Nodes may consist of hosts such as personal computers, smartphones, servers, and networking devices. Two such devices are considered to be networked together if one of them is capable of exchanging data with the other, regardless of whether they have a direct connection.
Interpersonal interactions are facilitated by a computer network, which enables individuals to communicate swiftly and simply through email, instant messaging, chat rooms, telephone, video telephone calls and video conferencing. Access to data stored on shared storage devices is a critical component of many networks. A network enables the exchange of files, data, and other forms of information by enabling authorized users to access data stored on other computers connected to the network. Users may access and utilize network resources, such as printing a document to a shared network printer.
Computer hackers may use a computer network to distribute computer viruses or computer worms to devices connected to the network or to prevent these devices from connecting to the network (denial of service). Setting up a complicated computer network may be challenging. Setting up an efficient computer network in a big firm may be expensive.
Routing is the process of determining the optimal route across a network. Historically, the word routing referred to the process of sending network traffic between networks. However, the latter function is more appropriately referred to as forwarding. Routing is used in a variety of different types of networks, including telephone networks (circuit switching), electronic data networks (such as the Internet), and transportation networks.
Routing controls packet forwarding (the passage of logically addressed network packets from their source to their final destination) via intermediary nodes in packet switching networks. Typically, intermediate nodes are network hardware devices like routers, bridges, gateways, firewalls or switches. Although general-purpose computers are not specialist hardware and may have restricted performance, they may also forward packets and conduct routing. Routing is often used to guide forwarding based on routing tables, which keep track of the paths to different network destinations. Thus, it is critical for effective routing to design routing tables that are stored in the router's memory. The majority of routing algorithms operate on a single network route at a time.
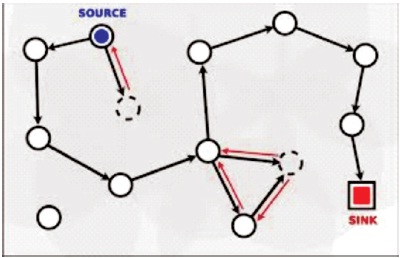
Only one route exists between any two networks in the internetwork in a single-path routing scheme. Single-path internetworks are not fault resilient, despite the fact that they simplify routing tables and packet flow pathways. A dynamic router may detect a fault, but the networks across the fault are unavailable for the duration of the fault. Before packets may be effectively sent via a downed connection or router, the downed link or router must be brought back up. The single route routing strategy is shown in Figure 1.
Figure 1. Single Path Routing
When it comes to network routing, multipath routing is a strategy that employs a large number of alternate paths at the same time. This has the potential to deliver a variety of benefits, including fault tolerance, increased bandwidth, and improved security. When dynamic routing is utilized, multipath networks become fault resilient, and some routing protocols, such as Open Shortest Path First (OSPF), can balance the weight of network traffic over many pathways with the same metric value. However, when distance vector-based routing protocols are used, multipath internetworks may be more complicated to build and have a larger risk of routing loops during convergence. Multipath routing is shown in Figure 2.
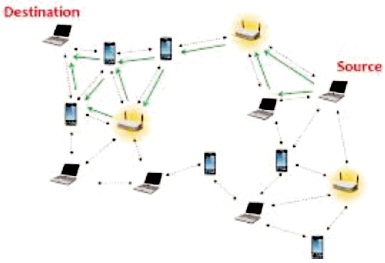
Figure 2. Multipath Routing
Multipath Routing is often interpreted to imply managing and using numerous accessible pathways simultaneously for the transmission of data streams emerging from one application or multiple applications. Each stream is allocated a distinct route in this format, to the extent permitted by the available pathways. When the number of streams exceed the number of available pathways, certain streams will share paths. This optimizes bandwidth consumption by establishing many active transmission queues. Additionally, it provides a measure of fault tolerance in that if one path fails, only the traffic assigned to that path is impacted, with the remaining paths continuing to serve their respective stream flows. Additionally, there is, ideally, an alternate path immediately available to continue or restart the interrupted stream.
This method provides a better transmission and fault tolerance.
Multipath routing enables the creation and usage of several pathways between two source-destination pairs. It makes use of the underlying network's resource redundancy and diversity to deliver advantages such as fault tolerance, load balancing, bandwidth aggregation, and an increase in QoS measures such as latency.
A multipath routing system consists of three components: path discovery, traffic distribution, and route maintenance. Path discovery is the process of determining possible pathways based on predefined parameters. Path disjointness is a prominent statistic for assessing resource variety across pathways.
The traffic distribution strategy specifies how available pathways are utilized simultaneously and how data travelling to the same destination is divided and dispersed over several paths. When the status of already accessible pathways changes, path maintenance describes when and how new paths are obtained. Numerous multipath routing methods have been developed for wireless ad hoc networks, each focusing on a different attribute such as mobility, interference, or topology.
The purpose of developing a multipath TCP protocol is to increase the reliability and performance of end-to-end connections. This method enables the simultaneous use of numerous pathways by a single TCP connection, maximizing resource utilization, redundancy, and resilience. This protocol enables multi-homing by using the many network interfaces available on modern devices, resulting in increased throughput. This protocol enables seamless connection handover on mobile devices without affecting application connections. Multipath connections can assist data center operations, as they may boost throughput, increase path variety, and improve fairness.
Rathore et al. (2020) offers a solution to the load balancing problem, by putting the users in a queue until they reach their time. During high load periods, the load balancer would abort the process of all users. Normally, the load balancer monitors the network and clears the respective host for discontinued users. Decentralization has affected the server hardware requirements. Load balancing increases the cost of service.
Rathore (2018) this approach is an improved version of random policy-based load balancing. Using the random load balancing strategy, the target point is randomly selected from the list. The grid response time was reduced by increasing the allocation of grid resources. To determine its efficiency on the grid platform, this algorithm is carefully tested on a grid simulator.
The suggested solution uses multiple factors to forecast the node's location, unlike the approach in (Makhlouf, 2018), which uses only the node's current and previous positions. Additionally, the suggested approach takes advantage of multipath forwarding. If the probability of the packet being determined is low, the packet will be sent. In such cases, the success ratio is unaffected. One of the most important points is the solution for the suggested problem is addressed in the paper.
Li et al. (2011) proposes a Hello protocol-based node mobility prediction. To forecast its location and those of its neighbors, each node uses an autoregressive model. Hello messages are used to send the projected position. As a consequence, the forecast result is updated by the neighbours.
In this paper, an integrated approach for assessing the user's mobility utilising an autoregressive model is provided (Zaidi & Mark, 2004). The mobility is properly modeled using a first-order autoregressive model.
On the training data, which consists of node location, velocity, and acceleration, Yule-Walker equations are used. The AR model is used to forecast future mobility states using preprocessed data. The Yule-Walker equations are used to estimate the mobility parameters from the training data. To assess connection uncertainty and stability, an entropy based metric is presented. The nodes' random movements result in a series of on-off linkages, resulting in often changing network connectivity. The development of link states is described as a stationary Markov chain with the same entropy rate as the transition entropy. The observed entropy rate is a measure of the link's future state's uncertainty.
Nakibly et al. (2013) define traffic flow as the movement of data packets between network nodes that have the same source and destination (switches or routers). A network flow may often be divided into various traffic sub-flows using information included in the packet header, such as the IP/MAC addresses, the UDP/TCP port fields, or the VLAN number. Because various traffic sub-flows are created by distinct apps or even hosts, each one may be routed through a distinct network channel. When directing a traffic flow across a single way is impracticable or prohibitively costly, using many paths is advantageous. We are given a traffic requirement (source, destination, and bandwidth need) and a network flow that meets the bandwidth demand between the source and destination nodes using Decomposition with Minimum Overhead (DMO). In Routing with Minimum Overhead (RMO), only a traffic demand (source, destination, and bandwidth demand) is specified, and the problem is to determine a set of simple paths between the source and destination nodes that can deliver the bandwidth demand while minimizing the number of paths or nodes they traverse.
Gerstel et al. (2000) to reduce total network costs, advocated reducing the number of wavelengths required rather than merely the number of OADM rings. The network cost comprises the number of wavelengths and transceivers needed at each node. The transceiver cost comprises terminating and higher-layer electronic processing equipment, which in reality might outweigh the cost of the network's wavelengths. A point-to-point OADM ring transports communication optically but switches it electronically across nodes. Two OADM ring networks with comparable performance but cheaper cost are shown. OADM ring networks that are non-blocking in both senses are studied.
Banner and Orda (2003) proposed typical routing techniques that send all traffic over a single path, and multipath routing solutions distribute traffic across many pathways to reduce congestion. Multipath routing is generally regarded as being more efficient than standard single path routing. Unlike single-path routing, most multipath routing research relied on heuristic approaches. It shows the value of optimum solutions. So, it examines multipath routing theoretically. It formalizes challenges with two main multipath routing needs. Then it establishes the computational complexity of these issues. As a result, it develops effective solutions with proven results. The equal distribution of flows along the (shortest) channels (coming from the round-robin distribution) further restricts the potential to minimize congestion through load balancing. The OSPF-OMP traffic allocation method is based on a heuristic technique that frequently results in poor flow distribution.
A classic multi-commodity flow theory is presented by (Baier et al., 2005). There is no constraint on the number of pathways utilized to distribute each commodity, therefore it is possible to split the flow across several paths. Unsplittable flows are the topic of study due to routing issues in real world applications like telecommunications. Demand for each product cannot be divided but must be channelled in one direction. This issue is generalized. Assume a commodity is broken into a finite number of parts that are subsequently transported over various pathways. Unlike classical (splittable) and unsplittable flows, the single commodity case is NP-hard and even approximation. There are methods for single and multi-commodity cases, and strong linkages to unsplittable flows are shown. Also provided are findings on approximation difficulty. So unless P = NP, some of our approximation findings are best conceivable.
In this paper, Extreme machine learning-based mobility prediction is presented (Ghouti, 2013). Every mobile node is aware of its location, velocity, and movement direction. The placements, velocity, and movement of nodes in the future are projected. The routing protocol is updated to choose the next hop based on the projected future distances. The effectiveness of the strategy is determined by the amount of training done. Each node's mobility is projected based on previous data, and transmitting this information to nearby nodes incurs a significant cost. By propagating fake distances, attacks may be launched quickly in this technique.
In this paper, we offer a neural network-based position prediction system with spatial routing (Cadger et al., 2016). The next coordinate is anticipated using a neural network based on N recent coordinates, and the geographical routing protocol determines the next-hop depending on the projected position. The value of N has an impact on forecast accuracy.
A big directed graph is composed of documents and relationships, according to (Barabási et al., 2000). Despite its apparent randomness, the topology of this network possesses some universal scale-free properties. It presents a model for a scale-free network that captures the selforganization mechanisms that govern the web. The formation of the order in natural systems fascinates and inspires scientists in both fields. While the spatial order of crystals has aided many discoveries in modern physics, most complex systems in nature lack such organization. Despite its growing importance in communication, the internet is still the least regulated medium: anybody may construct websites with unlimited content and connections. This uncontrolled expansion leads to a big and complicated web, which is a large directed network with documents as vertices and links (URLs) as edges.
Edmonds and Karp (1972) outline the maximum flow issue and provide the Ford-Fulkerson labelling technique for its solution. Then comes a novel solution for the minimum-cost flow issue that uses nonnegative weighted networks for all shortest-path calculations. These algorithms' upper limits on the number of steps necessary are generated and demonstrated to be superior to preceding methods' upper bounds.
Curtis et al. (2011) presented a great concept, however, its initial architecture imposes enormous overheads. Because it permits level control over Ethernet switching and gives global awareness of network overflows, it may simplify network and traffic management in corporate and data centre contexts. Such fine-grained control and visibility, however, comes at a price: the switch implementation costs of using the switch's control plane too often, and the distributed-system costs of involving the Open Flow controller too often. It examines these overheads and demonstrates that Open Flow's present architecture is insufficient for high-performance networks. It created and tested Devo Flow, a variant of the Open Flow paradigm that slowly dissolves the link between control and global visibility while maintaining a meaningful level of visibility and avoiding excessive expenses. It tests DevoFlow in simulations and finds that it can load-balance data centre traffic just as effectively as fine-grained alternatives, but with less overhead: DevoFlow uses 10 times fewer flow table entries and 10 times fewer control messages at an average switch.
The newest large-scale data centres, according to (Raiciu et al., 2011), provide increased aggregate bandwidth and resilience by constructing several pathways in the network's core. To make the most of this bandwidth, various flows must follow different channels, which is a difficulty. In other words, single-path transmission seems to be unsuitable for such networks. In such data centres, Multipath TCP is proposed as a substitute for TCP since it can efficiently and seamlessly exploit available bandwidth, resulting in enhanced performance and greater fairness on numerous topologies. It looks at what causes these advantages, separating the contributions of each of MPTCP's processes. Using MPTCP allows us to reimagine data centre networks, with a new perspective on how transport protocols, routing, and topology interact.
MPTCP allows topologies that are not possible with singlepath TCP. A dual-homed variation of the Fat Tree topology is presented as a proof-of-concept. For a broad variety of workloads, MPTCP beats Fat Tree, although at the same cost. MPTCP may be easily installed in existing data centres using commonly used technologies like ECMP. When route diversity is present, MPTCP beats TCP by a factor of three, according to tests conducted on Amazon EC2. However, the greatest advantages will be realised when data centres are configured to support multipath transfers.
In this system, multipath flow is implemented mainly by reducing the forwarding cost in two cases:
In DMO we are given a traffic demand (source, destination, and bandwidth demand) and a network flow1 that satisfies the bandwidth demand between the source and destination nodes. This network flow is predetermined according to some bandwidth efficiency criterion, such as bandwidth cost, and the problem is to break it into a set of simple paths between the source and destination nodes while minimizing the number of paths or the number of nodes they traverse.
In RMO only a traffic demand (source, destination, and bandwidth demand) is given, and the problem is to find a set of simple paths between the source and destination nodes over which the bandwidth demand can be delivered while minimizing the number of paths or the number of nodes they traverse. At first glance, it seems that RMO should be solved using a solution for DMO as a sub routine.
It indeed finds this approach to perform very well, but rather than starting with an initial network flow. For both problems, we aim at minimizing the forwarding cost, measured as the number of paths or the number of nodes traversed by the paths. Thus, we solve two pairs of problems:
The problem description of the proposed system is shown in Table 1 below.

Table 1. Problem Descriptions
There has been no previous research on reducing the number of nodes travelled by pathways that fulfill a particular traffic demand [RMO (n)]. Furthermore, no previous study has addressed the breakdown of a given network flow while reducing the number of nodes crossed by the pathways [DMO (n)]. However, there are a few efforts that solve the DMO (p) and RMO (p) issues. If the number of routes is unimportant, it is simple to deconstruct a given network flow into at most O (|E|) paths.
Ad-hoc On-demand Distance Vector (AODV) is a packet routing system developed for use in Mobile Ad Hoc Networks (MANET) that may support networks with thousands of nodes. It is one of many demand-driven (or on-demand) protocols now in use. As a result, the protocol is only activated when a node (host) has data to broadcast. It's a reactionary procedure. According to the AODV RFC the transport layer protocol is UDP, which of course only provides best-effort packet delivery and does not enable error recovery or flow control. The routing table has nine fields for each entry. In addition to the IP address of the destination node, the fields include routing information and information relating to the qualitative status of the route for maintenance reasons. Unlike some other protocols, AODV just keeps track of the next destination (hop) in the route, rather than the whole routing list. This saves memory and reduces the computational burden associated with route management. It also includes information that allows the host to communicate data with other nodes when link status change.
The size of the AODV routing database is reduced by including just the next-hop information rather than the whole path to a target node. The sequence number, which is unique to each destination route, is essential for keeping routing information up to date. A sequence number is included in protocol messages that carry routing information. The sequence number must be managed for routing and route maintenance to be efficient. The basic message set includes a Route Request (RREQ), a Route Reply (RREP), a Route Error (RERR), and a HELLO for monitoring connection status. If a route is still required, the source node may resume the discovery process. By sending an RREQ, the source node or any node in the path may reconstruct the route.
The method is used in conjunction with a routing table and routing database to determine the most efficient route.
Step 1: (Initialization)
Initialize Sequence number;
If (sequence no >0)
Broadcast- RREQ;
Step 2: (Creating Routing Database)
If (Destination number of RREQ is the last known number to the source =true)
Store
Step 3: (Creating Routing Table)
The destination replies using RREP (Route Reply) Unicasting
The sequence number is first incremented if it is equal to the number in the request
RREP contains the current sequence number, hop count = 0, full lifetime
Step 4: (Finish)
Discard duplicate requests
Exit
Each starting node has a sequence number that increases monotonically. Other nodes use this to assess the latest information. Every node's routing database holds the most up-to-date information on the sequence number for the IP address of the destination node for which routing information is kept. This is updated anytime a node gets new sequence number information through RREQ, RREP, or RERR messages sent to that destination.
AODV relies on each node in the network owned and maintaining its destination sequence number. Before initiating a route discovery, a destination node increases its sequence number. In response to an RREQ, a destination node increases its sequence number immediately before initiating an RREP. When incrementing, the node considers its sequence number as an unsigned integer, resulting in sequence number rollover. By verifying the sequence number of the incoming AODV message with the sequence number for that destination, destination information is ensured.
When a node detects that a link with an adjacent neighbour has been broken (the destination is no longer reachable), it receives a data packet destined to a node for which it does not have an active route and is not repairing, and when it receives a RERR from a neighbour for one or more active routes, a RERR message is broadcasted. A RERR packet is sent to all nodes that are directly connected to the broken connection. Then that node transmits the RERR packet to the nodes that came before it. This process is repeated to the source nodes. After sending the RERR packet via the source node, the connection will no longer be used. AODV employs loop free routes. In an ad-hoc network, there are only a limited number of nodes. The route is not removed by DSR. In DSR, nodes in the network may continue to believe that a broken connection is still valid. This may need several searches for new pathways. If a route is still required, the source node may resume the discovery process. By sending an RREQ, the source node or any node in the path may reconstruct the route.
Figure 3 depicts the proposed work's architectural diagram. For data transmission, two primary modules are used:
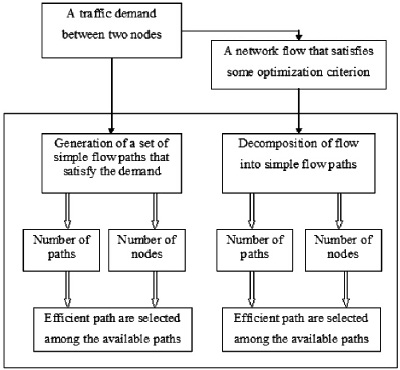
Figure 3. System Architecture
Only the traffic demand is provided in Routing with Minimum Overhead. The challenge is to identify a collection of simple pathways that meet the demand while limiting the number of paths or nodes traversed. We are provided a traffic demand and a network flow in Decomposition with Minimum Overhead. The traffic demand comprises the demand for the source, destination, and bandwidth. The network flow is predefined in terms of bandwidth cost. The goal in DMO is to divide it into a collection of simple pathways connecting the source and destination nodes while limiting the number of paths or nodes. Among the various pathways, efficient paths are chosen.
The major modules implemented in this work are
In a network, a node is a connection point either a redistribution point or an endpoint for data transmission. A node has programmed or engineered capability to recognize and process or forward transmission to other nodes. Figure 4 shows the node creation screenshot. The n number of nodes can be created for data transmission between the source and destination. The number of nodes is first determined by the user and it is then simulated using the ns2 simulator and the properties of each node are updated on the database.
Figure 4. Node Creation
The node created at the node creation module can be visualized at the view nodes submodule.
The Simulator object has a function called node to create new nodes. The Simulator object also has a function called duplex-link, which creates a link to send data between two nodes. Its parameters are the source node, the destination node, the bandwidth, the delay, and the queuing discipline along with the physical topology of our network.
In this module, the source node and the destination node can be created and the screenshot depicting this is shown in Figure 5.
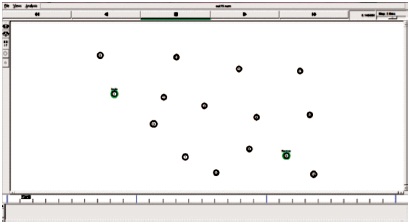
Figure 5. Setting Source and Destination
Figure 6 shows every available path that can be selected to send a broadcast message to all nodes in between source and destination.
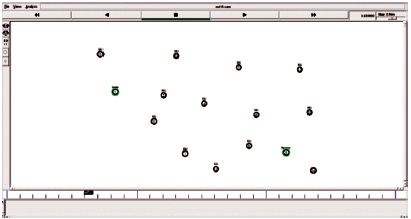
Figure 6. Path Selection
Figures 7 and 8 depict an optimized path is selected from a set of simple paths between the source and destination nodes over which the bandwidth demand can be delivered while minimizing the number of paths or the number of nodes they traverse.
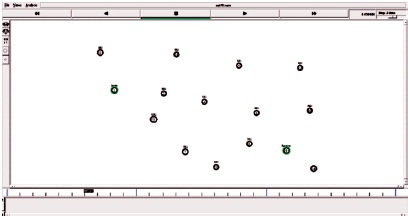
Figure 7. Optimized Path Selection
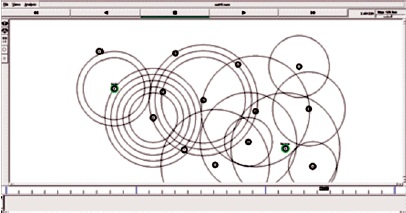
Figure 8. Searching Efficient Paths
Acknowledgement can be sent from the destination node to the source node through the efficient path. It searches the efficient path in the possible paths that are initiated between the source and destination nodes.
Figure 9 shows the available paths that will compute the best path and send the error message to the other breakable nodes. Figure 10 represents the data transmission by the effective path.
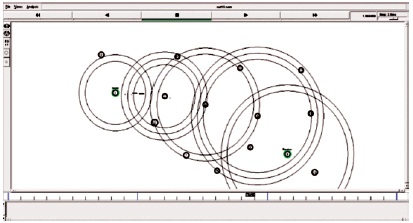
Figure 9. Compute the Best Path
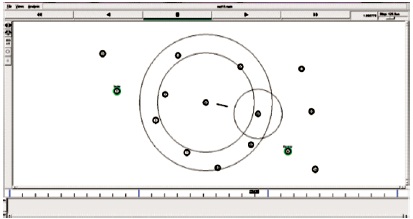
Figure 10. Sending Data through the Best Path
Figure 11 enumerates the receiving mode of data packets from source to destination.
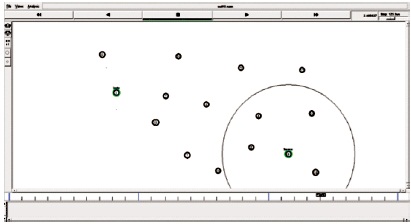
Figure 11. Packet Reaching the Destination Node
The performance evaluation can be calculated by the number of mobile nodes and the number of copies through each mobile node at a particular time. Each of the message copies of replicated data packets are received by their mobile nodes. The delayed delivery of each message or data packet should be associated with the delivery of data packets and the period. Those are provided at more efficient time delay and improve through the performance.
The transmission time is calculated only for the bit rate and the number of data packets delivery (n). Each data packet is counted fully upon the multiple ranges of each data packet. Every data packet is calculated by the data packet delivery at the particular time in encountered data packets delivery methods. Those are formed by the different distances and is increased by the speed of each data packet delivery in the network.
Figure 12 represents that the packet delivery ratio can be calculated by the transmission of packet delivery and the time.
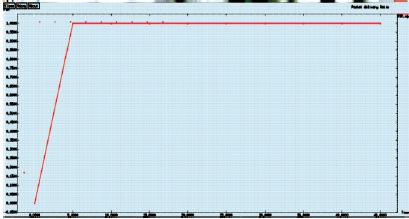
Figure 12. Packet Delivery Ratio Graph
Figure 13 represents the comparison of the existing and proposed number of packets and the time to delivery of the packets.
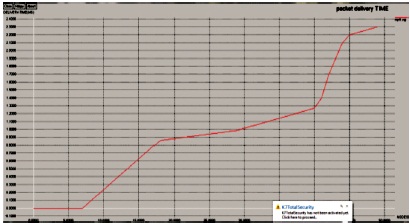
Figure 13. Packet Delivery Time Graph
Figure 14 represents the comparison of the existing and proposed methods of throughput.
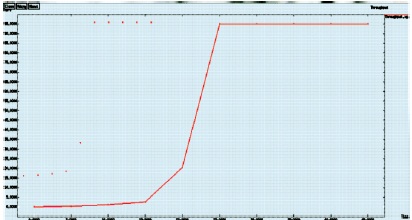
Figure 14. Throughput Graph
The packet drop can be calculated by packets transmission and the time of the transmission in the packets as shown in Figure 15.
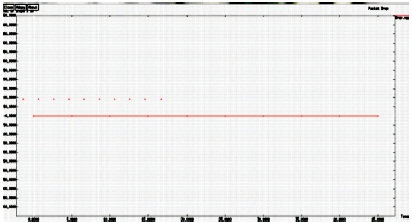
Figure 15. Packet Drop Graph
The expected number of transmissions is shown in Figure 16. It can be calculated by the number of nodes and transmission cost.
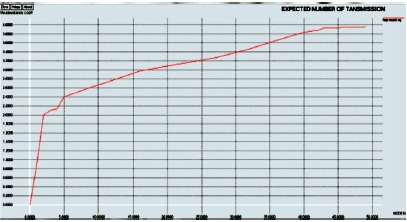
Figure 16. Expected Number of Transmission Graph
The energy consumption is calculated by the number of nodes and the energy consumptions of each transmission is shown in Figure 17.
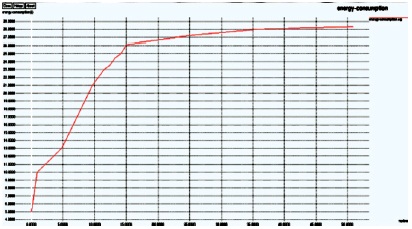
Figure 17. Energy Consumption Graph
Figure 18 represents the minimum delay delivery. It is calculated by each message delay and the time of the transmission.
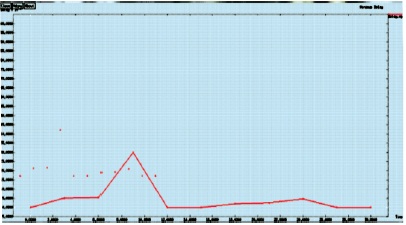
Figure 18. Minimum Delay Delivery Graph
In order to maximize bandwidth utilization, it is often desirable to split a flow of data over multiple paths while minimizing forwarding costs. By using RMO and AODV algorithm, decrease the forwarding cost and select efficient paths for transmitting data between the sources and destinations. This reduces the buffering delay during transmission.
Future improvements may be made to this system by reducing the number of routes and nodes. The data is divided into several pathways based on the traffic that passes through them, with the path with the fewest nodes receiving the highest priority.