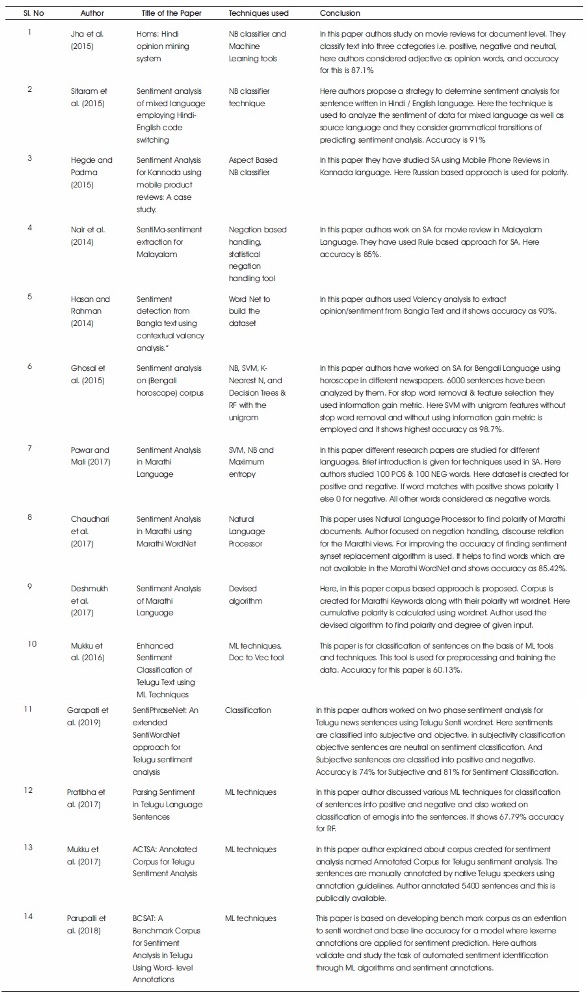
Table 1. Work on SA for Indian Languages
Social media is growing tremendously from last few years, and people are using social networking sites like Facebook, Instagram, Twitter etc. for sharing their opinions and their emotions for any social issue like CAA, Delhi rape case, elections etc. For expressing their views they use their native language for communication and the reason why lot for data is available for particular languages like Hindi, Marathi, Tamil, Telugu etc., and lot for work has been done on many Indian languages except Marathi. So in this paper we have discussed about Marathi Sentiment analysis and its challenges for data collection.
Sentiment analysis or opinion mining refers to the application of natural language processing, computational linguistics and text analytics to identify and extract sentiments from text or sentences. Sentiment analysis is nothing but to determine or express the attitude, judgment or emotion of speaker or a writer on a particular or any topic given. Sentiment analysis helps in recognizing the emotional tone, identifies the subject and generally measures in term of polarity of the statement i.e. positive, negative or neutral.
Sentiment analysis is “to find the human behavior, what human can think, what is his reaction, the way of expression, emotions, feelings on any general topic”.
Sentiment analysis is nothing but finding people's opinion and is also called as Opinion Mining. Opinion Mining (OM) is an area of Text Mining that has recently received a lot of attention due to the amount of opinion information that resides in web documents. It concerns the identification of opinions in a text and their classification as positive, negative or neutral. Opinion identification is more difficult than the topic-based one and it cannot be based on just observing the presence of single words. More sophisticated methods need to be employed in order to differentiate between the subjective and objective opinion of a reviewer or between the objective description of a movie and references to other people's comments (Chauchat et al., 2008).
For sentiment analysis the data is mostly collected through online or offline media and its polarity is calculated, which helps in finding sentiment on a topic or concept.
There are two methods for collection of data i.e. online (Social media) and offline which are briefly discussed below:
On social media, social networking sites are available for collection of data like Facebook, Twitter, Whatsapp, Instagram for chatting, etc. where people share their emotions, their updates, pictures etc. Also it is used to find contacts, present their views, reviews on particular product before buying, express their feelings, opinion, emotion on any regional, national topics like CAA, Disha Case, Nirbhaya Case, PMO, Surgical Strike etc., and also write their comments on any video or any social content.
Because of all these reasons huge amount of online data is available to find sentiment or opinion of people which can be useful in many areas like product marketing, getting product review, political influence, trend analysis and many more.
For offline data, we can prepare general objective-based questions based on any burning issues going on and ask people to give answers. With the help of this questionnaire, we can find the sentiment or opinion of people.
Fourteen earlier papers have been studied to understand the Sentiment Analysis on Indian Languages. Table 1 presents the work on Sentiment Analysis for Indian Languages.
Table 1. Work on SA for Indian Languages
Here we have noticed that for communication people prefer their native language and that's the reason lot of lingual data is available for languages like Hindi, Bengali, Malayalam, Telugu, and Kannada. This paper tries to address Sentiment analysis for Non English languages, especially Marathi.
In Maharashtra, people talk in Marathi language and whatever online discussion is going on in Maharashtra is in Marathi language, and not only in the state, but Marathi people from any states also use Marathi language. Each and every Marathi feel proud while talking in Marathi, and that's the reason lots of Marathi data is available online for research.
But analysing past reviews, there is less amount of work done in Marathi language, and hence Marathi language has been chosen for this work.
Marathi language is in it’s preliminary stage, and our focus is extending research in Marathi language. Thus this paper discusses the process of sentiment analysis on Marathi corpus.
After collection of data, preprocessing is done, where the data is cleaned by removing special symbols, extra space, extra dots, and also remove some garbage value. Figure 1 shows the flow of our proposed system.
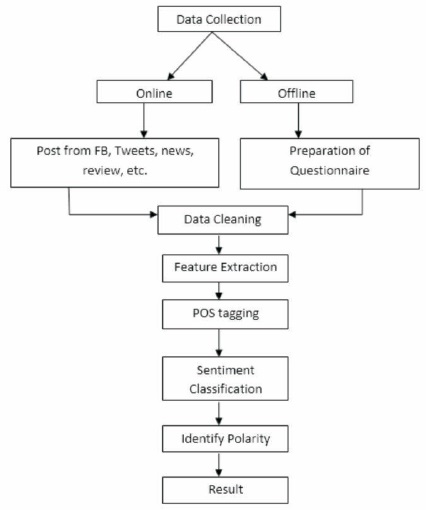
Figure 1. Work on SA for Indian Languages
As present no standard corpora is available for Marathi. The first stage is online data collection on various posts for a specific domain (burning issues) like Nirbhaya. Kopardi case 200 posts are collected, and on CAA there are 110 posts and for PMO (Narendra Modi and election) 100s posts were collected. All posts were in Marathi Language.
In this we remove unwanted characters, break attached words, correct spelling mistakes, grammar correction, and remove human expressions like lol, hahaha, mu etc.
Here we remove stop words, punctuation marks etc., and extract the exact words from data for processing.
A special tag is assigned to each word in a text corpus to indicate parts of speech and other grammatical categories such as tense, numbers etc.
Identifying opinions in text, and label them positive, negative and neutral, based on data collected from post.
Identify the sentence on the basis of polarity like positive and negative.
Finally produce the results of the study.
Following are some challenges we faced while collecting post for our data collection.
This paper presents the work done on sentiment analysis of various Indian Languages. Here according to previous study, lot of work has been done in languages like Hindi, Telugu, Malayalam etc., except Marathi language. On social media, people are talking in their native languages and so huge data is available in various languages. Marathi speakers are using Marathi language for talking online, and sharing their views, opinions, comments etc. So large amount of data is available in Marathi language as well, but very little work has been done in Marathi language. That's the reason lot of scope is there to work with Marathi Language. Here in this paper we discussed the proposed model for our research work and briefly explained the steps of our proposed model. There are lots of challenges we faced while collecting the data, and in future we are trying to overcome these challenges and are trying to enlarge our dataset.