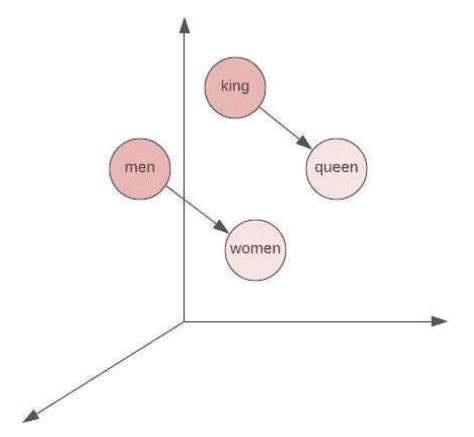
Figure 1. Visualization of Word Embeddings
Emotions are states of readiness in the mind that result from evaluations of one's own thinking or events. Although almost all of the important events in our lives are marked by emotions, the nature, causes, and effects of emotions are some of the least understood parts of the human experience. Emotion recognition is playing a promising role in the domains of human-computer interaction and artificial intelligence. A human's emotions can be detected using a variety of methods, including facial gestures, blood pressure, body movements, heart rate, and textual data. From an application standpoint, the ability to identify human emotions in text is becoming more and more crucial in computational linguistics. In this work, we present a classification methodology based on deep neural networks. The Bi-directional Gated Recurrent Unit (Bi-GRU) employed here demonstrates its effectiveness on the Multimodal Emotion Lines Dataset (MELD) when compared to Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM). For word encoding, a comparison of three pre-trained word embeddings namely Glove, Word2Vec, and fastText is made. The findings from the MELD corpus support the conclusion that fastText is the best word embedding for the proposed Bi-GRU model. The experiment utilized the "glove.6B.300d" vector space. It consists of two million word representations in 300 dimensions trained on Common Crawl with sub-word information (600 billion tokens). The accuracy scores of GloVe, Word2Vec, and fastText (300 dimensions each) are tabulated and studied in order to highlight the improved results with fastText on the MELD dataset tested. It is observed that the Bidirectional Gated Recurrent Unit (Bi-GRU) with fastText word embedding outperforms GloVe and Word2Vec with an accuracy of 79.7%.
Emotion is a psycho-physiological process that is triggered by the conscious or unconscious perception of objects and situations associated with a variety of characteristics such as mood, temperament, personality, disposition, and motivation. Emotion is closely correlated with daily life since it involves the act of decision-making, which is primarily influenced by several external factors, including personality type, social role, etc. Applications of accurate emotion recognition in natural language include creating emotional chat bots and improving understanding of people and their lives. Emotions play a vital role in human existence. It affects our mental and physical health, as well as our ability to make decisions. Therefore, creating emotion detection models is crucial. They can be used for a variety of purposes, such as creating emotional chatbots or monitoring the emotions of social media users to determine whether they are in good mental and/or physical health(Abdul-Mageed & Ungar, 2017).
A recent area of research that is closely related to sentiment analysis is emotion detection and recognition from text. While emotion analysis seeks to identify specific types of feelings expressed in texts such as fear, anger, happiness, disgust, surprise, and sadness, Sentiment analysis seeks to identify positive, neutral, or negative feelings from text (Weidman et al., 2017)
Word embeddings are often used in numerous Natural Language Processing (NLP) applications, such as question-answering, sentiment analysis, and machine translation. The majority of existing word embedding methods represent each word by predicting the target word from its context and mapping words with identical semantic roles to nearby points in the embedding space. For example, the words "man" and "woman" are semantically related and closely mapped into embedding space, as shown in Figure 1.
Figure 1. Visualization of Word Embeddings
However, its emotional state is confusing. This problem has recently been addressed by various emotion embeddings, which have improved performance on tasks involving emotions. Numerous applications in NLP now use pre-trained continuous word representations as their fundamental building blocks. These pre-trained representations offer word distributional data, which often enhances the adaptation of models developed using meagre data (Mikolov et al., 2017)
Facial expressions and speech for emotion recognition have been the focus of a lot of recent research. However, unlike in speech, where indicators like facial gesture, tonal stress, and pitch are present, emotion identification in text is a laborious task. The lexicon-based approach, the keyword approach, and the machine learning approach are some of the Natural Language Processing (NLP) methods that have been suggested in the past for extracting emotions from text. However, due to their emphasis on semantic relations, keyword and lexicon based techniques have some drawbacks (Bharti et al., 2022).
In this work, a Bi-directional Gated Recurrent Unit (Bi-GRU) network has been presented to demonstrate how these text emotion detection models can perform noticeably better when they are able to extract more meaningful information from text. We compare Word2Vect, GloVe, and fastText word embeddings for each word's encoding.
In this paper, Bi-GRU was used to detect emotion from textual data, and the impact of different word embeddings like GloVe, Word2Vec, and fastText is analyzed. Numerous studies on emotion recognition in text using various Word embeddings have been conducted.
Wu et al. (2006) used the universal lexical ontology rather than obtaining the emotional keywords. Emotion generation rules and emotion association rules for detecting emotions in text can be used to generate the universal lexical ontology. They used semantic labels in words to make it easier to recognize emotions. Emotional generation rules will be framed by domain-dependent and domain-independent words. To obtain these, each word has to be converted into a Semantic Label (SL) and attributes by analyzing the hierarchical structure of the sentence. A priori algorithm was used to attain the emotion association rules. They have detected only three emotions, namely happy, unhappy, and neutral. This model detects the three types of emotions without any manual effort.
Chen and Jin (2015) used a Recurrent Neural Network (RNN)-based network for emotion recognition. In order to improve the prediction performance, they have explored various features of modality, feature durations, novel loss functions, bidirectional networks, Long Short-Term Memory (LSTM), and early and late fusions. Though bidirectional LSTM achieves better performance than LSTM, it is time-consuming and has some overfitting issues. In order to avoid these issues, they have implemented the LSTM for recognizing emotions from the Remote Collaborative and Affective (RECOLA) dataset.
Another work on emotion recognition that was done by (Abdul-Mageed & Ungar, 2017). detected 24 types of emotions. The model was trained using Twitter data. A variation of the Recurrent Neural Network (RNN) called the gated recurrent neural network was used to detect 24 emotion categories. They have optimized the hyperparameters of the network by word-embedding vectors of 300-dimensional size. They also extended the model to detect eight primary emotions.
Park et al.(2020) built an emotion embedding model based on tweet data and analyzed emotions in ROC story data. Emotional words in each sentence of the story dataset are extracted using a sentiment analyzer. The emotion of the extracted word is detected based on the embedding model acquired during the learning process of the Convolutional Neural Network (CNN) classifier.
Calefato et al. (2017) proposed a toolkit called "EmoTxt" for text emotion recognition that classifies based on six defined classes namely love, fear, joy, sadness, anger, and surprise. They trained and tested the Support Vector Machines (SVM) model on a gold standard containing questions, answers, and comments from online interactions.
Azim and Bhuiyan (2018) proposed a supervised machine learning approach to identify the ten basic emotion categories, including anger, disgust, fear, guilt, interest, joy, sadness, shame, surprise, and neutral, from tweet data. On comparing various machine learning algorithms like the multinomial naive bayesian classifier, the artificial neural network, and the support vector machine, they concluded that the highest accuracy was obtained by the Support Vector Machine (SVM) approach.
Banothu et al. (2021) proposed a model that detects and recognizes six types of emotions through the expressions in sentences such as "joy," "surprise," "sadness," "anger," "love," and "fear." For detecting emotions, Convolutional Neural Networks (CNN) and Bi-LSTM models were used, and for word embedding, GloVe 6B 300d was used. Instead of using a one-hot representation for word embedding, which creates as parse vector representation, a GloVe embedding model was used that gives meaningful weight to the vector, which helps to maintain the sequence. When these two models were compared, it was discovered that the Bi-directional Long- Short-Term Memor y (Bi-directional LSTM) model outperformed Convolutional Neural Networks (CNN) Banothu et al. (2021)
In this section, a series of work is conducted among different word embedding models to evaluate their performances on our proposed bidirectional gated recurrent unit and a thorough comparative analysis is performed. The Multimodal Emotion Lines Dataset (MELD) corpus is chosen to perform the comparative research.
There are only a few free datasets available for classifying textual emotion. Most of them are related to a particular subject. Hence, for our experiment, we use the MELD dataset. The multimodal emotion lines dataset was created by enhancing the emotion lines dataset.
It contains the same text instances that are present in Emotion Lines, but it additionally includes both audio and visual modalities along with text. MELD contains over 1400 dialogues and 13000 utterances from the friends' television series. Each of the utterances was labelled with one of the seven emotions as displayed in Table 1.
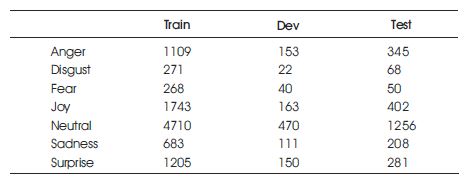
Table 1. Emotion Distribution in the MELD Dataset
The initial preprocessing methods include lowering the text, replacing letters or punctuation that is repeated, normalizing the frequently used informal expressions, stripping off the hash symbols, and replacing commas and newline characters with white space. Then text sequences are separated into tokens with the tensor flowkeras tokenizer, and only the top N terms are chosen. These top-level N tokens were added to our dictionary.
The value of N largely depends on the target emotion count. In our experiment, neutral, joy, surprise, and anger had the highest count, hence N = 100k, whereas for other emotions it was N = 50k.
In this section, we classify the preprocessed MELD dataset into emotions using the deep neural network architecture. When compared to other expressions, emotion texts are complex and context-dependent due to the complexity of human emotions and the difficulty in interpreting the communicated feeling.
The proposed architecture shows that the model captures better information about the context and sequential nature of the text than lexicon-based approaches. RNNs have been proven to perform better in Natural Language Processing (NLP) functions, specifically classification tasks. In order to capture information about the context and sequential nature of the text, a model based on RNN, specifically a bidirectional GRU network, is used to analyze and classify the MELD dataset. We built 7 emotion classifiers to classify each of the 7 emotions, each using the same architecture to detect the specific emotion class. Figure 2 shows the model summary of the proposed Bi-GRU model for emotion detection.
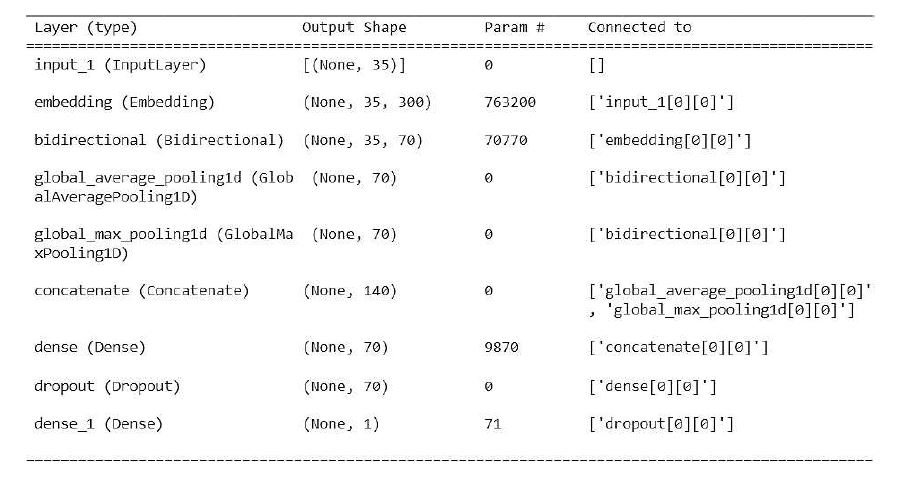
Figure 2. Model Summary of the proposed Bi-GRU Emotion Detection Model in Keras
The overall bidirectional GRU architecture used is depicted in Figure 3. Here is the flowchart with all the particulars mentioned in the flow diagrams. All of the processes are described in the model.
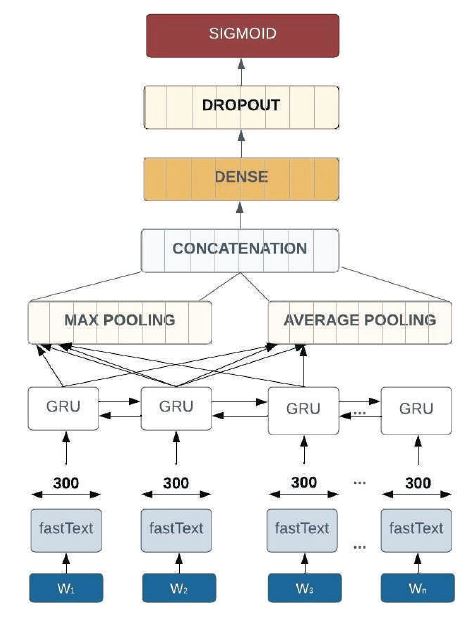
Figure 3. Architecture of the Proposed Bi-directional GRU
The first layer of the model is the embedding lookup layer, which is used to convert each text sequence into an embedding vector. This numeric representation of text facilitates the neural network's processing of textual data. This is the critical layer with which we compare different word embedding layers. This helps us to learn how the embedding layer affects the accuracy of the test. The performance of the word embedding is evaluated by employing the following list of embeddings.
Global vectors for word representation is an unsupervised machine learning algorithm developed by Stanford. It is used to obtain the vector representations of words. The training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase the interesting linear substructures of the word vector space.
One of the most popular methods for learning word embeddings using shallow neural networks is Word2Vec. Distributed numerical representations of word features are generated. These word features are made up of words that convey the context of the individual vocabulary terms present. Through the generated vectors, word embeddings eventually assist in establishing the association of a word with another word having a similar meaning.
FastText is another word embedding method that is an extension of the word2vec model. Instead of learning vectors for words directly, FastText represents each word as an n-gram of characters. This helps to capture the meaning of shorter words and allows the embeddings to understand suffixes and prefixes. Once the word has been represented using character n-grams, a skip-gram model is trained to learn the embeddings. This model is considered a "bag of words" model with a sliding window over a word because no internal structure of the word is taken into account. All three word embedding models have 300 dimensions. As the maximum size of the text sequence is 69, the embedding layer size is set to 70.
The output from the first layer goes into the bidirectional GRU layer. This layer traps the totality of every single text sequence and passes it forward. The main idea is to capture the sequential information in the data. Then the outputs using global max-pooling and average-pooling layers (window size = 2) are concatenated. Here, the global max-pooling filters are only the valuable features, and the average pooling weights out all features to form a whole textual representation. This concatenated representation is now forwarded to a dense classification layer of 70 nodes with a dropout layer at a 50% rate to prevent overfitting. Finally, a sigmoid layer generates the output of the classifier, returning the emotion class probability.
Each classifier classifies a particular emotion and gets trained with a binary cross-entropy function to objectify the presence of the particular emotion in the text sequence. The training runs for 20 epochs with 250 as the batch size and uses the adam optimizer. For each classifier, the dataset is separated into 80% for training, 10% for validation, and 10% for testing. The dataset is prepared in such a way that it sets the target emotions as class 1 and a random sample of other emotions of the same size as class 0.
The proposed model runs three times on MELD, using one word-embedding model at a time among Word2Vec, Glove, and fastText. For each emotional class, metrics such as precision, recall, F1 score, and accuracy are used in the model's evaluation. The network's embedding vector space can be changed to compare the performances of different configurations while focusing on the research of the results produced by the proposed system on the MELD dataset.
From Table 2 it is possible to observe that the average accuracy of fastText is higher than the other two-word embeddings (Word2vec and Glove) used.
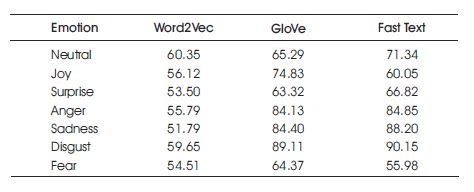
Table 2. Class Wise Accuracy of Bi-GRU With Different Word Embedding
In order to highlight the improved results with fastText on MELD dataset tested, the accuracy score value among these setups is crucial. As a result, in the task of emotion detection from the text, it is suggested to use fastText vector space for encoding the input.
MELD is used to implement Recurrent Neural Networks (RNN) and Bi-directional Long Short-Term Memory (Bi-LSTM) neural networks in order to demonstrate the improved performance of the proposed Bi-GRU model word embedding with fastText. Figures 4 and 5 depict the architectures of the implemented Convolutional Neural Networks (CNN) and bidirectional LSTM, respectively.

Figure 4. Architecture of CNN

Figure 5. Architecture of Bidirectional LSTM
Both architectures are depicted in the block diagram, with the hidden layers mentioned and the input and output clearly emphasized. The comparison of the parameters like accuracy, recall, precision, and F1 - Score for the modals like CNN, Bi-LSTM, Bi-GRU are shown in Figure 6.
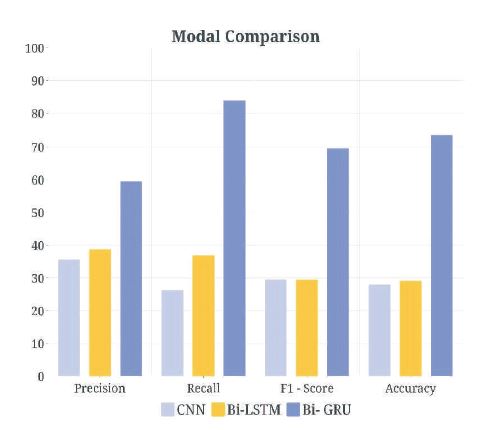
Figure 6. Comparison of Evaluation Metrics of CNN, Bi-LSTM, Bi-GRU
Convolutional Neural Networks (CNN) and Bi-LSTM models appear to perform similarly. The proposed Bi-GRU recognizes emotion with the highest accuracy of 79.7%.
Customization systems heavily rely on the capability to extract emotion classes from language. In this regard, ability to acquire precise annotations with a high level of granularity requires the use of tools. To meet this requirement, an emotion recognition model based on GRU is proposed to extract emotion classes from textual data. Furthermore, it was possible to quantify the impact of the word embedding technique chosen on the overall results of the proposed system. It has been demonstrated that the fastText word encoding for this design allows for the best results in emotion identification. As an enhancement, we aim to implement stacking classifiers using multiple word embeddings.