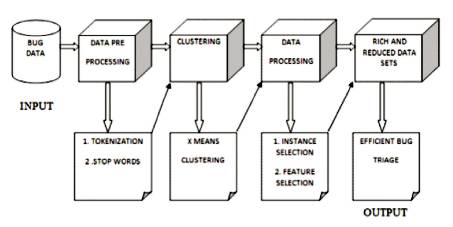
Figure 1. Framework for an Efficient Bug Triage Using Clustering Mechanism
Bug triage is the most important step in handling the bugs which occur during a software process. In manual bug triaging process the received bug is assigned to a tester or a developer by a triager, hence when the bugs are received in huge numbers it is difficult to carry out the manual bug triaging process, and it consumes much resources both in the form of man hours and economy, hence there is a necessity to reduce the exploitation of resources. Hence a mechanism is proposed which facilitates a much better and efficient triaging process by reducing the size of the bug data sets. The mechanism here involves techniques like clustering techniques and selection techniques. Their approach proved much efficient than the manual bug triaging process when compared with bug data sets which were retrieved from the open source bug repository called bugzilla.
Most of the software industries spend nearly half of their economy, that is more than 45 percent of their economy in finding out and correcting bugs alone, this is occurring due to the exploitation of resources both in the form of human labor and economy by implementing manual bug triaging process. Here the bugs are manually allocated to the testers or developers by the triagers, since the incoming bugs are all over from the world. It is a tedious process and requires much man power and economy to facilitate the process.
So, there is a necessity to reduce the expenditure. To deal with this exploitation, previously few techniques have been proposed like text classification techniques, Naïve bayes, and Support vector machine which facilitated the automation of the process, and also selection mechanisms like feature selection and instance selection have been used to reduce the size of the bug data sets for a better triaging process.
As few researchers proposed that triaging produces better results when the data undergoes preprocessing before any machine learning algorithms are applied to it Hence a combination of clustering mechanism and selection mechanism is used for a better triaging process. Primarily the data is prepared by pruning the data with the help of techniques like tokenization, stop words, stemming etc., and an algorithm called x means algorithm is used to cluster the data, and two selection mechanisms called instance selection and feature selection are used to reduce the size of the bug data set and provide better triaging process.
Ahmed E. Hassan & Tao Xie (2010), stated that, software engineering data contains useful information such as code bases, execution traces, bug databases, etc., By exploiting such data, we can build a more reliable software system by building dependencies based on the historical data produced in the software process. Ahmed E. Hassan (2008), stated that most commonly available repositories of a software system are source control repositories, bug repositories, archived communications, deployment logs, and code repositories.
T. Xie, et al. (2009) stated that, the mining software repositories concept which is called as MSR primarily analyzes and cross references all the data which is present in the repository to extract the data which is considered to be useful in the repository, by evolving these repositories from basic repositories which contain records to dynamic repositories which can be used for decision making in the aspect of software engineering. John Anvik, et al., (2006), stated that open source projects generally support open repositories in which both the user and the developers can access and report bugs. The reports which are received in the repository should undergo the process of triaging to determine whether the report is worthy or not, if it is that particular report should be assigned to a developer for further rectification. Davor Curbanic & G.C Murphy (2004) stated that, a bug tracking system is necessary to maintain bug reports on large software development projects. Research has been carried out by the researchers in the field of mining software repositories which augment traditional software engineering information by the use of tools and techniques, which are implemented in solving challenging problems in the field of software which the engineers face on a daily routine during the process.
Sunghun Kim, et al. (2006) stated that, change history is an important concept in the software development process, because it contains both the old bug reports and the solutions of those old bug reports, based on that we can build classifiers on the base of historical bug data. Triage is actually a medical term in which the patients are allocated based on their severity, and in a similar way bug triage is a term in which the bugs are allocated to the testers based on their priority. J. Xuan, et al. (2010) , stated that, most of the software industries contain and maintain a bug tracking mechanism to handle the arriving bugs, These bugs can be reported by various users, developers and testers. Before a bug can be rectified, it should be first allocated to a tester or a developer who can handle the bug. The process of allocation of bugs is known as bug triaging.
In conventional bug triaging, the process of allocation of bugs to testers or developers is done by humans who are called as triagers, and this process is costly in the terms of labor cost. H. Zhang, et al. (2013) stated that, for a large and evolving software organization, the triaging crew may get numerous bug reviews in excess for an extended period of time. It is crucial to achieve an optimal bug fixing time. The potential to predict bug fixing time can help a software to keep up with computer software projects. A Markov-based approach for predicting the number of bugs is used in this strategy. For a provided amount of defects, estimation is done by the total amount of time needed to correct them primarily based on the empirical distribution of bug-fixing time derived from historical information. J. Anvik and G. C. Murphy (2011) stated that, to facilitate better classification there is a necessity for recommenders, and they are designed based on the criteria given below.
Silvia Breu, et al., (2010), stated that in open source projects such as Mozilla, bugzilla and eclipse, the bug tracking systems interact with the user communities, so that the users can be a part of bug fixing process, hence this type of bug tracking systems play an important role in interacting and communicating with the users.
R. Nishanth Prabhakar & K.S. Ranjith (2016), stated that, Traditional bug consuming is a very tedious and time consuming job. The repositories which contain the bugs are called bug repositories, bugs are collected into a database, and the triaging team sorts out the bugs based on their priority.
Gaeul Jeong, et al. (2009) stated that, it is important that the bugs should be identified and rectified within time in software engineering process, Most of the bugs are manually allocated by human triagers which is a tedious task. T Zimmerman, et al. (2010) stated that bug reports acts as the main source of information for developers, but there exists a difference in the quality of each bug report, on the open source repositories like apache, eclipse and Mozilla. A survey has been conducted with the help of the users and developers, where more than 450 responses mismatched with the user requirement. To overcome this, methods like reproducing, and stack traces are used which are difficult to maintain for large number of bug reports.
Shivkumar Shivaji, et al. (2013) stated that prediction of bugs from source code files are done by using machine learning classifiers, primarily the classifier is linked with historical bug data and used for predicting the possible outcomes, yet these classifiers suffer from a drawback that is insufficient performance real world situations and slow prediction time. Some of the classifiers are Naïve Bayes and Support Vector Machine (SVM). A. Lamkanfi, et al. (2010) stated that, The severity of a reported bug is a vital factor in determining how quickly it should be fixed. Even if there are some mechanisms exist on how to assign the severity of a bug, it still needs a manual procedure for the human triager to report the bug. Another technique can be used in prediction of the severity of the bug that is by analyzing its textual content of the report and making use of text mining algorithms.
D. Matter, et al. (2009) stated that, there is a technique called expertise model which can be used to automatically suggest developers who have the suitable experience for dealing with a bug report. A developer expertise model is created by utilizing the vocabulary found in their source code contributions and compares this vocabulary to the vocabulary of bug reports. Finally by comparison of vocabulary, the allocation is done for a bug if the developer has already worked on that particular bug.
Feature selection can defined as the process in which the irrelevant features are deducted and detecting only the relevant ones, an optimal selection of features can bring improvement in the overall knowledge of domain, reduced size, generalization capacity, etc., J. Arturo Olvera Lopez, et al. (2010) stated that sufficient identification of features is necessary in real world scenario, hence the identification of features is important. M. Rogati & Yiming Yang (2002) stated that, feature selection is the best solution for text classification problems. It increases both the classification effectiveness and also the computational efficiency. Y. Yang & J. Pedersen (1997) stated that, there are five methods for text categorization; they are document frequency, information gain, mutual information, chi square test, and term strength.
Instance selection is a process, in which the dataset size is reduced, which eventually decreases the runtime, especially in the case of instance based classifiers. The commonly used instance selection mechanisms are wrapper and filter, here filtering mechanism is used called as Iterative Case Filtering (ICF) algorithm. W. Zou, et al. (2011) stated that, a combination of approaches can be used for dataset reduction by using instance selection and feature selection for bug triage. This combination technique is used to improve the accuracy of bug triage.
Neetu Goyal, et al. (2015) stated that there is a study which states that few researchers conducted experiments proving that, if the dataset which is being processed by the machine learning algorithms is preprocessed by a clustering method, then the quality of the output increases.
In software development process, the output of the software process is stored in large databases called software repositories. Conventional method of software analysis is not suitable for large databases, hence there is a necessity to reduce the size of the bug data. Data reduction for bug triage aims to build a small scale and efficient database by removing uninformative data. The problem of data reduction for bug triaging is how to reduce the size of the bug data to reduce labor cost of the developers and eventually increase the process of bug triaging.
It primarily concentrates on the problem of data reduction for bug triage in two aspects, namely
The main objective of the study is to reduce the expenditure in terms of time cost and manual labor during bug triaging, by reducing the size of the bug data sets. Previously, text classification techniques like Support Vector Machine and naïve bayes were used to reduce the size of the data sets, combinational approaches like combination of instance selection and feature selection were also used. Here to further reduce the size of the data set and increase quality of triaging, clustering mechanisms are used as a pre processing technique.
The proposed methodology starts by taking the bug data sets from open source bug repositories like Bugzilla, and Eclipse.
Figure 1 represents the proposed framework. Here initially the input data is taken as data sets and then the data is preprocessed using preprocessing mechanisms and the output of the preprocessing state is the pruned data, and the pruned data is taken as input and then clustering mechanisms are used and the pruned data is clustered. The clustered data is then taken as input and selection mechanisms are applied and the output of selection mechanism is the reduced data sets, which is further used for bug triaging.
Figure 1. Framework for an Efficient Bug Triage Using Clustering Mechanism
In the framework of the Figure 1 representing the downloaded bug data sets that are prepared by preprocessing mechanisms, the preprocessing mechanism which are being used are
Tokenization can be defined as the pre processing mechanism in which the given data is broken down into tokens or characters.
Stop word can be defined as the pre processing mechanism in which the grammar content that is removing capitalized words, punctuation marks and conjunctions like, the, it, this, there, us, we etc..,
On the completion of the preprocessing of bug data sets, the bug data sets are further processed by an algorithm called x means clustering algorithm.
Step 1: Initialize K= K min
Step 2: Run k means algorithm
Step 3: For k=1 to n K: Replace each centroid by two centroids μ1 and μ2 .
Step 4: Run k means algorithm with k =2 over the cluster k, replace or retain each centroid based on model selection criterion.
Step 5: If convergence condition is not satisfied, go to step 2, else exit.
Here in this algorithm, the model selection criterion is a condition called Bayesian Information Criterion (BIC), the algorithm performs a model selection test using BIC to decide whether the newly formed clusters are better than the original clusters or not,
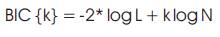
Where N is the observations and k is the number of clusters and log L is the log likelihood,
The following step after the x means clustering is the selection mechanisms which are instance selection and Feature selection,
Instance selection is a selection mechanism which uses the instance in which the bug occurred as the criteria, it is used to remove the noisy data. The algorithm which is used for instance selection is Automatic Branch and Bound algorithm (ABB).

Here Initially a procedure ABB S(X), is created, where S(X) is a sample space, x is derivation of sample space, var L` is the list set, for each subset x is present in X then the following steps should be done they are,
Step 1: en queue (Q, X\[{x}) here {x}is a random subset of a feature set. In this step, each feature set is removed from the sample space and inserted into the queue.
Step 2: By using a while loop, the queue is checked whether it is empty or not. If it is empty, we create a new sample space called as X` and we queue all the elements from the queue Q into the other sample space X`.
Step 3: Next if the data present in the sample space X` is legitimate, that is if it not a subset of pruned state, then by using an 'if' statement get J(S(X`)) ≥ J0 where as J(S(X`)) is an object function and J0 is the minimum allowed value.
Step 4: Then L`:= append (L`, X`), where as L` is a newly formed list of elements and the feature sets present in the sample space X` are appended into the newly formed list L`
Step 5: Finally, the procedure is closed by appending the list L` values to the derived sample space S(X`).
By using this algorithm, the noisy or uninformative data present in the data sets is reduced, In this context, the uninformative clustered data is removed from the dataset.
Feature selection is a selection mechanism which uses the features exhibited as the criteria. It is used to reduce redundancy, the algorithm which is used for feature selection is called as Iterative Case Filtering algorithm (ICF).

Step 1: Here by using a condition for all x ∈ T, whereas 'x' is the subset and 'T' is the training set, it is checked whether the subset belongs to the training set. If the condition is satisfied then by 'if' condition, the 'x' value is checked whether it is classified correctly or incorrectly this is done by using k nearest neighbor algorithm then flag 'x' is done for removal.
Step 2: Then again check for all x ∈ T, if 'x' is flagged then T=T-{x}, this means that the subset {x} should be removed from the training set 'T'.
Step 3: Iterate the above steps until no flagged items are left in the training set.
Step 4: Again check the condition for all x ∈ T, do compute reach ability (x) , compute coverage(x).
Step 5: for all x ∈ T, do if |reach ability(x)| > | coverage| then flag 'x' for removal.
Step 6: for all x ∈ T, do if 'x' is flagged for removal, then T=T- {x}, that is remove the subset from the training set, Return T.
All these mechanisms are applied on bug datasets which are used from the open source repository. A sample bug data set is given in Figure 2.

Figure 2. Sample Bug Dataset from an Open Source Bug Repository regarding a Bug (891298) called 'Error’
Here the primary attributes of a bug dataset is represented in Figure 2. The dataset (891298) is given below,
#Bug id = The allocation number of a particular bug id.
#Product = The product in which the bug occurred.
#Status = The present status of bug.
#Component = The component in which the bug has occurred.
#Version= Version of the product.
#Platform= Platform on which the product is being used.
#Importance= The level of prioritization of bug.
#Assigned to= The developer or the tester to whom the bug is assigned.
#Reported= Details about the time and date and the person who reported the bug.
#Modified= Details about the time and date and the person who modified the bug.
As previous research done by Jifen Xuan et al., on bug datasets from open source repositories like Mozilla and Eclipse, the evaluation of data reduction can be calculated by comparing two aspects they are, accuracy of bug triage and the scale of bug data.
Based on those aspects, a mathematical model can be developed as,

Based on this mathematical method, Jifen Xuan, et al. compared ten datasets five in Mozilla and five in eclipse. It is given in Table 1.
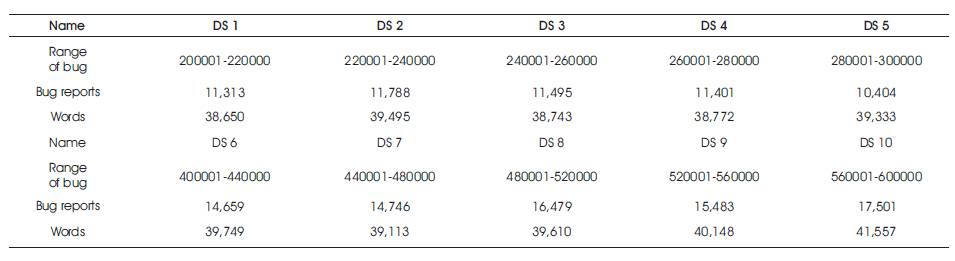
Table 1. Sample of Mozilla Dataset
Table 1 contains several fields like, Name of the dataset, range of the bugs, number of reports present in the dataset, and the number of words present in each dataset.
Five different datasets have been used which are named as BDS1, BDS2, BDS3, BDS4, BDS5, in Table 2 and Table 3, which are extracted from an open source bug repository called bugzilla. Here BDS represents bug datasets, Each bug dataset has different number of bug reports in it. All the bug datasets that is from BDS1 to BDS 5 are approximately ranged from 190900 to 1277000, The details of all the considered bug datasets are given in Table 2.

Table 2. Experimental sample which are considered (Bugzilla).
The experimental results obtained after the procedure of the experiment are tabulated in that table.
Table 3 shows the comparison of five different datasets ranging from BDS1 to BDS 5, by using both manual triaging and triaging after the data is reduced is shown graphically in Figure 3.
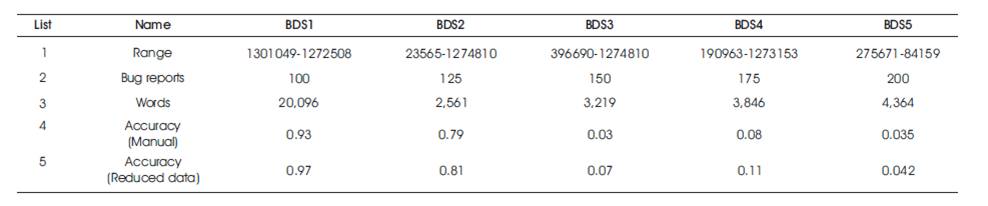
Table 3. Comparison between Manual and Reduced Data Triaging
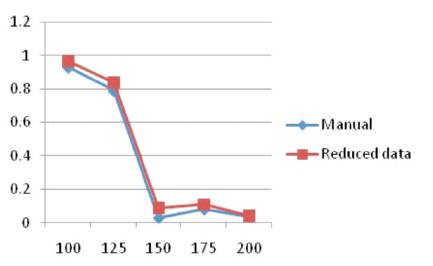
Figure 3. Curves of Accuracy between Manual and Reduced Data Triaging
Figure 3 depicts two curves, one representing the accuracy of manual triaging (blue), and the other representing the accuracy of reduced data triaging (red). Both these curves were plotted over the accuracy and the size of the dataset, where X-axis represents size of the dataset, Y-axis represents the accuracy value. When both these curves are compared, the value of accuracy is gradually decreasing with the increase in the size of the dataset, but the accuracy value of the reduced data triaging is more when compared to the manual bug triaging, Hence it can be stated that the accuracy of the bug triaging is increased by the usage of software data reduction techniques and clustering mechanism.
Bug triage is an expensive step in software maintenance in both cost of labor and time. Here the combinations of different selection techniques such as instance selection and feature selection are used to reduce the scale of bug datasets and also to improve the quality of the bug datasets. This process is further enhanced by using clustering mechanism like x means clustering as a pre processing mechanism. Due to this approach, the accuracy of the triaging process is increased when compared to manual bug triage and the bug triage using selection mechanisms. For future work, planning can be done in the way of data reduction by implementing further techniques to reduce size of data sets and facilitate a better bug triaging process.