Table 1. Movie Information Organized Using Tags
Now-a-days companies are concentrating on more data to take informed decisions. Companies that are able to effectively use data are the world leaders in terms of wealth, development and growth. Even to survive, operate and compete in this age, organizations need to be able to effectively use their data. Huge amount of investment is made in storing and processing large amounts of data to make better decisions. Data lake is a massive, easily accessible data store/repository that allows for collecting large volumes of structured and unstructured data in its native format from disparate data sources. This paper describes Data Lake, Schema-on-Write, Schema-on-Read, Characteristics and implementation of data lake.
Long gone are the days when businesses could be run by intuition or personal experience of a few people. Data driven organizations are the order of the day since that is the only way to survive and thrive in these days of cutthroat competition. Data never lies and the decisions taken based on the evidence and conclusions derived out of analysis of data are more likely to succeed and less likely to fail. It has been proven from many studies and research that Data Driven organizations perform better than their competitors.
Till now, the organizations depended on and are still depending on Enterprise Data Warehouses (EDW) for Data Driven decision making. The EDWs cater to the operational reporting needs and the analytical requirements of the organization. Operational reporting helps in getting the data required to support the day-to-day activities of the organization. Analytical Dashboards help in deriving Business Intelligence and insights out of the data collected over a period of time [1-6]. Building and maintaining the EDW more-or-less consists of the following steps:
This approach works fine within the following constraints.
With a great increase in volume, velocity and variety of data, new solutions and concepts are coming up to serve the needs of the Data Driven organizations. EDW is simply not a cost-effective solution to deal with this kind of Big Data.
Data Lake is one such concept and solution that is gaining traction these days. A Data lake is a massive, easily accessible data store/repository that allows for collecting large volumes of structured and unstructured data in its native format from disparate data sources [12-15]. The idea is to get the data into the data lake from the sources with minimum amount of processing (when compared to the ETL processes of an EDW) into a lesser rigid structure (when compared to that of a canonical data model).
At this point, it is appropriate to delve into the concepts of Schema-on-Write and Schema-on-Read before proceeding further with the Data Lake concept.
Schema-on-Write refers to the traditional EDW systems which require a schema before being able to load data into it. In relational parlance, you need a table in advance to be able to load data into it. If new fields get added in the incoming data, the table needs to be altered and columns are added to it before you can load data into it. This has the advantages of data consistency and allows for data retrieval at interactive speeds because the organization of data is tightly controlled by well-designed ETL processes and it is clearly known where the data in question resides. This model is good at getting answers to known Business questions. The disadvantage of this model is the loss of agility and the high cost and time involved in responding to even small changes.
Schema-on-Read refers to the concept of ingesting as-is data to the Data Store in native format with minimal amount of preparation and processing. Data Lake uses this Schema-on-Read model. Some amount of metadata may be associated with the data while storing it, so to be able to retrieve and organize it in a more useful format at a later date. This eliminates heavy processing at the time of data loading and allows for faster response to changes in the incoming data. When the actual use of the data becomes known in the context of the business questions, it needs to answer and when the data needs to be read and used, then the schema of the data can be defined. This is known as Late Binding. Thus the time and cost associated with data processing are deferred to the time of its actual usage. This is appropriate in the world of Big data where the value of data may not be known from the very start.
The term Data Lake was coined by James Dixon, who is the CTO and co-founder of Pentaho [7-9]. He first introduced this term in his following blog entry in October, 2010 (https://jamesdixon.wordpress.com/2010/10/14/pentaho -hadoop-and-data-lakes/).
In the above blog entry, he gave the analogy of bottled water for the structured and cleansed data in a data mart. A Data lake is compared to a large body of water, which is in a more natural state.
As with any concept/technology, Data Lake has evolved from the time James Dixon had described it five years back. The following characteristics of Data Lake [10] can be seen when we study the various contexts in which the term Data Lake is being today.
The most popular option used to implement Data Lake is Apache Hadoop. Data in Data Lakes is stored on Hadoop Distributed File System (HDFS).
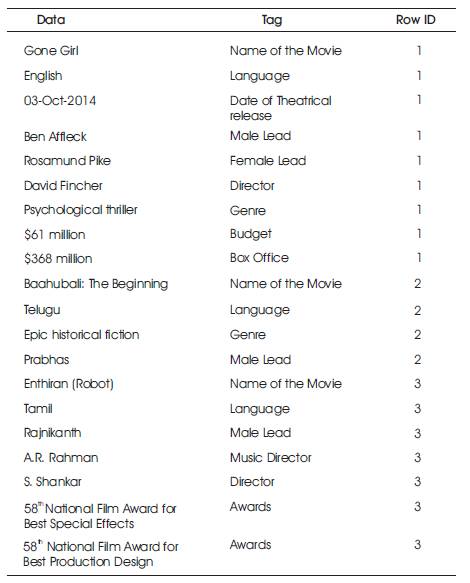
Booz Allen Hamilton Inc. [11] explained an innovative approach using key/value to organize data in the Data Lake. The metadata is stored along with the Data in the form of tags. These tags allow for storing, managing and retrieval of Data. The example in Table 1 shows the movie data organized using tags. In actual implementation scenario, further types of tags like Tag Group, Time Stamp and Visibility may be associated with the data. The table shows how flexibly the data can be organized. As newer type of data get added in future, the same can be simply handled by adding a new tag.
Table 1. Movie Information Organized Using Tags
The inability of existing analytical systems to respond to the speed of business has given rise to the concept of Data Lake and its adoption in Businesses. It is not that all the existing analytical systems are obsolete, but there are many use cases for which Data Lake may be the appropriate and cost-effective solution. Data Lake is definitely one solution which can serve a purpose or requirement which is not even known at this moment and thus enable the organizations to be future ready. Those organizations planning to adopt the Data Lake strategy should also be aware of the risks of their Data stores turning into Data Graveyards or Data Sewers when data is dumped into the Data Lake without proper thought. Usage of proper technologies and tested industry standard methods/processes will prevent this problem.