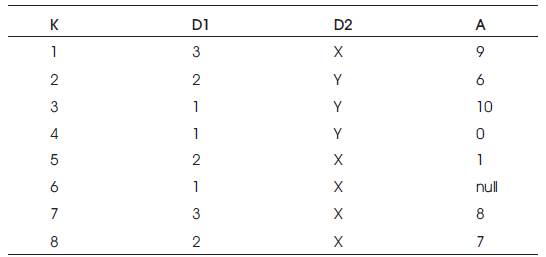
Table 1. Table – F
Data Mining is one of the emerging fields in research. Preparing a Data set is one of the important tasks in Data Mining. To analyze data efficiently, Data Mining systems are widely using datasets with columns in horizontal tabular layout. Building a datasets for analysis is normally a most time consuming task. Existing SQL aggregations have limitation to build data sets because they return one column for aggregated group using group functions. A method is developed to generate SQL code to return aggregated columns in a horizontal tabular layout, returning a set of numbers instead of one number per row. This new class of functions are called horizontal aggregations. This method is termed as BY-LOGIC. SQL code generator generates automatic SQL code for producing horizontal aggregation. A fundamental method to evaluate horizontal aggregation called CASE (exploiting the case programming construct) is used. Basically, there are three parameters available namely: grouping, sub-grouping and aggregating fields for creating horizontal aggregation. Query evaluation shows that CASE method responses faster than BY-LOGIC method.
Data Mining is the process of analyzing data from different perspectives and summarizing it into useful information. Simply, data mining refers to extracting or mining knowledge from large amounts of data.
Data mining is the task of discovering interesting and hidden patterns from large amounts of data where the data was to be stored in databases, data warehouses, OLAP (Online Analytical Process) or other repository information. Data mining is a part of a process called KDD-knowledge discovery in databases [11] [3].
This process is concerned with the collection of data from different sources and locations [6]. The current methods used to collect data are:
All raw data sets which are initially prepared for data mining are often large. Real-world databases are subject to noise. Data preprocessing is commonly used as a preliminary data mining practice. It transforms the data into a format, that will easily and effectively be processed by the users [9]. There are a number of data preprocessing techniques namely:
The estimating and building the model consists of four processes. The series of processes are,
Dataset preparation is very important for any of the operations in the data mining analysis. Preparation of dataset addresses many issues, and there are solutions for overcoming this problem. For performing operations on data stored inside the database system, users normally use SQL queries to retrieve those data and prepare it as required [5].
A method is developed to generate SQL code, to return aggregated columns in a horizontal tabular layout, returning a set of numbers instead of one number per row. This new class of functions is called horizontal aggregations.
A fundamental method to evaluate horizontal aggregation called CASE (exploiting the case programming construct) is used. Basically, there are three parameters available namely: grouping, sub-grouping and aggregating fields for creating horizontal aggregation. Query evaluation shows that CASE method responses faster than BY-LOGIC method. Using this method can avoid the web application attacks. Like Cross Site Scripting (XSS), Cross Site Request Forgery (CSRF), and injection type of attacks [12] [10].
In data mining project, a huge amount of time is dedicated in building datasets. It generally requires joining tables and aggregating columns with SQL queries. Existing aggregations are limited, since they return a single number per group. Whereas, horizontal aggregation returns a set of columns instead of single number per row. Two strategies are followed. The first strategy is based only on relational operators and the second one uses the CASE construct [2]. Data mining project consists of four phases. First phase involves extracting, cleaning and transforming data for analysis. In second phase, a data mining algorithm analyses the prepared dataset. Third phase validates results and creates reports. During the fourth phase, statistical results are deployed on new data sets. In a relational database environment with normalized tables, a significant effort is required to prepare a summary data set in order to use it as input for a data mining algorithm.
In a relational database environment building a suitable data set for data mining purposes is a time-consuming task. This task generally requires writing long SQL, if it is automatically generated by some tool. There are two main ingredients in such SQL code: joins and aggregations. The proposed project concentrates on the second one. The most widely-known aggregation is the sum of a column over groups of rows. In data mining, statistical or machine learning algorithms generally require data in a summarized form that needs to be aggregated from normalized tables. Normalization is a well-known technique used to avoid anomalies and reduce redundancy when updating a database. When a database schema is normalized, database changes tend to be localized in a single table.
Based on current available functions and clauses in SQL, there is a significant effort required to compute aggregations when they are desired in a tabular form, suitable to be used by a data mining algorithm. Such effort is due to the amount and complexity of SQL code that needs to be written and tested. To be more specific, data mining algorithms generally require the input data set to be in a tabular form having each point/observation/instance as a row and each dimension/variable/feature as a column. Standard aggregations are hard to interpret when there are many result rows, especially when grouping attributes have high cardinalities. To perform analysis of exported tables into spreadsheets, it may be more convenient to have aggregations on the same group in one row. There are two practical issues with horizontal aggregations: reaching the maximum number of columns and reaching the maximum column name length, if columns are automatically named. Horizontal aggregations may return a table that goes beyond the maximum number of columns in the DBMS when the set of columns has a large number of distinct combinations of values, when column names are long or when there are several horizontal aggregations in the same query. This problem can be solved by vertically partitioning, so that each partition table does not exceed the maximum allowed number of columns. There also pivot and unpivot operators, that transpose rows into columns and columns into rows Horizontal aggregations are useful to build data sets in tabular form [1] [7].
The existing system has some of the drawbacks which are to overcome. The drawbacks are as follows:
All aggregations present limitations to build data sets for data mining purposes.
In data mining, preparing data set for analysis is a tedious process. This process includes many complex SQL queries, joining tables and aggregating columns. Presently, existing SQL aggregation (vertical aggregation) have limitations to produce data sets because they return one column per aggregated group. A work is needed to produce data sets in horizontal layout [8].
The proposed horizontal aggregation produces data sets that will be in horizontal layout. This is the standard layout required by most data mining algorithms. Horizontal aggregation is created BY-LOGIC which is then optimized using CASE programming construct. Query Evaluation compares the time required by these two ways to produce horizontal aggregation. SQL Code generator is used to generate complex SQL queries. The concept of horizontal aggregation is explained briefly with the following Tables 1,2 and 3.
Table 1. Table – F

Table 2. Vertical Table – Fv
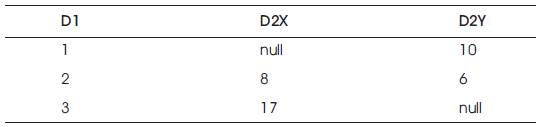
Table 3. Horizontal Table - Fh
Input : Databases
Output : Horizontal Aggregated Table
The proposed project explains about the creation of horizontal aggregations and the steps for the creation of horizontal aggregations are as follows:
The proposed system has been divided into three modules and the modules are as follows:
The horizontal aggregation is created by two methods namely: BY-LOGIC and CASE. First method creates horizontal aggregation through the creation of vertical aggregation. Second method directly creates the horizontal aggregation. SQL Code generator generates SQL queries to perform these two methods.
First method is called BY-LOGIC. To produce horizontal aggregation, databases with tables are needed. This method proceeds by two phases. First, it creates vertical aggregated table then it transforms the vertical aggregated table into horizontal aggregated table. An authentication system is provided for security purpose.
Before creating vertical aggregation, there are some inputs to be given. First, list of available databases are displayed. List of databases are displayed using the SHOW DATABASES command through a JSP code. On choosing a database, list of available tables inside the selected database are displayed. List of tables in the selected database can be displayed using metadata() and getTables(). Then on choosing a table from the displayed list, fields inside the selected table can be displayed using metadata() and getcolumnName(). The chosen table is denoted by F. In the parallel, the selected table's contents are displayed. The contents of the selected table are displayed using SELECT query.
Then creation of vertical aggregation starts. Creating a vertical or horizontal aggregation, requires three necessary parameters. The necessary parameters are GROUPING field, SUB-GROUPING field and AGGREGATING field.
Grouping field is described as, it is the field name that uniquely points a record in the resultant vertical or horizontal aggregated table. Sub-grouping fields is described as, it is the fields whose values are to be transposed into horizontal layout. Aggregating fields is described as, it is the field on which aggregation function works on. The proposed project uses the SUM() aggregation function.
After the contents of the selected table are displayed, they displayed three drop down list box for each necessary parameters. The drop down list box contains the field names of the selected table. Grouping, Subgrouping, aggregating fields are selected from the list. These parameters are sent to SQL Code generator. The SQL Code generator generates dynamically the needed query to perform vertical aggregation. SQL Code generates a query to create a table dynamically with the necessary parameters as fields. The dynamically generated table is named Fv (Vertical Aggregated Table). Vertical aggregation can be produced using GROUP BY clause. The default syntax to create vertical aggregation is,
SELECT L1 ,….,Lm, SUM(A)
FROM F
GROUP BY G1 ,….,Gm
Grouping field is denoted by L. Sub-grouping field is denoted by G. Aggregating field is denoted by A.
This vertical aggregation query is dynamically generated by SQL Code generator. The generated query is executed. Using the result, the obtained vertical aggregated values are inserted into Fv dynamically. Now a vertical aggregated table is created. SQL Code generator generates SQL query to create Fv for different databases, different tables and different fields.
In second phase of first method, for creating horizontal aggregation, vertical table which is created in last phase is given as input to the horizontal aggregation creation process. After providing the vertical aggregated table as input, horizontal aggregation is created by the following steps:
The created horizontal aggregated table is made persistent in the selected database, such that it can be given as input for data mining analysis. SQL Code generator creates SQL queries for different databases, different tables and different columns correctly.
The second method implements CASE construct to create horizontal aggregation. CASE is an in-built operator that is available in all DBMS. CASE is like switch case statement in programming languages. The simple CASE statement only allows matching a value of an expression against a set of distinct values. In order to perform more complex matches such as ranges, use the searched CASE statement. The searched CASE statement is equivalent to the IF statement, however its construct is much more readable.
The following illustrates the syntax of the searched CASE statement:
CASE
WHEN condition_1 THEN commands
WHEN condition_2 THEN commands
ELSE commands
END CASE;
MySQL evaluates each condition in the WHEN clause until it finds a condition whose value is TRUE, then corresponding commands in the THEN clause will execute. If no condition is TRUE , the command in the ELSE clause will execute. If the ELSE clause is not specified and no condition is TRUE, MySQL will issue an error message. MySQL does not allow empty commands in the THEN or ELSE clause. If the logic in the ELSE clause is not to be handled while preventing MySQL raise an error, an empty BEGIN END block in the ELSE clause can be inserted.
This method also requires 3 parameters like as in the BYLOGIC method namely: grouping, sub-grouping and aggregating fields. Grouping field is described as, it is the field name that uniquely points a record in the resultant vertical or horizontal aggregated table. Sub-grouping fields is described as, it is the field whose values are to be transposed into horizontal layout. Aggregating fields is described as, it is the field on which aggregation function works on. The CASE construct uses the SUM () as aggregation function.
After the contents of the selected table are displayed, they displayed three drop down list box for each necessary parameters. The drop down list box contains the field names of the selected table. Grouping, Subgrouping, aggregating fields are selected from the list. These parameters are sent to SQL Code generator. The SQL Code generator generates dynamically the needed query to perform horizontal aggregation. SQL Code generator generates a query to create a table dynamically with the necessary parameters as fields. The dynamically generated table is named Fh.
This horizontal aggregation query is dynamically generated by SQL Code generator. The generated query is executed. Using the result, the obtained vertical aggregated values are inserted into Fv dynamically. Now, a vertical aggregated table is created. SQL Code generator generates SQL query to create Fv for different databases, different tables and different fields.
The flow diagram for the process of creating horizontal aggregation by BY-LOGIC method and CASE method is shown in the following Figure 1.
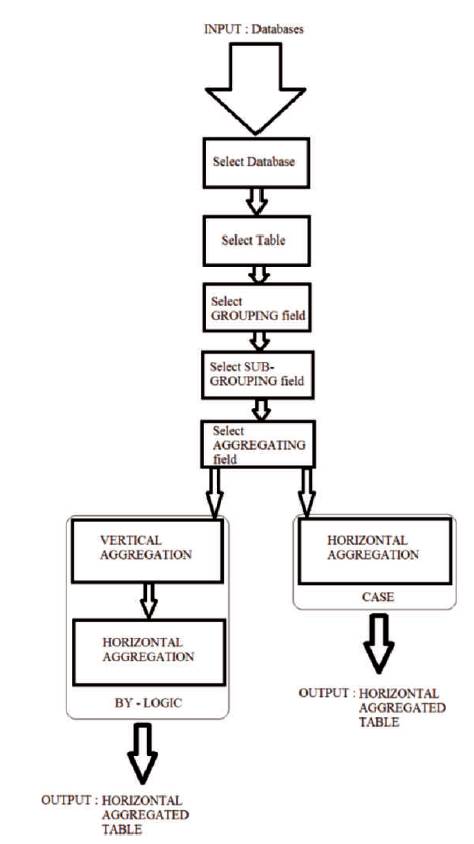
Figure 1. Flow Diagram for Creation of Horizontal Aggregation
The proposed project explains how to evaluate horizontal aggregations with standard SQL using CASE construct. The CASE relies on the SQL case construct. The CASE Strategy is important from a practical standpoint given its efficiency. Our proposed horizontal aggregations can be used as a method to automatically generate efficient SQL code with three sets of parameters: grouping columns, Sub grouping columns and aggregated column. The basic difference between vertical and horizontal aggregations from the user point of view is just the inclusion of sub grouping columns.
Data analysis applications look for unusual patterns in the data. They categorize data values and trends, extract statistical information, and then contrast one category with another. There are four steps to such data analysis: formulating a query that extracts relevant data from a large database, extracting the aggregated data from the database into a file or table. Visualizing the results in a graphical way and analyzing the results and formulating a new query. Visualization tools display data trends, clusters, and differences. Some of the most exciting work in visualization focuses on presenting new graphical metaphors that allow peoples to discover data trends and anomalies. Many of these visualization and data analysis tools represent the dataset as an N-dimensional space.
Visualization as well as data analysis tools do "dimensionality reduction", often by summarizing data along the dimensions that are left out. For example, in trying to analyze car sales, we might focus on the role of model, year and colour of the cars in sale. Thus, we ignore the differences between two sales along the dimensions of date of sale or dealership, but analyze the total sale for cars by model, by year and by colour only. Along with summarization and dimensionality reduction, data analysis applications extensively use constructs such as histogram, cross-tabulation, subtotals, roll-up and drilldown.
Visualization and data analysis tools extensively use dimensionality reduction (aggregation) for better comprehensibility. Often data along the other dimensions that are not included in a "2-D" representation are summarized via aggregation in the form of histogram, cross-tabulation, subtotals etc. In the SQL Standard, aggregate functions and the GROUP BY operator are depended to support aggregation. SQL's aggregation functions are widely used in database applications. This popularity is reflected in the presence of aggregates in a large number of queries in the decision-support benchmark TPC-D. The TPC-D query set has one 6D GROUP BY and three 3D GROUP BYs. One and two dimensional GROUP BYs are the most common. Surprisingly, aggregates appear in the TPC onlinetransaction processing benchmarks as well.
Certain common forms of data analysis are difficult with these SQL aggregation constructs. As explained next, three common problems are: (1) Histograms, (2) Roll-up Totals and Sub-Totals for drill-downs, (3) Cross Tabulations. Creating a data cube requires generating the power set (set of all subsets) of the aggregation columns. Since the CUBE is an aggregation operation, it makes sense to externalize it by overloading the SQL GROUP BY operator. In fact, the cube is a relational operator, with GROUP BY and ROLL UP as degenerate forms of the operator. This can be conveniently specified by overloading the SQL GROUP BY clause [4].
To minimize data movement and consequent processing cost, compute aggregates at the lowest possible system level. If possible, use arrays or hashing to organize the aggregation columns in memory, storing one aggregate value for each array or hash entry. If the aggregation values are large strings, it may be wise to keep a hashed symbol table that maps each string to an integer so that the aggregate values are small. When a new value appears, it is assigned as a new integer. With this organization, the values become dense and the aggregates can be stored as an N-dimensional array. If the number of aggregates is too large to fit in memory, use sorting or hybrid hashing to organize the data by value and then aggregate with a sequential scan of the sorted data. If the source data spans many disks or nodes, use parallelism to aggregate each partition and then collapse these aggregates.
Query Evaluation shows the performance analysis of the proposed two methods in terms of time complexity.
First performance analysis depicts the time complexity of BY-LOGIC. Records of different range are given as time as input to the BY-LOGIC. The response time of creating horizontal aggregation is noted down. The number of records range from 100 to 500 in 100 intervals. A graph is plotted for a number. of records against the response Figure 2 shows the Performance Analysis of BYLOGIC.
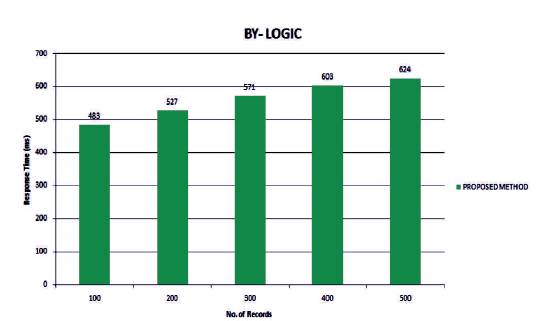
Figure 2. Performance Analysis - BY-LOGIC
Second performance analysis depicts the time complexity of CASE. Records of different range are given as time as input to the CASE. The response time of creating horizontal aggregation is noted down. The number of record ranges from 100 to 500 in 100 intervals. A graph is plotted for number of records against the response time.
Third performance analysis depicts the time complexity difference between BY-LOGIC and CASE. Records of different range are given as time as input to the BY-LOGIC and CASE. The response time of creating horizontal aggregation is noted down. The number of record ranges from 100 to 500 in 100 intervals. A graph is plotted for the number of records against the response time and their differences are shown in the following Figures 3 and 4.
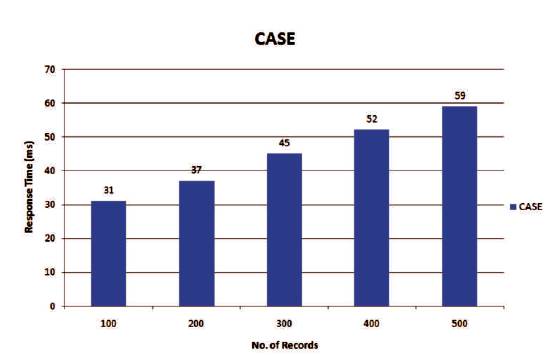
Figure 3. Performance Analysis – CASE
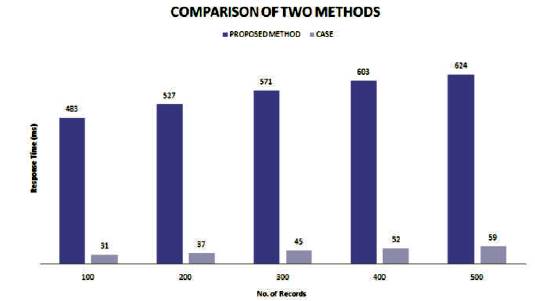
Figure 4. Performance Analysis – Comparison
Table 4 shows the output of horizontal aggregation that has been created. Usually vertical aggregated tables are created using the following query (Ex):
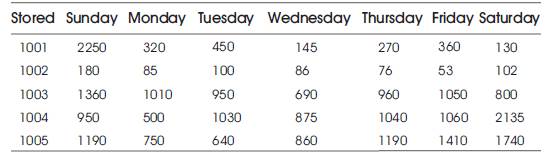
Table 4. Output of Horizontal Aggregation
SELECT StoreID, DayWeekno, Sales Amt
FROM Deptstore
GROUPBY StoreID,DayWeekno
ORDERBY StoreID,DayWeekno;
And then Vertical aggregated table is converted into horizontal aggregated table. SQL Code generator creates dynamic complex SQL queries to perform vertical and horizontal aggregation.
The creation of horizontal aggregated table is optimized through CASE strategy which is an inbuilt operator that is already available in DBMS. Figure 5 shows the response time of both methods. The CASE method responses much faster than BY-LOGIC method. This is because of SQL Code generation in both the methods. In BY-LOGIC method, the SQL Code generator generates many UPDATE queries which is equal to the number of tuples in the horizontal aggregated table. Whereas in CASE method, the SQL Code generator generates single query to perform horizontal aggregation.
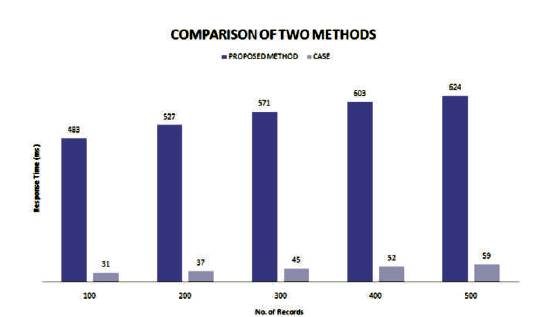
Figure 5. Evaluation
SQL code generator is created. SQL code generator generates query for the creation of vertical and horizontal aggregation. The Horizontal Aggregation is created through two methods. First method creates horizontal aggregation in comparatively high responsive time. Second method is implemented through CASE construct that optimizes the creation horizontal aggregation. Working with large number of data sets and small number of data sets produces the expected output.
If the length of the aggregated object exceeds the column length of related database, then there occurs an error which may be overcome by using alias method. That means it is very complex to aggregate when data fields contain multimedia content. That is, aggregating the data become very tedious process when the data are image, video, files.