Figure 1. TCP Flow Diagram
In today’s scenario most of the work carried out is accomplished through the internet. Internet plays a vital role in day-today’s regular activities and hence has become the backbone of our society. In internet the data is transferred from one place to another with the help of most commonly used protocol known as Transmission Control Protocol (TCP). TCP possesses various variants and each one has different criteria such as TCP, Tahoe, Reno, New-Reno and so on. Each variant performs in a different routine for different networks based upon the various key parameters. In this paper we have simulated various TCP variants with respect to different network parameters such as variable packet size, bandwidth and buffer size. This paper analyses the throughput, packet drop, delay and jitter of TCP variants evaluated over the above mentioned network parameters.
Transmission Control Protocol (TCP) is a reliable connection oriented end to end protocol in which each packet sent over the network is acknowledged by the receiver. Connection establishment in TCP is based upon 3-way handshaking between a sender and a receiver in which SYN and ACK packets play a major role. Sender sends a SYN packet to receiver along with a sequence number which is acknowledged by the ACK packet of receiver, thereafter establishing the connection, and the packet is sent.
Protocols are set of rules for the exchange of messages over the network and TCP is considered as the most reliable one. But the network's imperfection leads to slight amount of packet loss during the transmission. There are various causes for the packet loss such as network error, bit error, congestion in the network but the main culprit is buffer overloading at the router. So it becomes the responsibility of the TCP to handle such errors. It comes to the rescue by starting a timer while sending a packet over the network. If the timer times out, TCP resends the packet to the receiver. strength of the TCP lies in its congestion avoidance and control algorithm as well as its retransmission procedure. So congestion control plays a vital role in adjusting rate of transfer of data to avoid occurrence of congestion in the network.
The initial TCP suffered many issues due to the congestion in the network. Therefore many versions were proposed by different people to improve the performance of TCP in context of wired, wireless, high speed and long distance network. These versions later came to be known as TCP Variants for congestion control.
The rest of this paper is organized as follows. Section 2 covers certain important related works in the field of comparison of various TCP variants. Section 3 discusses types of methodologies used in networks for congestion control and avoidance along with the description of different types of TCP variants. Section 4 offers details about the experimentation, describing about the simulation based comparison of TCP variants that the authors have incorporated. In Section 5, performance assessments and evaluations for comparing different TCP variants over diverse parameters are discussed. Finally, Section 6 presents the conclusion and outlines for future work.
MazleenaSallehet. al. (2005) compared four TCP variants- Tahoe, New-Reno, Vegas and SACK on the self-similar RESEARCH PAPERS traffic. In this paper authors have concluded that even in small LAN such as FSKSM and UTM, the traffic flow still demonstrates self-similar properties. Other conclusion was that TCP New-Reno performs best among the four variants in terms of efficiency and throughput [1].
A.R.Britto Pradeep et. al. (2011) performed comparisons of drop rates in various TCP variants such as Reno, New- Reno, STCP and so on; again different routing protocols such as DSDV, DSR, AODV and TORA are detailed. The authors concluded in this paper that irrespective of the number of nodes as well as simulation time, TCP Tahoe had least packet drop[2].
Poonam Tomaret. al (2011) analyzed three TCP variants – Tahoe, Reno and Lite over the ad-hoc network on various parameters like packet loss, byte received, throughput and pause time. They concluded that no single TCP variant performs well for all parameters. For few parameters, one variant performs better and for the other parameters, other variant performs well[3].
AnkurLalet. al (2012) analyzed the performance for TCP variants such as Reno, Vegas and NJplus with routing protocols such as AODV and DSDV over wireless networks. They concluded that no single TCP variant performs well for all parameters. For few parameters, one variant performs better and for the other parameters, other variant performs well. But TCP NJplus performance was little better than the other compared variants[4].
Jawhar ben Abed et. al. (2012) compared eight low and high speed TCP variants with multiple flows. They concluded that some variants perform well for particular defined cases and perform poorly for some other conditions. It was one of their observations that network architecture plays a significant role in the evaluation of performance of TCP variants[5].
Mohit P. Tahilianaiet. al. (2013) analyzed high speed TCP variants for multi-hope non wired networks. They studied high speed variants by making the changes in routing protocols such as DSDV - Destination Sequenced Distance Vector, AODV - Ad hoc On Demand Distance Vector and DSR - Dynamic Source Routing. They evaluated high speed variants on the basis of their throughputs for different topologies such as static and mobile topology. They made an observation that TCP's performance relies immensely on the type of routing protocol being used[6].
MadihaKazmiet. al. (2014) has done the broad study of TCP variants in IP - Internet Protocol and MPLS - Multi- Protocol Label Switching network with CBR - Constant bit rate traffic. They analyzed different variants and came to the conclusion that TCP Vegas had the best performance and throughput among the variants as Reno, New- Reno, SACK, Tahoe and Vegas [7].
Kevin Fall et. al. illustrates the benefits of adding selective acknowledgment to TCP. It deals with the comparison of the two versions of TCP Reno that is TCP New-Reno and TCP SACK. They performed various experiments and came to the conclusion that TCP SACK works better than TCP Reno and TCP New-Reno[8].
TCP congestion control is an end to end approach but TCP does not receive any information from network layer about current state of the network. Therefore TCP sender must monitor the network in order to identify whether the congestion is occurring in the network. When packet loss occurs then TCP sender comes to know about the packet loss. In network, there are two ways of knowing about the occurrence of packet loss. Firstly the time out occurrence, at the sender side. Secondly when sender receives three duplicate acknowledgments from the receiver for the same segment, it signifies the next segment in the sequence is lost [23, 24].
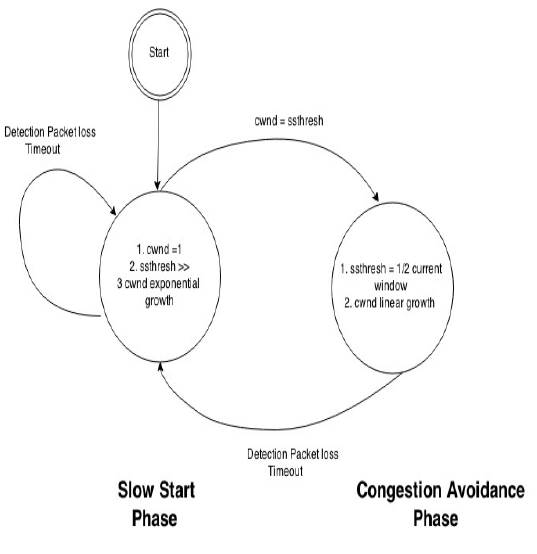
TCP sender utilizes slow start and congestion avoidance algorithm to determine how much data can be sent via current window. These algorithms use a variable called Congestion Window (cwnd) which gives the information to the sender about the amount of data that can be sent over to the network till an acknowledgment is received. Whether slow start algorithm or congestion avoidance algorithm should be used is decided by the value of Slow Start Threshold (ssthresh). The decision criteria is as shown in Figure 1.
Figure 1. TCP Flow Diagram
There are different TCP variants based upon the several ways of implementation of congestion control algorithm. These variants are described below:
A congestion control algorithm TCP Tahoe had been proposed by V.Jacobson based on a concept of “Conservation of Packets”. It works on the model in which a connection is working at available bandwidth capacity, and then no new packet is injected in the network till the previous packet gets acknowledged by the receiver. Major executions in Tahoe are:
Whenever a connection starts or restarts after a packet loss, TCP Tahoe uses slow start. Since the packet loss rate is high when initially huge number of packets are sent, so TCP Tahoe increases cwnd exponentially until a sign of congestion is captured by it.
TCP Tahoe uses the concept of Additive increase multiplicative decrease (AIMD). When congestion occurs Tahoe set the ssthresh as half of the current window value and then set cwnd to one. Afterwards the slow start procedure is started until cwnd reaches the threshold value [9].
Another congestion control algorithm TCP Reno had been proposed by V.Jacobson. This variant sustains slow start and coarse grain retransmit timer concepts of the TCP Tahoe but adds an intelligence to detect the lost packet soon. In this, an algorithm called “Fast Retransmit” was suggested in which whenever three duplicate acknowledgments occurs for a same segment, it is taken as a sign of packet loss and retransmits that packet without waiting for the time out. Also, it does not set cwnd as one, but it is set to half after the detection of packet loss [10].
Modified version of congestion control algorithm TCP Reno had been proposed by S.Floyd et. al. This algorithm detects multiple packet loss and is more efficient than TCP-Reno while dealing with multiple packets. Like Reno it enters into the Fast Retransmit algorithm as soon as the acknowledgment duplicity is detected but unlike Reno, it does not come out of the algorithm till all the outstanding packets are sent over [11]. .
A congestion control algorithm TCP SACK had been proposed by M. Mathis et. al. TCP SACK (selective acknowledgment) is an extension of TCP Reno which tackles the problems of TCP Reno as well as the TCP New- Reno like detection of multiple loss packets and retransmission of more than single packet in one RTT (round trip time). It laid emphasis on making the selective acknowledgment rather than cumulative acknowledgment on a segment. Every ACK has a block describing which segments are acknowledged and gives information to sender about the acknowledged packets and pending packets[12].
A congestion control algorithm TCP Vegas had been proposed by L.S. Brakmo et. al. It is the modified version of TCP Reno based upon the fact that proactive measures in the congestion detection are more efficient as compared to the reactive measures. It overcomes the problem of detection of packet loss by three acknowledgments only and modified slow start algorithm to prevent congestion in the network. It does not merely depend upon the packet loss as the only sign of congestion occurrence, rather it helps in detection of congestion prior to occurring of packet loss in network [13].
A congestion control algorithm TCP Westwood had been proposed by C. Casetti et. al. It is a sender side modification of congestion window algorithm and it enhances the TCP's performance on the wired as well as wireless network. Its performance is not sensitive for the random loss of packets unlike TCP-Reno which is equally sensitive for random loss and congestion loss, as it fails in determining the difference between the two. TCP Westwood completely follows end to end transmission, in which sender side's bandwidth is constantly examined by keeping a track of rate of returning of ACK's. This rate is further used to determine the values of cwnd and ssthresh unlike TCP-Reno which blindly halves the ssthresh [14].
A congestion control algorithm TCP Westwood had been proposed by C. P. Fu. It is simple and effective for dealing with random packet loss. The main idea is to monitor network congestion level and that same information is further used to determine whether it is congestion error or random bit error. It works on the similar idea of Vegas but instead of using the measures for adjusting the window size proactively, it rather uses it as an indication whether the connection is in congestion or not [15].
A congestion control algorithm TCP H-TCP had been proposed by R. Shorten et. al. This TCP was designed for the high speed and long distance networks. It stated that the conventional TCP variants were not effective when the window size becomes large and they also consume a lot of time to recover a packet loss which leads to poor bandwidth utilization in the network. Unlike conventional TCP variants, this variant adjusts the rate of insertion of packets into the network. It reduces the rate for conventional variants whereas increases the rate for high speed and long distance networks automatically[16].
A congestion control algorithm TCP BIC had been proposed by Lisong Xu et. al. which is a high speed congestion control protocol ensuring RTT fairness in large windows while maintaining both the scalability and TCP friendliness. It combines the two ideas of Additive increase and Binary Search increase. In case of large congestion window, additive increase is implemented with large increments. By this RTT, fairness and scalability is maintained. In case of small congestion window, binary search increase is implemented and hence this maintains TCP friendliness [17].
A congestion control algorithm TCP CUBIC had been proposed by Injong Rhee et. al. Its main feature is that its window growth function is defined on real time base system. Thus it makes the growth of window independent of RTT. Since window growth is not depending upon RTT, fairness of RTT is maintained as it does not hinder the flow of other RTT's. In this TCP, window growth function is a cubic function similar to TCP BIC [18].
This congestion control algorithm had been proposed by Tom Kelly. TCP congestion control algorithms works poorly in the high speed wide area networks as they have slow response time in such cases. Scalable TCP provides a robust mechanism which improves performance in high speed wide area network. It is designed to be incrementally deployable and performs similar to conventional TCP variants when the window size is small. Its main advantage is that when an ACK is received and congestion is not detected, window size is increased. But if congestion is detected on ACK arrival, window size is decreased[20].
A congestion control algorithm TCP Illinois had been proposed by Shaoliu. It utilizes the information regarding packet loss so that it can notify about the action to be taken on the window size, whether the window size need to be increased or decreased. It achieves high throughput, allocates network resources judicially and is compatible with standard TCP's. To achieve concave window curve, it keeps incremental factor large when there is no sign of congestion and it keeps incremental factor small if congestion control is likely to occur. Similarly it keeps decremental factor small when there is no sign of congestion and it keeps decremental factor large if congestion control is likely to occur[21].
This congestion control algorithm had been proposed by Andrea Baiocchi et.al. for high speed networks. It works basically on two modes: fast and slow. In fast mode it increments congestion window with respect to an aggressive rule. In slow mode, it works similar to TCP Reno[22].
Implementation of different TCP variants apart from Reno, New-Reno, SACK and Vegas was carried with the help of TCP Linux. The various steps involved in implementation are described below:
The topology on which we have performed various experiments is Dumbbell Topology consisting of 6 hosts and 2 routers as shown in Figure 2. The positive edge of this topology is that it is highly scalable. The traffic flow in this topology is analyzed by different TCP variants.
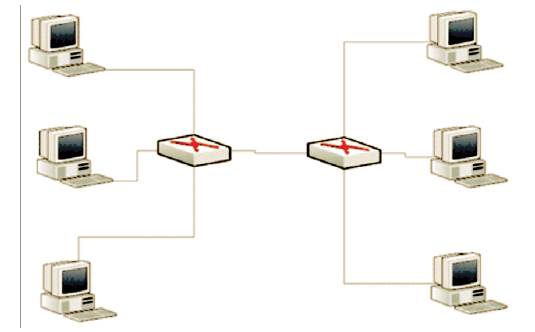
Figure 2. Dumb bell Topology
The results evaluated in this paper are based upon the simulation which is done on NS2- Network Simulator 2. It is a discrete event simulator. In NS2 mainly two languages are used C++ and Object Oriented Tool Command Language (Otcl). In figure 3, OTcl script file ( .tcl) and Traffic Trace File ( .bin) are taken as two inputs in NS2. Two output files are generated after the procedure in NS2 named as Nam trace file (.nam) and ASCII trace file (.tr). Nam trace file is used by Nam animator whereas ASCII trace file is analysed with the help of different scripts as python, pearl, awketc to generate the final results.
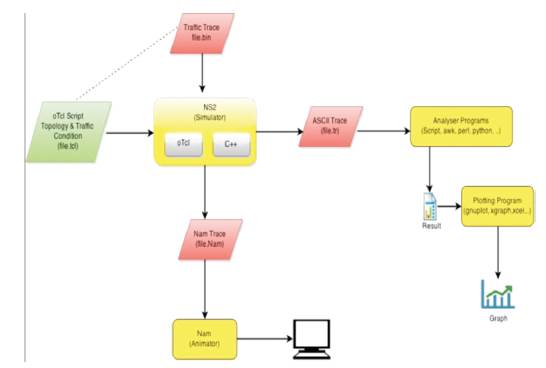
Figure 3. NS2 Architecture
Performance metrics used in our experiments are:
Throughput: It is a measure to calculate the number of successfully transmitted packet from source to destination per unit time. It is the ratio of total number of packets sent over total number of packets received.

Packet loss: It is measure for total number of packets that are discarded or lost while transmitting the data from source to its destination. It is calculated by subtracting the total number of packets received at the receiver side from the total number of packets sent from sender side.
Packet Loss = Total no of packets received - Total no of packets sent
Average packet delay: It is the measure which can be experienced by any packet and given by the formula-

Jitter: It is the variation in latency between the arrival of packets which may occur due to the congestion in the network, time drift or any change in the route.
In Table 1 we have listed all the parameters taken into consideration while performing tests on ns2 simulator.

Table 1. Simulation Methodology
When packet size is varied in NS2, different behavior of the TCP variants was observed for various performance metrics.
Packet Loss: After performing the variation in packet size, it was concluded from Figure 4 that TCP Veno had the best performance by achieving a minimum packet drop rate. Whereas TCP Scalable had the worst performance by having the maximum packet loss.
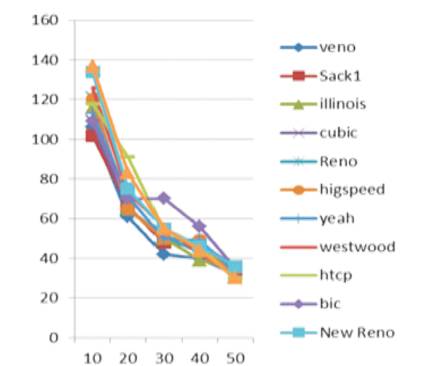
Figure 4. Packet Loss in variable buffer size
Throughput: After performing the variation in packet size, it was concluded from Figure 5 that TCP htcp had the best performance by achieving a maximum throughput rate. Whereas TCP SACK had the worst performance by having a minimum throughput rate.
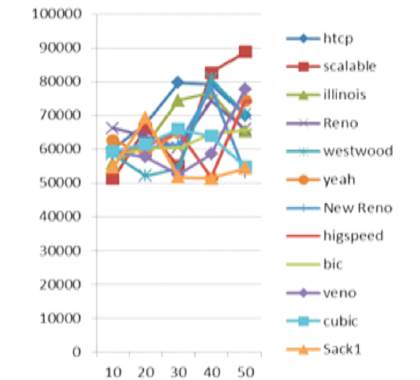
Figure 5. Throughput in variable buffer size
Packet Delay: After performing the variation in packet size, it was concluded from Figure 6 that TCP Cubic had the best performance by achieving a minimum packet delay. Whereas TCP Reno had the worst performance by having the maximum packet delay.
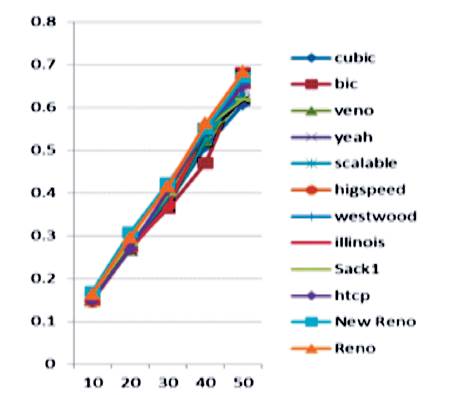
Figure 6. Packet Delay in variable buffer size
When packet size is varied in NS2, different behavior of the TCP variants was observed for various performance metrics.
Packet Loss: After performing the variation in packet size, it was concluded from Figure 7 that TCP Reno had the best performance by achieving a minimum packet drop rate. Whereas TCP Yeah had the worst performance by having the maximum packet Loss.
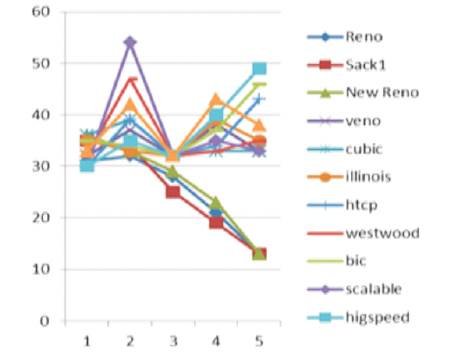
Figure 7. Packet Loss in variable bandwidth
Throughput: After performing the variation in packet size, it was concluded from Figure 8 that TCP Illinois had the best performance by achieving a maximum throughput rate. Whereas TCP New-Reno had the worst performance by having a minimum throughput rate.
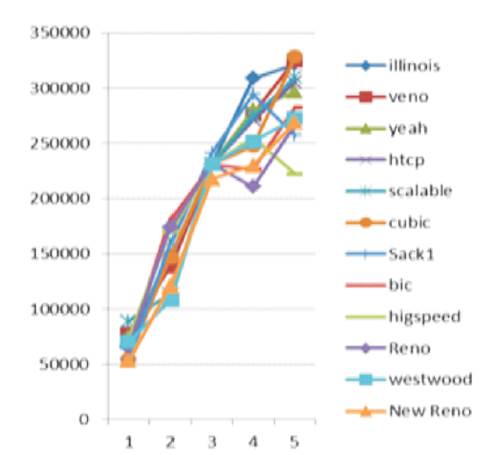
Figure 8. Throughput in Variable Bandwidth
Packet Delay: After performing the variation in packet size, it was concluded from Figure 9 that TCP Veno had the best performance by achieving a minimum packet delay. Whereas TCP Reno had the worst performance by having the maximum packet delay.
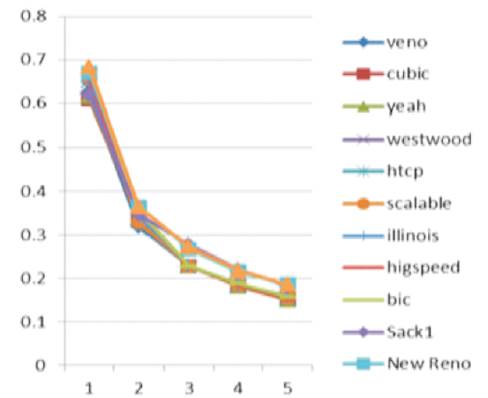
Figure 9. Packet Delay in Variable Bandwidth
Congestion Control is a significant issue in static and mobile networks. The authors have simulated various TCP variants such as Tahoe, Reno, New-Reno, Vegas, SACK etc. Network traffic is provided using FTP - File transfer protocol application. The authors have studied various network parameters such as throughput, jitter, packet drop and packet delay over the dumbbell topology. Although simulation for various parameters on different TCP variants were performed, no single algorithm could overcome congestion due to unpredictable behavior of network. Deciding factors for any TCP variant to be effective or non-effective, were the parameters on which simulation was carried out.
In future this area can be explored to a higher level for the development of a new algorithm for congestion control and avoidance which can handle unpredictable behavior of the network to improve TCP performance.
We hereby, would like to take this opportunity to acknowledge the continuous support and guidance by Mr.Vishal Sharma, Ph.D., Research scholar Thapar University without whose directions and support, not just this work, but our research would not have been possible.