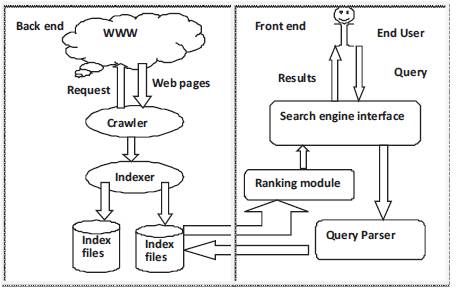
Figure 1. Basic Architecture of Web Search Engine
World Wide Web is growing every day, that people searching for information can be easily lost in the web. People use search engine to find relevant information from the web. So it is very challenging for search engine to find relevant and quality information from the huge collection of hyperlinked data on World Wide Web. This paper gives an introduction of web search engine with its architecture. It also describes web mining techniques and page ranking algorithms in detail. Some very important page ranking algorithms like PageRank algorithm, Weighted Pagerank algorithm and Hyperlink induced topic search (HITS) algorithm are discussed and compared on the basis of various parameters like mining techniques, input parameter, working process, complexity, limitation and search engine using algorithm.
WWW is a huge collection of hyperlinked and heterogeneous information resources, for example: text, images, audios, videos and metadata. As the volume of information on the web is increasing day by day, retrieval of relevant information from the web has become challenging because of some key factors like: Web is vast, Web pages are semi structured, and Information on the web tends to be of diversified meaning, degree of the quality of the information extracted from the web [2, 4]. So it is essential to analyze and understand the underlying data structure of the Web for efficient Information Retrieval. Web mining techniques along with other areas like Natural Language Processing (NLP), Database (DB), Information Retrieval (IR), Machine Learning etc. can be used to solve the challenges. Today majority of the users use information retrieval tools like search engine to find relevant information from the collection of data. Desktop search engine are used to find information from the collection of data from the computer (offline basis), while web search engines are used to retrieve relevant information from the internet. Some most commonly used web search engines are: Google, Yahoo, Bing, MSN etc [2]. All these search engines answer trillions of queries every day.
There are three important components in a web search engine, which are Crawler, Indexer and Ranking mechanism. The Front-end of the search engine contains- search engine interface, query processor, ranking mechanism and in the back-end, it has crawler and indexer. Crawler is also known as a robot, scooter or spider that recursively navigates the web, downloads the documents and identifies new URLs to visit from the previously visited web pages. The downloaded pages are being transferred to an indexing module and then indexer parses the web pages and builds indexes which are based on the keywords in individual pages and store them on index files [4].When an end user types query keywords in search engine interface, the query processors match query keywords with the index and returns the URLs of the pages. Then, finally, ranking mechanism is done by ranking all these returned pages according to chosen relevancy ranking algorithm. Figure.1. shows the working of a typical search engine.
Figure 1. Basic Architecture of Web Search Engine
This paper is organized as follows. Section 1 describes web mining techniques. In this section web structure mining, web content mining and web usage mining are explained. Section 2 explores different types of Page Rank algorithms like PageRank algorithm [8], Weighted PageRank algorithm [6] and Hypertext Induced selection (HITS) [7]. Section 3 compares all Page Rank algorithms and finally the paper is concluded.
Data mining is extracting useful information from the huge collection of data. And web mining is an application of data mining, which is used to crawl through various web resources to collect desired information. In other words, web mining is extracting useful information from the web. Web mining can be divided into three categories namely web structure mining, web content mining and web usage mining [9].
Web structure mining uses the hyperlinked structure of the web documents and generates the structure summary about the web documents in the form of web graph, where web pages are represented as nodes and hyperlinks between web documents which are represented as edges. In this technique, back links and forward links play vital role in the retrieval of the web page.
In this mining technique, information is extracted from the contents of web documents or result pages produced from search engine. The web document may contain text, multimedia (Audio, video, images) or structured records like lists and tables. Web content mining has two types of approaches: agent based approach and database approaches.
In this mining technique, user navigation pattern and the useful information is extracted from the secondary data stored in server like access log, agent log, cookies, user profile data, metadata. All the data is derived from the interactions of the user while surfing on the web.
Ranking module plays a vital role in web search engine. It is used by web search engine for ranking search result. For a user is queries, it determines the order of the return pages in result. The order of the web pages basically depends on Page rank of the pages. Web pages' having high Page Rank comes up in the returned result; it means that web pages are arranged in descending order of their Page Rank in return result for a query by search engine. For this purpose, search engine uses page ranking algorithms. Basically page ranking algorithm are used to present the search result by considering the relevance, importance and content score [2]. Some page ranking algorithms depend upon the hyperlinked structure of the web pages which is a type of web structure mining, and some other page ranking algorithms depend only on the actual content on the web pages known as web content mining, while some page ranking algorithms use the combination of hyperlinked structure and content in the web pages [4]. Some of the most popular page ranking algorithms are discussed below.
The PageRank algorithm was developed by Larry Page and Sergey Brin in 1996 at Stanford University. Page Rank algorithm is based on link analysis which is used by the Google web search engine [8]. Google Search engine is very popular and successful because of its PageRank algorithm. PageRank is a method of measuring a page's "importance." PageRank is a numeric value and it provides a better approach that can compute the importance of the web page by counting the number of web pages that are backlinked. For example: if we have a web page A which links to web page B, then web page A is saying that Web page B is an important page. Pagerank algorithm states that if a web page has some important backlinks to it, then its outgoing links to other web pages also become important [3]. It means backlinks from the important pages play a vital role in the Page Rank of that page (which will be automatically high because of its important backlinks).
Let x be a web page and F(x) is the set of pages that x points to and B(x) is the set of pages that points to page x. Let Nx be the number of the links from page x(outgoing links) and c is a factor of normalization [1]. A simplified version of Page Rank is in “(1)”
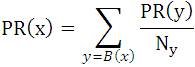
This formula of PageRank is recursive. To compute the PageRank of a page we need to know the PageRank of others. Therefore calculating the PageRanks of pages we started with any random value of PageRank (normally with 1 for all pages in hyperlink structure) and iteratively update these ranks using the above formula and waiting until they converge happens [5]. But there is a small problem with this simplified ranking function. Suppose we have two web pages that point to each other but there are no outgoing links from this loop and there are some web pages which have incoming links to one of them, then during iteration, this loop will accumulate rank but will never distribute any rank, since there are no outgoing links. The loop forms a sort of trap which is known as rank sink [1].To overcome this problem a modification was made on PageRank formula. Modified Page Rank formula is:
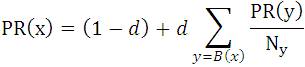
Where d is a damping factor, its value can be set between 0 and 1, we usually set the value of d to 0.85. The damping factor is used to stop the other pages having too much influence because their contribution value on PageRank is damped down by multiplying it by 0.85.
Weighted PageRank Algorithm is proposed by Wenpu Xing and Ali Ghorbani.WPR is the modification of the standard PageRank algorithm. WPR does not divide the page rank value of a page equally among its all outgoing or forward linked pages. But it assigns larger page rank values to more important pages than others. And the importance of a web page is measured by its number of back links and forward links [6]. The importance is assigned in terms of weighted values of the back links Win(m, n) and forward links Wout(m, n).
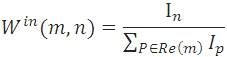
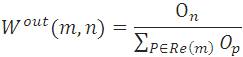
Win(m, n) as shown in “(3)” is the weight of link(m, n) calculated based on the number of incoming or back links of page n and the number of incoming or back links of all the reference pages of page m. Ip and In are the number of incoming links of page n and page p respectively. R(m) denotes the reference page list of page m. Win(m, n) is as shown in equation (4) which is the weight of Link(m, n) calculated based on the number of outgoing or forward links of page n and the number of outgoing or forward links of all reference pages of m. Where On is the number of outgoing links of page n and Op is the number of outgoing links of page p. WPR formula is shown in equation (5),
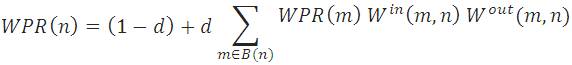
Where d is damping factor, its value can be set between 0 to 1. And B(n) is the set of pages that point to page n. We have four categories of resultant page for a query. Where categorization is based on the resultant page's relevancy to the given query [2].
In 1988 Kleinberg proposed HITS algorithm [7]. He identified two different web pages called hubs and authority. Authority pages are popular and are the ones having relevant information for a given query, while hubs are web pages that contain important links to relevant pages or many authorities. So, a good authority page is pointed by many good hub pages on the same subject, and good hub pages are having links to good authority pages. A web page may be a good hub and authority at the same time. Figure. 2 is illustrating hub and authority relationship. The HITS algorithm treats hyperlinked structure of WWW as a directed graph G (V, E), where V is a set of vertices representing web pages and E is the set of edges that representing links between pages. The HITS algorithm works in two major steps. First step is sampling and second step is Iterative. In sampling step Hub and Authority weight is calculated using the following equations (6 and 7)".
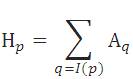
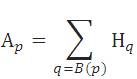
Where Hp is the hub weight and Ap is authority weight. I(p) and B(p) are the set of the reference and referrer pages of the web page p. In iterative step, the output of the sampling step is used to find Hubs and Authorities. The page's authority weight (Ap ) is proportional to the sum of the hub weights (Hq1 , Hq2 etc) of pages that it points to it, Kleinberg [7]. Similarly, a page's hub weight (Hq ) is proportional to the sum of the authority weights (Ap1 , Ap2 , Ap3 ) of pages that it points to. HITS algorithm is used by 'Clever' a prototype search engine for IBM research project’. But HITS could not be implemented in real time search engine because of the topic drift and some efficiency issues [7].
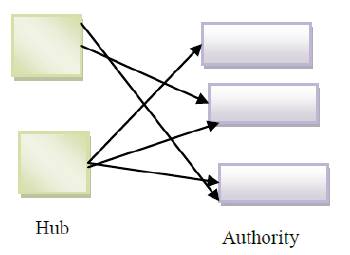
Figure 2. Hubs and Authority
Based on the analysis, a comparison of the PageRank algorithm, WPR and HITS algorithm is shown in Table 1.
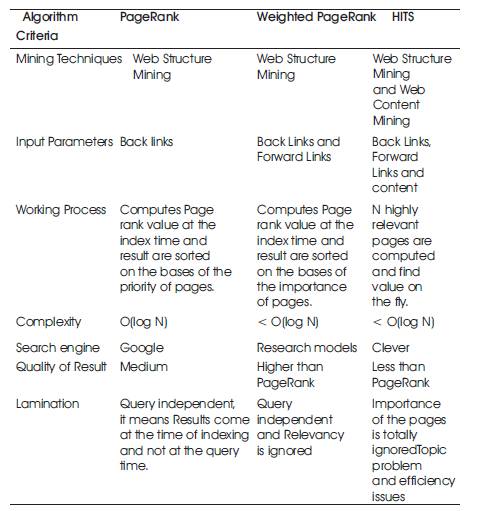
Table 1. Comparison between Ranking Algorithms
Comparison is done on the basis of various parameters like mining techniques, input parameter, working process, complexity, limitation and search engine using algorithm. PageRank and HITS are the most important algorithms among all the algorithms. PageRank algorithm is used by Google Search engine and HITS algorithm is used in the prototype search engine 'Clever' of IBM.
The Page ranking Algorithm plays a vital role in the ranking mechanism of search engine. It determines the order of the return result for a query. This paper describes that PageRank algorithm and WPR only depends on the hyperlinked structure of the web, while HITS algorithm stresses on the content of the page as well as the hyperlinked structure of the web. A typical search engine may deploy a particular Page Ranking algorithm according to the user needs. In order to improve the search result, a ranking algorithm should be developed by equally considering the importance and relevancy of a page.