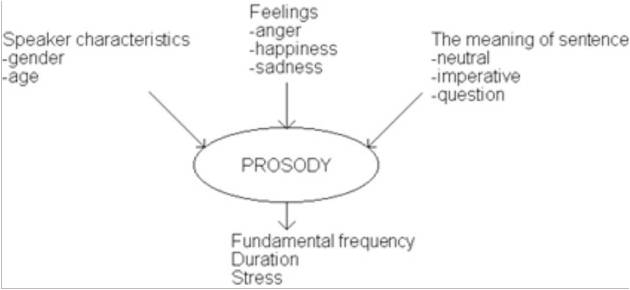
Figure 1. Prosodic dependencies
The process by which the authors try to reconstruct or regenerate a voice sample from a source sample or try to modify a source voice to a desirable voice, the authors call it as Synthetic Voice Generation or Artificial Voice or Voice Conversion. The basic and conventional remedy to this issue are based on training and applying conversion functions which generally require a suitable amount of pre-stored training data from both the source and the target speaker. The paper deals with a very crucial issue of achieving the required prosody, timber and some other unique voice templates by considerably reducing the dependence on the sample training data set of voice. The authors needed to find out a way by which the authors can have templates of the “to be achieved voice” which are nearly same parametrically. This is achieved by assigning a marker to the target voice sample for training .A proper estimation of the transformation function can be made possible only by the above mentioned data. We can get the process done by pre existing methods. In nut shell what the authors proposed is that a system by which in the scarce availability of training data set also we can reach to a considerable amount of closeness of the target voice. Even though there is a disadvantage that to have higher precision and closer resemblance the authors need to have clear idea of the system of spelling that a language uses.
While considering the synonymous words like voice, sound, speech, noise or music all correspond to the human's eternal instinct to perceive something by “LISTENING”. Out of all the varieties of mechanical waveform widely available in the nature, the most intriguing is human voice. Un-denying the fact that sound waveforms as compared to other sources of perception are equally important, but it's the complexity and the dynamically varying nature of the human voice that fascinates us the most. The moment the authors start talking about voice or speech the developments that are associated with this arena which dawns in our thoughts are speech synthesis and recognition, voice commands and interactive voice response and many more.
In the light of artificial intelligence where much of the effort that has been invested is in creating intelligence part for the robots for its articulation in movements, prediction abilities, computer vision, pattern recognition or even artificial thoughts, very less has been endeavored for artificial voice. Now these are the aspects to name a few of them. For the time being it's the sheer human ingenuity and the basic transcendental quest to achieve the other utilities of speech or voice synthesis.
The initial step may be regarded as the pre requisite step where the most unique features of both the source as well as the target dataset is traced and this phase is called the Analysis step. The values achieved are basically the parameters associated with the speaker identity like pitch, prosody and formant frequencies and a few more.
In the second step the authors try to map the features computed in the previous step of that of the source voice to that of the “to be achieved voice” to as close a proximity as possible. This phase is controlled by a conversion rule obtained by a training phase.
Synthesis: Last but not the least is the final phase where the modified parameters are used to synthesis or reconstruct the new speech which generally does have the target voice as well as the required prosody too if the module assists.
The researches on the crux topics of voice and speech is basically revolving around the paradoxical axis of speech or voice synthesis with application areas in the form of text to voice and vice versa with stress on characterization and bifurcation of two or more voice samples. Some of the broad application areas are as enumerated.
Unnatural or synthetic or artificial speech has been developed steadily over the last decades. Especially, the intelligibility has attained an adequate level for most of the user defined applications, viz for communication impaired people. The intelligibility of artificial speech may also be enhanced considerably with visual information. Speech synthesis may be classified as restricted in the form of messaging and at times unrestricted when it is text to- speech processing. The first one is suitable for announcing and information systems while the latter is needed for example in applications for the visually impaired. [2] In the sections to follow we are going to exemplify some of the topics.
The basic problematic area encountered by any TTS system is the conversion of input text into linguistic representation, which is generally known as text-to phonetic or grapheme-to-phoneme conversion. Another aspect to be noted is that every single language has got its own unique way of conversion and this leads to tremendous increment in the complexity level. In some languages, such as Finnish, the conversion is easier as written text almost corresponds to its pronunciation, where as for English and most of the other languages the conversion is much more complicated. A correct pronunciation and prosodic flow is the outcome of strict coherence to a colossal amount of language axioms and rules. The correctness does not only depend on these facts and rules rather a huge set of exceptions too. The process basically begins with the preprocessing of the text to be converted and then an in-depth analysis of the data for a unique and correct pronunciation. The last step involves the proper computation of the prosodic features. A few of the important steps have been discussed here.
The first step i.e. text preprocessing can be understood about its difficulty level from the following example where let's say any English numeral 121 may be at first read as one hundred and twenty one and 2014 as twenty fourteen if inferred as year or two thousand and fourteen for quantizing something for measurement. Some of the similar cases are the distinction between the any numeral and then stating pilot or people. The final area is the fractions and dates which are equally troublesome. 4/14 can be expanded as four-fourteenths (if fraction) or April Fourteenth (if date). The above mentioned problems are amongst a few of the problems encountered and the corresponding solution.
The next important task is to find correct pronunciation for different relevant areas in the text. There are certain types of words that bear a same spelling but have different meaning and sometimes different pronunciations also which are called homographs. Now these type of words are a big obstacle for the overall module. While considering an English word lead we generally can end up with different pronunciations depending on its utility as a verb or noun, and between two noun senses. With all these kinds of words some semantically helpful as well as informative data is highly essential to achieve correct pronunciation.
The rhetorical flow of any word or its segment will definitely consider the correct intonation, proper stress at the punctuations and duration from written text is probably the most challenging problem for years to come. All these features when cumulatively considered are called prosodic features and may be considered as a melody stream, rhythmic flow and stress of the speech at the perceptual state. When the fundamental frequency are also at times the same, the varying patterns in the pitch varies during the whole voiced segment of speech and then it may be regarded as a particular intonation. The basic meaning of the uttered phrase and the emotional state of the speaker are some of the deciding factors for the prosodic characteristics. The dependencies of prosodic variations are shown in Figure 1. The ironic situation is that any information in written or textual format doesn't carry the traits of these qualities[2].
Figure 1. Prosodic dependencies
The forthcoming segments will deal with the idea of reconstructing of human voice. Our basic aim will be to learn the voice of an existing voice sample, and then try to convert any given sound signal input, into that particular voice. For this we have reviewed some of the most recent work which emphasizes the most popular ways of voice reconstruction. In this regard hence forth we will be enlisting an analysis part of the related work study and then we will propose our work.
This idea consists of two voices, one is the source voice and other one is target voice. The first sample ie the target voice is the one in which the authors try to observe the required input. The source voice is the sample which contains the information that we need to have reconstructed[1].
This methods implementation consists of three major stages-filter analysis, voice de filtering and voice conversion. The broad outline of each of these methods is as follows. In the first stage, the authors use Machine Learning techniques such as minimizing the mean squared error, the components unique to any voice of human, subsequently this is what the authors refer to as the human voice filter. In the second stage, the authors use speech signal processing techniques like Z-transform to get the segment of the speech from the given speech signal, by de filtering the unique voice content of the particular human voice. In the third and final stage, we now pass this de filtered voice into the human voice filter of the target voice, and obtain the final speech in the target voice[1].
A rough idea of this is given in the form of a block diagram. In Figure. 2, the central block is the filter V[z] which is a discrete time filter that models the human voice, and the filter Gu[Z] refers to the discrete time input which saves the words and other sounds in speech in some form. The output S[Z] consists of the exact speech samples recorded by us.
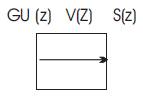
Figure 2. Voice reconstruction Linear Regression Techniques
The next basic idea is that of auto-regression on stationary time-frames where auto-regression is customized to the properties of the time-frame we consider. This is explained below. Auto-regressive techniques for Voice Conversion basically consists of three stages. At stage 1 the authors implement the Dynamic Time Warping, the second stage concentrates on K-Means clustering which emphasizes the fact that sound samples are stationary for relatively small time frames. This is justified by the fact that for small time frames, which are generally of 10ms, the sound varies very less. Each of the frames would have auto-regressive techniques performed on them[4].
Stage three is Auto-Regression for time-frame where we use the auto-regression means on relatively stationary frames. Auto-regression process proposes that output samples are dependent on a few previous output and input samples. This uses a feedback from output to determine the future output samples[9].
Stage four and five consists of Training phase and testing phase respectively where in the training phase the authors will perform clustering and will obtain coefficients where as in the testing phase the authors will start once the source speaker's voice sample is obtained. Then the authors will first split it into stationary time samples, as in the training phase. These stationary time samples, initially in our testing phase, are then detected to be part of a cluster, among the set of clusters obtained in the training phase. The output in the next stage is achieved by use of the cluster obtained. The second stage consists of predicting the output frame given the cluster and the input frame. Once the cluster has been obtained, the authors pull out the coefficients corresponding to the cluster, and use it to linearly generate the samples which mimic the output[4].
The study says that in this approach static voice conversion is basically taken care of. Static speech parameters are the parameters which cannot be changed by the speaker even on his willingness such as vocal tract structure modification, inherent natural pitch of speech etc[5]. It has got a very high utility in the multimedia application industry as it responds to the need for efficient storage of data. The quantitative analysis of the algorithm is dependent on the Quality factor (Q) and The Resemblance factor (R). The parameters are applied for diversified sample of voice.
The PSOLA algorithm assesses these indexes on the pitch for scaling down of each unique signal
After analyzing a variety of approaches like Linear Transformations, Z-Transforms and the Continuous Probabilistic Transformation we arrived to a conclusion that all these methods take an assumption which is existence of good amount training data from both the source and the target speakers[7]. The expectation of a parallel date so as to have a training data set consisting of the same textual segment spoken by both the source as well as the target speaker arises due to the application of least squared error estimation method.
Basically, a voice reconstruction module includes two parts, the initial training phase and the conversion process. In the first step of training procedure, the voice data from both the sources database of training set are parameterized and finally a function for conversion is generated to quire the similarity between the two. Any new speech can be transformed to a target voice segment on the basis of the trained transformation function available. There are certain pressing requirements like the fact that the conversion function be almost lossless speaker transformation with very less noise, distortions and continuity snags in the modeled voice or speech. The above process may depend on a variety of factors but out of all of them abundance of training data for conversion function estimation is the most important one.[8]
In most of the times the requirement for parallel training data can be fulfilled but there are arenas and applications which require voice modification for previously unknown voice data. Some of the prominent utility may be correction in the prosodic as well as the utterance correctness. The second utility may be reconstruction of voice for impaired speakers and also for anonymity of the speaker over phone. [11] Our model is basically an extension and modification of the previous conventional approaches comprising of linear transformations. These transformations are also trained by the use of least square error methodology. A conventional recognizer on a HMM model may be utilized in the database where the target voice sample is to be kept parallel to the recognizer itself. The fresh arriving voice segment is marked in tandem to reach and retrieve the expected segments which can be mapped with the arriving voice. This process leads to the proper evaluation of the transformation functions.
Since the authors are considering the case where a constrained training dataset is available hence we need to find out the way to have the parameters for conversion. These parameters which are the transformation functions are now left to be retrieved from only one source and it is the source voice segment only. While doing so, the problem simplifies to that of tracing one or more frames of the target voice sample to amalgamate with subsequent voice sample of the unknown source. In the proposed system, the above task is accomplished by using a speech recognizer to index the target training voice data so that each new voice source can be used to retrieve similar frames from the target voice database. Much can be done on the speech recognizer part as this is at its primitive state. Thus retrieved voice samples may be used to predict the conversion functions by conventional methods[12].
The step by step procedure or flowchart is as follows. Before the voice conversion of any fresh segment the available training data is managed in a database:
The unit selection step as mentioned above is one of the most important steps. To achieve a guaranteed process that the continuous spectral evolution of the source is implemented on the transformed speech, it is essential to choose continuous target segments wherever applicable and possible. A constraint that helps achieve the longest matching state segments has been utilised. To explain and illustrate how this algorithm or process works let us consider the sequence of source state ids “1223445556”, subsequently upon close examination we can find that the longest matching series in the target database is “12234” then the target spectral vectors corresponding to this subsequence are also extracted. This procedure then gets repeated with an expectation for a match for “5556” and hence forth until the total source sequence is symmetric. A concatenation process is initiated to get the final target vectors supplement the source one.
At this point it may be noted that the number of similar or parallel vectors which can be extracted from the voiced sounds in one utterance is generally not sufficient to train a robust transformation matrix. Hence, it is the training data which is to be changed. By definition of the least squares criterion, the estimated matrix does provide, upto certain extent at least, a sufficient transformation of the training data. By using only the target vectors the output voice becomes machine like hence global transformations are better comparatively. The above issue may be addressed by transformation as the fresh vectors avoid discontinuities as they are already embedded in the source voice.
While dealing with the Unit selection for training approach the authors thought of modifying the process and make it more convenient by adopting the Genetic Algorithm approach. Before we move on to principle of association of GA we would have a very brief overview of the actual GA and its requirements. Genetic algorithm has the following two requirements:
The basic different phases of genetic algorithms are:
Some of the common termination conditions are:
Now while choosing the continuous target segments wherever possible there may be certain GA based approaches for the same. While doing so the authors need to provide the basic ways of chromosome crossover and mutation. As a process what the authors generally do is while crossover, keep the initial 8 bits constants for both the parents. Then in the next 8 bits, apply the encoding. The authors have even enlisted certain modified encoding schemes in the next section.
The basic genetic algorithms encoding techniques are Binary encoding, Permutation encoding and Value encoding. The authors have listed some relevant examples for each of the cases. What the authors want to do is to change the way of encoding which might be customized according to the need in the continuous spectral evolution of the source to precisely trace the matching series. The below mentioned examples are just to show how those modifications may be shown.

To formulate a Genetic Algorithm (GA) approach we can now conclude that the encoding cross over simulating plays the most important role. To list out the operators that impact it are:
Now considering the fact that the major advantage of using GA is that they are broadly applicable and require little knowledge encoded in the system. However because of being knowledge poor approaches, GA's fail to give satisfactory results and performance in some specific problems. Now our approach is to formulate a plan to remove this disadvantage due to knowledge poor condition by adopting the following approaches:
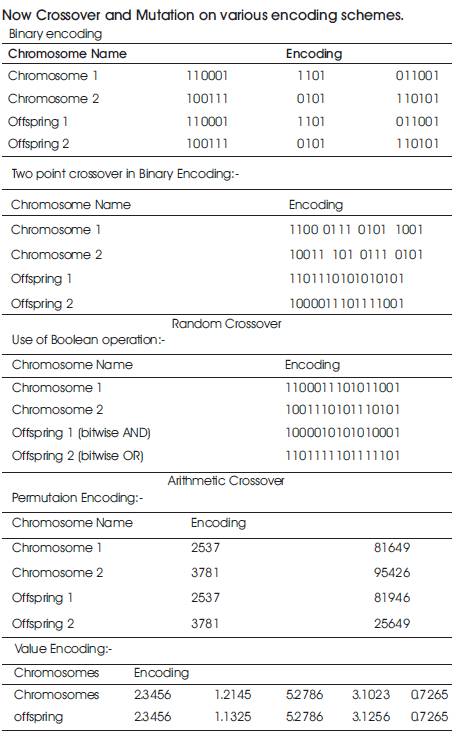
Now Crossover and Mutation on various encoding schemes.
In our case the advantage is achieved by having a single global linear transform, but this use may lead averaging problem which may be avoided by having transforms in multiple numbers. By doing so the authors also have a better formant.
When there is fresh incoming voice then the use of interpolation method is the best way to have transforms of multiple nature. [8] This is implemented in two phases, firstly the process of conversion of the source vectors are done by the use of a single global transform. Secondly the target components of the Gaussian Mixture Model's occurrence are computed and the posterior probabilities are then used as the interpolation weights.
Subsequently the multiple transform parameterizations can be done in the same way like conventional one. The constrained training data set initiates the practical problem acting as an hindrance to make out an estimate of the multiple transforms. But this data is just sufficient to train a single dimensional linear transform matrix but not more than that. The authors will try to solve this problem by applying a more aggressive unit selection approach whereby each segment of the source voice is matched with many voice samples of the target database. To be more precise, the unit selection process is performed repeatedly until enough vectors for ex 300 number of GMM components have been extracted from the target database. At the end it can be inferred that the occurrence of the vector source is relatively high in the training set.
While starting with the endeavor we decided to map the unique template of the “to be generated” voice segments for a singing tone but instead of that we tried to first critically analyze the prospect of reconstructing the basic phonetics. Hence in this work the authors have tried to formulate and propose a method of converting the speech of a source voice. Many a times it may be from unknown speaker to sound like that of some pre assigned target voice sample. The output may be further enhanced for better prosodic and formant structure. Lastly the prosodic and formant structure must be at par with the spectral transformation and this is very precisely another area needing endeavor.