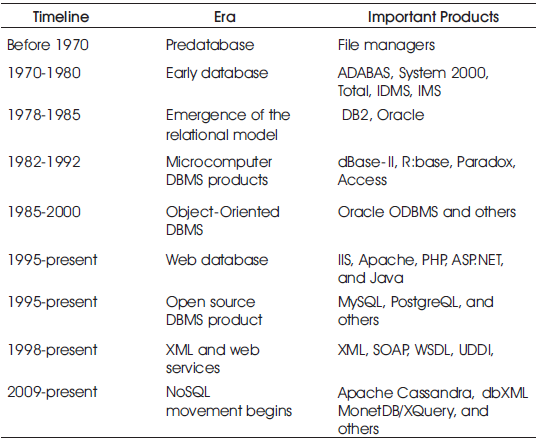
Table 1. Eras in the Timeline of Database Technology Development [5].
In-memory computing has changed the landscape of database technology. Within the database and technology field, advancements occur over the course of time that has had the capacity to transform some fundamental tenants of the technology and how it is applied. The concept of Database Management Systems (DBMS) was realized in industry during the 1960s, allowing users and developers to use a navigational model to access the data stored by the computers of that day as they grew in speed and capability. This manuscript specifically examines the SAPHigh Performance Analytics Appliance(HANA) approach, which is one of the commonly used technologies today. Additionally, this manuscript provides the analysis of the first two of the four common main usecases to utilize SAP HANA's in-memory computing database technology. The performance benefits are important factors for DB calculations. Some of the benefits are quantified and demonstrated by the defined sets of data.
The concept of a Relational Database Management system (RDBMS) came to the fore in the 1970s. This concept was first advanced by Edgar F. Codd in his paper on database construction theory, “A Relational Model of Data for Large Shared Data Banks”. The concept of a database table was formed where records of a fixed length would be stored and relations between the tables maintained [1].
The mathematics at the heart of the concept is now known as tuple calculus [2]. The variation on relational algebra served as the basis for a declarative database query language, which in turn formed the basis for the Structured Query Language (SQL). SQL remains as the standard database query language some 30 years later.
Database technology, specifically Relational Database Technology (RDBMS), has seen incremental advancements over recent decades but the competition has narrowed to a few remaining larger entities. The pursuit for improvement has largely left technology practitioners, especially the database administrators, focused on the benefits of performance tuning of the database technology. The infrastructure teams have relied on benefits of the potential compression factors from various RDBMS offerings to help quell the ever expanding footprint of structured and unstructured data that fills the capacity of the typical data center.
As a result, infrastructure teams continually seek hardware refreshes with promises of faster disk performance and improved memory caching to gain new database performance tools. Ultimately,a database administrator is left with only a few tools to improve database performance such as adding and tuning database indexes, which only add to the amount of space required for the database. In the end, the data of concern becomes secondary too and can even become smaller than the indexes themselves, leaving the technology practitioners faced with a diminishing rate of return from their efforts. Technology can only go so far and the physics of spinning disks is reached eventually with the associated costs of competing methods to store, retrieve and query data.
Today, IT professionals are challenged with the task of on going improvements to achieve goals of businesses. Unfortunately, IT budgets do not dynamically grow as fast as business needs. That sequence of events creates majors obstacles for DB infrastructure, deployment, administration and maintenance.
Frequently, IT is not seen as a valuable partner in meeting the objectives of the business and IT is not characterized as the means by which a business can create new opportunities and grow. More difficult times lead to further budget tightening and reductions in the needed hardware refreshes. All of these factors leave no time for innovation, creativity and the lack of budget for evaluating the latest new technology.
The reality is a declining benefit of investment into physical disks. The apparent limitation in the physics of spinning disks leads to questioning previous systems and development paradigms. With the continued need for deeper, mobile and real-time access to all of the companies' data calls for innovative solutions.
Emerging technology in the area of in-memory computing and products like SAP HANA are changing the database technology arena and the analytics field and the overall system architectures [3]. These database advancements can bring improvements in the timeliness of access to data and can enable improved decision making and enable transformation of business processes to make use of this new capability.
In order to proceed with the subject at hand, an overview of Relational Database Management System (RDBMS) advancements is needed.
The database technology field dates to the 1960s, with the introduction of the Integrated Data Store by Charles Bachman [4]. Prior to 1970 the relational database was conceptual and data was stored in separate files stored on magnetic tape [5]. Memory was expensive, while storage was relatively inexpensive and the Moore's law was a maturing concept without its full validity or its temporal limitations [6].
The proceeding decades of database history can be tabulated into nine distinct eras. In viewing this data alone a slowing trend of advancements can be seen since the mid-1990s. Table 1 outlines the 9 eras.
Table 1. Eras in the Timeline of Database Technology Development [5].
Through the proceeding decades of database history and computer science theory specifically, Moore's law has proven itself and the linear nature of the number of components in integrated circuits has doubled at a predictable pace. The linear nature of this relationship as it applies to Central Processing Unit (CPU) performance and CPU cost has begun to change very recently. CPU performance improvement has begun to slow and clock rates have remained nearly steady for several years. Meanwhile the cost of these components continues to decline substantially. Furthermore, the cost of memory has also declined substantially. During this same time physical disks have seemed to reach a performance plateau and not offered the same declining cost and improving performance relationship as CPU and RAM have demonstrated.
These changes have enabled hardware advancements including more cores and more CPUs on a given server and far more RAM is now feasible [7]. RAM costs have also changed such that it is less necessary to limit the amount of RAM and use it only for caching of critical processes. Instead, RAM can now go toe-to-toe with fixed disk for storage and also combine with the CPU to provide a tremendous performance differential as compared to disk-based systems and databases [8]. When compared with disk, the physics of spinning platters and their resulting database, read and write characteristics are best measured in milliseconds. RAM arrives without those physical limitations and delivers nanosecond response times [9]. Increasing RAM is one possibility -one must begin to think in terms of terabytes of RAM and no longer gigabytes of RAM, in much the same way computer science has moved beyond kilobytes and bytes of RAM quite some time ago. According to IBM, some applications simply cannot run without in-memory computing even with high-data volumes [10].
In-memory computing does dramatically change the landscape of the database technology [11]. In-memory computing involves the use of main memory not as a cache of memory but instead as a means of storage, retrieval and computational performance in close proximity to the Central Processing Unit (CPU). The use of row and columnar storage of data creates the ability to remove the need for the index which is predominating in the disk-based database world. The lack of the index is a key area of compression and columnar storage allows further compression.
According to IBM and as Shown in Figure 1, “the main memory (RAM) is the fastest storage type that can hold a significant amount of data” [10].
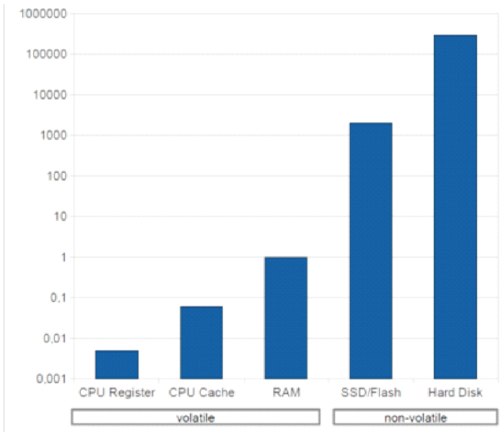
Figure 1. Data Access Times of Various Storage Types, Relative to RAM (logarithmic scale)
These advancements arrive at a time when RDBMS advancements have increased and the typical IT infrastructure is faced with the declining budgets and the expectations of improving performance results; all at the same time. If a hardware refresh is being planned, Linux-based solutions and in-memory database solutions are increasingly becoming part of the reference architecture. At a minimum, the question of in-memory computing is now being asked as part of architecture planning for infrastructure updates. These technologies are increasingly being accepted as proven and ready for long-term capital investment.
The problem of data growth and the impact it has on run-times and data accessibility is faced by system administrators, programmers and functional analysts. Due to the data growth, a program, system process that used to run each day, can now run once a week. Another problem is the runtime of a report which creates the need for a developer to reduce the user's ability to ask questions of the data, limiting its selection criteria. These problems may also impact system administrators as they are asked to add database indexes to improve the programs performance.
Data growth is viewed as the largest datacenter infrastructure challenge based on Gartner research [12]. Survey data indicated business continuity and data availability were the most critical, followed by cost containment initiatives and maintained or improving user service levels was the third most important factor for data center planning and strategy development [12].
Another way to view the large data analytics is analyze three characteristics of big data – volume, velocity and variety [13].
The hardware specifications are two-servers which were configured to act as one database. When combined the system has eight (8) Westmere EX Intel E7-8870, ten (10) core CPUs (80 cores) with a 2.4 GHz clock rate. The system has two (2) SSD (Solid-State Drives) Fusion-IO drives with 640GB of capacity each for database log volumes. The system has sixteen (16) 600GB 10,000 RPM SAS drives in a RAID-5 configuration for persistence of the data volume in addition to its storage and calculation on sixteen (16) 64GB DDR3 RDIMM.
It has been established that the emerging technology in the area of in-memory computing is making promising advancements and the technology is being applied in ways that were not previously anticipated. According to IBM, SAP High Performance Analytics Appliance (HANA) “enables marketers to analyze and segment their customers in ways that were impossible to realize without the use of in-memory technology” [10]. Some applications are not available without in-memory technology [10].
Unique application of this emerging technology has been applied within healthcare field, for personalized patient treatment planning in real-time, to greatly accelerated cancer screenings and human genome analysis. Out of the box thinking is needed to explore and find the limits of these new technologies [14].
These four use-case areas for SAP HANA are [15]
When compared to a disk-based database, the in-memory database yields far faster read-rate response times [10], when comparing disk-based technologies the measurements are in milliseconds while in-memory databases are measured in nanoseconds. The unit of measure shift alone is a matter of calculation and not the result of a test to outline the significant change from measurement in 1/1,000 (one one-thousanth) of a second to 1/1,000,000,000 (one one-billitionth) of a second.
The results were quantified and the system was measured in terms of the aggregation levels of a given report. Typically, a report is severely constrained in selection criteria to aide runtime performance, effectively removing scope from the user's ability to query the data. Another measurement will be in terms of data compression. The source database tables were measured for index and data size and the compression of the data size calculated. As the data is stored in columnar form, the need for the index is removed. Finally, measurements in preparing the data for query including runtime of all background jobs, extracts, transformations, loads, aggregation and index in addition to query time will be compared to the replicated data and its query response time using the in-memory database.
The first of two use-cases accelerated a complex table-set and performed an analytics use-case demonstrating the real-time nature of the data access, the improved response time and the data compression characteristics of an in-memory database. The second use-case utilized the improved read-rate performance to accelerate an existing table-set and performed a database call from an existing program with the table-set residing on SAP HANA, instead of directing the database call to the disk-based database.
The hardware utilized was from one of several hardware vendors partnering with SAP to provide hardware capable of utilizing SAP HANA as an in-memory computing engine.
As discussed previously, disk-based hardware advancements have slowed, the cost of various system components have fundamentally changed and the user base along with the system administrator is faced with an ever increasing growth of data size and along with increasingly complex data with the result being slower and slower system performance.
The first of two use-cases accelerated a complex table-set and performed an analytics use-case demonstrating the real-time nature of the data access, the improved response time and the data compression characteristics of an in-memory database.
In this first use-case the SAP HANA appliance hardware was installed and configured and the necessary replication of the SAP ERP source tables was established. The initial load of data took as much as 120 hours due to CPU and RAM restrictions on an intermediate server. Additional tuning and increased allocation of CPU and RAM on that intermediate server allowed subsequent loads to be completed on the same dataset in less than fourteen hours.
With this real-time replication established and these initial one-time loads, these datasets are now continually updated as the source database is changed, in real-time.
After some data modeling of these tables and development of a set of reports, query of the dataset using the SAP HANA in-memory platform was tested. Previously, the dataset was accessible as a static result running each night. As is typical the dataset grew and as such run-time began to exceed the daily iteration of assembling the data for analysis. With the data now only accessible weekly, a user had less access to the necessary data to run the business. The combination of background programs and data extracts to an external data warehouse system combined for a total processing time of 1,131 minutes or 18.9 hours. The data set was comprised of approximately 40 tables, the largest of which was over 700 Million rows in size.
As indicated by Figure 2, the prior dataset contained aggregations limiting the analysis scope. The user having limited access to the data as constraints were placed on the selection criteria in order to aid run-time performance. Using SAP HANA these constraints are removed and the user can now query the full dataset range.
As for data compression, the data set of approximately 40 tables on the disk-based database utilized 765 GB of total space and more than half of this space was attributed to index space (428.2 GB) while the data space accounted for only 336.3 GB. The 336.3 GB replicated to HANA now accounts for 108.2 GB of compressed data in memory. The index space is not replicated to SAP HANA as the indexes are not necessary for the in-memory database.
As noted by Figure 2, the total processing time of 1,131 minutes or 18.9 hours, which is the combination of background programs and data extracts to an external data warehouse system including the query response of the static report is now compared to the response time of less than 1 minute for the dynamic report. The dynamic report is now available in real-time, all day, every day and the user no longer has to wait each week to receive an aggregated, static report. This is a significant advantage over the previous approaches that did not utilize in-memory technology.
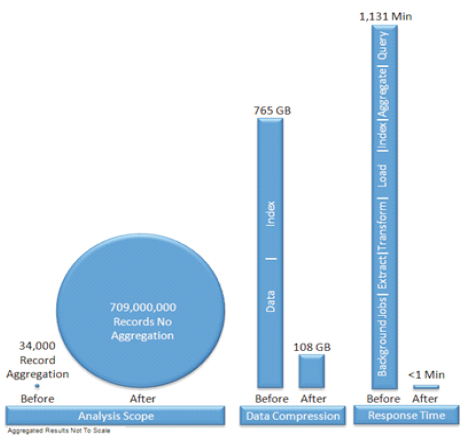
Figure 2. Comparison of Changes in Aggregation Level, Data Compression and Data Processing
The second use-case utilized the improved read-rate performance to accelerate an existing table-set and performed a database call from an existing program with the table-set residing on SAP HANA instead of directing the database call to the disk-based database.
The secondary database connection to SAP HANA facilitated an accelerated read from existing standard and customized code. The accelerated read-rate performance yielded significant improvements even on unoptimized code.
As specified, the system had two (2) SSD Fusion-IO drives with 640GB of capacity each for database log volumes and sixteen (16) 600GB 10,000 RPM SAS drives in a RAID-5 configuration for persistence of the data volume in addition to its storage and calculation on sixteen (16) 64GB DDR3 RDIMM. Support for a Storage Area Network (SAN) is not required as on-device persistence is part of the solution; other back-up solutions are supported.
Table 2 presents the data compression summarized. Dependent on the cardinality of the table, the data compression for a given table ranged from <1x compression to near 6x compression; overall this data set compressed 3x. When comparing the compressed data set in-memory to the data set including indexes on the traditional database the data compression for a given table may range from <1x compression to over 13x compression, overall this data set compressed 7x.
As outlined by Figure 3, the unoptimized code calling the traditional database had a run-time of 291 seconds. The same unoptimized code calling the same table set replicated on SAP HANA had a run-time of 22 seconds. The difference represented a 13x improvement in the run-time of the sample program tested. Identifying unoptimized code and mitigation of the unoptimized code further improved the run-time on the traditional database to 12 seconds, an improvement of 24x versus the baseline. The now optimized code calling SAP HANA now has a run time performance of .67 seconds, an improvement of 434x versus the baseline.
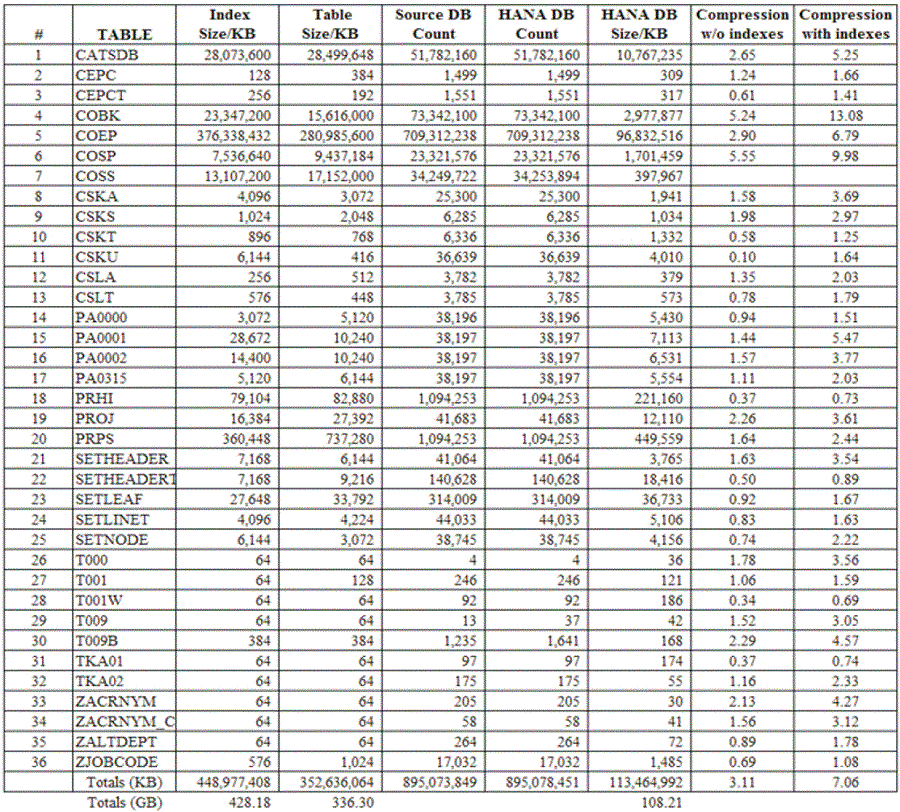
Table 2. Comparison of Data Compression by Table with and without Indexes
In-memory computing is making promising advancements and the technology is being applied in ways that were not previously anticipated. The findings of this manuscript support and outline the performance results on two specific data sets within the context of two of the four primary use-cases for SAP HANA.
This manuscript's limitations included testing only one type of software by SAP - High Performance Analytics Appliance (HANA). Additionally, the factors such as loss of data and the risks and costs associated with the SAP HANA technology were beyond the scope of this study. Hence the following recommendations can be made for future research
This manuscript addressed only certain use cases of the SAP HANA technologies.
The first use-case outlined the ability to take untimely access to static data sets and enable real-time access to dynamic data sets. The change in analysis scope and timeliness in access to data can enable improved decision making and enable transformation of business processes to make use of this new capability.
The second use-case outlined the ability to access the SAP HANA database through a secondary database connection, and utilizing existing SAP ERP ABAP code to access replicated tables in the in-memory database. The program can yield significant improvements in run-time even on unoptimized code.
As the traditional disk-based architecture data footprint grows at over 36% per year [16], innovations such as in-memory computing are increasing in adoption rate and organizations adopting this technology are also gaining a competitive business advantage [10].
When hardware refreshes are planned, SAP HANA and Linux based operational systems require a thorough review for integration into the architecture and where business requirements demand dynamic access to increasing complex data sets in real-time. Real-time terminology is the key in understanding the benefits of in-memory computing. Some applications and techniques would not be even possible without in-memory technologies [10].
“In May 2011, the market research firm IDC released its Digital Universe report estimating data growth. The IDC researchers estimated that stored data grew by 62 percent or 800,000 petabytes in 2010. By the end of 2011, 1.2 zettabytes (ZB) of information will be held in computer storage systems, according to IDC.
And that is only the beginning of the story. By 2020, data will have grown another 44-fold. Only 25 percent of that data will be original. The rest will be copies [17]. In a survey of 237 respondents from a broad range of organizations 12% indicated they had installed an in-memory database in the last 5 years, 27% between 2 and 5 years ago, 24% between 1-2 years ago, 15% within the last 6 months to 1 year ago and 22% within the last 6 months. The data indicates the technology has had some attention for nearly 5 years, and while it is still maturing to its potential it is certainly a technology worth further consideration whether it has been evaluated previously or not.
Adding to the problem of exploding data is the new reality of a declining benefit of investment on physical disks and an apparent limitation in the physics of spinning disks. With the continued need for real-time mobile access to all of a companies' data, this convergence technology is creating the demand for innovative solutions such as in-memory computing.