In today's intensely competitive environment organizations must secure a high customer satisfaction in order to survive. This requires identifying customers and properly understanding their needs. However, targeting the customer is not that easy as the businesses have massive data and this requires properly analyzing and dealing with data. Moreover, old forecasting method appears to have no obvious advantage, and no longer adaptable for any business condition. Data mining is a powerful technique which can serve the purpose. Data mining is automated extraction of data from large databases. Data mining offers several techniques such as attribute relevance analysis, decision tree, clustering, prediction, etc for the task and thus to this end, this paper suggests the use of data mining techniques of attribute relevance analysis and decision tree for prediction.
The aim of marketing is to know and understand the customer so well, such that the product or service fits him and sells itself [1]. This paper suggests data mining of prediction techniques. The process of Data Mining helps firms to analyze the customer data and extract the useful information, to gain competitive advantage over others. As Data mining described, the database of customer service as a repository of invaluable information and knowledge, can be utilized to improve customer service [2]. Indeed, the potential use of Information Technology as a competitive weapon has already become a popular cliché and if data mining and information technology technique both combine they can discover new patterns from large data sets in a human-understandable structure and involve database from which they seek to derive information about their customers' wants and needs [3]. The key issue we find is that old forecasting is the area of predictive analytics dedicated to understanding consumer demand for goods or services. That understanding is harnessed and used to forecast consumer demand. Knowledge of how demand will fluctuate enables the supplier to keep the right amount of stock on hand. If demand is underestimated, sales can be lost due to the lack of supply of goods. If demand is overestimated, the supplier is left with a surplus that can also be a financial drain. Understanding demand makes a company more competitive in the marketplace. Understanding demand and the ability to accurately predict it is imperative for efficient manufacturers, suppliers, and retailers. To be able to meet consumers' needs, appropriate forecasting models are vital. Although no forecasting model is flawless, unnecessary costs stemming from too much or too little supply can often be avoided using data mining methods. First technique in data mining for forecasting techniques is decision tree; it is the learning of decision trees from a class labeled training tuples. A decision tree is a flow chart like tree structure, where each internal node denotes a test on an attribute, each branch represents an outcome of the test, and each leaf node holds a class label. The topmost node in a tree is the root node. The construction of decision tree classifier does not require any domain knowledge of parameter setting, and therefore is appropriate for exploratory knowledge discovery [4]. But in attribute relevance analysis, we need to identify weak relevant attributes and/or irrelevant data that can be excluded from the concept description process. Evaluation of each attribute in the relation is done using the selected relevance analysis measure. Retrieving useful information from a specific database is a critical task in many application domains. One of the important works in retrieving information is capturing the right perceptions of human communication [5]. Using these techniques, a business is better prepared to meet the actual demands of its customers [6]. Because in business, customer is the hero of whole process model of market and both satisfying and exceeding customers through the use of product is important. And doing so, company seeks to confirm that the right products and services are supplied to the right customers. In any data mining exercise, one of the first tasks is to identify the input variables and the output (predicted) variable(s). It is a wide and exciting area of business intelligence, and many organizations are yet to appreciate how they can profit from its use. They had anticipated the application of data mining to grow exponentially over the next few years. By and large, the application of data mining was constrained only by their imagination [7].
Data mining or knowledge discovery is needed to make sense and use of data. Knowledge discovery in the data is the non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns of data [8]. Data mining is core subject in the field of neural network, artificial intelligence, understanding the customer needs, database management system, fuzzy logic, determining the forecasting of the product sell out, etc. Despite several efforts, there has been considerable rise in the failure of these above fields. One of the reasons for this is improper analysis of requirements beforehand. This requires looking for a method which overcomes these issues. Here, we are focusing on the customer need, and data mining is a customer-driven process used for improving quality and gaining higher customer satisfaction. There are several major data mining techniques that have been developed and used in data mining projects recently as follows:
Thus, to make the study more specific in attribute relevance analysis and decision tree, the data has been presented in categorical fields by studying the published and available literature.
Decision tree is the learning of decision trees from a class labeled training tuples. Decision trees may handle high dimensional data. Their representation of acquired knowledge in free form is intuitive and generally easy to understand by humans. The learning and classification steps of decision tree induction are simple and fast. In general, decision tree classifier has good accuracy. Decision tree have been used for classification in many applications areas, such as medicine, manufacturing and production, financial analysis, astronomy etc [4]. Decision tree is a widely used data mining method and in decision theory, a decision tree is a graph of decisions and their possible consequences, represented in form of branches and nodes. This data mining method has been used in various fields in business and science for many years and has given outstanding results. [9]. Folorunsho Olaiya investigated the use of data mining techniques in forecasting maximum temperature, rainfall, evaporation and wind speed. This was carried out using Artificial Neural Network and Decision Tree algorithms and meteorological data collected between 2000 and 2009 from the city of Ibadan, Nigeria.[10]. Ding and Qia presented a decision tree based method which was used to clarify the relationship between the load and relative variables. A set of decision rules were obtained and stored in the knowledge base to forecast especially for developing countries where the demand is increased with dynamic and high growth rate [11]. Andy presented a successful application of a decision-tree to the market-clearing price forecasting for Queensland day-ahead electricity market in Australia (Pool trades model). Taking Load and historical MCP (Market Clearing Price) into full account, principles of the decision-tree technique and its involvement in electricity price forecasting were summarized in detail [12]. E. Lobato et. al predicted the values of switched shunt devices, i.e., reactors and capacitors in a short-term time scope (24 -36 hours ahead) in order to build a power system scenario. A methodology based on decision trees is proposed and its performance is validated by forecasting the reactive output of the shunt components of the spanish power system [13]. Decision Trees for Uncertain Data by Smith Tsangy Ben Kaoy Kevin Y. Yipz Wai-Shing and Hoy Sau Dan Leey discussed that sources of uncertainty include measurement/quantization errors, data staleness, and multiple repeated measurements. With uncertainty, the value of a data item is often represented not by one single value, but by multiple values forming a probability distribution. Processing (Probability Density Function) PDF's is computationally more costly than processing single values (e.g., averages); decision tree construction on uncertain data is more CPU demanding than that for certain data. To tackle this problem, they proposed a series of pruning techniques that can greatly improve construction efficiency [14]. Jim Dowd et al presented data perturbation technique based on random substitutions. They showed that the resulting privacy-preserving decision tree mining method is immune to attacks that are seemingly relevant [15]. Sreerama K. Murthy summarized work on constructing decision trees from data exists in multiple disciplines such as statistics, pattern recognition, decision theory, signal processing, machine learning and artificial neural networks. Significant results relate to automatically constructing decision trees from data, on decision tree construction, attempting to identify the important issues involved [16]. Mark Last et al discussed that decision tree algorithms are known to be unstable: small variations in the training set can result in different trees and different predictions for the same validation examples. And for stability and accuracy, the Info-Fuzzy Network (IFN), a novel information-theoretic method for building stable and comprehensible decision-tree models is used. The stability of the IFN algorithm is ensured by restricting the tree structure to using the same feature for all nodes of the same tree level and by the built-in statistical significance tests [17]. Yael Ben-Haim et al proposed a new algorithm i.e Streaming Parallel Decision Tree (SPDT) for building decision tree classifiers. The algorithm is executed in a distributed environment and is especially designed for classifying large data sets and streaming data [18]. Leonard et al presented a framework that organizes the approaches to tree simplification and summarize and critique the approaches within tree simplification approach framework and insight into their relative capabilities [19]. Several voting algorithms, including Bagging, Ada Boost, and Arc-x4, have been studied using decision tree and Naïve Bayes to understand why and when these algorithms affect classification error [20].
Retrieving useful information from a specific database is a critical task in many application domains. One of the important works in retrieving information is capturing the right perceptions of human communication [5]. Yo-Ping Huang et al discussed a bird searching system using the attribute relevance analysis method to improve information retrieval which has the potentials of flexible querying for ecological databases and the experimental results show that our proposed method would be helpful in understanding the existing database and come up with a pretty good guess about the ambiguity [5]. Another one presented that attribute relevance analysis is used to eliminate irrelevant attributes to give as inputs to neural network and it is a simple neural network used for testing class defaulter [21]. Thakkar A et al addressed that in data mining applications, very large training sets are common and this restriction limits the scalability of such algorithms and this issue has proposed a data classification method which integrates data cleaning, attribute oriented induction, relevance analysis and induction of decision trees and this method extracts rules at multiple levels of abstraction and handles large data sets and continuous numerical values in a scalable way [22]. Zeng F et al presented a method of test suite reduction by using data classification techniques which are introduced in data mining. This method tries to use attribute relevance analysis to find the interrelations of all attributes in test requirements, and then reduce the test suite with the most appropriate attributes and values [23]. Rajdev Tiwari et al presented a paper formulate and validated a method for selecting optimal attribute subset from the large number and size of modern data sources that can make the integration process cumbersome. In such cases dimensionality of the data is reduced prior to populating in Data Warehouse (DW). Attribute subset selection on the basis of relevance analysis is one way to reduce the dimensionality. Relevance analysis of attribute is done by means of correlation analysis, which detects the attributes (redundant) that do not have significant contribution in the characteristics of whole data of concern, based on correlation using Genetic Algorithm (GA), where GA is used as optimal search tool for selecting subset of attributes [24].
Data mining refers to extracting or mining knowledge from large repository of data. Data mining should have been appropriately named knowledge mining from data which is somewhat large in size. The origin of Data Mining draws ideas from machine learning/AI, pattern recognition, statistics, and database systems. Traditional techniques may be unsuitable due to enormity of data, high dimensionality of data and heterogeneous distributed nature of data. To generalize a decision-making process, collecting and processing original data is done with the objective to predict target customer product preferences. The entire data mining model consists of the following five steps: construction of data marts, preprocessing of data, attribute relevance analysis, decision-tree classifications, and prediction of target customer needs. There are six steps for mining the data from given database as follows [25]
Through data mining, manufacturers can get useful and accurate trends about their customers purchasing behavior.
Data mining provides financial institutions about the estimated level of risk associated with each given loan and many other related predictions.
It helps law enforcers in identifying criminal suspects as well as apprehending these criminals by examining trends in crime habits, crime type, location and many other patterns of behaviors.
Data mining can assist researchers by speeding up their data analyzing thus allowing them more time to work on other projects.
With the widespread use of Internet, the concerns about privacy have increased tremendously. Because of privacy issues, some people do not shop on Internet. They are afraid that somebody may have access to their personal information and then use that information in an unethical way, thus causing them harm.
Although companies gather a lot of personal information about us online, they do not have sufficient security systems in place to protect that information. For example, recently the Ford Motor credit company had to inform 13,000 of the consumers that their personal information including Social Security number, address, account number and payment history were accessed by hackers who broke into a database belonging to the Experian credit reporting agency.
Trends obtained through data mining is intended to be used for marketing purpose or for some other unethical purpose, may be misused. Unethical businesses or people may used the information obtained through data mining to take advantage of vulnerable people or discriminate against a certain group of people, and data mining technique is not 100 percent accurate; thus mistakes do happen which can have serious consequence.
Following are the main applications and existing sectors where applying data mining is applied and profits increased by understanding the customer needs and wants.
And there are many more places where data mining can be applied and make our prediction better instead of traditional forecasting techniques.
The general idea behind this method is to compute some measure that is used to quantify the relevance of an attribute with respect to a given class or concept. The first limitation of class characterization for multidimensional data analysis in data mining and warehousing and OLAP tools is the handling of complex objects. The second limitation is the lack of an automated generalization process: the user must explicitly tell the system which dimensions should be included in the class characterization and to how high a level each dimension should be generalized. Actually, each step of generalization or specialization on any dimension must be specified by the user [26]. The attribute relevance analysis demands the following steps,
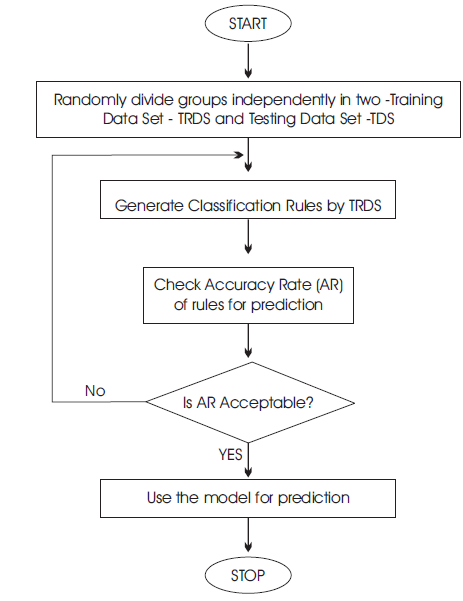
Large scale data mining applications involving complex decision making can access billions of bytes of data using this technique, efficiently and accurately [27]. In Attribute Relevance Analysis, the data of the samples will be divided randomly into two independent groups: training data set and testing data set. A model will be generated by the training set and the entire modeling process is to learn and gain information from the given data. A concept called “information gain” is needed here and is explained as follows based on the work of Han and Kamber [26]. The authors discuss the various steps involved in this method but for better understanding, the flow chart for Attribute Relevance Analysis as given in Figure 1 because John Berger, media theorist, writes in his book, Ways of Seeing (Penguin Books, 1972), "Seeing comes before words". Attribute relevance analysis performs to remove irrelevant or weakly relevant or less informative attributes, and hold the most relevant attributes for analysis.
Figure 1. Flowchart for Attribute Relevance Analysis in Data Mining
Suppose S is the training samples set, and all of the label values of the samples in the set are known.
Assume that an attribute has m label values with each value representing a class, thus there are m classes and are denoted as Ci (i = 1,…, m). Furthermore, denote the sample number in class Ci as si and the total sample numbers in S as s. Thus, the expected information needed to classify a given set of samples is
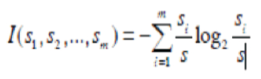
Assume that attribute A has v values{a1, a2… av}, then S may be partitioned into v subsets, {s1, s2,…,sv}, where sj (j = 1, 2, …, v) contains the samples from S and has the same value of aj (j = 1, 2, …, v). If A is selected as the testing attribute, and given that sij is the sample number of Ci in subset Sj, the entropy (expected information) corresponding to the subsets partitioned by A is
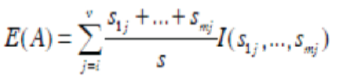
The information gain corresponding to the subsets partitioned by A is
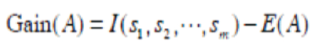
Then the attributes represented by the values of information gain are ranked from high to low. The attribute that has the highest information is selected as the test attribute.
As the name indicates, the decision-tree approach presents a set of decisions in a tree-like structure. The basic concept behind the decision tree classification algorithm is the partitioning of records into “purer” subsets of records based on the attribute values. A pure subset is one in which all the records have the same class label. The end result of the decision tree algorithm is the output of classification rules that are simple to understand and interpret. This interpretability property is strength of the decision tree algorithms [28]. Each node specifies a test of some attributes of an instance. Each branch corresponds to one of the possible values of this attribute. Each leaf node represents class label or class label distribution. The basic top-down decision tree generation approach is greedy algorithm. At the beginning, all the training examples are at the root. Then the best attribute for each tree node is selected based on the Relevant Attribute Analysis described in the preceding section. During a movement from the root to a leaf node, a node is split into several branches. At each branch, run the algorithm and generate more nodes. The basic steps of the greedy algorithm are summarized below.
Otherwise, the heuristic algorithm selects the attribute with the highest information gain among the others that are not labeled yet. This attribute becomes the “test” or “decision” attribute at the node.
The knowledge represented in decision-tree induction can be extracted and represented in a form of IF-THEN rules. One rule is created for each path from the root to a leaf node. Each attribute-value pair along a given path forms a conjunction in the rule antecedent (“IF” part). The leaf node holds the class prediction, forming the rule consequent (“THEN” part). Decision tree technique is useful where, there is involved simple decision making to access thousands of bytes of data.
As computerization has been coming to all aspects of life, the storage of massive amounts of data also is increasing. Data mining comes with a pool of techniques which can be effectively utilized for the prediction purpose with this massive data. Two of the techniques Attribute relevance analysis and Decision tree classification described here are generated by the training set. After the model and rules are extracted, it is necessary to examine the accuracy rate of the rules before using it for prediction. The accuracy rate is the percentage of samples from the testing set that are correctly classified and is obtained by evaluating the data in the training set with the known label values. If the accuracy rate is acceptable, then the rules can be used for prediction. Specifically, the attribute set of given customers with certain characteristics is the input of the classification rules, and the products or services that will be provided are the output.
These techniques can be used for predicting purpose. The flowchart depicting the entire process of attribute relevance analysis is shown in Figure 1.
Targeting the customers is an integral part of businesses today as it directly relates to customer satisfaction. For this suitable prediction of customer is necessary. Various techniques or methods are proposed over the years for this purpose. Data mining is one such powerful method which can be effectively utilized for this purpose. This paper makes an attempt to present a conceptual analysis of how data mining can be used for the prediction using attribute relevance analysis and decision tree classification rules. The advantage of using attribute relevance analysis technique for mining large databases allows an attribute of raw data having a large number of distinct values to be removed if there is no higher level concept for it whereas for small amount of data mining, decision tree is well suited. Decision tree can predict what the future will look like and attribute relevance analysis predicts what the future should look like. If we apply attribute relevance analysis to filter out irrelevant attribute and then we go for the decision tree on the same data sets, we will get comparatively higher accuracy in small amount of time than before we construct the decision tree.