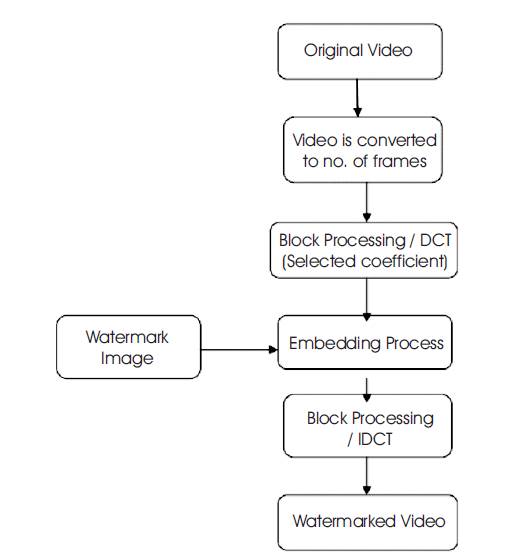
Figure 1. Flowchart showing Watermark Embedding Process
In this paper, an improved video watermarking algorithm is presented for copy protection. Each video frame is divided into non-overlapping 8*8 blocks. Each block is a transformed 2D-DCT. After performing the same transformation to all the blocks and frames, embedding of image watermarking is performed with the selected DCT coefficients. Performance of the system is evaluated using peak Signal to Noise Ratio, Mean Square Error, Normalized Mean Square Error, Root Mean Square Error and Absolute Mean Error.
Nowadays people are highly dependent on network technology, where the users of networks especially over the Internet are increasing enormously. The increased importance of digital content invites new challenges for securing the distribution of digital media, because the digital content can be easily copied and distributed. Therefore copy protection is one of the greatest challenge. The protection of copying a content is known as copy protection. This copy protection is the motivating factor in the new developing watermarking techniques. Watermarking [1-6] can be used for copy protection. There is a need for video watermarking[1, 2], as most of the information on internet these days are in the form of videos. Video watermarking is a technology of embedding various digital information in video frames [3], 6, 7].
Digital watermarking algorithms are classified into frequency domain and spatial domain algorithms. Spatial domain algorithms embeds watermark by directly modifying pixels of carrier signal[8, 9], while Frequency domain algorithms embeds watermark by modifying frequency bands [10, 11]. Frequency domain watermarking is more secure and robust as compared to spatial domain watermarking.
Developing an algorithm for video watermarking in frequency domain using DCT which embeds watermark in video frames.
Watermark is embedded by using block processing and selector. Proposed method uses invisible watermarking. In literature, DCT transform has been successfully used for digital watermarking. In the proposed algorithm, DCT is used for video watermarking in frequency domain. DCT divides carrier signal into low, middle, and high frequency bands [10]. DCT watermarking is classified into two types: Global DCT watermarking and Block-based DCT watermarking. In the Global DCT watermarking, the DCT computation is performed on the whole image, while in the Block-based DCT, the image is divided into nonoverlapping blocks and then DCT computation is performed on each block separately to obtain lowfrequency, mid-frequency and high-frequency subbands .
To improve the robustness of watermark against JPEG compression, some techniques are proposed that embed watermark into the low-frequency components of the image/frames. However, these components hold significant information of the content. Directly replacing the low-frequency components with watermark may introduce undesirable degradation to image quality. To preserve acceptable visual quality for watermarked images.
S.D. Lin et. al proposed a watermarking technique that adjusts the DCT low-frequency coefficients by the concept of mathematical remainder [11]. Simulation results demonstrate that the embedded watermarks can be almost fully extracted from the JPEG-compressed images with very high compression ratios.
J. R. Hemandez et. al proposed image watermarking in DCT domain [12]. Generalized Gaussian distributions to statistically model the DCT coefficients of the original image were applied and showed how the resulting detector structures lead to considerable improvements in the performance with respect to the correlation receiver. Performance was measured using probability of errors in watermark decoding and the probabilities of false alarms and detection in watermark detection.
Kothari A., and Dwivedi suggested the transform domain method for digital video watermarking for embedding invisible watermarks behind the video using middle frequency band and PN Sequence. The result was compared using same parameters and concluded that, for the same block size and constant value, the first method gives better results at the receiver end compared to the second. As the value of the constant increases, the watermark recovery is better at the cost of perceptibility of the watermarked video in both methods [13].
Lu Jianfeng et. al suggested a MPEG2 Video Watermarking Algorithm Based on DCT Domain [14]. The performance was good.
R. Eswaraiah et. al discussed about the robust watermarking method for color images using DCT coefficients of watermark [15].
K. Ramanjaneyulu et. al proposed robust and oblivious watermarking algorithm and its performance against various image attacks was good. Algorithm was designed for embedding both 32×32 size and 64×64 size watermarks. Proposed method was the modified version of DCT based Permuted Image Digital Watermarking Method extended for 64×64 size watermark [16].
Masoumi M. et. al proposed video watermarking in YCbCr color space [17]. The presented method maintained a good transparency of video stream, meanwhile resists the watermark against a variety of attacks including geometric attacks such as rescaling, rotation, and nongeometric attacks like Gaussian noise, salt & pepper noise, speckle noise, median & low-pass filtering, blurring, JPEG and MJPEG compression.
Wood H. presented two digital watermarking schemes for embedding a grayscale watermark into color images. The first scheme embeds the watermark directly into the spatial domain while the other embeds the watermark after converting to the DCT Domain [18]. In both schemes, following the pixel modification, the watermark is redirected into the saturation component of the image. The original image was needed in the extraction process. The result of both schemes produced a watermarked image that has no different visibility of the original image.
Gopika V Mane et. al discussed a number of techniques for the watermarking of digital images, also focused on the limitations and promises of each. LSB substitution does not provide robustness, hence it was not a very efficient approach for digital watermarking. LSB embedded watermarks can easily be extracted using techniques that do not visually degrade the image to the point of being noticeable. DCT domain watermarking proved to be highly challenging to JPEG compression as well as considerable amounts of random noise. The wavelet domain as well proved to be highly resistant to both compression and noise, with minimal amounts of visual degradation. The counters proposed to geometric distortion typically rely on discovering the exact rotation, or shifting used in the attack. Typically these techniques are computationally pricey, and unpredictable[19].
Priya Porwal et. al proposed the Least Significant Bit Technique, Discrete Cosine Transform Technique, Combined Least Significant Bit, and Discrete Cosine Transform Technique and Least Significant Bit with Modifications. Out of all the above four proposed techniques, Discrete Cosine Transform watermarking techniques in frequency domain have better perceptual quality control and capacity than the others [20].
Jaya Jeswani and Tanuja Sarode have proposed a blind image watermarking using DCT in RGB color space by modifying middle frequency coefficients DCT(4,3) and DCT(5,2) [21].
Wen Yuan Chen proposed watermarking scheme using the lower-band coefficient of DCT block was employed, it is robust against the attack by the JPEG. In order to improve the imperceptions, only one bit was embedded in each coefficient of a DCT block [22].
Proposed method is divided into three subsections. Section 2.1 explains frame conversion of video and selection of DCT Coefficients using block processing. Section 2.2 describes watermark insertion process and Section 2.3 describes watermarked video after Inverse DCT.
A video is converted into a number of frames. Each frame is resized by 256* 256. Each frame is divided in the sub matrix using block processing of 8*8 blocks. In this process, most of the energy in the image is into the upper left corner of resultant matrix. These cofficients are selected using selector. Selector is used to extract the upper left corner of sub matrix.
For watermark embedding process, Gray scale Watermark image is multiplied by a constant factor and is added with the block processed output.
To view watermarked frame, IDCT Block is to be used. Again block processing block is used to set the size 4*4. Now an image pad block with a zero pad 4*4 sub matrix is used to get its original 8*8 size because zeroes are replacing the lower energy transform coefficient. The output frame is an approximation of original frame. 2D IDCT picks the inverse two dimensional DCT of submatrix. Figure 1 shows the Watermark Embedding Process.
Figure 1. Flowchart showing Watermark Embedding Process
Input: Video frames and watermark Images
Output: Watermarked video
The proposed video watermarking algorithm is implemented on Intel Core i5-3210M, 1.8 Ghz, 4GB RAM machine and Matlab 7.8 R2009A. The proposed method is tested on different videos like vipcolorsegementation, vipbarcode, vipmosaiking of different size and different frame rates and the watermark of size 256×256 is used as watermark. For evaluating the performance of the proposed algorithm, Peak Signal to Noise Ratio (PSNR), Mean Square Error (MSE), Root Mean Square Error (MSE), normalized Mean Square Error (MSE) and Absolute Mean Error (AME) were used.
Mean Square Error,
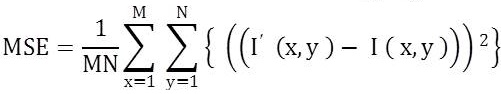
Peak Signal to Noise Ratio,
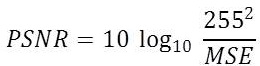
where,
M, N = size of the original video frame,
I( x , y ) = pixel values at location ( x, y ) of the original video frame,
I'(x , y ) = pixel values at location ( x , y ) of watermarked video frame.
Normalized Mean Square Error,
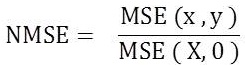
Root Mean Square Error is given by ,
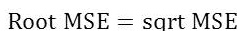
Absolute Mean Error is given by ,
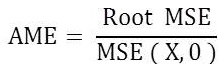
The suggested algorithm was tested on 100 videos. The results of embedding algorithm for 9 videos are shown in Table 1, where same size watermark is embedded into different cover videos that are having different frame size and frame Rates.

Table 1. Different Outputs for different cover videoes and with different watermark
Suggested System's performance is evaluated using PSNR, MSE, NMSE, Root MSE, Absolute MSE for the seven videos are presented in Table 2 and a comparative analysis is shown in Table 3.
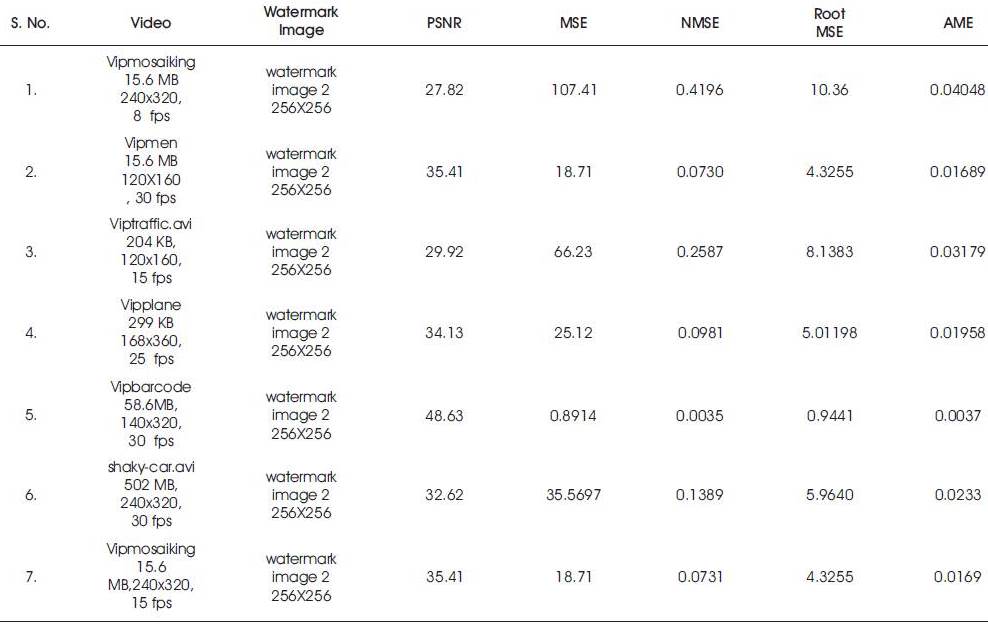
Table 2. Performance Analysis
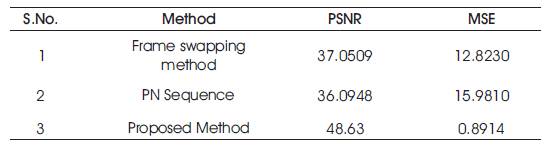
Table 3. Comparative Analysis
Averege PSNR = 33.6937.
Average Normalized Mean Square Error = 0.2203.
Averege Root Mean Square Error = 6.1786.
Average Absolute Mean Square Error = 0.443.
The algorithm presented in this paper is robust video watermarking technique for the gray scale watermark images. Various video watermarking algorithms have been proposed in spatial and frequency domain. This technique is implemented in frequency domain in which the watermark is embedded in the video frames using selected DCT coefficients.
The proposed method achieves PSNR as 48.63 dB and MSE 0.8913. Experimental results show that the proposed method is imperceptible, embedded video is excellent with high PSNR and has very low visual artifacts.