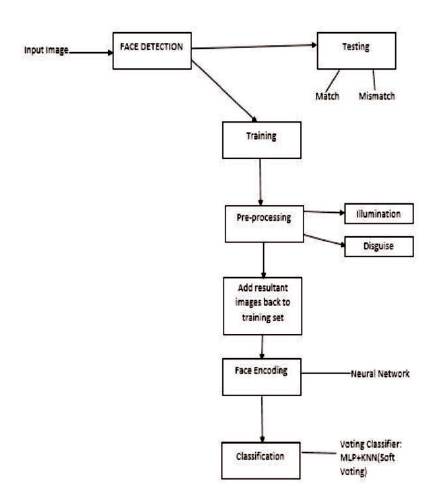
Figure 1. Steps involved under Face Recognition
Accuracy is one of the major concerns for any face recognition algorithm. A good preprocessing technique can increase the accuracy of a face recognition system. For this purpose, the authors present a preprocessing method for face recognition, which is helpful for training under-sampled images. For this purpose, different preprocessing techniques are taken and those methods are used during training and the resultant images are added back to the training set. Each individual preprocessing technique is helpful to tackle different conditions like lighting, disguise, etc. The training will be done using a deep convolutional neural network and a Voting Classifier. Further the results of the existing preprocessing methods are compared with the proposed model on LFW dataset. They have also used a technique to increase the accuracy of the system.
Face Recognition is one of the key topics being focused by many researchers now-a-days. Face Recognition basically deals with the detection of a face in a particular image or video, and then to identify the individuals in that particular image. This process can be done by converting the image into numerical values and then storing them in a dataset. Once a dataset is formed, any face from a new input image can be identified by comparing the values of the face in the input image with the values present in the dataset. The entire process of face recognition can be done in the order: Image input, Face- Detection, Training/Testing. Face recognition can be used for video surveillance in public places and for that reason, various conditions should be taken into consideration, such as various lighting conditions, disguise, etc. To tackle these conditions, different pre-processing methods are used together under training. Since the author start with very few training images per class at the beginning, facial expressions are not looked upon in the initial stages. To tackle under-sampled data, a method is used where few of the test images will be added to the training images. This can improve accuracy of the system significantly. OpenFace is used for face recognition ( Amos et al., 2016).
Before reaching on to a conclusion about the preprocessing techniques to be used, different techniques were studied ( Han et al., 2013; Karthikeyan et al., 2012) to tackle illumination problems and tested the system with various existing preprocessing techniques like Histogram Equalization and Discrete Cosine Transform (DCT) ( Ahmadi and Jamzad, 2011; Chande and Shah, 2011; Dharavath et al., 2014).
Histogram Equalization is used to increase in the contrast of an image, when data of the image is represented by close contrast values. It evenly distributes the intensities among all areas of an image. It works better, when the histogram of image is restricted to a particular region. But it fails, when there is a large intensity difference within an image. Histogram Equalization is generally applied on grayscale images.
Discrete Cosine Transform (DCT) is a process of splitting an image into parts of different importance. It represents an image as a sum of sinusoids of varying magnitudes and frequencies. DCT is generally used for image compression applications.
The problem with the existing preprocessing techniques is that they are able to tackle only one problem (like illumination) at a time. In order to tackle multiple problems, a preprocessing method is considered which applies various preprocessing methods on the existing training images and adds them back to the training images, which is discussed further. Preprocessing techniques are applied on the combination of a portion of LFW ( Huang et al., 2008) dataset and some real time images before deciding about the techniques to be applied. In this paper, face recognition technology is considered for educational institutions. In these organizations, face recognition can be used for both biometric as well as video surveillance purposes. Since the main concentration is on individual organization, the focus is mainly on the accuracy and tackling multiple challenges rather than on the time period involved. The entire process is done under UBUNTU environment using Python, Torch, and OPENCV.
Lawrence et al. (1997) presented a hybrid neural network system and combined a local image sampling, a Self- Organizing Map (SOM) neural network and a Convolutional Neural Network. Quantizations of image samples are provided by self-organizing map, which provides dimensionality reduction and invariance to minor changes in image samples. The successively larger features in a hierarchical set of layers are extracted using convolutional neural network. Jafri and Arabnia (2009) discusses about the various face recognition techniques such as feature-based and holistic techniques, different applications of face recognition, advantages and disadvantages of each recognition technique, and finally about how face recognition works for Video Sequencing. Zhang (2011) discussed about pre - processing techniques such as DCT and Wavelet transform. Wavelet Transform is mainly used for image de-noising, compression, fusion, and so on. Inner products of a signal with a family of wavelets are computed using Wavelet Transform. DCT makes an attempt to DE correlate the image data. After each transform coefficient, it can be independently encoded without any compression efficiency loss. Ahonen et al. (2004) provided a technique by considering both the shape and texture information to represent face images. Face description using Local Binary Patterns (LBP) was described, which is a powerful means of texture description. After labelling an image pixel using thresholding, the 3 x 3 neighborhood values of each pixel with centre value are calculated as a binary result. After this, Histograms were used as texture descriptors. Dissimilarity measures, such as Histogram intersection, Log-likelihood statistic, and Chi Square Statistic were discussed.
Deng et al. (2012) used an Extended Sparse Representation- Based Classifier [ESRC] to deal with undersampled data. They used an interclass variant image to overcome different variations in images.
Wei and Wang (2013, 2015) proposed an auxiliary dictionary learning method, where the auxiliary dictionary is learned from external data. Images collected from the external data are utilized for the learning of an auxiliary dictionary for modelling intra-class variations including possible occlusions. By jointly solving this learning algorithm with Sparse Representation - based Classification (SRC) in a unified framework, the recognition performance can be significantly improved. They proposed a Robust Auxiliary Dictionary Learning Model (RADL), where the external dataset of p subjects are partitioned into Probe set and Gallery set. The probe matrix consists of images with different intra-class variations to be modeled. The gallery matrix contains only one or few face images per subject.
Different steps involved are shown in Figure 1. Initially, different images are taken for training. For this purpose, a combination of LFW dataset and images of few known people have been taken. A selected number of classes from LFW dataset are chosen such that each class contains at most 5 training images per class. A total of 2208 training images for 502 classes are taken for training purpose.
Figure 1. Steps involved under Face Recognition
Initially, the faces are detected for each training image. This is done by using shape_predictor_68_face_ landmarks. dat file, which crops only the face part from an image using 68 landmarks that cover the entire face ( Tensor face, 2018). Once the faces are detected, these faces undergo preprocessing and then the generated preprocessed faces undergo encoding, where the image will be converted into numeric values and are stored under a dataset. For this purpose, a strong Deep Convolutional Neural Network is used. This dataset will be used for classification where different classes are formed and each class name represents the name of a person.
Different preprocessing techniques are considered and the resultant images are added back to training. This technique has been approached since we start with very few training images per class. Later on, the number of training images will be increased.
Different Preprocessing techniques used in this system are
All these techniques are used to tackle various illuminations and disguise conditions.
Tackling Different illumination conditions: (Gamma Correction + Contrast Enhancement + Increased Illumination).
To handle the images with various lighting effects in real time environment, the authors have used the following pre-processing methods.
Gamma correction is used to correct the image illuminance. It increases the brightness of images and removes the noise values. Gamma Correction of an image is found by using the following equations
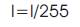
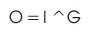
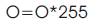
where, I is the input image,
O is the output image, and
G is the gamma value.
1.0. Here, we keep G=0.5. This makes the image to lighten up./p>
It enhances the pixel intensity in an image. Increase in contrast makes the object more distinguishable. A factor of 0 gives a solid grayscale image. They have used the factor of 1.5. Contrast enhancement is done by using “Image Enhance.Contrast” class of Python PILLOW.
It increases the overall illumination of an image. In this method, the image is converted into a numpy array and then the illumination factor is added. The resultant array is converted back into an image. The following equation is used to increase the illumination:
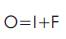
where I is the input image,
O is the output image, and
F is the illumination factor.
The problem with this method is that there might be noise values in the resultant output image.
Tackling other conditions: (Grayscale + Addition of disguise.
Convert original images into grayscale images and include them under training images.
This is done to tackle any disguise of a person by adding disguise (Addition of goggles) to each training class during training. Here, an image of a person wearing goggles is taken and then those goggles are added to all the training classes. This can be done simply by identifying the location of goggles of the image and then add that goggle region to the eye region of all the images of every class. Though this method results in a bit of noise, this can be quite effective.
The variation among different preprocessing methods of a same sample are shown in Figure 2.
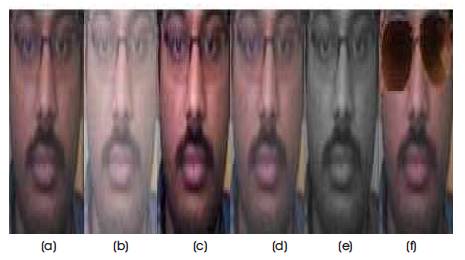
Figure 2. Image Variation in Pre-processing Methods, (a) Actual Image, (b) Gamma Correction, (c) Contrast Enhancement, (d) Increased Illumination, (e) Grayscale Image, (f) Disguise Addition
All the resultant images of each class (images of one sample of a class are shown in Figure 2), will be added back to the training images of corresponding class. An image can also be formed through a combination of methods like Increased Illumination + Disguise addition or Grayscale + Disguise addition and the resultant image can also be added to the training set.
The entire process is distributed into two phases:
Before one can use a face recognition system, it is needed to be trained so that it can recognize different people. For this purpose, the images of required people are entered as input and the system is trained accordingly. The following steps are followed during the training phase:
Once the classification is done, the system will be good enough to be used in real time.
Once the classification is done, the system can be used for testing. Even in the usage of system in real time, the system will be continuously tested. The following steps are followed during testing phase.
The results have been calculated using 323 test-images of 250 classes of the LFW dataset. An additional 50 testimages of other classes have also been considered. To find out the best preprocessing technique for this system as well as the suitable classifier, the system has been tested with different preprocessing methods as well as different classifiers. Different classifiers like K-Nearest Neighbors Classifier (KNN), Multilayer Perceptron Classifier (MLP), Voting Classifier, and Support Vector Machine Classifier (SVM) (SVM's results were not included since they were poor for low number of training images per class). In the initial phases, experimentation was carried out on different preprocessing methods and the accuracies were pretty low for them. Each preprocessing method was applied on different classifiers (SVM, KNN, MLP, and Voting). As stated earlier, a new preprocessing method have been used to tackle various conditions. Coming to the classifiers, MLP classifier outperformed KNN classifier in most of the cases. But still, for few images, KNN classifier gave better results when compared to MLP classifier. For this reason, the authors have opted to go for a Voting classifier (Soft voting among KNN and MLP). Figures 3 to 6 show the accuracy charts in different cases.
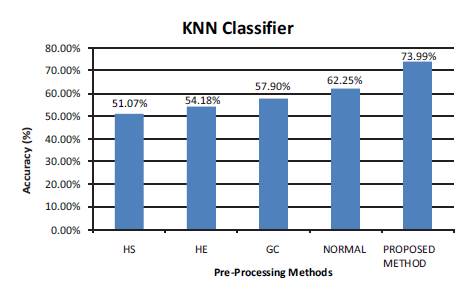
Figure 3. Accuracy Chart for KNN Classifier
Figure 3 shows the accuracy of the system using different preprocessing methods under KNN classifier.
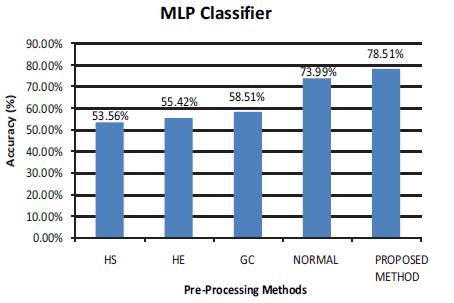
Figure 4. Accuracy Chart for MLP Classifier
Figure 4 shows the accuracy of the system using different preprocessing methods under MLP classifier.
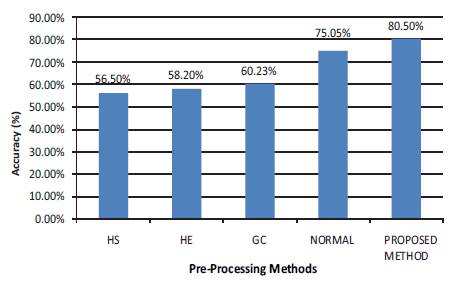
Figure 5. Accuracy Chart for Voting Classifier
Figure 5 shows the accuracy of the system using different preprocessing methods under Voting classifier.
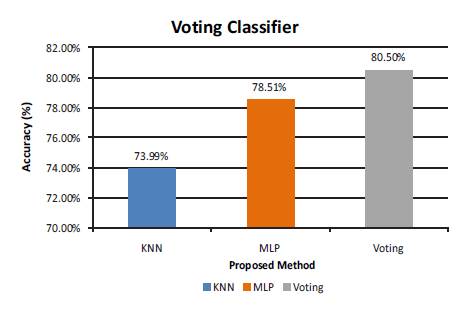
Figure 6. Accuracy Chart for Proposed Pre- Processing Method
Figure 6 shows the accuracy of the system under different classifiers using proposed preprocessing method.
The final analysis shows that the accuracy is high for the proposed preprocessing method. The accuracy is further high when real time samples are considered. Figure 7 shows the variation inaccuracies under different classifiers when the total training images are increased.
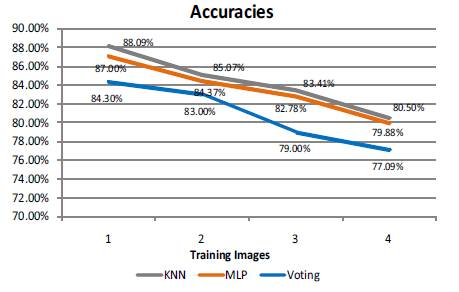
Figure 7. Accuracy Chart for Variation in Training Images
The main reason behind the usage of Voting classifier is to combine both KNN and MLP classifiers. It implements hard voting and soft voting. Soft voting between KNN and MLP classifiers has been used. Soft voting is only possible for well calibrated classifiers, i.e., classifiers that can give confidence values as output. The voting process is done using the formula,
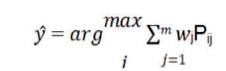
where w is the weight that can be assigned to j classifier j and i ∈{0,1}.
P is the prediction given by classifier j.
Since the weights are uniform, the formula can be used as,
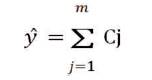
For example, if KNN predicts an image with 0.60 confidence and MLP predicts the same image with 0.96 confidence, then the Voting classifier gives a confidence of 0.78 for the same image.
C =0.60 C2=0.96
C =0.60+0.96
C is the confidence predicted by classifier 1 and C is the 1 2 confidence predicted by classifier 2.
KNN classifiers correctly predicts images if classes are majorly unique. It fails when there are similar classes and when the training images per class are less in number. But KNN gives better results under disguise conditions. Similarly, variations in images are well detected by MLP classifier and moreover it works well for under-sampled data. Since the plan is to increase the amount of training images per each class by adding test images to training, they have opted to go for a Voting classifier through soft voting.
Face recognition system can be used for biometric and video surveillance in an organization.
Figure 8 shows the overall architecture. Here, the database server holds the entire details of all students and faculty of an organization. Few systems will be connected to the server using the remote desktop architecture and these systems can be used for surveillance purposes. Biometric devices will have monitors to display the log files. Same server will be used for both biometric as well as surveillance purpose.
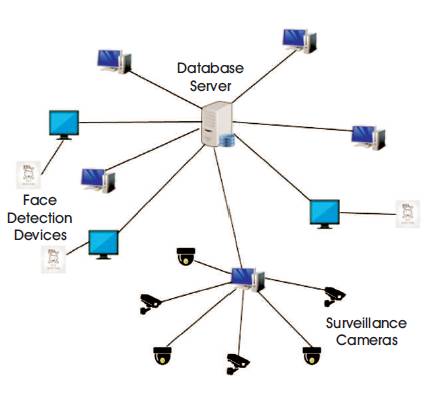
Figure 8. Architecture
Face recognition system can be used for biometric logins in an organization.
Figure 9 shows the procedure to implement the biometric device using face recognition system. Initially, limited number of training images per class will be taken. A threshold value will be set based on the confidence of identification. Later on, a simple algorithm will be run such that every time a user logs in, his/her image will be added to their respective training class if the confidence is less than the given threshold value. This method will be followed until the each training class reaches their maximum size (say 50 images per class). Once a class reaches its maximum size, no more images will be added to training. The concept of this paper is to start with very few training images per class and then keep on increasing the number of training images. This makes sure that one can obtain different types of training images of a same person. For the first few days, an option can be added where user intervention will be provided regarding the login output (whether the output is correct or not), and that option would be removed later. This method can increase the overall accuracy of the system.
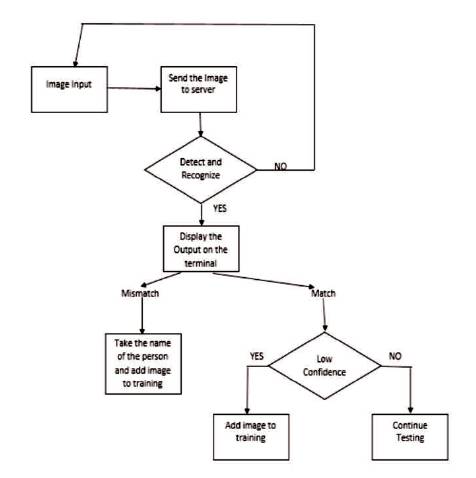
Figure 9. Procedure for Biometric
Many systems will be connected to the server using remote desktop configuration. CCTV footage of all cameras will be recorded. Details of the people involved in a particular footage can be found out with the help of few specified client systems. Only authorized people can use this system. For this purpose, each area will be provided with a system, where footage of all the surveillance cameras of that particular area will be stored in a local database which will be connected to that system. Anys ecific part of a footage / entire footage/photo can be sent to the server via these client systems. The details of those people will be sent back as a response from the server. This request-response process can be done with the help of a local host.
The word under-sampled was started with very few training images per class. The proposed preprocessing method does not show a great variation in accuracies when implemented on LFW dataset, but a major improvement is shown when the real time images are considered. The authors have not considered the LFW dataset as it is and they have only taken a part of the dataset as per their requirements and the accuracies are calculated by considering both LFW dataset and the real time images.
Though we used different preprocessing methods were used to overcome lighting conditions, there are still few limitations with this work.
Using different preprocessing techniques can be very helpful to tackle various conditions like illumination, disguise, etc. Tackling illumination is by far one of the major concerns for biometric facial recognition systems. This paper mainly focuses on tackling those conditions by including multiple preprocessing methods to the basic pre- processing method. The authors have also tested the system by using different classifiers. With the inclusion of these methods, facial recognition can become more accurate, especially for biometric and surveillance applications.
This system cannot detect partial faces. One way to overcome this is to attach the input partial face with its mirror image, i.e., by detecting the eye and nose on one side of the face and by attaching its mirror image on the other side of the face.