Abstract
Nowadays, the corporate world not only prioritizes an individual's skills but also their personality traits, as they play a crucial role in achieving success both professionally and personally. Therefore, recruiters must have knowledge of potential employees' personality traits. However, due to the significant increase in job seekers and the decline in job availability, it is challenging to manually select the most suitable candidate by just reviewing their resume. This analysis aims to explore various machine learning techniques for predicting personality traits effectively by analyzing resumes through Natural Language Processing (NLP) methods. The research demonstrates that the Random Forest algorithm outperforms other approaches such as k-Nearest Neighbors (kNN), Logistic Regression, SVM, and Naive Bayes in terms of accuracy.
Keywords:
- Personality Prediction
- Curriculum Vitae (CV)
- Machine Learning
- Natural Language Processing
Introduction
Personality can potentially determine an individual's suitability for a specific job role. Personality assessment enables us to evaluate an individual's ability to lead, influence, and communicate effectively with others. The first step in the recruitment process involves submitting a job application, which includes personal information, experience, and, most significantly, a CV. Companies usually receive a large volume of applications per job opening, and selecting qualified candidates is a challenging task for humans. Many candidates are eliminated in the first round based on factors such as suitability, a poorly structured CV, or inadequate skills. Finding the right candidate is a daunting task, as no candidate is perfect. Some may lack the necessary skills, while others may not have the right personality traits. Hence, this research proposes a way to streamline and expedite the shortlisting process by predicting the candidates' personalities.
However, personality is a crucial factor in determining an individual's suitability for a specific role, and therefore, analyzing and understanding personality is essential. The research aims to elevate the machine's proficiency level so that it can evaluate candidates using the same approach as a human reviewer, thereby adopting a more human-like approach to personality analysis. This research endeavors to examine and implement several machine learning algorithms to determine which of them offers the highest accuracy when processing diverse datasets. Furthermore, it aims to visualize the data and establish correlations between different factors.
1. Big Five Test
The research focuses on predicting personality types using the big five test, which is widely used, reliable, and directly correlates with performance across five cognitive domains. Although other personality tests, such as the Rorschach and Myers Briggs Type Indicator (MBTI) tests, are available, the big five test was chosen for its effectiveness in predicting personality traits.
Big five personality test also known as Openness, Conscientiousness, Extroversion, Agreeableness and Neuroticism (OCEAN) Model analyses personality types of individuals based on five dimensions - Openness(O), Conscientiousness (C), Extraversion (E), Agreeableness (A), Neuroticism(N). With each of the dimensions signifying a different personality type. It uses keywords to identify traits and analyze which personality a person fits.
1.1 Openness
The trait "openness" is characterized by qualities such as imagination, curiosity, and a willingness to consider new ideas, as implied by its name. Openness is one of the big five personality traits to test the personality. It refers to an individual's level of imagination, creativity, curiosity, and willingness to try new things. People who score high in openness tend to be more open-minded, receptive to new ideas, and open to new experiences. They are often described as creative, imaginative, and unconventional, and they are likely to explore new ideas and perspectives. Openness can be an important factor to consider when evaluating a candidate's potential for a particular role or organization. Machine learning algorithms can analyze the language used in a candidate's CV to assess their level of creativity, curiosity, and openness to new experiences. This information can be valuable to employers seeking candidates who can bring fresh ideas and perspectives to their organization. Incorporating the trait of openness into machine learning algorithms can provide deeper insights into a candidate's personality and potential for a particular role or organization.
1.2 Conscientiousness
Conscientiousness describes someone who is thoughtful, goal-oriented, and able to make good decisions. It refers to an individual's level of organization, responsibility, and reliability. People who score high in conscientiousness tend to be disciplined, hardworking, and detail-oriented. They are often described as dependable, organized, and goal-oriented. Conscientiousness can also be an important factor to consider when analyzing a candidate's personality. By examining the language used in a candidate's CV, machine learning algorithms can assess the level of organization, attention to detail, and goal orientation. This information is valuable to employers who are seeking candidates who can take on responsibilities, meet deadlines, and work effectively in a team. Conscientiousness is an important personality trait that can influence an individual's work behavior and effectiveness. Incorporating this trait into machine learning algorithms can provide deeper insights into a candidate's potential for a particular role or organization.
1.3 Extraversion
"Extraversion," also known as "extroversion," is characterized by qualities such as excitement, talkativeness, and assertiveness. It refers to an individual's level of sociability, assertiveness, and outgoingness. People who score high in extraversion tend to be more outgoing, energetic, and social. They are often described as talkative, assertive, and confident. Extraversion can be an essential factor to consider when assessing a candidate's suitability for a role. By analyzing the language used in a candidate's CV, machine learning algorithms can assess the level of social and interpersonal skills, as well as confidence and assertiveness. Extraversion is an important personality trait that can influence an individual's communication style, social behavior, and effectiveness in certain roles. It is possible to gain deeper insights into a candidate's personality and potential fit for a particular role or organization by incorporating this trait into machine learning algorithms.
1.4 Agreeableness
Agreeableness refers to features such as trust, affection, and social behavior in an individual. It pertains to an individual's level of kindness, cooperativeness, and empathy. People who score high in agreeableness tend to be more compassionate, friendly, and cooperative. They are often described as warm, helpful, and considerate. By analyzing the language used in a candidate's CV, machine learning algorithms can assess the level of empathy, cooperation, and helpfulness. This information can be valuable to employers who are seeking candidates who can work effectively in a team, build positive relationships with clients or customers, and contribute to a positive work environment. It is also important to note that extremely high levels of agreeableness can sometimes lead to a tendency to avoid conflict or confrontation, which can be detrimental in certain situations, such as negotiating or making difficult decisions. Therefore, it is essential for machine learning algorithms to consider a balance between agreeableness and other personality traits, such as assertiveness and resilience.
1.5 Neuroticism
Neuroticism includes attributes like sadness, moodiness, and sudden bursts of emotion. Neuroticism refers to an individual's level of emotional instability, anxiety, and moodiness. People who score high in neuroticism tend to be more sensitive to stress, more prone to negative emotions, and may experience difficulty regulating their emotions. By analyzing the language used in a candidate's CV, machine learning algorithms can assess the level of emotional stability, resilience, and ability to cope with stress. This information can be valuable to employers who are seeking candidates who can work effectively under pressure, maintain a positive attitude in difficult situations, and manage their emotions in a healthy way. Neuroticism can sometimes lead to a tendency to be overly self-critical, anxious, or prone to negative thinking, which can impact job performance and overall well-being. It is important to consider a balance between neuroticism and other personality traits, such as confidence and optimism. Neuroticism influences an individual's emotional well-being, coping skills, and job performance. It is possible to gain deeper insights into a candidate's personality and potential fit for a particular role or organization.
As these five dimensions cover almost all avenues needed to know someone, it is the right method that forms the basis of a person's overall personality.
2. Literature Survey
Demetriou et al. (2003) investigated the relationships between performance on tasks representing five cognitive domains (quantitative, categorical, spatial, causal, and propositional reasoning), self-attribution of ability in regard to them and also in regard to three general cognitive functions (processing speed, working memory, and self-monitoring and self-regulation), and the big five factors of personality (extraversion, agreeableness, conscientiousness, neuroticism, and openness to experience).
Bai et al. (2012) propose an approach that intends to facilitate this line of research by directly predicting the Big- Five Personality from user's SNS behaviors. Comparing to the conventional inventor y-based psychological analysis, demonstrated via experimental studies that users' personalities can be predicted with reasonable precision based on their online behaviors. Except for proving some former behavior-personality correlation results, our experiments show that extraversion is positively related to one's status and neuroticism is positively related to the proportion of one's angry blogs (blogs making people angry).
Robey et al. (2019) designed a plan to integrate the job characteristics model into the E-HR system to search for a new model of efficient operation in human resource management in the internet age. In this project, a set of techniques is developed that make the whole recruitment process more effective and efficient. A system is implemented that ranks the candidates based on weight-age policy as well as an aptitude test. Today, there is a growing interest in the personality traits of a candidate by the organization to better examine and understand the candidate's response to similar circumstances.
In a project described by Zubeda et al. (2016) they used natural language processing and machine learning to rank CVs based on the company's criteria. The authors suggest incorporating the candidate's Github and LinkedIn profiles to gain a better understanding of their skillset, abilities, and, most importantly, personality. This approach would make it easier for the company to find a suitable match.
Reza and Zaman (2017) analyzed the CVs of individuals using natural language processing and machine learning by first converting CVs to HTML and then reverse engineered them to HTML code, following which segment finalization and qualification feature extraction were done. The model extracts data from a CV and segments it based on the values. They have classified the CVs using multivariate logistic regression. However, the size of the dataset was very small (Reza & Zaman, 2017).
3. Proposed System
3.1 Dataset
To avoid the tedious process of manual data collection, resumes are gathered of job candidates through various websites and direct communication with potential candidates, which resulted in a collection of 708 resumes in PDF and DOCx formats.
3.2 Methodology
The main goal of our study is to predict an individual's personality by evaluating their scores for the big five personality traits, which are openness, extraversion, agreeableness, neuroticism, and conscientiousness. To achieve this, it is necessary to calculate the scores directly from each CV ting their scores for the big five personality traits, which are openness, extraversion, agreeableness, neuroticism, and conscientiousness (Khan et al., 2020). To achieve this, it is necessary to calculate the scores directly from each CV. The method, illustrated in Figure 1, involves parsing the entire resume and searching for relevant keywords related to the big five test.
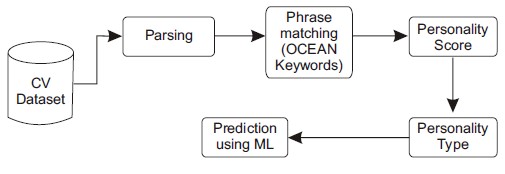
Figure 1. Workflow of Proposed System
The CV dataset refers to a collection of resumes or CVs from job applicants. These CVs are analyzed to extract information about the candidate's skills, work experience, and education. The parsing stage involves breaking down the CV into its component parts, such as sections for work experience, education, and skills (Aydin et al., 2016). This allows the machine learning algorithms to better understand the structure of the CV and identify relevant information. Phrase matching involves analyzing the language used in the CV to identify specific keywords or phrases that are associated with different personality traits.
For example, words like "team player" or "collaborative" may be associated with high levels of agreeableness, while words like "ambitious" or "competitive" may be associated with high levels of conscientiousness. Once the relevant phrases have been identified, a personality score is calculated based on the frequency and strength of these phrases in the CV. This score is used to assign a personality type to the candidate, based on the big five personality traits. Machine learning algorithms are then used to analyze the data and predict the candidate's personality type based on the identified phrases and their frequency in the CV. This allows employers to gain insights into a candidate's personality and potential fit for a particular role or organization, helping them to make more informed hiring decisions.
To parse CVs, use of pyresparser, a simple resume parser designed to extract important information like name, email address, description, and skills from CVs. Pyresparser can process files in Portable Document Format (PDF) and DOCx formats, and the parsed data is subsequently stored in a Comma-Separated Value (CSV) file.
Table 1 presents a compilation of keywords linked to the OCEAN personality traits, with each trait having a designated set of ten related keywords. To analyze the resume data, Natural Language Processing (NLP) tools such as TextBlob, NLTK, and SpaCy can be utilized. Chose to use SpaCy as it is a freely available NLP software library with the capability to process vast quantities of text data.
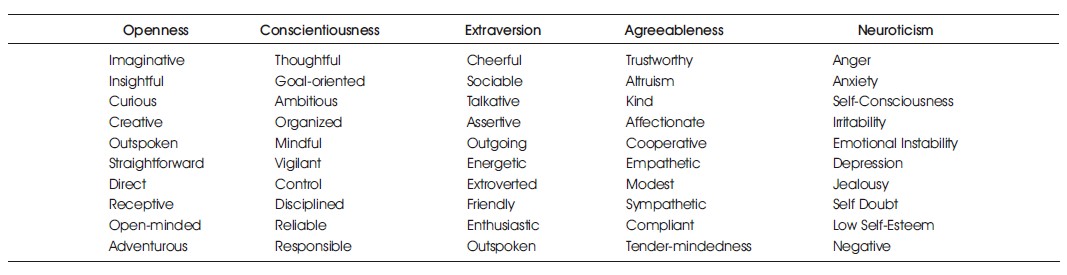
Table 1. Ocean Keywords
The PhraseMatcher class in spaCY is highly efficient in matching large sequences of tokens in documents (Spacy, n.d.).
The keywords in Table 1 will be matched by the mentioned class. The algorithm uses the Phrase Matcher class to search for these keywords and assigns scores ranging from 0-10 based on the occurrence of OCEAN keywords in a candidate's CV. These scores are shown in the table below, and each data point is then labeled as dependable, extraverted, lively, responsible, or serious. A Comma-Separated Value (CSV) file is an output with the degrees of the 'big five' traits as columns, and each data point is labeled according to Table 2.
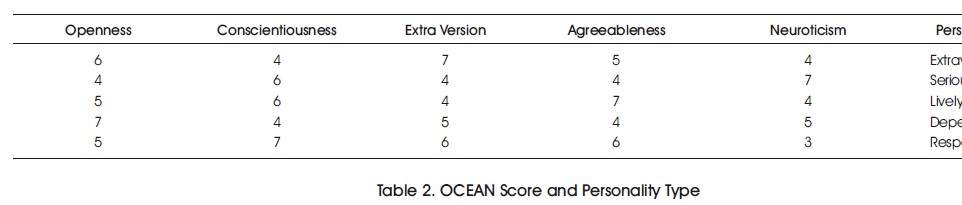
Table 2. OCEAN Score and Personality Type
4. Model Training and Testing
In probability, Baye's theorem is used to compute the conditional probability. The theorem forms the basis of the Naive Bayes classifier, a classification algorithm that assumes strong independence assumptions between the features. According to the algorithm, each feature of the problem makes an equal and independent contribution to the outcome.
4.1 Logistic Regression
Logistic regression is an algorithm that is analogous to linear regression except that it predicts the probability of an outcome being true or false. It is a popular algorithm for solving classification problems like binary classification (pass/fail, rain/no rain). Logistic regression is commonly used for binary classification problems, such as predicting whether a candidate has a certain personality type or not. Once the supervised learning algorithm has been trained, it is tested using a separate set of labelled data to evaluate its accuracy and performance (Sharma & Kaur, 2015). This testing data consists of CVs from candidates whose personality type is unknown, and the algorithm is tasked with predicting their personality type based on the language used in their CV. The logistic regression algorithm is used to calculate the probability of a candidate having a particular personality type based on the identified phrases and their frequency in their CV.
4.2 Naive Bayes
Random forest is an ensemble technique that is used for both regression and classification tasks. It generates output by employing multiple decision trees. Bagging, or bootstrap aggregation, is used to train the random forest algorithm. Naive Bayes is a type of supervised learning algorithm that is commonly used for text classification problems, such as predicting whether a given document belongs to a certain category or not. The algorithm analyzes the language used in the CVs and identifies specific words or phrases that are associated with each of the big five personality traits. This testing data consists of CVs from candidates whose personality type is unknown, and the algorithm is tasked with predicting their personality type based on the language used in their CV (Pratama & Sarno, 2015). The algorithm assumes that the presence of each word or phrase is independent of the others, hence the name "naive." Despite this simplifying assumption, Naive Bayes is often effective at text classification tasks. It is possible to predict a candidate's personality type based on the language used in their CV with a high degree of accuracy. This information can be valuable to employers who are seeking candidates with the right personality traits for a particular role or organization.
4.3 kNN
kNN refers to k-nearest neighbors, which is a supervised machine learning algorithm capable of addressing both classification and regression problems. The algorithm assumes that similar data points typically appear in close proximity, allowing it to predict the class of a new data point based on the classes of its nearest neighbors in the training data.
During the model training stage, the kNN algorithm is trained using a set of labeled data, which consists of CVs from candidates whose personality type has already been determined. Once the algorithm has been trained, it is tested using a separate set of labeled data to evaluate its accuracy and performance (Kunte & Panicker, 2019). This testing data consists of CVs from candidates whose personality type is unknown, and the algorithm is tasked with predicting their personality type based on the language used in their CV.
The kNN algorithm works by finding the k nearest neighbors of a given data point in the training data, based on some similarity metrics. The algorithm then assigns the class that is most common among the k-nearest neighbors to the new data point. The performance of the kNN algorithm can be sensitive to the choice of the value of k and the similarity metric used, which may require tuning.
4.4 SVM
Support Vector Machine (SVM) is a supervised machine learning algorithm that can handle classification and regression problems. Its aim is to locate a hyperplane in N-dimensional space (where N is the number of features) that can effectively categorize data points. The SVM algorithm accomplishes this by maximizing the margin between the hyperplane and the nearest data points, called support vectors. The margin is defined as the distance between the hyperplane and the support vectors. The SVM algorithm can handle both linear and non-linear data by mapping the data to a higher-dimensional space, where it becomes linearly separable. The algorithm uses a kernel function to perform this mapping, which can be a linear, polynomial, or Radial Basis Function (RBF) kernel. In addition, the SVM algorithm tries to find a hyperplane that best fits the data points, aiming to minimize the difference between the predicted output and the actual output for each data point, subject to a penalty for deviations from the hyperplane. This penalty is controlled by the regularization parameter, which helps to balance the trade-off between model complexity and accuracy.
The SVM algorithm is a powerful tool for classification and regression problems, particularly when dealing with high-dimensional and non-linear data. Its ability to handle both linear and non-linear data, and to find the best hyperplane for separating classes or fitting the data, makes it.
4.5 Random Forest
Before training our model, the personality column was label-encoded in our dataset. Our final dataset had 708 rows and 6 columns. Using the sklearn library, 70% of our data is used for training purposes and 30% for testing the results. To predict the personality of a prospective candidate, various machine learning algorithms are used such as logistic regression, naive bayes, random forest, Support Vector Machine (SVM), and kNN. Random Forest combines multiple decision trees to create a more robust and accurate model. The algorithm randomly selects subsets of the data and features and builds decision trees for each subset. The final prediction is based on the aggregation of the predictions from all decision trees. Random forest is effective in handling high-dimensional data and is less prone to over fitting than a single decision tree.
Despite training our model on all the algorithms, that our predictions were quite inaccurate, with even the best models only achieving an accuracy rate of 30 percent. In addition, our training and testing datasets had very different distributions. While the training data was slightly imbalanced, the testing data was even more so. However, as employers typically seek candidates who are "responsible" and "lively" above all else, the problem converted into a binary classification problem (1 = responsible or lively, 0 = others).
5. Results and Discussions
After inputting the data into the models, we were able to increase the accuracy to approximately 0.71. Table 3 shows that the Random Forest algorithm provides the highest accuracy, followed by Bayes, kNN, SVM, and logistic regression. As anticipated, the Random Forest algorithm also has the lowest mean squared error, which calculates the average difference between the actual and predicted values squared.

Table 3. Accuracy and Mean Squared Error (MSE) Values
Among the five algorithms used, the Random Forest algorithm provided the highest accuracy, followed by Bayes, kNN, SVM, and logistic regression. The accuracy score indicates the percentage of correctly classified data points. Therefore, an accuracy of 0.71 implies that the model was able to correctly predict the personality type of 71% of the candidates. The Mean Squared Error (MSE) was calculated for each algorithm, which measures the average difference between the actual and predicted values squared. The lower the MSE, the better the performance of the models. As anticipated, the Random Forest algorithm had the lowest MSE, indicating that it was the most effective algorithm for predicting the candidate's personality type. The results suggest that Random Forest is a highly accurate and reliable algorithm for predicting personality type based on the language used in a candidate's CV.
Conclusion
This research employs several machine learning algorithms, including logistic regression, naive bayes, random forest, SVM, and KNN, to predict personality using CV analysis. Through the use of pyresparser, spaCy, and phrase matcher, it was able to predict the personalities of multiple candidates. The results indicate that the random forest algorithm achieved the highest accuracy of 0.71. However, due to the limited availability of data, the accuracy is lower than expected, and further research is necessary to improve the models' accuracy. This research highlights the potential of machine learning algorithms for predicting personality based on CV analysis and provides a foundation for future research in this area. The ability to predict personality type can provide valuable insights for employers in the hiring process and can lead to more effective job matches and increased job satisfaction for both employers and employees. The proposed system has the potential to streamline the recruitment process for various companies by considering the personalities of potential candidates. Further research can enhance the proposed system's efficiency and performance and improve the accuracy of personality prediction using CV analysis.