
Figure 1. Typical Trademark Images in the Database
This paper proposes an automated system for rotation, scaling, and translation invariant trademark retrieval based on colored trademark images. Trademark images are recognized using color, shape, and texture feature extraction. Color Feature extraction is done by implementing Color Histogram, Color Moments, and Color Correlogram techniques. Texture features are extracted by Gabor Wavelet and Haar Wavelet implementation. Shape feature extraction is implemented by using Fourier Descriptor, Circularity features. The proposed trademark retrieval approach uses Relevance Feedback and three kinds of query improvement strategies, New Query Point (NQP), Query Rewriting (QRW), and Query Development (QDE). The datasets used for experimentation are publicly available FlickrLogos 27 and FlickrLogos 32 databases. The query image is varied from the database images, by applying transformations on the query image like rotation, scaling, and translation of the image by number of pixels in X and Y direction. The system is tested for transformed query images with different combination of transformations. The proposed system is highly robust giving good retrieval results against these transformations.
Trademarks are the symbols used by organizations to promote their products or services. For the recognition of these products and services trademark play very important role. Trademark image registration is one of the important applications of Content Based Image Retrieval (CBIR), which is coming under the Intellectual Property Rights (IPR) area. Therefore, designing an efficient trademark recognition system for its registration has become a challenge nowadays. There might be attacks like rotation, translation, scaling, and noise addition on the images in this system. This is one of the challenges that should be handled while designing a trademark retrieval system.
Trademark retrieval is one of the important applications of Content Based Image Retrieval (CBIR). The conventional approaches of CBIR are based upon the visual feature extraction techniques. The retrieval is done by computing the similarity between query image (Query By Example (QBE) and the database images. This approach is having the problem that the extracted visual features are very assorted and cannot capture the concept of the user's query. To solve this problem, Relevance Feedback (RF), technique is incorporated in the QBE system. In this approach the users give feedback on the preferred images to refine the image explorations (Su et al., 2011).
The feedback taken from user against the relevancy of the retrieved images is called as Relevance Feedback (RF). In this process, the user gives feedback to the system whether the retrieved image is relevant or not relevant. This information associated with the feedback given by the user can be used for the improvement of the query (Pinjarkar et al., 2012). The query improvement process may help to improve the retrieval performance of the image retrieval system.
Various RF based CBIR systems are developed to improve their results. But still these systems have some problems like redundant browsing and exploration convergence. Redundant Browsing means most of the RF methods focus on how to gain the user's satisfaction in one query process. The query is improved again and again by analyzing the precise relevant images selected by the users.
The conventional trademark image retrieval system (based on visual feature extraction) can be integrated with navigation pattern mining mechanism and the query improvement strategy to resolve the problem of redundant browsing and exploration convergence. The user's interest is attained through the navigation patterns mined from the user query log. It is used as an optimized search path to meet the search space toward the user's intention effectively. According to the discovered patterns, the users can obtain a set of relevant images in the query improvement process. Thus, the problem of redundant browsing can be solved using this mining process (Su et al., 2011). Three query improvement strategies New Query Point (NQP), Query Rewriting (QRW), and Query Development (QDE) are implemented to deal with the problem of exploration convergence.
In this paper, framework for color trademark recognition based on shape, color, and texture features by using Relevance Feedback technique is proposed which is invariant to translation, rotation, and scaling.
The rest of the paper is organized as follows. Section 1 describes the review of literature in this field. The proposed approach and details about dataset used are discussed in section 2. Section 3 deals with the experimentation and results obtained. Section 4 concludes the paper.
Rusiñol et al. (2011) designed an efficient queried-by example retrieval framework for trademark images. The images were described through vienna codes and visual contents of the images. The retrieval efficiency of the system was enhanced by using relevance feedback technique. The experimentation was done using 30000 trademark images database.
Wahdan et al. (2011) suggested a logo recognition system by using region-based Angular Radial Transform (ART) for shape feature extraction of logo images. The classification was done using Euclidian Distance (ED). The system was tested for the effects of noise on the retrieval performance using dataset of 2730 logo images.
Wang and Hong (2012) combined the image's global features and local features to design a trademark retrieval algorithm. The extraction and sorting of Zernike Moments was done on the basis of similarity. The similarity between the query image and the candidate images was calculated by using the Scale Invariant Feature Transform (SIFT) features. The experimental database used was “MPEG7 CE Shape-2 Part-B” of 3621 trademark images.
Hou and Shi (2012) proposed a Logo on Map (LoM) system which consisting of three modules: Picture Extraction Module (PEM), Logo Matching Module (LMM), and Web Mapping Module (WMM). The PEM was based on a keyword textual search while the LMM was a visual search using SIFT (Scale-Invariant Feature Transform) algorithm. This work proves that visual search is more efficient than textual search.
Bagheri et al. (2013) suggested a system based on shape feature extraction techniques. Zernike moments, Fourier descriptors, and shape are used to describe shape feature. For recognition of the logo images the Dempster- Shafer theory combination strategy was utilized with the three classifiers.
Alaei and Delalandre (2014) designed logo recognition system for document images. This system was detecting the regions of interest in the document images first. The Piece-wise Painting Algorithm (PPA) and probability features along with a decision tree technique was used for this detection. Template based recognition approach was used for the retrieval of logo images.
Ghosh and Parekh (2015a) designed an automated system for rotation and scale invariant logo recognition based on black and white logo images. The recognition was based upon two shape features Moment Invariants and Hough Transform. The experiments were implemented by using 1700 black and white logo images categorized into 100 classes. Classification of the images was done through Manhattan and Euclidian Distances metrics.
Ghosh and Parekh (2015b) suggested a system for rotation and scale invariant color logo recognition. The system was based on shape and color features extraction. Shape recognition was implemented through Moments Invariant and Color Recognition through color moments. The similarity/ distance metrics used were Manhattan and Euclidean distances.
The work done by the authors in the area of trademark image retrieval discussed above is based upon either of the color, texture, or shape features. In the proposed methodology, all the three features i.e. color, texture, and shape are taken into consideration for computing the similarity in the retrieval process, which yields promising results.
The performance of the trademark retrieval system was tested using publicly available FlickrLogos-27 and FlickrLogos-32 logo image databases. Some sample trademark images from the database are as shown in Figure 1. The low level features extracted from the image are used to explore the visual contents of the image. These mainly comprise of color, shape, and texture features (Long et al., 2003). The features of the trademark images in the database are extracted by implementing color feature extraction, texture feature extraction, and shape feature extraction. For color feature extraction, Color Histogram, Color Moments, and Color Correlogram techniques are used. For texture feature extraction Gabor wavelet and Haar Wavelet are implemented. And for shape feature extraction, Fourier Descriptor and Circularity features are used.
Figure 1. Typical Trademark Images in the Database
These features are classified using Euclidian Distance for similarity computation so as to retrieve the relevant trademark images from the database feedback is taken from the user about relevancy of the retrieved images (relevance feedback); performance of the system is evaluated using precision, recall, and accuracy.
To make the system robust against various transformations, transformation factors are taken in GUI designed. These factors include the translation of the image by shifting the image by number of pixels in the X direction and in the Y direction (referred as translate X and translate Y in the GUI), rotation angle, and scaling factors for resizing the image. The query images are tested for various combinations of these transformation factors.
The proposed approach is implemented as per the following steps:
Step 1: Querying an image to the system.
Step 2: Feature Extraction of the query image (Color Feature, Texture Feature, and Shape Feature extraction).
Step 3: Retrieval of images from the database similar to the query image.
Step 4: Taking feedback from the user whether the retrieved images are relevant or not relevant? (Relevance Feedback).
Step 5: Categorize into positive (P) and negative examples (N).
Step 6: Determine modified query point (new )
Step 7: Retrieval of images from the database based on new query point.
The block diagram of the proposed work is shown in Figure 2.
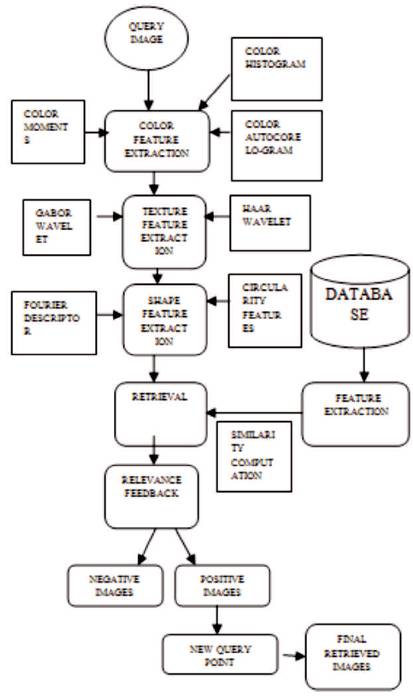
Figure 2. Block Diagram of the Proposed Work
The details about the feature extraction process are discussed as following:
The absolute color value of every pixel is analyzed through color feature extraction, which is executed by the image processing techniques, such as color histogram, color moments, and color correlogram (Long et al., 2003).
A color histogram is a vector, where each element represents the number of pixels falling in a bin, of an image. The color histogram has been used as one of the feature extraction attributes with the advantage like robustness with respect to geometric changes of the objects in the image.
The first order (mean), the second (variance), and the third order (skewness) color moments are used for effective representing color distribution of images (Long et al., 2003) .
The first three moments are defined as shown in the following equations.
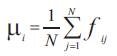
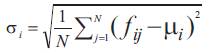
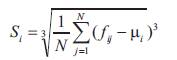
where fij is the value of the ith color component of the image pixel j, and N is the number of pixels in the image.
A color correlogram expresses how the spatial correlation of pairs of colors changes with distance.
Let M be an n x n image (For simplicity, let us assume that the image is square). The colors in M are quantized into m colors c1 ……cm .
For a pixel 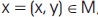 , let M(x) denote its color.
, let M(x) denote its color.
Let 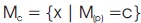 . Thus the notation
. Thus the notation 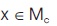 is identical with
is identical with 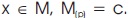 . For pixels x1 = (x1,y1), x2 =(x2,y2 ) the (p) distance between x1 and x2 is given by
. For pixels x1 = (x1,y1), x2 =(x2,y2 ) the (p) distance between x1 and x2 is given by
The set {1, 2, 3 …..n} is denoted by [n]
|x1 –x2| = max {|x1 –x2|, | y1 – y2|}.
Let a distance 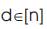 be fixed a priori. Then the correlogram of I is defined for
be fixed a priori. Then the correlogram of I is defined for 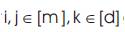 as
as
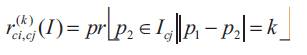
where, p1 ϵ Ic, p2 ϵ I
Given any pixel of color ci in the image, gives the probability that a pixel at distance k away from the given pixel is of color cj .
The representation of texture as a two-dimensional gray level variation can be employed for recognition of explicit textures in an image. Gabor wavelet transform and Haar wavelet transform are executed for texture feature recognition in the proposed work.
Gabor wavelet transform represents efficient technique for image texture retrieval in content-based image retrieval applications. Offering the capacity for edge and straight line detection with variable orientations and scales not being sensitive to lighting conditions of the image.
A two dimensional Gabor function g(x, y) is defined as:
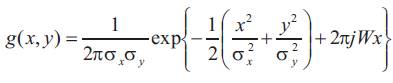
where, σx and σy are the standard deviations of the Guassian envelopes along the x and y direction, respectively. Then a set of Gabor filters can be obtained by appropriate dilations and rotations of g(x, y):
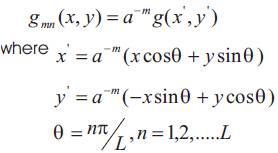
and m=0,1,…..s-1
where 
K and S are the number of orientations and scales, respectively. The scale factor a-m is to ensure that energy is independent of m.
Given an image I(x, y), its Gabor transform is defined as:
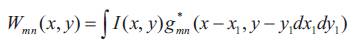
where * indicates the complex conjugate. Then the mean μmn and the standard deviation σmn of the magnitude of Wmn (x,y), i. e.
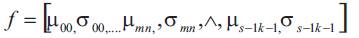
can be used to represent the texture feature of a homogenous texture region.
Haar wavelets are fastest to compute and simplest to implement. User queries tend to have large constantcolored regions, which are well represented by this basis. Haar wavelet can be represented as:
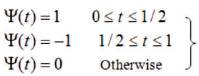
As is required, ψ(t) integrates to zero. One-level decomposition is performed on image I, which yields approximation image (A1) and horizontal, vertical, and diagonal detail images (D11, D12, D13) as shown in Figure 3.
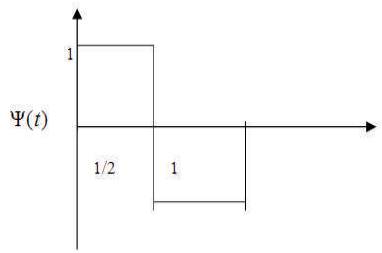
Figure 3. Haar Wavelet Representation
The methods for shape description can be categorized into either boundary-based (rectilinear shapes, polygonal approximation, finite element models, and fourier-based shape descriptors) or region-based methods (statistical moments). For retrieval of shape feature Fourier Descriptor and circularity features are implemented.
The shape of an object can be described through the Fourier transform of its boundary. Assume the contour of a 2D object as a closed series of consecutive boundary pixels (ps , qs), where 0 ≤ s ≤ T-1 and T is the total number of pixels on the boundary. Subsequently the three types of contour representations, i.e., curvature, centroid distance, and complex coordinate function are described as follows
The curvature C(p) at a point p along the contour is identified as the rate of modification in tangent direction of the contour, i.e.
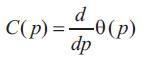
where θ (p) is the turning function of the contour.
The centroid distance is described as the distance function between boundary pixels and the centroid (pc , qc) of the object:
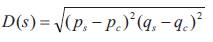
The computation of complex coordinate is done by characterizing the coordinates of the boundary pixels as complex numbers:
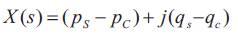
The fourier descriptor of the curvature is described as:

The fourier descriptor of the centroid distance is computed as:
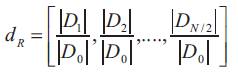
where Di in equations (10) and (11) indicate the ith component of Fourier transform coefficients. The positive frequency axes are taken into consideration since the curvature and centroid distance functions are real and, hence, their fourier transforms reveal symmetry, i.e., |D-i| = |Di|.
The fourier descriptor of the complex coordinate is given as:
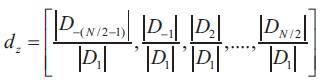
The transform coefficients are normalized through the first non-zero frequency component given by D1 in the above equation. Now negative and positive frequency components both are taken into consideration. The position of a shape determines the DC coefficient and hence it is not needed.
The boundary ((ps , qs), 0 ≤ s ≤ M-1) of each object is re-sampled to N samples before performing the fourier transform for ensuring the resulting shape features of all objects in a database to possess the same length. For example, N is set to 2n = 64 in order to accomplish the transformation proficiently using the fast Fourier transform (Long et al., 2003).
Circularity is calculated as:
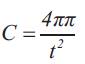
where z is the size and t is the perimeter of an object. This value varies between 0 (corresponding to a perfect line segment) and 1 (corresponding to a perfect circle). The direction of the largest eigenvector of the second order covariance matrix of a region or an object is described as the major axis orientation. The ratio of the smallest Eigenvalue to the largest Eigenvalue is defined as the eccentricity (Long et al., 2003).
Images are retrieved based on the similarity computed between query image and the images in the database. Euclidean distance is used for similarity computation.
The normal distance between two points in Euclidean space is called as Euclidean distance.
In Cartesian coordinates, if x = (x1 , x2 ,..., xn) and y = (y1, y2 ,..., yn) are two points in Euclidean n-space, then the distance (n) from x to y, or from y to x is given by the Pythagorean formula:
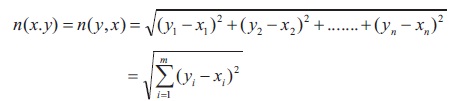
The Euclidean vector is the location of a point in a Euclidean n-space. Hence, x and y are Euclidean vectors, starting from the origin of the space, and their tips specify two points.
Based on the visual features and Euclidian distance the relevant images are retrieved from the database. After this retrieval process the feedback is taken from the user (relevance feedback) about the relevancy of the retrieved images.
The Relevance Feedback (RF) implementation is based upon the query improvement strategy and the mining concept. Query improvement strategy is implemented through New Query Point (NQP), Query Development (QDE), and Query Rewriting (QRW) method. The proposed framework is tested for 10 iterations of RF. The visual query points (of relevant/positive images) of every iteration are grouped into clusters using k-means clustering algorithm. A cluster number is assigned to each cluster. The RF information is kept as log records in four different tables which are used for mining frequently occurring patterns for the next query sessions. Data structures needed for storing this log information are described as follows:
1. Unique Record Table – contains query image name, iteration number, query point, and relevant image name
2 . Query Position Table – contains query image name and query point.
3. Navigation Operation Table – contains query image name, iteration number, and cluster number.
The entries of this table are implemented as follows:
Based on retrieval results after every iteration, query points are clustered using k-means clustering. The cluster number is assigned to each cluster and is saved in this table along with iteration number. These clusters are traversed for constructing a pattern for every query. For example, given a query image, if the retrieved images are available in cluster 2 of iteration 1, cluster 1 of iteration 2 and cluster 2 of iteration 3, then the pattern is N21, N12, and N23. These sequential patterns constructed are used for the mining process; the frequently occurred patterns are mined using Apriori mining algorithm.
4. Record Partition Table – contains Query point and relevant image name.
The information related to each feedback is stored in the Unique Record Table after every iteration of the feedback. The Navigation Operation Table is used for mining the navigation patterns. The Query Position Table and Record Partition Table are used for searching the relevant images. The navigation pattern tree is constructed by using sequential patterns determined. Each branch of this tree represents the sequential pattern. The query of every sequential pattern is utilized as seed of that tree referred as query pit.
The search process in the proposed trademark retrieval framework requires following input:
1) Set of positive and negative images obtained from the preceding feedback
2) Sequential patterns and Navigation pattern trees with query pit called as 'pt'.
The subsequent steps characterize this search process:
Step 1: The average of features of positive images is taken to obtain the new query point.
Step 2: The matching sequential patterns are determined through the closest query roots
Step 3: The closest leaf nodes are obtained by using these matching navigation pattern trees
Step 4: The top 'p' relevant query points from the collection of the closest leaf nodes are obtained.
Step 5: The top 'r' relevant images are retrieved as output.
In the proposed framework, the New Query Point (NQP) implementation is done through step 1. Steps 2-5 are executed for Query Development (QDE). The new feature weights are calculated using the features of positive images given by user at ever y feedback for implementing Query Rewriting (QRW) procedure. The details of the New Query Point (NQP) generation, Query Rewriting (QRW), and Query Development (QDE) are described as follows.
Suppose in the preceding feedback the images retrieved by the query point denoted by oldqp . A new query point newqp is generated by averaging the visual features of the positive examples P given by the user as a feedback.
Suppose the positive examples are given as P ={p1 , p2 ,.. ., pk} and m dimensions of the jth feature Rj ={r1Y , r2Y …… rkY} extracted from the Yth positive example. Then the new query point newqp implied by P can be defined as (Su et al., 2011).
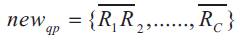
where
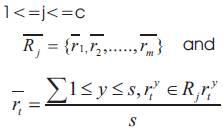
newqp and the positive examples are stored into the log database.
Suppose a set of positive examples is given as P = {p1 , p2 , . . . , pk} found by the query point oldqp in the previous feedback. The new weight of the jth feature Rj is defined as (Su et al., 2011).
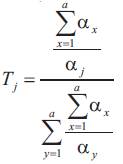
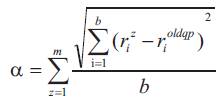
and
The weighted KNN search is done by QDE procedure, first the nearest query seed to each of P is determined called positive query seed, and the nearest query seed to each of N, called negative query seed (Su et al., 2011).
The positive query seed set and the negative query seed set may contain few common query seeds. To deal this condition a token tn.check is allocated to every seed. If the seed is having bigger number of negative examples than the positive examples then tn.check =0 otherwise tn.check=1.
After this the relevant query seeds are determined. The navigation pattern tree is traversed to find a set of matching leaf nodes. The new feature weights as calculated in equation (16) are used in the search procedure to find the required images.
The search procedure is classified into two steps.
In the first step, the relevant visual query points are generated and in second step, the relevant images are determined.
The query position table is used to find the relevant query points. The most similar visual query points are found using the KNN search method. Top 'r' similar visual query points are determined in first step. The top 't' images which are closer to newqp are retrieved as a result.
For experimentation FlickrLogos 27 and FlickrLogos 32 logo image databases are used. Feature vector's database is formed by extracting color, texture, and shape features. Euclidian distance is used to measure the similarity between query image and images in the database.
The experiment include giving a query image applying transformations on the query image, extracting features of the transformed query image, retrieving relevant trademark images from the database, taking feedback from the user about the relevancy of retrieved images, and finally retrieving the relevant images based on the feedback given by the user and new query point.
To introduce variations between the training and test images, transformations are applied to each of the query image, viz. rotation, scaling, and translation of the image by shifting the image by number of pixels in the X direction and in the Y direction (referred as translate X and translate Y in the GUI). These transformation factor values are taken from the user in the GUI designed making the system robust against these transformations. The input transformed query image, the top 20 relevant images retrieved before Relevance Feedback (RF) and the final retrieved images after taking the relevance feedback from the user are shown in Figures 4, 5, and 6, respectively.
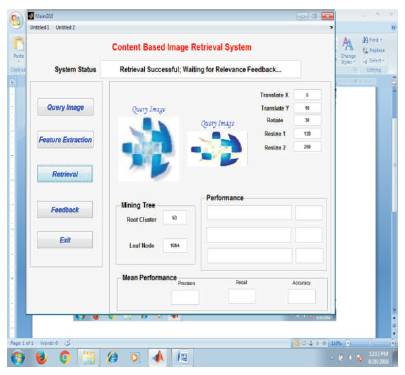
Figure 4. Giving Transformed Query Image with the given Transformation Factors
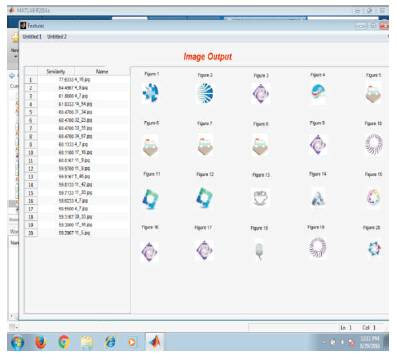
Figure 5. Top 20 Relevant Images Retrieved for the Sample Query Image with their Similarity (%) (Before Relevance Feedback)

Figure 6. Final Retrieved Images with Reference to the Sample Query Image (after Relevance Feedback)
The performance of the proposed system is evaluated in terms of standard evaluation parameters precision, recall, and accuracy which can be defined as follows:

TP - True positive means, if the retrieved images are similar.
Example 1: We retrieve 4 images. When the user checks two are relevant, then TP = 2.
FP = The images that are not recognized as relevant. The rest of the two images are considered as FP, means FP = 2.
TN = The images which are not retrieved are actually irrelevant.
Among 4 images, we input 2 as relevant. If the 2 images are available in the relevant images list, i.e. images that satisfy 40% similarity percentage, then TP = 4.
FN: Any image, which are not retrieved, but relevant
To determine this, list of images are sorted outbased on similarity percentage. The images that are not retrieved from the sorted list are considered as FN.
Example 2: We retrieve 4 images, out of which 2 are already decided as relevant. In the sorted list, apart from these two images, number of rest of the images, say 18, are FN.
TN: The non-retrieved images that are not relevant.
The images that are not retrieved and not available in the sorted list are TNs. It means, total number of database images - FN - number of retrieved images.
Example = 200-18-4 = 178
Accuracy is determined based on TP, TN, FP, and FN.
Accuracy= TP + TN/ (TP+TN+FP+FN)
= (2 + 178)/ (2+2+18+178)
= 180/200 = 0.9 = 90%.
The given query image is tested for the various set of transformations and the results are shown in Table 1. The color, texture, and shape similarity (%) of the final retrieved images (after RF) is calculated with reference to the given sample query image for the first set of transformations in Table 1 and is shown in Table 2. Table 3 provides the comparison of the proposed approach with Su et al., (2011) (All results shown are with respect to FlickrLogos-32 dataset.)
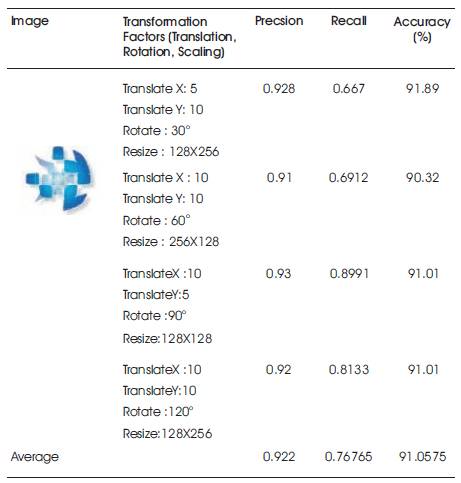
Table 1. Results in terms of Precision, Recall, and Accuracy with the Transformed Query Image
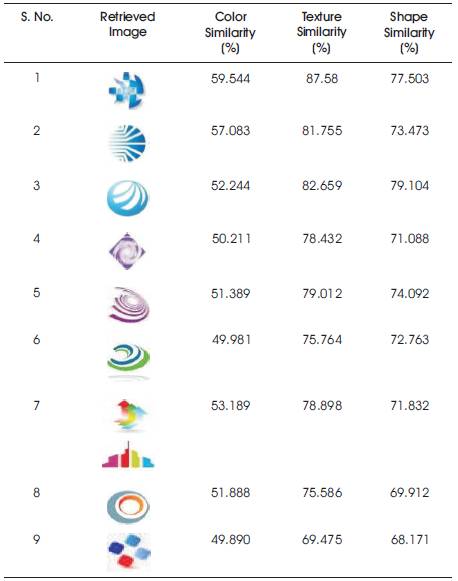
Table 2. Color, Texture, and Shape Similarity with respect to the Sample Query Image for the First Set of Transformation given in Table 1
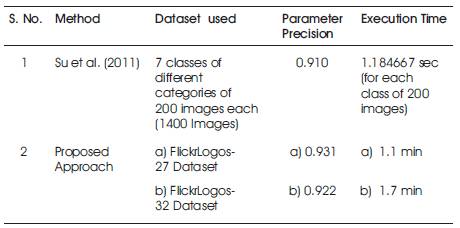
Table 3. Comparison with Su et al. (2011) and the Proposed Approach
In the proposed work, an automated system for color trademark retrieval is designed by implementing color, texture, and shape feature extraction techniques and relevance feedback approach. The system is tested for the various set of combinations of rotation, scaling, and translation factors on different query images. The performance of the system is evaluated using precision, recall, and accuracy. The color, texture, and shape similarity of the retrieved images with the query image is calculated. The results obtained are promising and proves that the performance of the system is improved after applying relevance feedback technique as compared with conventional technique of content based image retrieval. The proposed system is highly robust against rotation, scaling, and translation providing good retrieval results. In the future scope of work machine learning techniques can be combined with relevance feedback for further improving the accuracy of image retrieval system and to reduce the execution time. Also the system can be tested for the color variations in the query image by changing its color properties.