Figure 1. Dale's Cone of Experience
Advanced multimedia techniques offer significant learning potential for students. Dale (1946, 1954, 1969) developed a Cone of Experience (CoE) which is a hierarchy of learning experiences ranging from direct participation to abstract symbolic expression. This paper updates the CoE for today's technology and learning context, specifically focused on the use of multimedia in education. The new hierarchy, called the Multimedia Cone of Abstraction (MCoA), has fewer primary levels than the CoE but many more total levels because of multiple potential sublevels. The purpose of the MCoA is to help instructional designers of educational content to select appropriate multimedia for each learning context.
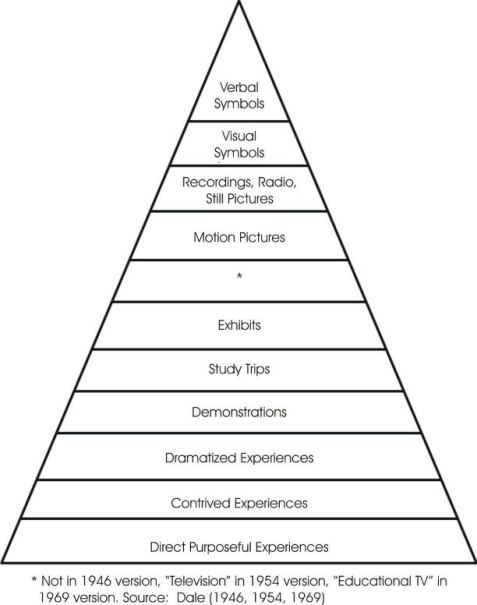
Dale's (1946, 1954, 1969) Cone of Experience (CoE) is an icon of instructional design theory. Counts (2004, p. 2) called it an “influential and widely used model for the planning and use of instructional media.” The CoE shown in Figure 1 is a visual analogy to illustrate the progression of learning experiences from direct, firsthand participation to purely abstract, symbolic expression (Dale, 1969). Ausburn and Ausburn (2008b) asserted that Dale's CoE is based in the propositioning Piagetian psychology of concrete versus abstract reason. They provided the following description of the CoE.
[It] . . . proposed that (a) various types of learning experiences and media representations vary in their “concreteness,” (b) more concrete forming experience and media are truer and more complete representations of reality, and (c) media epresentations that are more concrete can facilitate learning, particularly when reality is complex and unfamiliar to learners. (p. 62)
Figure 1. Dale's Cone of Experience
Dale's CoE shows the level of abstraction for various types of learning activities to help educators design appropriate instructional materials using audiovisuals. The base of the CoE or lowest and least abstract level is “Direct Purposeful Experiences” where students participate directly in an activity and use their senses to help them learn. The highest and most abstract level of experience is “Verbal Symbols” where students use written symbols to express a concept. For example, H2O represents the chemical compound for water which shows that water consists of two hydrogen atoms bonded with one oxygen atom. H2O is a symbolic representation of water.
Dale emphasized the CoE was not designed to attribute worth to a particular level, such as the top being better than the bottom or vice versa. In some learning contexts, more direct interaction may be needed, such as when the learner has no previous experience or foundation with a subject. In other learning contexts, symbolic expression may be preferred, such as when a graduate chemistry student no longer needs direct experience and uses the symbol CO2 instead of the words carbon dioxide.
Dale's focus was on the experience of the learner, although he admitted his placement of learning experiences on the CoE hierarchy was based on their level of abstraction. However, the impact of experiences can vary between learners and some experiences may be quite similar such as study trips and exhibits. Therefore, level of abstraction appears to be a more relevant way to classify the levels, rather than by experience which can be very subjective. The main differences may lie not in the nature of the media components, but rather in their design.
Some current forms of multimedia were not readily available to teachers when Dale proposed his CoE. For example, Virtual Reality (VR) is a relatively new element of multimedia available to educators today which has the potential to show very realistic simulations of things like airplane cockpits and operating rooms (Ausburn&Ausburn, 2008a). Some of the elements in the original CoE are not as relevant today as they were at the time the CoE was first developed. These include, for example, contrived experiences, study trips, exhibits, and educational television. Seels (1997, p. 358), who was mentored by Dale, wrote, “While the direct to vicarious and purely symbolic experience continuum is still valid, the cone is dated in its description of media.” According to Richey, Klein, and Tracey (2011, p. 86), “One could easily update the Cone by substituting modern technology.” Dale's CoE needs to be updated for today's technology and learning context.
Figure 2 shows the conceptual framework for this analytical study. Baddeley's Working Memory Theory, Paivio's Dual Coding Theory, and Sweller's Cognitive Load Theory all contributed to Mayer's (2009) Cognitive Theory of Multimedia Learning. Combining Dale's Cone of Experience and Mayer's Cognitive Theory of Multimedia Learning led the present researchers to develop a new Multimedia Cone of Abstraction (MCoA) which is designed to update Dale's CoE. The proposed MCoA provides guidelines for instructional designers using multimedia, particularly via computer, to enhance learning. The proposed MCoA focuses on learning experiences based on their media components and the level of abstraction required of users. The new model has important implications for instructional designers using technology to enhance education.
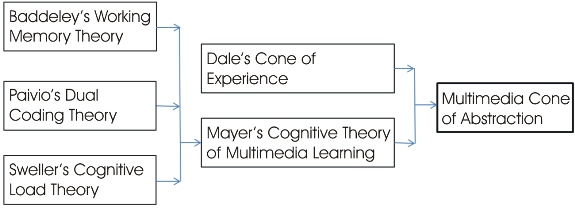
Figure 2. Conceptual Framework of Proposed New Multimedia Cone of Abstraction
Mayer (2009) gave 12 research-based principles for designing effective multimedia presentations which are based on his Cognitive Theory of Multimedia Learning.
Mayer's theory was derived from three other theories: Baddeley's Working Memory Theory, Paivio's Dual Coding Theory, and Sweller's Cognitive Load Theory. These three theories are summarized next.
According to Baddeley's Working Memory Theory (Baddeley 2007; Baddeley & Hitch, 1974), humans have a limited capacity to process information in memory channels. Baddeley theorized there are three subcomponents of working memory: the phonological loop for handling speech-based information, the visuospatial sketch pad for handling visual images, and the central executive responsible for controlling attention. There are two primary memory channels: verbal and visual. An important tenet of this theory is that multimedia designs should not overload a learner's memory channels or learning will be reduced.
According to Paivio's (1971, 1986, 2007) Dual Coding Theory, text and graphics are encoded into two functionally independent but interconnected memory systems: verbal and nonverbal. Learning is more effective when one channel is not overloaded and when both channels are used to reinforce concepts. For example, the verbal channel can be overloaded when the learner is reading text and listening to narration that differs from the text. However, if the learner is viewing a graphic containing few if any words, while listening to narration describing the graphic, both channels are used which reinforces the concept and helps the learner form a mental representation of the concept. Paivio's theory proposes that multimedia designs should use both channels and avoid overloading either one.
According to Sweller's Cognitive Load Theory (Chandler & Sweller, 1991; Sweller, Ayres, & Kalyuga, 2011), instructional materials should not overload a learner's mental processing. For example, having a figure on one page and the text describing the figure on a different page increases the mental integration required by the learner which increases the cognitive load and reduces learning. An example of unnecessary redundancy which increases cognitive load is the simultaneous presentation of written text with narration that repeats the written text. Kalyuga, Chandler, and Sweller (2004) experimentally showed that narration with redundant on-screen text actually reduced learning in a multimedia environment. Sweller's theory proposes that multimedia designs should eliminate unnecessary processing for the learner.
Multimedia has become an important element in instructional design. Multimedia instruction can be defined as “the presentation of material using both words and pictures, with the intention of promoting learning” (Mayer, 2009, p. 5). The multimedia principle states that “people learn better from words and pictures than from words alone” (Fletcher & Tobias, 2005). Multimedia can be used to effectively communicate complex concepts. It has become easier to develop and use multimedia technologies because of advancements in both hardware and software. Multimedia can refer to sensory modalities such as text vs. narration, representational modes such as graphics vs. text, or delivery media such as paper vs. computer (Mayer & Moreno, 2002).
Because of the ubiquity of using computers to display instructional content, it is assumed for this paper that multimedia specifically refers to materials that can be displayed on a computer. That assumption necessarily limits the senses that can be used in materials delivered by computer to visual and auditory. This means some of the elements in Dale's CoE would not be appropriate in a computer-based learning environment. For example, a study trip where students physically travel to another location is not included in the updated CoE for the specific context defined here. However, today's VR technology, included in the MCoA, allows students to virtually travel to other locations.
There is growing research that shows learning is enhanced by well-designed multimedia presentations compared to text-only (Mayer, 2003). However, not all forms of multimedia are equally preferred in instructional settings. For example, it is often naturally assumed that dynamic visuals such as videos and animations are superior to static visuals (dynamic media hypothesis) such as photographs and drawings because of their ability to show temporal relationships (Hegarty, 2004; Lowe, 1999). The transient nature of dynamic visuals can help learners develop dynamic mental models (Kozma, 1991). Many studies have found that students prefer dynamic over static visuals (e.g., Smith & Woody, 2000), and there is a small but statistically significant improvement in learning (e.g., Rieber, 1991). Höffler and Leutner (2007) did a meta-analysis of 26 primary studies that compared dynamic and static visualizations and found a statistically significant advantage for animations over static pictures. Lin and Dwyer (2010) found a statistically significant learning advantage measured with four different types of tests for students viewing animations compared to those viewing static pictures. These studies supported the dynamic media hypothesis by demonstrating the superiority of dynamic over static visuals.
However, other studies have shown no significant difference between learning with and without multimedia (e.g., Lewalter, 2003). In some cases, a reduction was actually found in learning with multimedia compared to learning without multimedia (e.g., Lowe, 1999). Mayer, Hegarty, Mayer, and Campbell (2005) conducted four experiments on technical topics, such as lightning formation, in which one group of learners had annotated illustrations and the other group had narrated animations. The annotated illustration group did as well as, if not better than, the narrated animation groups, which supported the static media hypothesis that static media are superior to dynamic media for learning. Tversky, Morrison, and Betrancourt (2002) questioned those studies showing an advantage for dynamic over static visuals because the visuals may not have been informationally equivalent or there may have been some confounding variables.
Other studies have found mixed results in comparing static and dynamic visuals, depending on learner characteristics. Schnotz, Böckheler, and Grzondziel (1999) found empirically that animations aided learning in one type of learning, but that static pictures provided superior learning in most conditions tested. This can possibly be explained by the increased extraneous cognitive load caused by the animations compared to static pictures.
There is currently no consensus among media researchers that dynamic visuals such as animations enhance learning (Mayer & Moreno, 2002). This may be at least partially explained by the increased cognitive load on the learner caused by dynamic visuals compared to static visuals within a given (usually short) time period (Hegarty, 2004; Lewalter, 2003). Viewers may look at a static visual for as long as they want, while non-interactive dynamic visuals such as videos are transitory and play automatically at a predefined rate (Höffler, Prechtl, & Nerdel, 2010). In this paper, interactive dynamic visual means more than the ability to merely start and stop the visual; it also includes the capability to move to a specific frame, change the playing speed (i.e., slower or faster), and to zoom in or out. While viewers may replay a dynamic visual, they often do not take advantage of this capability, which means they may miss some details. An important advantage of interactive dynamic visuals such as VR compared to non-interactive dynamic visuals such as animations is that the learner controls how the visual is displayed (Hegarty, 2004). A possible explanation why dynamic visuals may not be superior to static visuals is related to the viewer's previous knowledge of the subject, where novices often lack sufficient background to process complex information from animations quickly enough (Lowe, 1999). A further possible explanation why dynamic visuals may not be superior to static visuals is a reduction in the degree to which learners engage in processing activities (Lowe, 2003). These studies show there is no current consensus regarding what type of multimedia is best for learning.
Based on current research, there is no clearly superior multimedia type for all learning contexts that enhances learning more than other types. This is a complex issue requiring further research. Clark and Lyons (2011, p. 10) argued that “prior knowledge of the lesson content is the most important individual difference affecting the value of graphics.” It may be that learner characteristics such as spatial ability have a large influence on what type of multimedia is preferred by a particular learner. In the absence of clear differences for enhancing learning, it appears that level of abstraction is a valid approach to ranking different types of multimedia. Level of abstraction was used as the ranking basis for placing various media formats in the hierarchical MCoA in this paper.
Figure 3 shows the proposed MCoA designed to update Dale's CoE specifically for the use of multimedia in a learning context. The closer to the bottom of the cone, the more realistic the representation; the closer to the top, the more abstract. The choice of a cone helps symbolize that multimedia towards the bottom is likely to be effective for more learners, compared to the top where fewer learners possess the knowledge and experience needed to process information in those forms. The levels in the MCoA are consistent with Mayer's Cognitive Theory of Multimedia Learning. There are some relationships among some of the levels which could potentially have been combined, but have been purposely separated. For example, nonverbal audio and narration both involve sound, and symbols are a specific subset of images and text. However, they are distinct forms of multimedia and therefore have been kept separate here. As will be shown, there are numerous potential combinations of these levels.
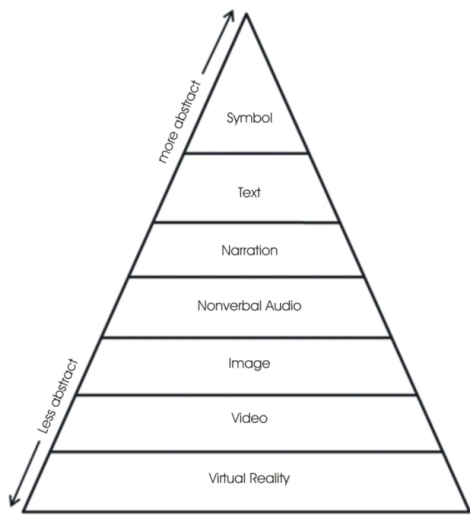
Figure 3. Proposed Multimedia Cone of Abstraction
The lowest and least abstract level on the MCoA is Virtual Reality. There are two basic types of VR: real and simulated. Real VR is a user-controllable virtual reality simulation using actual images such as photographs of things like objects or scenes. Today's VR is so realistic that the experience is almost like being there. Simulated VR is also a user-controllable virtual reality simulation, but using simulated graphics, such as computer-aided drawings, instead of actual photo-real images. While today's drawings can be very realistic, they are not quite as realistic as actual photographs and are therefore more abstract. However, in some learning contexts it may be preferable to use simulated VR because the images could be colored or cut away to highlight specific areas. While actual images can be colored as well, they are then no longer “real” because they have been altered. It is not usually as easy to cut away a real image as it is with a simulated image. For example, it would only be possible to “cut away” a mannequin or cadaver if one is interested in looking inside the human body for an anatomy class. It would not be possible to cut away a living creature to look inside for instructional purposes without injuring or killing the specimen. In that case, a simulated VR consisting of representational images may be preferred.
It might be argued that the next level, Video, should be considered less abstract than VR. However, user-controllability makes VR less abstract than video in a learning environment. With video, the user generally only controls the speed and time sequence of the display (e.g., start, stop, rewind, fast forward), but not the location being viewed (i.e., it has no pan or zoom capability). VR has the added feature that the learner not only controls the speed and time sequence, but also the location being viewed (e.g., zoom in, zoom out, pan left, pan right, pan up, pan down). Further, while learners control the speed and time sequence of a video, in actual practice this capability is rarely used as previously discussed. However, in VR the user must control those functions or the image will not move, so learners are forced to control what they are viewing, which typically means they will move at a pace they are most comfortable with and not at the preset pace (e.g., 30 frames per second) of a typical video.
Image is a static graphic that may be in multiple formats. Real images are static graphics (e.g., photographs) of an actual object or scene. Simulated images, such as drawings, are representations of real images. Images have dimensionality and may be two-dimensional (2D) or three-dimensional (3D). While it might be assumed that more detailed 3D drawings would be superior to less detailed 2D drawings, Butcher (2006) experimentally found that a simplified 2D drawing actually promoted more factual learning than a detailed 3D drawing in the study of the heart and circulatory system. Another aspect of images is that they may be black-and-white or color. While color is often preferred, in some instances it can be overused where too many colors could overload the learner. Pett and Wilson (1996) found there is no significant improvement in learning with color compared to black and white. Tufte (1990) noted that while some people are capable of distinguishing 20,000 different colors, using more than 20 to 30 colors may not only have a diminishing returns effect, but may actually have a negative effect on the viewer. Fewer colors or even black-and-white might be better in some learning contexts, to avoid cognitively overloading the learner.
In the proposed MCoA, Nonverbal Audio refers to sound other than narration, which is treated here as a verbal form at a higher level of abstraction. Nonverbal audio could, for example, be produced during everyday life such as the sounds of traffic in a city. Audio could also be produced by devices designed specifically to make sound, such as musical instruments. Then, there are two types of audio: real and simulated. Real audio is a recording of actual sound, while simulated audio is produced, for example, by a computer which can be used to recreate sounds such as from electronic instruments. Nonverbal audio has the added features of dimensionality where the sound could be mono (1 channel), stereo (2 channels), or surround-sound (multiple channels) and frequency (bass, mid-range, and treble).
In general, images are considered to be more concrete than nonverbal audio. Consider the adage that “a picture is worth a thousand words” and compare that to a recording of sounds. In most cases, images clearly depict something readily identifiable to the viewer. Pure sound recordings (with no narration) are usually more challenging to identify compared to images and therefore more abstract. However, there may be circumstances where a sound recording could be more concrete than a particular image. For example a photograph of a car would be less concrete than the recording of a car horn blasting which cannot be discerned in a photo. Then, the levels in Figure 3 are intended to provide the instructional designer with guidelines rather than rigid rules.
Narration is a specific verbal (auditory) form using spoken language with no images or text. Narration is less abstract than the next level “Text” because the spoken language includes changes in volume and tone that contain additional meaning compared to written words (Mayer, Hegarty, Mayer, & Campbell, 2005). Other aspects of narration include the pace (speed the words are spoken) and the diction of the narrator.
Text is a verbal form that refers to written words. This may be as simple as a bulleted list or as complicated as a textbook. The assumption is that the language is familiar to the learner, although advanced vocabulary or a language that is not the primary language of the learner can make text even more abstract. The challenge with pure text is that the learner has fewer queues, such as facial expression or voice inflections, to determine what the author means. This makes it more abstract than images and narration. There are also many aspects of text that impact learning such as the font type and size, capitalization, paragraph justification, and the use of white space. For example, using an unusual font type, too small a font size, or too little white space can make text difficult to read (Lohr, 2008) and unnecessarily increase the cognitive load on the learner.
Symbol is the most abstract level and requires special prior knowledge by the learner for interpretation. There are two primary types of symbols: visual and verbal. A visual symbol refers to a graphic that is often short-hand notation for something. For example, a circle with a slash diagonally across it on top of an image is a universal symbol that means do not do whatever is in the image. For example, an image of a cigarette with smoke rising from the lit end that has a circle with a slash on top of it means the area is non-smoking. A pure visual symbol does not have any textual characters and is a more abstract form of a typical image. The learner must be familiar with the symbol for it to be meaningful which is why it is considered more abstract than a non-symbolic image. Visual symbols may be specific to an industry and need to be learned by those working in that industry. For example, an image of a person standing under a shower is the symbol for a safety shower in a chemical plant. Those working in that plant need to know what that means in case they ever need to wash off potentially dangerous chemicals. A verbal symbol is usually short-hand notation for something more complex. The example previously given is the verbal symbol for water which is H2O. This can be further refined to show the state of the water: H2O(s), H2O(l), and H2O(g) refer to water in the solid (ice), liquid, and gaseous (steam) states, respectively.
Within a given level of the MCoA, there may be many sublevels. For example, possible sublevels for the Video level include those shown in Figure 4. The Video sublevels are combinations of video type (simulated or real), dimensionality (2D or 3D), and verbal type (none, text, narration). Simulated Video (better known as animation) is where the dynamic representation uses moving simulated graphics such as computer-aided drawings. Real Video is a moving (dynamic) representation using actual images, such as those taken with a movie camera. Using today's technology, special glasses are typically required to view 3D videos, whether real or simulated. A verbal component may or may not be present and, if present, it could be in the form of narration, text, or both.

Figure 4. Possible Sublevels within the “Video” Level of MCoA Listed from Most Abstract (top) to Least Abstract (bottom)
Not all of the sublevels shown in Figure 4 satisfy Mayer's Cognitive Theory of Multimedia Learning. For example, Baddeley's Working Memory Theory and Paivio's Dual Coding Theory do not recommend using both narration and a substantial amount of text together as they would overload a learner's verbal memory channel. A more effective use of both would be, for example, text labels identifying component parts, with narration that explains each component.
The Video sublevels could be even further expanded if, for example, audio (other than narration) and color (black-and-white, color) were included. The audio would be sounds relevant to the content, but not simply background music as that would violate Mayer's Coherence Principle where extraneous content should be avoided as it distracts the learner. An example of relevant audio might be the sound of a jet engine if the content concerned jet engine maintenance. The volume would likely need to be appropriately reduced as jet engines are very loud. However, because most people are familiar with that sound, it may be preferable to deliberately exclude it as it could be argued it does not add anything substantive to learning and may even reduce learning by distracting the learner.
The MCoA proposed in this paper demonstrates the many levels of abstraction that are available to the instructional designer of educational content. The appropriate amount of abstraction depends on both the subject matter and on the prior knowledge of the learners. For example, students with no prior background in a subject area will likely need less abstract multimedia initially, but will be capable of more abstract multimedia as their knowledge of the subject increases. This is consistent with the Piagetian conceptualization of human development of abstract reasoning competency. Materials need to be tailored to the knowledge level of the learners, which is referred to as the prior knowledge principle (Kalyuga, 2005). No single level will be appropriate for all topics. In addition, some levels may not be appropriate for all learners. For example, more visually-oriented learners may prefer virtual reality, while more verbally-oriented learners may prefer narration and text. In a meta-analysis, Höffler (2010) showed that spatial ability is important when working with visualizations. To reiterate Dale's caveat, the proposed MCoA is not intended to rank multimedia types from best to worst, because no single level is best for all learners, subjects, and contexts. It is intended to give some guidance to instructional designers.
In some ways, the proposed MCoA is simpler than Dale's Cone with only seven levels compared to Dale's eleven in his final 1969 version of the CoA. In other ways, the MCoA is much more complicated with numerous sublevels. One of the criticisms of Dale's CoA is that it is not based on empirical evidence (Subramony, 2003). The proposed MCoA is based on voluminous experimental data collected by Mayer and co-workers that were used to develop the Cognitive Theory of Multimedia Learning. As Dale noted with his Cone, the proposed MCoA is not intended to be prescriptive, but rather to identify the range of possibilities. The MCoA is generally hierarchical according to level of abstraction, where the levels represent a continuum rather that discrete elements. In some cases, the levels overlap and may even change places depending on the actual content and learning context.
Instructional designers of educational materials have many choices for incorporating multimedia into course content as shown by the proposed MCoA. There may be many sublevels within a given level. An important factor in the appropriate choice of multimedia is the learner's level of expertise (Sweller, 1999). For example, details that may be redundant for experts and should be excluded because they unnecessarily increase cognitive load, may need to be included for novices because they may not be knowledgeable about those details. Instructional designers need a range of multimedia tools, particularly for classes containing both novices and experts. Sweller et al. (2011, p. vii) wrote, “the aim of instructional design is to facilitate the acquisition of knowledge in long-term memory via a working memory that is limited in capacity and duration until it is transformed by knowledge held in long-term memory.” Skilled instructional designers should select the appropriate multimedia to facilitate knowledge acquisition by the learner based on the learner's knowledge of the topic.
Much work remains to be done concerning learning effectiveness for various types of multimedia, particularly whether certain types are more effective than others and if so under what conditions and for which learners. Unless and until certain multimedia types are found to be more effective, research is recommended to determine learner multimedia preferences, so materials can be designed accordingly. Despite possible learner preferences, using only a limited number of multimedia types is not likely to be effective either, as learners should be exposed to many types as they are likely to be exposed to most of them at some point in their professional lives. Continued use of a limited number of multimedia types in a course could reduce learning because the learners may lose interest, particularly if the multimedia being used does not appeal to their preferences. For example, showing only text would quickly become tedious. Showing too many multimedia types could also be problematic by distracting learners who could focus too much on the multimedia and not enough on the content. Another factor which has not been discussed here is the time and cost effectiveness of developing each type of multimedia. VR requires special hardware, software and training to create, compared to text which is fast, easy, and ubiquitous. At this time, even if it turned out that VR significantly enhanced learning compared to other multimedia types, it is not realistic that all content could or even should be created using VR. Because of continuous changes in educational technology, this is an area of research that needs to be continuously updated to determine the relative effectiveness of each type of multimedia.