Figure 1. Basic FFNN Structure
Soft computing Artificial Neural Networks (ANN) represent a family of statistical learning models inspired by the biological nervous systems for approximating functions based on large number of unknown inputs. Artificial Neural Networks are comprised of simple processing Neuron elements that possess numeric weighted interconnections arranged in a layered fashion, which can be tuned to make them adaptive to the given inputs. Hardware architectures for implementation of soft computing multi layer perceptron type feed forward artificial neural networks (MLPFFNN) targeting Field Programmable Gate Arrays (FPGA) are presented. Hardware realization of ANN, to a large extent depends on the efficient implementation of a single neuron. Parallel digital system MLPFFNN architecture is designed in Verilog HDL language. The fast processing tendency of parallel neural network architectures makes them more suitable for implementation in VLSI technology. FPGA realization of ANNs with a large number of neurons is still a challenging task. The proposed neural network architecture is implemented in two phases; First phase includes training the neural network using MATLAB program, the second phase of implementation included the hardware implementation of trained parallel neural network targeting Xilinx high performance Virtex family FPGA devices. Hardware realization of ANNs with a large number of neurons is still a challenging task.
Artificial Neural Networks (ANN) are biologically inspired parallel distributed computation systems widely used in problems pertaining to broad spectrum of applications involving huge quantities of data for image perception, recognition and classification etc. The learning capabilities of artificial neural networks (ANNs) enable them to receive several inputs at a time and distribute them in an organized manner to the processing Neuron units for improving performance and reliability of the implemented systems. Application of neural networks to real time applications is made possible only with the realization of new low cost and high speed neural computing architectures. Most of the ANN implementations are purely based upon soft computing simulation based software models that are relatively slower than the hardware based ANN implementations [1],[2].
Hardware architectural designs of Neural Networks can be implemented using analog and digital systems. Analog implementations are focused more on exploiting the nonlinear characteristics of Complementary MOS devices however the digital implementations are highly accurate ensuring better repeatability, less noise sensitivity, better testability and compatibility with other systems. Digital ANN implementations are classified as FPGA-based implementations, DSP-based implementations and ASIC-based implementations. DSP implementations are sequential in nature and does not preserve the parallel architecture of neurons while the ASIC implementations does not offer re-configurability to the end users, While, FPGA implementations obviously preserve the parallel processing architecture of neurons within the layers and between the layers offering flexible design architectures promoting the possibility of reconfigurable designs [3].
Artificial neural networks are characterized by densely interconnected arrangement of neurons in the form of multilayered network structure. Such structure enables neural networks to learn and solve problems, based on the number of layers in the network and the number of neurons per layer in association with the adopted activation functions. From the structural point of view, Artificial Neural networks are classified as Feed Forward Neural Networks-in which computation is performed in layer by layer fashion proceeding from the input to the output of the network from layer to layer; while the Recurrent Neural Networks contain an interconnected Network structure including cycles. Operation of ANNs involves the learning and training stages respectively. In the learning stage the NN weights are updated based on the Backpropagation training algorithm adopted for the application in hand [4] [5].
Multilayer perceptron type feed forward neural network (MLPFFNN) is the simplest ANN architecture in terms of the direction of information flow and many neural network architectures are variations of the feed forward neural networks consisting of a number of layers. Each layer in turn contains a number of synapses. Traditionally, first layer is called the input layer, the last one the output layer and the one between those two can be regarded the hidden layer [6].
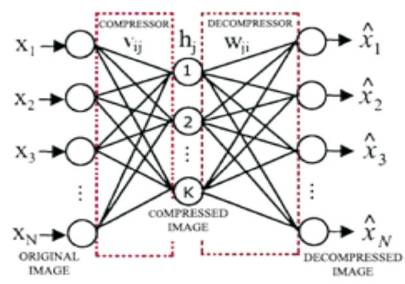
In the MLPFFNN architecture shown in Figure 1, input vectors from large number of neurons in the input layer are fed to a less number of hidden layer neurons and subsequently fed to large number output layer neurons of the network. The number of interconnections between any two layers of the NN is obtained by multiplying the total number of neurons of the two layers and adding the number of bias neurons connections of the second layer (bias connections of a layer is equal to the number of layer neurons) .If there are Ni neurons in the input layer, Nh neurons in the hidden layer and No neurons in the output layer, the total number of connections is given by the equation:
Network Size:(Nw)= [(Ni*Nh)+Nh]+[(Nh*No)+No]
Figure 1. Basic FFNN Structure
Proposed parallel MLPFFNN hardware architecture is considered for image compression application clearly illustrating the hardware architectures for image compression as well as decompression- as shown in Figure 2 and Figure 3 below. After appropriate training of the neural network, weights and bias values are used for modeling a 16-4-16 neural network architecture. The hidden layer consists of 4 neurons while the input layer and the output layer contain 16 neurons each [7], [8].
First set of 8 bit input samples, each of size 16 x 1 is stored in the intermediate memory. Multiplier blocks perform the product of input samples with weights and accumulate the partial products in adder array. Further, the accumulated data is added with the bias values and fed to the network function (which is implemented in form of a look up table in this work). Output of bias forms the address of LUT and corresponding ROM element. Precomputed outputs are read out from ROM in accordance with the network function (Tansig) and stored in output memory [9].
Decompression unit (Shown in Figure 3) consists of input memory, multiplier, adder and bias units. Output of bias is fed to the network function (Purelin) and decompressed data is stored in output memory [10].
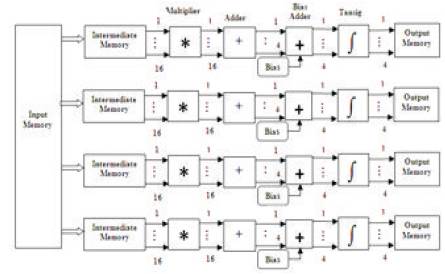
Figure 2. Parallel Hardware FFNN Architecture for Image Compression
Simulations results of hardware model for each sub block of neural network are performed in VCS (Verilog Compiler Simulator). The functionality of hardware models are verified with Chip Scope Pro and synthesized using Xilinx ISE and implemented on Virtex-5 FPGA board [11].
The Chip Scope pro simulations for the compressed output at hidden layer as well as the decompressed data at the output layer are also performed. However, Chip scope pro simulation results of top module comprised of the Hidden layer and Output layer is shown in Figure 4.

Figure 3. Parallel Hardware FFNN Architecture for Image Decompression
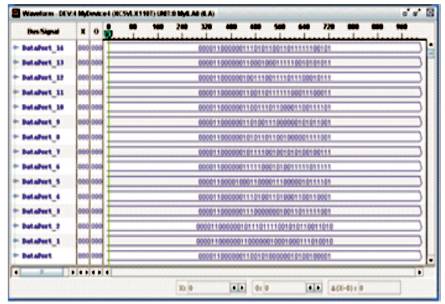
Figure 4. Top Module Simulation Results in ChipScope Pro
Synthesis results of proposed implementation is shown in Table 1.
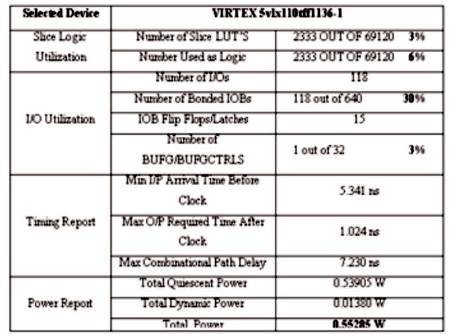
Table 1. FPGA Synthesis Results
New parallel MLP Neural Network architecture is designed, and implemented targeting to Xilinx Virtex family FPGA device. Wallace tree based arithmetic is used for multiplication in the hardware architecture. Architecture on FPGA is found to operate at a maximum speed of 138 MHz consuming power of 55.285mW and occupying 3% of the resources. This design can be further enhanced by exploiting the redundancies associated within the weight matrix for further optimization of area and hence the power and time as well. Proposed architecture can be targeted for ASIC implementation for low power design applications. The proposed architecture may be implemented for high speed applications incorporating pipelining based designs using Distributed Arithmetic (DA) concepts as well as modified DA based designs for low power applications.