Table 1. Comparative Analysis of The Proposed Image Compression Approach
The need for an efficient technique for compression of images is ever increasing because, the raw images need large amounts of disk space where seem to be a big disadvantage during transmission and storage. Even though, there are so many compression techniques already present, a better technique which is faster, memory efficient and simple, surely suits the requirements of the user. We have planned to design the hardware design flow of Distributed Arithmetic (DA) based 2-D Adam7 algorithm for the proposed image compression algorithm. Accordingly to, an effective 2-D Adam7 algorithm will be performed on input image using well-known Distributed Arithmetic (DA) technique, which exploits the LUT-based FPGA structure to build multiplier-less filter bank, the main component in a Adam7 structure. After computing the Adam7 algorithm, the suitable Adam7 co-efficient is selected and then, applied DPCM (Differential Pulse-Code Modulation) that is a transformation for increasing the compressibility of an image. Finally, the transformed image is given to Huffman-encoder that is designed by merging the lowest probable symbols in such a way that, the images will get compressed. For implementation, the DA-based Adam7 Algorithm is modeled in Simulink and tested. The Verilog source code is developed for the algorithm. All the modules are simulated in Xilinx tool and the final design is verified with Verilog test benches. The final design is implemented in Xilinx Atlys Spartan 6 FPGA Kit.
One major problem that happens during the transmission and storage of raw images is the necessity for giant amount of disk space. Thus, there is an ever-increasing need for a very potent and robust technique for compression of such images. A better compression technique that is faster, memory efficient, and simple can definitely satisfy the requirements of the user. Generally, Image compression refers to the compression of data on digital images. Principally, its goal is to diminish the redundancy of the image data in order to store or transmit the data in an effective manner as well as to provide a best image quality at a given bit-rate (or compression rate).Two types of compression techniques often employed for image compression are: Lossless and Lossy. The lossy compression that produces indiscernible differences can be called as visually lossless. In lossless image compression, the compression ratio obtained is extremely low and so, considerable resources cannot be saved by using such image compression. The image compression technique with compromising resultant image quality, without much notice of the viewer is the lossy image compression. The loss in the image quality increases with the percentage of the compression, hence results in saving the resources. In recent years, the Adam7 theory and its application in image compression has progressed rapidly. The field of Adam7 is still sufficiently new and further progressions will continue to be reported in several areas. One of the most imperative processing components of image compression is Adam7 transform.
According to the study, the proposed compression phase is mainly divided into three sequential steps: (1) Adam7 Transform, (2) Quantization, and (3) Entropy Encoding. After preprocessing, each component is independently analyzed by an appropriate discrete wavelet transform. Since the emergence of JPEG 2000, considerable attention has been paid to the development of efficient system architectures of Adam7.FPGA implementations can accelerate Adam7 by pipelining these Operations. Several VLSI architectures based on Adam7 have been designed and implemented in order to achieve real-time signal processing. There is much architecture proposed for the implementation of Adam7 Algorithm. For the 1-D Adam7, the architectures can be categorized into the convolution-based, lifting-based, and B-spline-based. The first one is to implement two-channel filter banks directly. The second one is to exploit the relationship of low pass and high pass filters for saving multipliers and adders. The third one can reduce the multipliers based on the B-spline factorization. The B-spline-based architectures could provide fewer multipliers while the lifting scheme fails to reduce the complexity.
In Adam7 image compression, after applying the transform, quantization, which is a lossy compression technique achieved by compressing a range of values to a single quantum value is performed. When the number of discrete symbols in a given stream is reduced, the stream becomes more compressible. For example, reducing the number of colors required to represent a digital image makes it possible to reduce its file size. Specific applications include DCT data quantization in JPEG and Adam7 data quantization in JPEG 2000. After the quantization, the quantized Adam7 coefficients are converted into sign-magnitude represented prior to entropy coding because of the inherent characteristics of the entropy encoding process. Entropy coding can yield a much shorter image representation on average by using short code words for likely images and longer code words for less likely images. Entropy encoding, which is a lossless form of compression is performed on a particular image for more efficient storage. Either 8 bits or 16 bits are required to store a pixel on a digital image. With efficient entropy encoding, we can use smaller number of bits to represent a pixel in an image; this results in less memory usage to store or even transmit an image.
A handful of low power architectures are presented in literature for computing the Adam7 co-efficient. The proposed methodology is mainly concentrated on the Adam7-based image compression.
Here, low power architecture is used to compute the Adam7 so that the overall efficiency can be achievable. Initially, here, we have presented some of the low power architecture presented in the literature for Adam7 transform that are mostly based on lifting, distributed arithmetic and spline. Three case studies, including JPEG2000 default (9, 7) filter, the (6, 10) filter, and the (10, 18) filter, were given to demonstrate the efficiency of the proposed architecture. On the other hand, Kai Liu et al. [5] have proposed a VLSI architecture that performed the line-based discrete wavelet transform (DWT) using a lifting scheme. The architecture consists of row processors, column processors, an intermediate buffer and a control module. Row processor and Column processor work as the horizontal and vertical filers respectively. Intermediate buffer was composed of five FIFOs to store temporary results of horizontal filter. Control module scheduled the output order to external memory. Compared with existing ones, the present architecture parallelizes all levels of wavelet transform to compute multilevel DWT within one image transmission time. Furthermore, Wang Chao and Cao Peng [6] have proposed a Decomposed lifting algorithm (DLA), in which the image data was processed in raster scan manner both in row processor and column processor. Theoretical analysis indicated that the precision of DLA outperformed other lifting-based algorithms in terms of round-off noise and internal word-length. An efficient line-based architecture was designed to perform 2D DWT based on DLA with high performance and low memory by eliminating the implementation of data buffer. For an N*N image, only 4N internal memory is required for 9/7 filter with output latency of 2N clock cycles. Compared with related 2D DWT architectures, the size of on-chip memory and output latency were reduced significantly under the same arithmetic cost, memory bandwidth and timing constraint.
Xixin Cao et al. [4] have proposed an efficient and simple architecture for 9/7 Discrete Wavelet Transform based on Distributed Arithmetic. To derive the proposed architecture, they considered the periodicity and symmetry of DWT to optimize the performance and reduced the computational redundancy. The inner product of coefficient matrix of DWT was distributed over the input by careful analysis of input, output and coefficient word lengths. In the coefficient matrix, linear maps were used to assign the necessary computation to processing elements in space domain. Moreover, the proposed architecture has regular data flow, and low control complexity. The result was low hardware complexity DWT processors for 9/7 transforms, which allows two times faster clock than the direct implementation. This design was very suitable for image compression systems, e.g., JPEG2000 and MPEG4. Mohsen Amiri Farahani and Mohammad Eshghi [7] have implemented the design of the Discrete Wavelet Packet Transform with efficient hardware acceleration. This design worked based on the word serial pipeline architecture and the parallel filter processing. For accelerating in the Discrete Wavelet Packet Transform, a high-pass filter and a low-pass filter were used concurrently in each level. Using parallel filters makes possible that this design works two times faster than the design introduced in [8]. This architecture was implemented using internal multipliers of the FPGA and results of these implementations for the different filter lengths were presented. This high speed architecture was suitable for on-line applications and can be implemented for the Direct Wavelet Packet Transform with any levels of tree.
C. T. Huang et al. [2] have presented a detailed analysis of very large scale integration (VLSI) architectures for the one-dimensional (1-D) and two-dimensional (2-D) discrete wavelet transform (DWT) in many aspects, and three related architectures were proposed as well. The 1-D DWT and inverse DWT (IDWT) architectures were classified into three categories: convolution-based, lifting based, and B-spline-based. They were discussed in terms of hardware complexity, critical path, and registers. As for the 2-D DWT, the large amount of the frame memory access and the die area occupied by the embedded internal buffer became the most critical issues. The 2-D DWT architectures were categorized and analyzed by different external memory scan methods. The implementation issues of the internal buffer were also discussed, and some real-life experiments were given to show that the area and power for the internal buffer were highly related to memory technology and working frequency, instead of the required memory size only. Besides the analysis, the B-spline-based IDWT architecture and the overlapped stripe-based scan method were also proposed. Last, they proposed a flexible and efficient architecture for a one-level 2-D DWT that exploits many advantages of the presented analysis.
While analyzing the literature, several VLSI implementations are presented for image compression. According to, Kumar Gupta, A. et al. [9] they have presented the VLSI design of a Block Coder (BC) system that can process 21 mega pixels per second. For the Bit Plane Coder (BPC), they employed a Concurrent Symbol Processing(CSP) algorithm to process of all 4 sample locations within a stripe-column in a single clock cycle during a pass. The BPC produced on average, 1.21 Context Data (CxD) pairs per clock cycle. In addition, they have designed an Arithmetic Coder (AC) that processed 2 CxDs/clock cycle. To allow for an efficient coupling of the proposed BPC and AC modules, they also proposed architecture for an intermediate buffer. The BC chip implemented on TSMC 0.18 micrometer technology, occupied an area of 1.6 mm2, with an equivalent gate count of 95,000 that included 24576 memory bits. Its high processing throughput was the highest ever reported for a JPEG2000 BC engine capable of handling both normal and causal modes of operation.
C. Hemasundara Rao and M. Madhavi Latha [10] have proposed a hybrid image compression technique based on reversible blockade transform coding. The technique, implemented over regions of interest (ROIs), was based on selection of the coefficients that belong to different Transforms, depending on the coefficients. This method allows: (1) codification of multiple kernals at various degrees of interest, (2) arbitrary shaped spectrum, and (3) flexible adjustment of the compression quality of the image and the background. No standard modification for JPEG2000 decoder was required. The method was applied over different types of images. Results showed a better performance for the selected regions, when image coding methods were employed for the whole set of images. Finally, VLSI implementation of proposed method was shown. It was also shown that the kernel of Hartley and Cosine transform gave the better performance than any other model. Isa Servan Uzun and Abbes Amira [11] have presented field programmable gate array (FPGA) implementation of a non-separable 2-D DBWT architecture which was the heart of the proposed High-Definition Television (HDTV) compression system. The architecture adopted periodic symmetric extension at the image boundaries, therefore it conforms the JPEG-2000 standard. Hardware implementation results based on a Xilinx Virtex-2000E FPGA chip showed that the processing of 2-D DBWT was performed at 105MHz providing a complete solution for the real-time computation of 2-D DBWT for HDTV compression.
The following is the justification behind the proposed method.
Ultimate aim of this project is to increase the compression rate along with reducing the power consumption and integrate whole system on FPGA. According to, we make use of the procedure utilized in JPEG/PNG compression. The advantages compared with the JPEG/PN are that we have planned to use DA-based Adam7 algorithm to reduce the power consumption. In addition to, we will choose only most important co-efficient obtained from the high pass filter so that the compression can be improved. This is the modification we have done when we are applying the Adam7 transform.
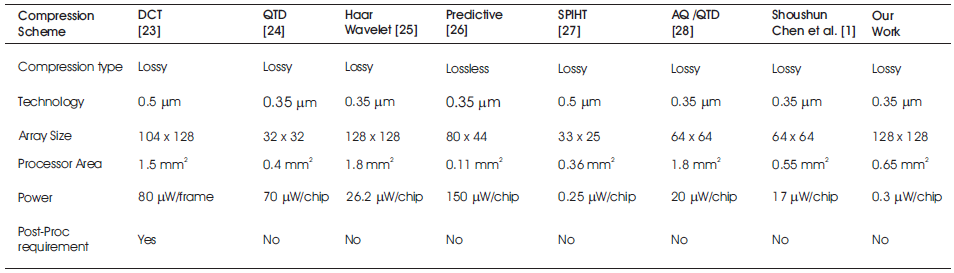
The comparative analysis of the various approaches including Adam7-based image compression algorithm is given in Table 1.
Table 1. Comparative Analysis of The Proposed Image Compression Approach
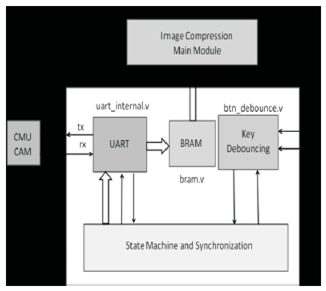
Figure 1. Block diagram of camera interfacing module
Furthermore, DA-based wavelet method is used to ensure the low power consumption. Then, wavelet coefficients are given to DPCM technique that improves the compressibility of image. Subsequently, the bit stream is generated from the transformed coefficients using Huffman coding. Finally, the modules are programmed using Verilog and then, it is synthesized using the active HDL software and simplify pro. The performance of every module is analyzed using the Parameters such as, gate required, clock cycles required, power, processing rate, processing time etc. In addition we have conducted the performance analysis of the proposed architecture with different images. Finally, from the comparative analysis over the previous methods, it is concluded that the proposed method presents good performance in power-efficiency corresponding to 0.3mW/chip, percentage compression depending on the image and processing rate, 11 clock cycles per pixel which can be referred in Table 2.
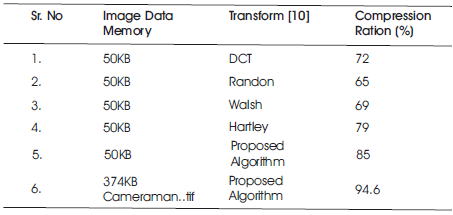
Table 2. Comparative Analysis Of The Proposed Image Compression Approach With Traditional Methods For Compression Ratio
The final design is implemented in Xilinx Atlys Spartan 6 FPGA Kit. Block diagram of camera (CMUcam) interfacing module is seen in Figure 1, in which main module is UART code that works at 115,200 baud rate With CMUcam. Image will be captured and stored in block memory once button is pressed. Finite state Machine of camera interfacing is seen in Figure 2. CMUcam works on commands sent by hardware. When switch is pressed RS (Reset Camera) command is sent. Camera will respond by ACK or NCK. If NCK is received then same command is sent after desired delay (10ms).If ACK is received then CR command is sent to set the camera register value.“CR 18 36” will set color mode to CrYCb mode with white balance on. If NCK is received then same command is sent after desired delay (10ms). If ACK is received then DF (Dump Frame) command is sent. In response to DF command, still image is transferred on serial link which will be stored on memory for further processing.
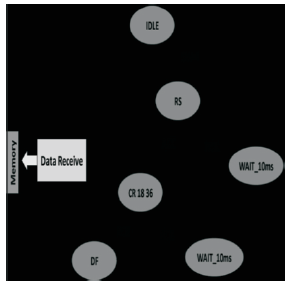
Figure 2. Finite state machine of camera interfacing
Proposed system is implemented in Xilinx Spartan 6 FPGA kit with real time image taken from camera and input bit stream is given to input of image processing main module. The power analysis results can be seen in Figure 3 and output bit stream results are shown in Figure 4 using ChipScope Pro Analyzer tool.
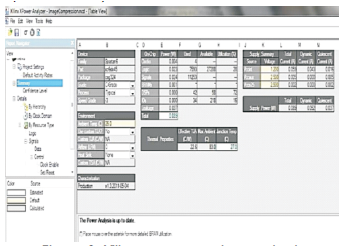
Figure 3. Xilinx xpower analyzer output
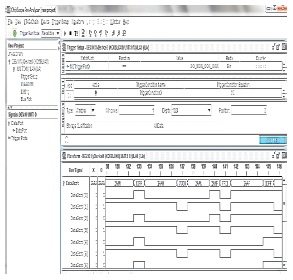
Figure 4.chipscope pro analyzer output
Adam7-based image compression algorithm is developed using well-known Distributed Arithmetic (DA) technique. The DA-based Adam7 method is used to ensure the low power consumption.
Then, the Adam7 coefficients were given to the DPCM technique that improves the compressibility of image. Subsequently, the bit stream was generated from the transformed coefficients using Huffman coding. Finally, the modules were programmed by means of Verilog and then, it was synthesized with the aid of active HDL software and synplify pro. The performance of every module is analyzed using the parameters such as, gate required, clock cycles required, power, processing rate, processing time. In addition to that, performance analysis of the proposed architecture with different images is conducted. Eventually, from the comparative analysis over the prior methods, it is concluded that the proposed method offers good performance than the traditional methods in terms of number of gate required, percentage compression, power and processing rate