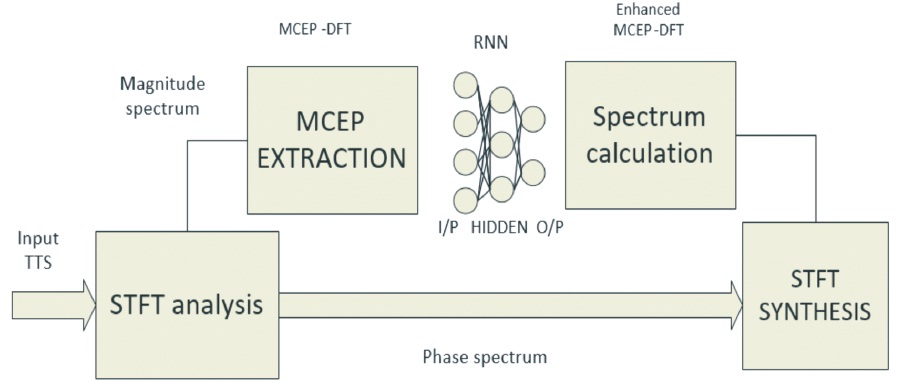
Figure 1. Enhancing the Quality of Speech Using RNN
Most of the present literature on speech enhancement focus totally on existence of noise in corrupted speech which is way from real-world environments. In this project we choose to enhancing the speech signal from the noise and reverberant using RNN and CNN. We trained separate networks for both RNN and CNN with noise, reverberation and both combination of reverberant and noise data. A simple way to enhance the quality of speech is raise the quality of the previous recordings by using speech training with speech enhancement methods like noise suppression and dereverberation using Neural Networks. The quality of voices trained with lower quality data that are enhanced using these networks was significantly higher. The comparison of RNN and CNN is shown and the experimental results are performed using MATLAB tool.
Considerable growth has been undergoing in improving the speech area, especially in using statistical parametric speech synthesis, researches are underway to enhance the quality of recording speech. We observed quality of training data drastically decrease when the data contains noise or reverberant. To boost the quality of speech, one of the ways is to eliminate the distorted signal. But in some cases, this is a bad strategy when there are insufficient data. In this paper, we used speech enhancement by removing additive noise by using the technique called noise suppression. Removing the effects of the room acoustics is called dereverberation.
A lot of literature is available in noise suppression and dereverberation methods within the speech enhancement literature (Naylor, 2010). Statistical models like Wiener filter, spectral subtraction, Kalman filter produces high quality of speech (Vaseghi, 2007). At present most popular method is to use neural networks to map acoustic parameters that are extracted from speech containing noise (Abeßer, 2020).
The block diagram used to enhance the quality of speech using RNN is shown in Figure 1. The magnitude spectrum is derived from Short Term Fourier Transform (STFT), where the N is length magnitude spectrum, we extract M Mel cepstral coefficients, where M < N via truncation (Jiang, 2018). These coefficients are mentioned as MCEP-DFT. The distorted coefficients are enhanced using RNN. These coefficients are then converted in to DCT. Using RNN we get the improved MCEP-DFT coefficients that are converted in to magnitude spectrum using the DCT. Finally, we get enhanced magnitude and phase spectrum this can converted into the speech signal by using the IDFT.
Figure 1. Enhancing the Quality of Speech Using RNN
Here RNN is used to enhanced the speech which is previously trained with MCEP-DFT coefficients that are extracted from corrupted (noise, reverberation and both combination) speech is to reduce the errors between feature extracted from clean speech data and generated features.
Short Time Fourier Transform (STFT) is a continuous periodic signal transform used to determine the magnitude and phase of a signal as it changes over time. In practice, if we take a long sentence at a time it may consist of several variations as speech signal is a nonstationary. Therefore, long sentence are divided into frames of equal length using window technique and then compute the Discrete Fourier Transform (DFT) with each of the short segments. We get the spectrum of each short segment.
Short time Fourier transformation can be seen by two different time origins (NPTEL, n.d.).
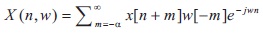
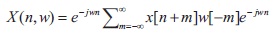
In speech analysis, first convert speech with the pre emphasis signal. Then framing and window technique are applied to get magnitude and phase spectrum from the input signal. From the magnitude spectrum, we extracted the MCEP coefficients. In the synthesis part, we get enhanced MCEP coefficients from RNN. It is then applied to discrete cosine transform to convert it into magnitude spectrum. Then we combined the magnitude and phase spectrum using Inverse Fourier Transform to get our enhanced speech signal (Kinoshita et al., 2015).
MFCC is most used parameters in speech technology development. Mel Frequency Cepstral Coefficients (MFCC) computed from the speech signal using following three steps (Alasadi, 2020):
A long sentence consists of several variations, as speech signal is not stationary. Hence, long sentence is divided into frames of equal length using window technique and then computed with the discrete Fourier transform with each of the segments. We get the spectrum with frequency versus power plot. To extract the Mel frequency cepstral coefficients, use the Mel-space filter-bank and convert spectrum into Mel spectrum (Rabiner, 2012).
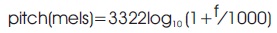
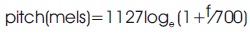
Mel filter bank equation (Rani et al., 2018) is as in Equation 5.
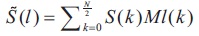
where l=0,1,…….,L-1
 will get the whole range of the frequencies but only L samples.
will get the whole range of the frequencies but only L samples.
is mel spectrum
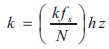
L is total number of triangular Mel weighting filters S(k) is original spectrum
lth filter from filter bank
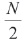 half of the FFT size
half of the FFT size
Now instead of taking uniform bandwidth filter we are taking Mel scale filter. So lower frequencies have narrow bands and higher frequencies have larger bands. Since the spectrum is frequency warped in Mel scale, it is called Mel frequency cepstral coefficients.
In synthesis part, after getting the Mel spectrum, take log of the Mel spectrum because cepstral coefficients have to be calculated using homomorphic decomposition which required logarithm. Then take DCT (Discrete Cosine Transformation) implementation is same like as the FFT but more efficiently by taking advantage of the redundancy in a real signal. Finally, have enhanced Mel frequency cepstral coefficients, which we refer as MCEP-DFT.
Recurrent Neural Network (RNN) comes under the category artificial neural networks. This permits to exhibit dynamic temporal behaviour for a time sequence (Weninger et al., 2014; Weninger et al., 2015).
The next step is to train the neural network. After applying STFT, we get magnitude and phase spectrum. From this, we considered only magnitude spectrum. From magnitude spectrum, extraction of MCEPT-DFT features using framing, Mel-space filter bank and Blackman window technique. per each window frame, we extracted a DFT of 1024 size. We selected this value as it coordinates the quantity of parameters extricated utilizing the STRAIGHT vocoder, a correlation focuses for our characteristics test with additive noise. The contribution of the network is that the frame level MCEPDFT separated from the lower quality speech signal and in this manner the objective yield is that the MCEP-DFT removed from the hidden clean speech signal of that precise frame. Various organizations were prepared with the noise information (RNN-N), the reverberant information (RNN-R) and both blend of noise and reverberant information (RNN-NR) (Hu &Loizou, 2006).
CNN is the mainstream deep learning architecture and utilizes a variety of multilayer perceptron's intended to require minimal pre-processing. It requires a smaller number of parameters compare to the recurrent neural network because it has weight sharing property. CNN are all over the place. It is seemingly the most well know profound learning engineering. The ongoing flood of enthusiasm for profound learning is because of the huge notoriety and viability of convnets. The success for CNN began with AlexNet in 2012 (Gu et al., 2018).
CNN consist of three layers (Gopika, et al., 2020),
CNN is likewise computationally productive. It utilizes exceptional convolution and pooling activities and performs boundary sharing. This empowers CNN models to run on any gadget, making them generally attracting. All things considering; this seems like absolute enhancement. Ideally this paper will assist us with improve the quality of speech from corrupted speech (noise, reverberation, and combination of both noise & reverberation).
The voice signal of “Jawaharlal Nehru Technology University” was used as the input signal.
For the signal input, we can observe that its produces and clean speech signal in Figure 1 and then we are adding the noise, reverberant and combination of both noise and reverberant that are observed in Figures 2, 3 and 4.
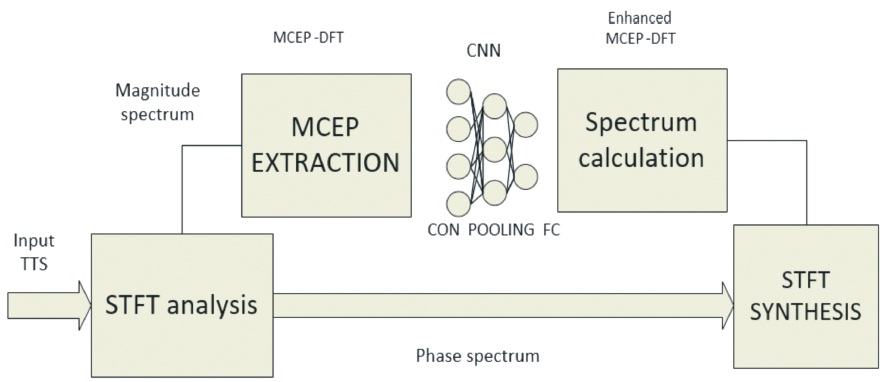
Figure 2. Working of CNN
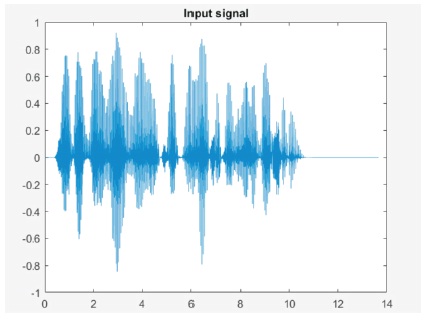
Figure 3. Input Signal
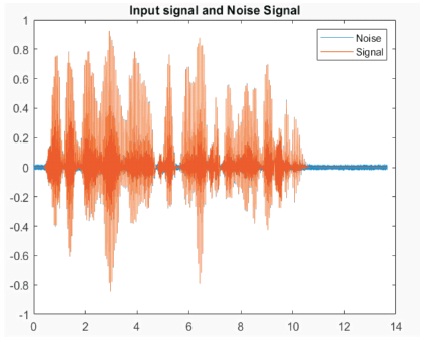
Figure 4. Input Signal with Noise
On applying RNN, we found little improvement as shown in Figures 5, 6 and 7.
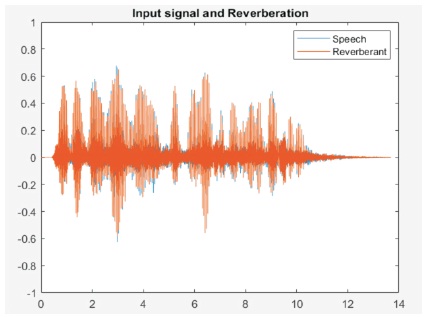
Figure 5. Input Signal with Reverberation Signal
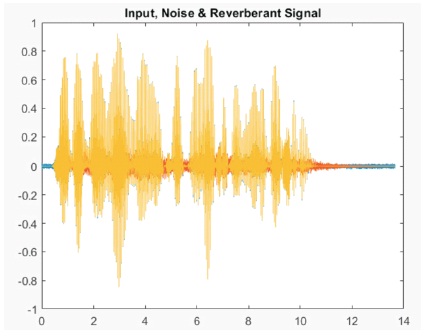
Figure 6. Input Signal with Noise and Reverberant
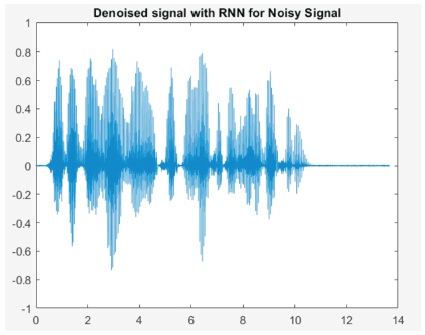
Figure 7. Denoised Signal with RNN for Noise Signal
Then, on applying CNN, we found better improvement compare to RNN in Figures 8, 9,10, 11, and 12.
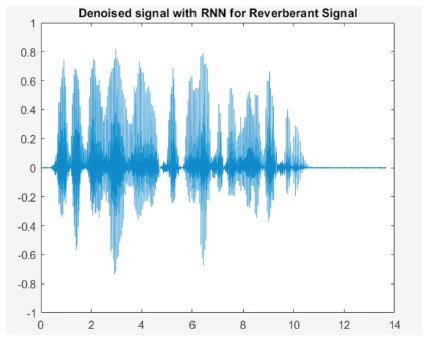
Figure 8. Denoised Signal with RNN for Reverberant Signal
Figure 9. Denoised Signal with RNN for Reverberant & Noise Signal
Figure 10. Denoised Signal with CNN for Noise Signal
Figure 11. Denoised Signal with CNN for Reverberant Signal
Figure 12. Denoised Signal with CNN for Noise and Reverberant Signal
Table 1 shows that parametric comparison of RNN & CNN for noise signal. Table 2 shows that parametric comparison of RNN & CNN for reverberant signal. Table 3 shows that parametric comparison of RNN & CNN for noise and reverberant signal.
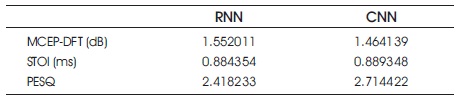
Table 1. Parametric Comparison of RNN & CNN for Noise Signal
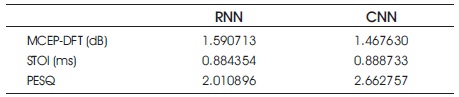
Table 2. Parametric Comparison of RNN & CNN for Reverberant Signal
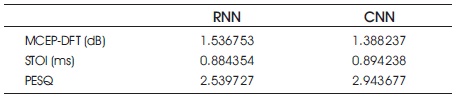
Table 3. Parametric Comparison of RNN & CNN for Noise & Reverberant Signal
From the Tables and graphs (Figures 13, 14 and 15) presented in this paper, Perceptual Evaluation of Speech Quality (PESQ), quality of the speech is improved, Short Time Objective and Intelligibility (STOI) is increased for CNN & MCEP-DFT is decreased. From this comparison of RNN and CNN, we conclude that better results are coming from CNN.
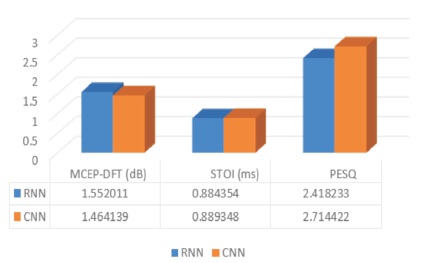
Figure 13. Parametric Comparison of RNN & CNN for Noise Signal
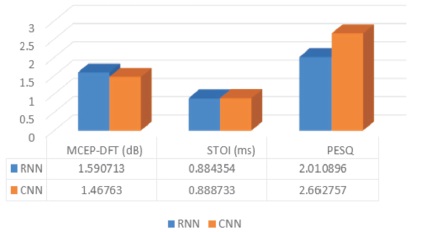
Figure 14. Parametric Comparison of RNN & CNN for Reverberant Signal
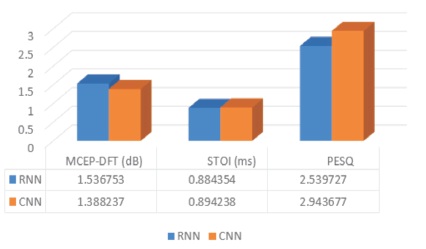
Figure 15. Parametric Comparison of RNN & CNN for Noise and Reverberant Signal
In this project we proposed the utilization of RNN and CNN to eliminate added substance noise and reverberation of speech and blend of both noise and reverberation signal. Here, our evaluation on the quality of the speech in various forms like clean speech, noise speech, reverberated speech being improved using RNN. We found that speech quality can be significantly improved by simply improving the quality of the recordings used for training the voices. However, enhancement was still significantly beneficial. We found that speech quality can be fundamentally improved by essentially improving the quality of the recordings utilized for training the voices. In any case, enhancement was still essentially useful. The CNN method is considered to be best in removing noise and reverberation when compared with RNN method.