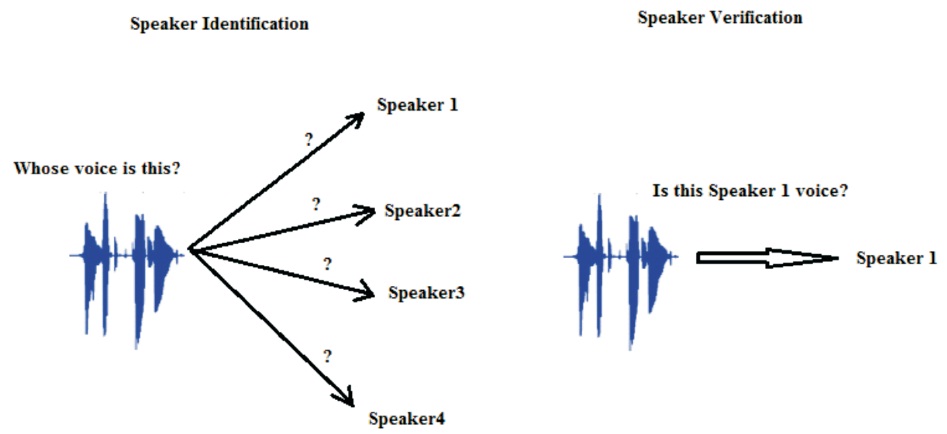
Figure 1. Types of Speaker Recognition System
Speaker recognition system automatically recognizes who the speaker is by using the speaker's speech features included in speech signal. After verifying the speaker claimed to be, it allows and enable access control of various voice services. The main applications of speaker recognition are in the field of forensic and providing additional security layer where security is the primary concern. The aim of this work is to verify a speaker with the approach of MFCC and Back Propagation Neural Network. Training function Lavenberg-Marquardt is used to train the network. Voice samples from a group of ten people uttering the same sentence five times repeatedly are collected to train the neural network. The testing of the network for verifying the speaker is done with new data set with the same utterance spoken once. A specific target or speaker ID is assigned to each speakers and verification is based on how close the network output is to the assigned code for each speaker. Verification method depends on the minimum positive error generated between the code and the actual network output. If the error is below the threshold value, the speaker claimed to be is accepted otherwise rejected. The tool for simulation is MATLAB.
Speaker recognition system can be classified as speaker identification and speaker verification (Remya, 2014). The basic difference between the two is shown in Figure 1.
Figure 1. Types of Speaker Recognition System
Speaker identification aims to identify an input speech by selecting one model from a set of enrolled speaker models. Speaker identification is the way toward figuring out which enlisted speaker gives the articulation, whereas speaker verification aims to verify whether an input speech corresponds to the claimed identity. It deals with the way toward accepting or dismissing the personality guarantee of as a speaker. It is a 1:1 matching process (Sharma & Bansal, 2013). In every speaker recognition system, training and testing are the two main phases which govern the system (Mansour et al., 2015; Wang & Lawlor, 2017), i.e., speech features extraction module and speech features matching model. Several common methods used for extraction of unique speech features are Linear Prediction Coefficients (LPC), Mel-Frequency Cepstral Coefficients (MFCC), Gammatone Frequency Cepstral Coefficients (GFCC), Linear Predictive Cepstral Coefficients (LPCC) and Perceptual Linear Predictive (PLP). In a similar manner, for speech features matching technique, several classifiers such as Dynamic Time Warping (DWT), Gaussian Mixture Model (GMM), Hidden Markov Model (HMM), K- Mean Clustering and Vector Quantization (VQ) are employed. In this work MFCC will be use for speech features extraction and neural network as speech features matching model.
Many researchers working in the field of speech processing has reported that speech features extracted with MFCC method is popular and successful as it is being modeled as human auditory system and also because of its high accuracy rate (Ahmad et al., 2015). MFCC algorithm is generally preferred as a feature extraction technique to perform voice recognition as it involves generation of coefficients from the voice of the user which are unique to every user. (Chakraborty et al., 2014). Because of this reason many work have been carried out on speaker recognition based on MFCC. The various step by step of MFCC involving for speech feature extraction are listed below (Martinez et al., 2012).
In this work, the speaker speeches features will be extracted with MFCC approach from any speech wave file and represent it with unique 13 coefficients for each speaker. The parameters of MATLAB code for speech feature extraction is set at frame duration of 26 ms, frame shift 10 ms, pre emphasis coefficient of 0.97, filter bank channel 20, lower frequency cut off of filter 300 Hz and upper frequency cut of 3750 Hz. The resultant 13 coefficient matrix will have variable column depending on the speech length. The voice is sampled at 48 KHz with a bit depth of 16 bit. The MFCC feature is in the form of matrix consisting of fix 13 rows and having different column for different speaker. The longer the utterance of speech, the more the number of column is and vice versa. Data are collected for ten speakers from Sp1 to Sp10 in a relatively less noise environment with the same voice recorder device. The results of MFCC are then used for training the neural network. The MFCC simulated result of a particular speaker is shown in Figure 2.
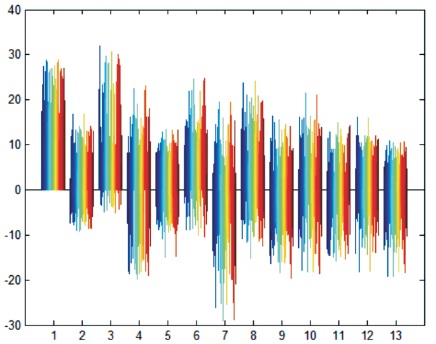
Figure 2. Simulation Result of MFCC
The results obtained in MFCC of all the ten speakers are in matrix form consisting of fixed 13 rows and variable column for different speaker as shown in Figure 3. This can be represented as M x N where M is fix rows and N is variable columns. The value of N will be more if a speaker takes more time to complete the utterance of the sentence.
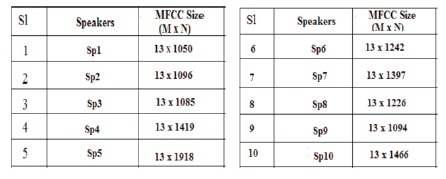
Figure 3. MFCC Result in Matrix Form
The basic structure of multilayer Perceptron neural network which consists of interconnected input nodes, hidden layer and output nodes is shown in Figure 4.
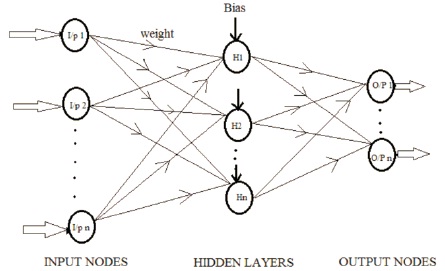
Figure 4. Multilayer Perceptron Neural Network Structure
In Back propagation algorithm, two basic steps takes place to obtain the desire network output, i.e., feed forward and back propagation. In feed forward direction the propagation of data is from inputs nodes towards output nodes along with its initial bias and weights. In this process, the network output and desire target checks whether they are equal or not. If not equal, then back propagation takes place. In back propagation the weights are updated backward from output nodes towards input nodes. The back propagation algorithm is used to train supervised learning of Artificial Neural Networks (ANN). When the network is designed, initial random weights are assigned to predict the desired target. If there is a variation between the network output and the desire target, the weights are updated to minimize the error. The final weight which minimizes the error function is the solution of the neural network leaning. The goal of Back propagation algorithm is to minimize the value of the mean square error function by updating its weight until the actual output is almost equal to the desire target value (Hossain et al., 2013; Joshi & Cheeran, 2014). The more the number of input data, accuracy will be more and the performance of the network will be better (Achkar et al., 2016).
The algorithm of Back Propagation is as follows (Ayshwarya et al., 2014)
The general structure of speaker verification is shown in Figure 5.
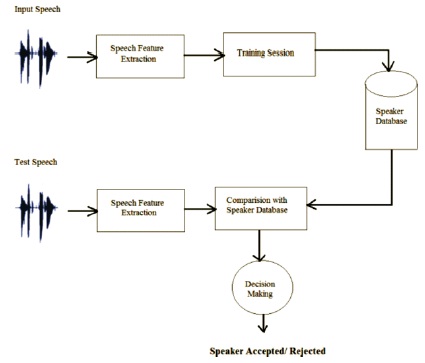
Figure 5. Structure of Speaker Verification
Here, the speaker is either claimed to be rejected or accepted by the decision making block. The proposed network is designed for one to one mapping of speaker, i.e., each network will accept only one speaker and reject all other speakers as shown in Figure 6.
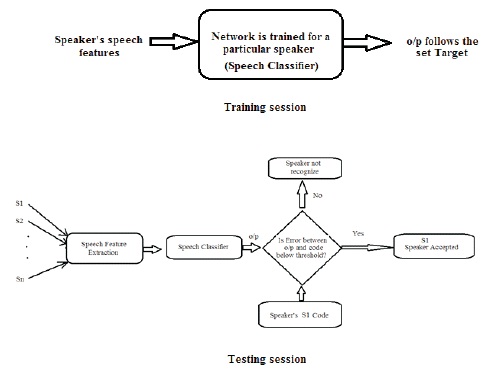
Figure 6. The Proposed Structure of Speaker Verification
Each network is assigned with a specific code as a network target for a specific speaker. Initially the network is trained with a particular speaker's speech feature which is extracted with MFCC method. In the testing phase, the trained network will recognize only the trained speaker, based on the error generated by the network output. This error is the difference between the actual network output and the code assigned for the speaker.
The model is built with a multilayer perceptron neural network consisting of 13 inputs nodes, 50 hidden neurons with 1 output node as shown in Figure 7.
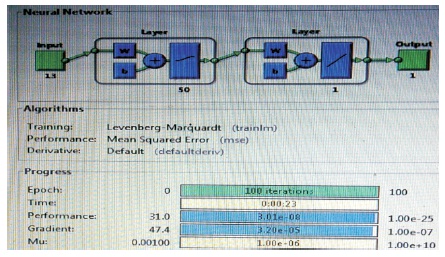
Figure 7. Neural Network Model
The epoch is set at 100 with a learning rate of 0.35. The 13 coefficient features obtained from MFCC computation is given as inputs to the inputs of neural network.
The neural network training phase is carried out for a speaker uttering the same sentence repeatedly by setting the desire target. The best result obtained from the simulation is at 100 epochs with mean square error of 3.0084e-08 as shown in Figure 8 along with its fitting plot.
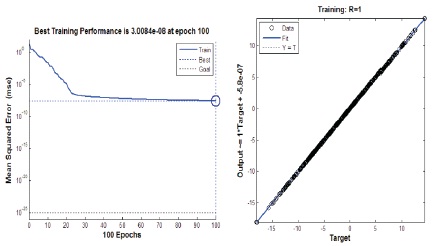
Figure 8. Regression Plot and Performance of the Neural Network
Similarly training for all other speakers is carried out. Now the testing phase of the trained network is carried out with the new inputs from the same speaker uttering the same sentence. The neural network target is a set of different numeric number ranging from negative to positive values. The neural network is trained in order to produce an optimum output value which is so close to the set target. The difference between the set target and the actual output is the network error. So, to represent this error with a single value, the algebraic sums of all targets and outputs values are computed initially. After that, difference between the two is calculated and will be represented as an error. The network is tested for all speakers applying a “For loop”. The network trained for a specific speaker will match its output and the assigned code closely for that speaker only by producing a small error. But for other speaker error will be huge as there is a wide variation between the code and the actual network output. A threshold value of error is set to either accept or reject the speaker. If the error lies between zero and the threshold error value, a speaker is accepted otherwise rejected. Hence, based on the least positive error generated, the speaker can be recognized. The simulation result of accepting only one speaker, i.e., the right speaker base on the least error generated is shown in Figure 9 to Figure 11.
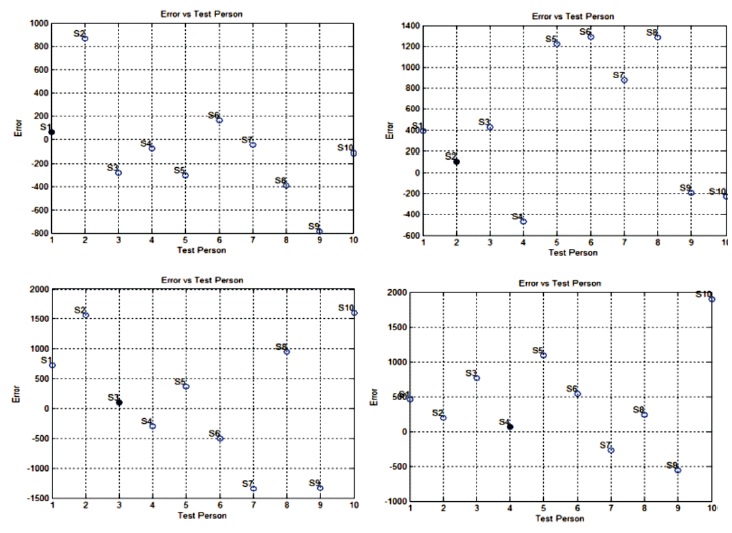
Figure 9. Simulation Result Generating the Least Positive Error of S1, S2, S3 and S4
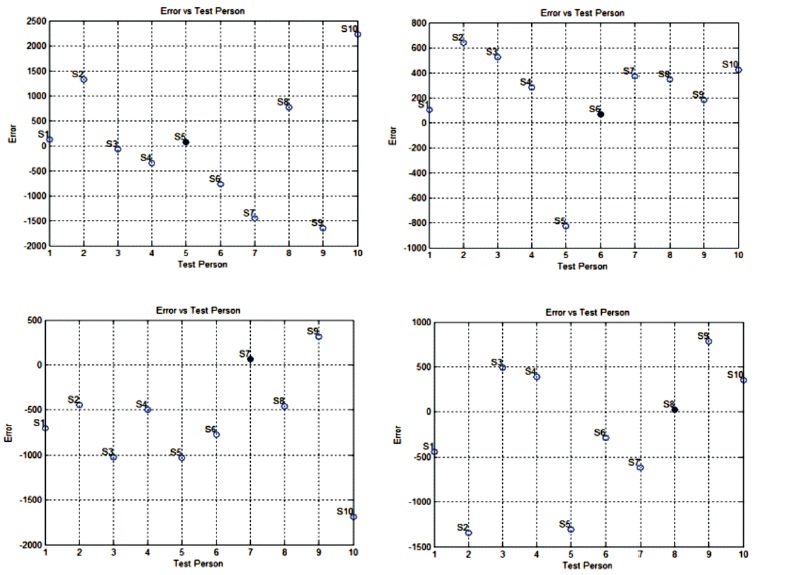
Figure 10. Simulation Result Generating the Least Positive Error of S5, S6, S7 and S8
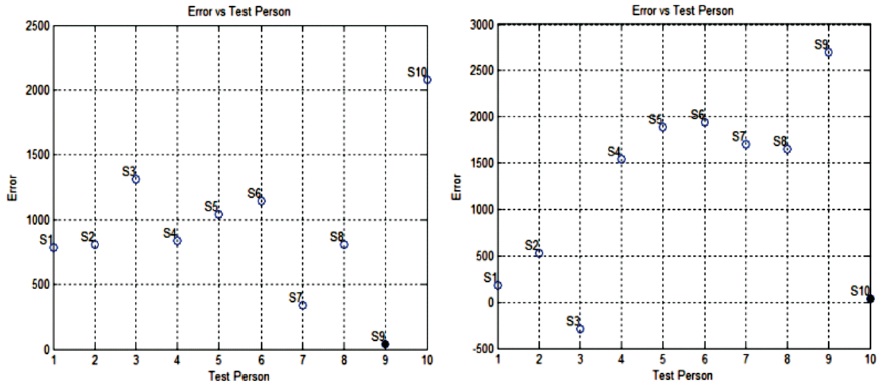
Figure 11. Simulation Result Generating the Least Positive Error of S9 and S10ax
The method of how a speaker got accepted is summarized with the help of Figure 12. Here a speaker Sp1 only will be accepted as the error generated is below the threshold level and all other speakers will be dismissing as their error values are out of the range of acceptance level.

Figure 12. Error vs. Test Speakers
A total number of ten speaker verification system is modeled to verify each speaker. Verification is based on the least positive error generated. If the error is below the threshold error level, a speaker claim to be is accepted otherwise it is rejected. Setting the threshold value of error is prominent in this model. If it is set too high, probability of false acceptance increases and if it is set too low, there is a probability of miss detection of a right speaker. Optimum values of threshold of error are set such that only the right speaker is verified and all other are rejected. More the number of training set data is used, the more the network will learn about the speech features of the speaker. The simulation result of all speakers from S1 to S10 generating the least positive error is also shown in the result. This can be extended for N number of users applying the same approach for verification. The advantage of this model is less simulation time as each network is trained only one particular user for one to one mapping.