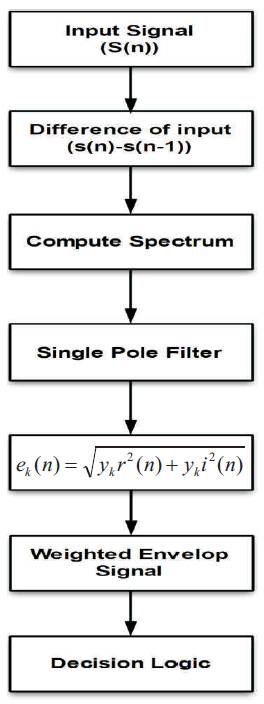
Figure 1. Block Diagram of the Proposed Method
Signal Processing is used to bring out the speech in a degraded signal. Amplitude of the signal is obtained by using the SFF (Single Frequency Filtering). Spectral and Temporal resolutions are compared by using three different methods, which are discussed in this paper. Voice Activity Detection is the process in which any noise or disturbance that are made to the speech signal is detected. In this paper, the author has proposed Voice Activity Detection system with the help of Frequency based filtering method. The experimental results show that it gives better results compared to the existing systems.
Speech processing is the way of processing the signals and also is about the study of the speech signals. The signals are sometimes processed in a very digital illustrated manner so that the process will be considered as a special signal processing, which was applied to the speech signal (Garg, 2015). By the estimation of the amplitude at the peak of the spectrum, which has short time and wavelet transformed speech signals, the fundamentals of the speech signal frequency can be determined (Qiu et al., 1994). Recently, a wide range of speech signals processing algorithms using speech signals have been introduced. Many speech coding applications, such as digital voice storage, Code Division Multiple Access (CDMA) wireless networks, and packetized communication systems allow variable rate transmission. The Voice Activity Detector is usually employed by the speech coders so that the average bits can be reduced. Also, during the absence of a speech signal, no or less bits can be assigned (Sohn and Sung, 1998). Voice activity detection happens during the presence or absence of a human speech. This is also called speech detection. The main objective of voice activity detection is when the signal is even in a corrupted manner and the speech in the acoustic signal should be determined. Speech coding and recognition are one of the important uses of VAD. By avoiding the silent data transmission the bandwidth of the signal can be saved and also some non-speech processes are deactivated in the audio session.
VAD is used in speech based application. Various VAD algorithms has been developed which comprises of latency, sensitivity, accuracy, etc. Pitch Extraction, Speech enhancement are the couple of few applications, where the Single Frequency Filtering appears to be promising (Aneeja and Yegnanarayana, 2015).
Zhang and Wang (2016) have used the machine learning methods to explore three levels of contextual information. There is a stack of ensemble classifiers at the top level, which is Multi Resolution stacking where the ensemble learning framework is employed. The results of the proposed system states that this Voice Activity Detection method gives better results compared to other VADs.
Hung et al. (2015) have proposed a signal processing apparatus, which includes a speech recognition system and a voice activity detection unit. The voice activity detection unit is coupled to the speech recognition system, and arranged for detecting whether an audio signal is a voice signal and accordingly generating a voice activity detection results to the speech recognition system to control whether the speech recognition system should perform speech recognition upon the audio signal.
Mak and Yu (2014) have proposed the difficulties in segmentation of the speech and non-speech signals. The speech characteristics of the interview speech in NIT SREs are calculated. The preprocessing technique is used in the proposed system, which is used for the reliability enhancement of energy as well as statistical based model of VADs.
Sehgal and Kehtarnavaz (2018) have proposed an application which can be used in smartphones for performing the real time voice activity detection. It is based on a convolutional neural network. The slow inference convolution neural network issue is discussed. The proposed system in a smartphone app is used for reducing the noise for signal processing pipelines, and also for the estimation or the classification of noise from speech signals.
Kinnunen et al. (2007) have proposed to construct with SVM-VAD that uses MFCC features where the relevant information is captured. The proposed system was used in speech as well as speaker recognition techniques that make the proposed system to combine with the existing applications. The probability of using the proposed method in new conditions is expected to be high.
Iain McCowan et al. (2011) have done an investigation on a representation on a deviation of frequency in an instantaneous manner. Here the step size between the frames is calculated on the changes in phase other than the simple intervals which happens traditionally. Also in the proposed system it shows that magnitude and also the representation of the phase have yielded a better performance.
Haigh and Mason (1993) have compared the review of different algorithms on the time domain analysis to provide energy as well as zero crossing rates accordingly with other algorithms, which are used for speech detection methods. High degree of amplitude as well as independence in noise level is examined here with different approaches. With the code book, Euclidean distance measure for voice detection algorithm is used accordingly.
Dhananjaya and Yegnanarayana (2010) have proposed a method for epoch extraction for both the detection on voice and non-voice. The signal is extracted on significant excitation, where zero frequency filtered approach is used. The strength of the proposed method is the glottal activity against the periodicity of the signal.
Pham et al. (2010) have analyzed the performance of wavelet-based Voice Activity Detection (VAD) algorithms with respect to the detection of target speech in a cocktail party environment. In addition, the state-of-the-art VAD standardized for the G. 729 B, the ETSI AFE ES 202 050 are evaluated extensively. Experimental results include different target-interference speech activity conditions.
Adiga and Bhandarkar (2016) have proposed in low Signal to Noise Ratio environments, where the accuracy of the frequency domain will be high. In Single Frequency Filtering (SFF), the computing of the FFT of the given audio frame is discarded. In this paper, the SFF approach is evaluated by adaptive spectral subtraction which was based on the cancellation of the noise.
Ong et al. (2017) have proposed an Upper Envelope Weighted Entropy (UEWE) methodology for enabling the separation of speech and non-speech segmentation in the voice communication. In addition, Dual-rate Adaptive Nonlinear Filter (DANF) is introduced. The DANF has high adaptivity. Time-varying noise computation of the decision threshold is done here with the DANF.
Borin and Silva (2017) have addressed the VAD task through machine learning by using a Discriminative Restricted Boltzmann Machine (DRBM). The DRBM method is extended in the present study to deal with the continuous valued and also based on mel-frequency cepstral coefficients. The output of the proposed systems detector gives better results compared to other VADs.
The features of speech even in the degraded signal are highlighted with the proposed system using Frequency based filtering. At each frequency, the signal energies of the temporal variation are extracted. Also at each frequency, the characteristics of the speech (due to correlations among speech samples) differ from the characteristics of noise (due to UN corelatedness in noise samples in many cases).
At some high frequencies, noise of the signal is compared with the SNR of the speech signal. The high SNR property of speech at several single frequencies is exploited. Due to the extraction of energy in a single frequency, it is known as a Single Frequency method. At each time instant, with the envelope computed across the frequency, the mean and variance of the noise compensated is weighed.
The variance of speech across frequency is higher than that for noise after compensating for spectral characteristics of noise. Using the SFF approach, with the help of floor of the temporal envelope at each frequency, the characteristics of the noise gets determined.
The SFF method yields envelopes at any desired frequency, with high temporal and spectral resolution. This property can be exploited for many other applications in speech processing, such as robust pitch extraction, speech enhancement, and deriving robust features for speech and speaker recognition.
Figure 1 shows the block diagram of the proposed system.
The steps involved are,
1.Applying the Input signal.
2.Finding the difference of the input signal and the previous signal.
3.Sampling of the signal.
4.Finding Fourier transform of the sampled signal.
5.Designing the filter to obtain spectral output.
6.Calculating the Weighted envelope.
7.Determining the decision logic.
Figure 1. Block Diagram of the Proposed Method
The stages of the proposed system are listed below.
- Audio, Sampling
Speech signal has dependencies both along time and frequency. This results in signal to noise power ratio to be a function of time as well as a function of frequency. The signal and noise power as a function of frequency can be computed using either by block processing as in the DFT, or by filtering through SFF.
The discrete-time speech signal s(n) is differenced, and the differenced signal is denoted by x(n)=s(n)-s(n-1). The sampling frequency is fs . With the given Normalized frequency of a complex sinusoid, it gets multiplied with the signal x(n). The resulting operation in the time domain is given by,
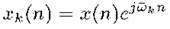

and the transfer function is given by,
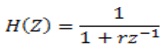
The envelope of the signal yk (n) is given by,

The output of the filter is given by,
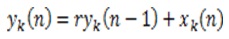
where, ykr(n) and yki(n) are the real and imaginary components of yk(n), respectively (Sharmida and Athira, 2016).
The decision logic is based on (n) for each utterance, where the applied threshold on temporally smoothed (n) values are derived by the threshold over the assumed (20% of the low energy).

The window size used for smoothing (n) is adapted based on an estimate of the dynamic range of the energy of the noisy signal in each utterance, assuming that there is at least 20% silence region in the utterance. The binary speech and non-speech at each time instant is denoted as 1 and 0. And also it is further denoted that the final decision by smoothing is done using an adaptive window (Sharmida and Athira, 2016).
Floor level depends on the distribution of power in the noise across frequency. The noise is almost stationary when the floor is uniform with respect to time. On the other hand, even though the noise is non-stationary, they are relatively stationary when the time interval is large. In these cases, level of floor is computed over different intervals at different frequencies. To compensate for the effect of noise, a weight value at each time.
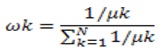
Frequency is computed using the floor value. For each utterance, the mean (k) of the lower 20% of the values of the envelope at each frequency is used to compute the normalized weight value at that frequency. The choice of 20% of the values is based on the assumption that there is at least 20% of silence in the speech utterance (Sharmida and Athira, 2016).
Note that the spectral dynamic range is given by,
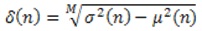
In the performance analysis, the existing method is compared with the proposed method for the efficiency. In the proposed method, a new VAD method is proposed based on Single Frequency Filtering approach in this paper. At different frequency and different time, the fact that speech has high SNR regions gets exploited in this method.
The threshold value is calculated in all cases. The value depends on speech and also it is based on the characteristics of speech and noise.
In order to smoothen the window, a parameter is used, which is obtained from the formula,
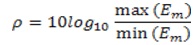
The decision d(n) is made as follows,

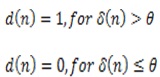
The decision d(n) at each sample is processed over windows of size 300 ms, 400 ms, and 600 ms, respectively.
In order to compare the proposed method with AMR method, the decision is converted to 10 ms. For each10 ms, for the non-overlapping frame, if majority of d(n) values are 1, then the frame is marked as speech, otherwise it is marked as non-speech.
Figure 2 shows the sample output signal. The sound wave is given as an input and when the Pink noise with 10 db is added it can be seen that the SNR level decreases which is shown in Figure 3. Figure 4 shows the STFT spectrum of signal and spectrogram gives the detailed information about the STFT.
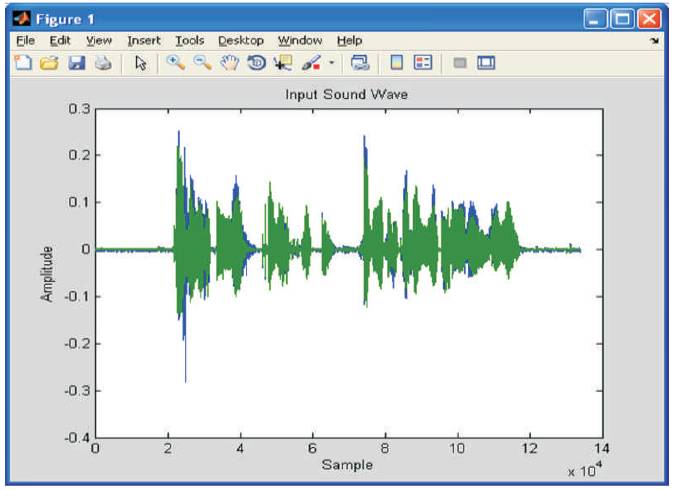
Figure 2. Sample Input Signal
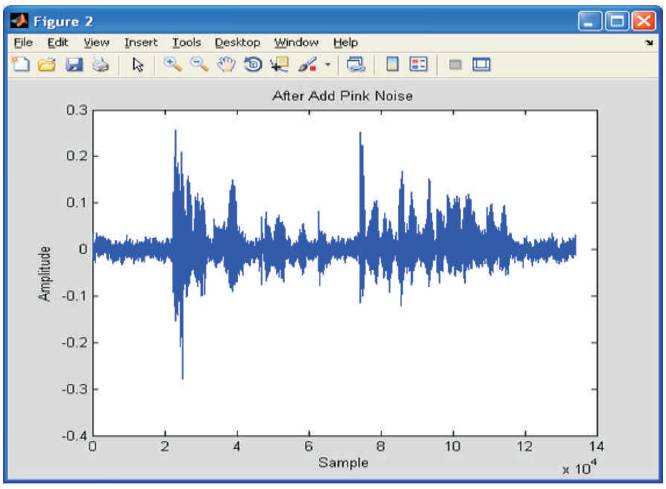
Figure 3. Pink Noise Level Increase
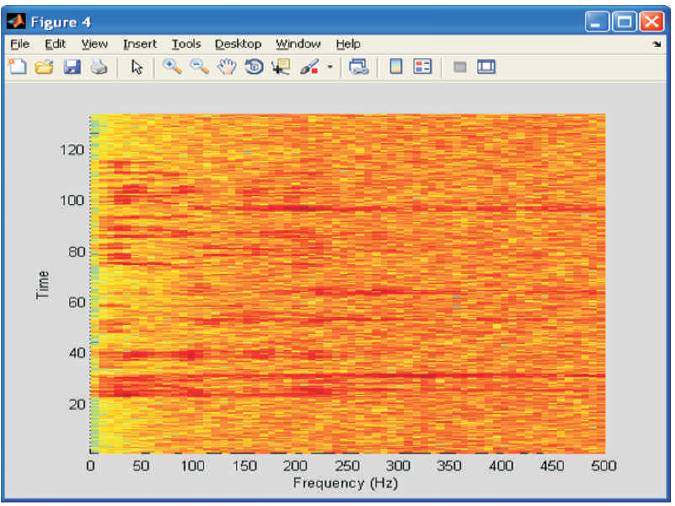
Figure 4. STFT Information
Envelop of Signal is given below.
En=sqrt(real^2+imag^2)
The Envelop of the signal is shown in Figure 5 and the results are provided for the Filter design model with respect to the Normalized Frequency, 3D plot with respect to multiple Single pole filter, estimation of DEL value are as seen in Figures 6 to 8, respectively. The redline shows that voice activity is detected which is shown in Figure 9 and Figure 10 shows the accuracy of the signal with respect to the test sample.
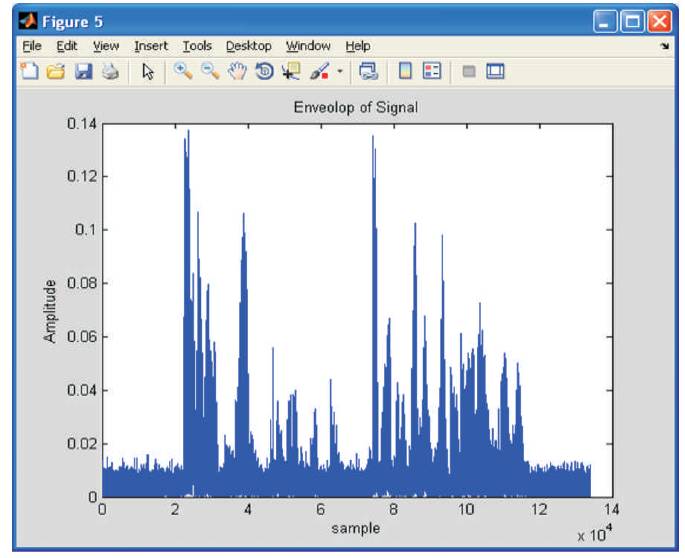
Figure 5. Envelop of the Signal
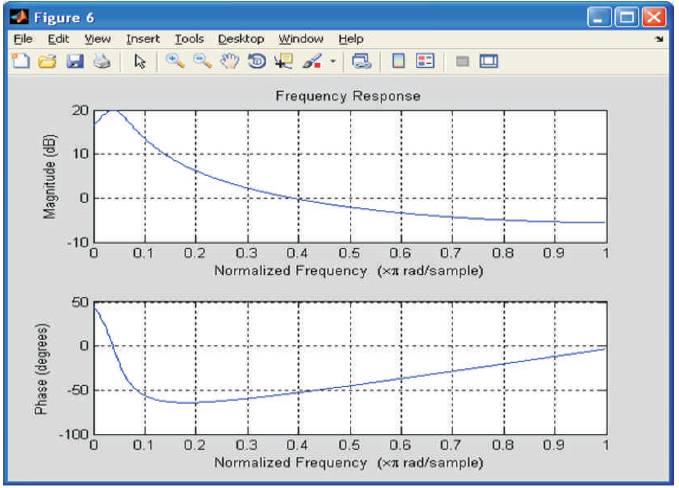
Figure 6. Phase and Magnitude Response with respect to Normalized Frequency
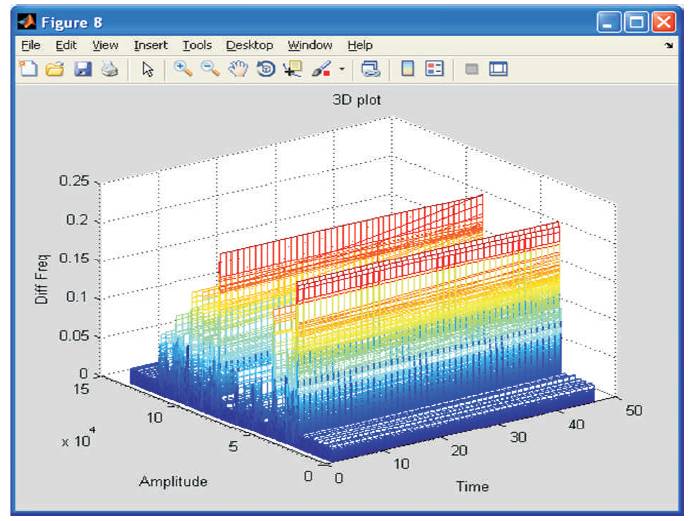
Figure 7. 3D Plot with respect to Multiple Single Pole Filter
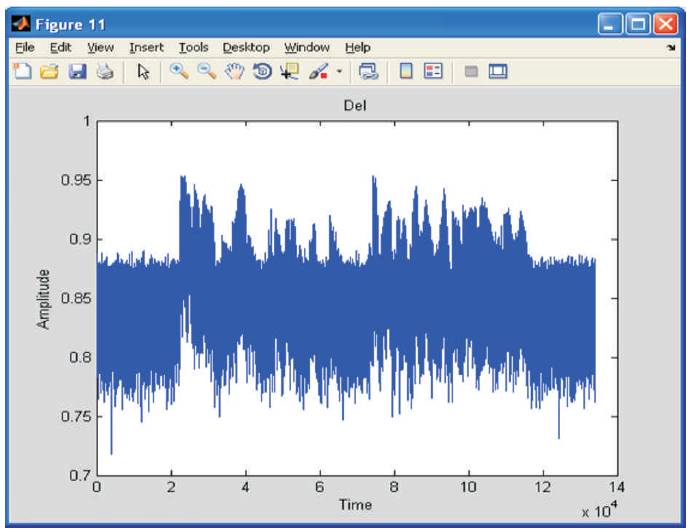
Figure 8. Del Value Estimation
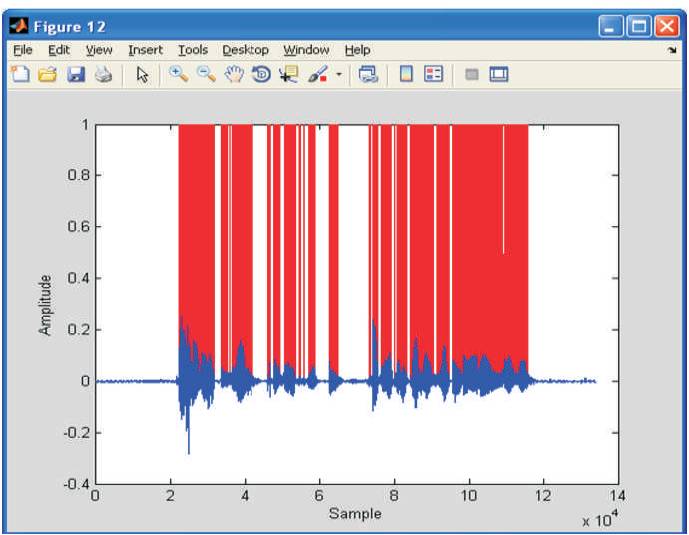
Figure 9. Speech Signal Detection
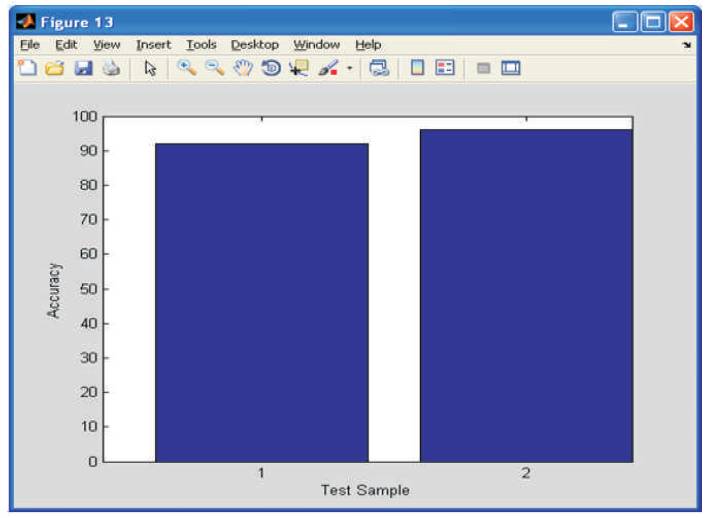
Figure 10. Accuracy of the Signal with respect to the Test Sample
This work proposes the Single Frequency Filtering (SFF) method, wherein at different times, the mean and variance is high when compared to the noise. In the temporal envelope of every frequency, the noise spectral character is determined which is done by the help of SFF methodology. The merits of this work are highly efficient results for all types of noises, yields high temporal and spectral resolution, and does not require training data or any other prior information about the type of noise. Finally this work concludes with the experimental results that even in the presence of too much background noise, clear speech signal can be obtained.