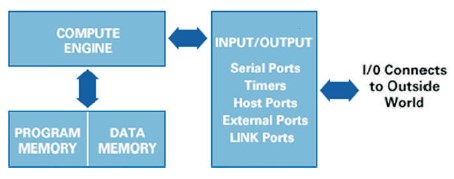
Figure 1. Key Components of DSP
Over the past years, advancements in speech processing have mostly been driven by DSP approaches. The speech interface was designed to convert speech input into a parametric form for further processing (Speech-to-Text) and the resulting text output to speech synthesis (Text-to-Speech). Feature extraction is done by changing the speech waveform into a parametric representation at a relatively low data rate so that it can be processed and analyzed later. There are numerous feature extraction techniques available. This paper presents the overview of Linear Predictive Coding (LPC).
Digital Signal Processing is the method of choice for many applications, such as multimedia, speech analysis and synthesis, mobile radio, sonar, radar, seismology, and biomedical engineering. Figure 1 shows the key componenets of DSP such as program memory, data memory, compute engine, Input/Output. A DSP algorithm is made up of several mathematical operations. As shown in Figure 2, a 4th-order Finite Impulse Response (FIR) filter requires five digital multipliers, four adders, and delay elements. As a result, a digital signal processor also functions as a computing engine. This computing engine can be a general-purpose processor, a Field-Programmable Gate Array (FPGA), or even a DSP chip made for a specific task (Diniz et al., 2002). Speech is one of the ancient forms of expression. These speech signals are being utilized in machine communication and biometric recognition systems.
These speech signals are signals that change slowly over time (quasi-stationary). Its properties can be observed over a short time (5–100 msec) and are mostly stationary. However, if the signal properties change over time, this will reflect in the various speech sounds that are being spoken. The short-term amplitude spectrum of the speech waveform truly represents the information in voice signals. This enables us to extract information from speech that is based on the short-term amplitude spectrum (phonemes).
Figure 1. Key Components of DSP
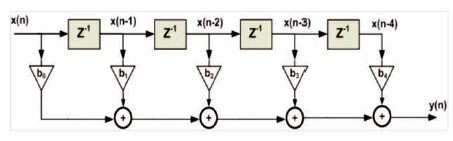
Figure 2. Digital Signal Processing
Speech processing is the study of speech signals and the techniques used to process information. Typically, the signals are processed in a digital format. As a result, speech processing can be thought of as a subset of Digital Signal Processing applied to speech signals. The primary challenge in speech recognition is the voice signal's extreme variability caused by various speakers, speaking rates, contents, and acoustic circumstances. Automatic Speech Recognition(ASR)system performance depends on feature analysis. There are numerous feature extraction methods, including,
Feature extraction is done by converting the speech waveform to a parametric representation at a slower data rate so that it can be processed and analyzed later. Typically, this is referred to as front-end signal processing. It changes the processed speech signal into a short, logical representation that is more accurate and reliable than the actual signal.
Speech recognition is usually done in the following stages, as shown in Figure 3. For each process, various mathematical methods can be used. The accuracy of the results of speech recognition can vary depending on various strategies (Rabiner & Juang, 2003). Unwanted noise is reduced through the use of filtering. Depending on the method used on the audio corpus, various noises are removed. Principal Component Analysis (PCA) is the most commonly used method of feature extraction. These methods are employed to extract various types of characteristics, such as statistical, linear, and non-linear features, which vary depending on the resource model. As a result, it is not a structure that applies to all models. These methods vary depending on the language of the resource; in this case, English is taken into account for the procedure. Then comes the decoding phase, which is when each corpus of audio segments' real meaning is discovered. Resource languages are also used for corpus decoding. The audio corpus is matched to the stored matching audio corpora using a variety of statistical, pattern-based, or machine-learning-based methods, which ultimately result in text extraction. There are numerous uses for speech recognition technology (Ainsworth, 1988).
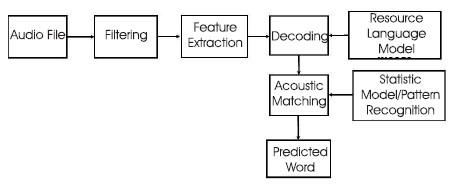
Figure 3. Stages of Speech Recognition
Signal processing is the process of getting useful information from a spoken signal reliably and effectively. A speech recognition system is made up of several algorithms that are borrowed from several fields, such as linguistics, statistical pattern recognition, communication theor y, signal processing, and combinational mathematics. The signal processing front end, which converts the speech waveform into some kind of parametric representation for additional analysis and processing, may be the feature that unites all recognition systems the most, even though different recognizers use each of these components to varying degrees.
Speech recognition is the process of converting an acoustic signal that a microphone or phone has recorded into a list of words. The signals are typically transformed into a digital representation before being analyzed, speech processing can be thought of as a subset of Digital Signal Processing that is applied to speech signals.
The following is a list of some of the methods and relevant techniques that the researchers use for application such as, Speech Communications, Speech Recognition Systems and Processing of Degraded Speech.
Some of the techniques of speech processing are shown in Table 1.
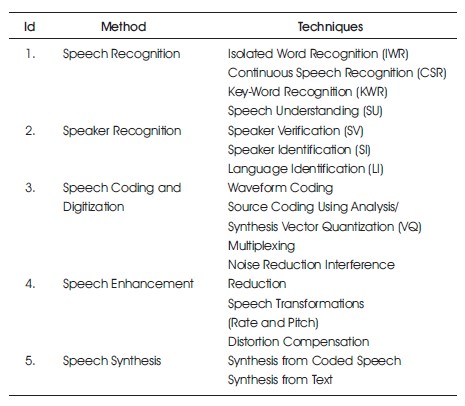
Table 1. Methods and Techniques of Speech Processing
2.2.1 Speech Recognition Systems
Speech recognition is a technique that allows machines to be controlled by voice in the form of single or connected word sequences. It involves the automatic recognition and comprehension of spoken language.
The aim is to classify a speech signal input pattern as a series of precisely defined stored patterns. These saved patterns could be composed of components known as phonemes.
The primary challenge with speech recognition is that the voice signal is highly varied due to a variety of factors, including different speakers, speaking rates, contents, and acoustic conditions. Identifying which speech variations are relevant for speech recognition and which variations are not is the task at hand.
Feature extraction is the process of taking a small amount of data from the voice that can then be used to represent each word (Bou-Ghazale & Hansen, 2000). Feature extraction is an important approach. Several feature extractions and lists of feature extraction properties are shown in Table 2.
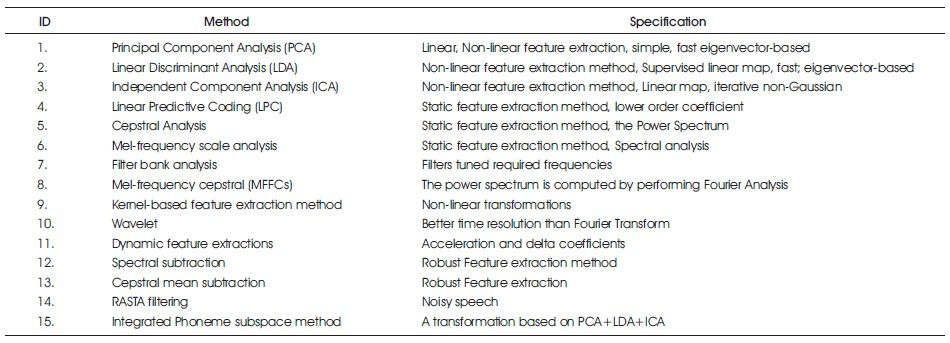
Table 2. Feature Extraction
The goal is to transform the speech waveform into some kind of parametric representation for additional processing and analysis. This is frequently referred to as the front end of the signal processor. There are many ways to parametrically represent the speech signal and the speech recognition tasks, such as Mel-Frequency Cepstrum Coefficients (MFCC), Linear Predictive Coding (LPC), the Filter-Bank Spectrum Analysis Model, Vector Quantization, and others. The overview of the Linear Predictive Coding (LPC) model is analyzed in this paper.
The speech signal is a signal that varies slowly in time (it is called quasi-stationary). Figure 4 shows an illustration of a speech signal and Figure 5 shows the speech signal in the time domain (Rabiner & Juang, 1993). Its properties are stable for 5-100 ms. To reflect the many speech sounds being spoken, the signal characteristics do fluctuate over long periods (on the order of 1/5 second or more). As a result, the most popular method for characterizing the speech signal is short-time spectrum analysis.
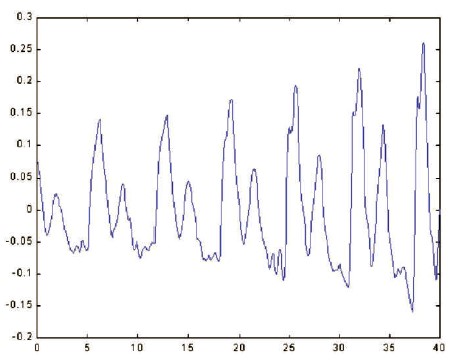
Figure 4. Speech Signal
Figure 5. Speech Signal in Time Domain
3.1.1 Linear Predictive Coding (LPC) Model
One of the most effective speech analysis techniques is Linear Predictive Coding (LPC), which is also a good way to encode high-quality speech at a low bit rate. It offers precise estimates of speech properties and is effective for calculations. The technique in the speech signal is extracted using the LPC method. Linear predictive analysis is based on the idea that a sample of speech from the present can be thought of as a linear combination of samples from the past (Shrawankar & Mahajan, 2013).
The speech signal parameters are obtained after completing the procedures depicted in Figure 6, and these are then used for training (Bradbury, 2000).
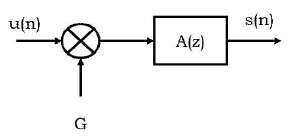
Figure 6. Linear Predictive Model of Speech
3.1.2 Algorithm Description
By minimizing the mean square error between the input speech and the estimated speech, the linear prediction approach is used to produce the filter coefficients equal to the vocal tract. Any given speech sample at a given period is predicted by a linear prediction analysis of the speech signal as a linearly weighted aggregate of prior samples. Kumar et al. (2009) provides Equation 1 as the linear predictive model of speech production,
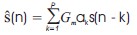
where p is the predictor coefficient, s is the speech sample, and ŝ is the predicted sample, the prediction error is shown in Equation 2.
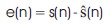
Each frame of the windowed signal is autocorrelated, and the order of the linear prediction analysis is based on the frame with the highest autocorrelation value. LPC analysis converts each frame of autocorrelations into LPC parameters, which are LPC coefficients. Figure 7 shows an overview of the LPC application process. LPC may be calculated using Equation 3.
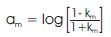
where, am is the linear prediction coefficient, km is the reflection coefficient.
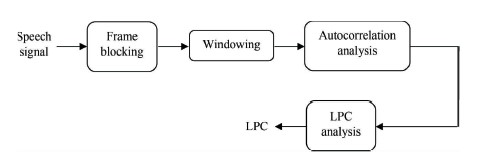
Figure 7. Block Diagram of LPC Processor
Selecting the vocal tract information from a particular speech using linear predictive analysis is effective. Accuracy and computing speed are well-known strengths. The continuous and constant source behaviors are very well represented by LPC. It can also be applied to speaker recognition systems, whose primary goal is to extract the vocal tract's characteristics (Agrawal et al., 2010). It provides extremely precise estimates of speech characteristics and is relatively computationally efficient (Narang & Gupta, 2015). Aliased autocorrelation coefficients cause problems for conventional linear prediction. LPC estimates may not be suitable for generalization because of the high sensitivity to quantization noise (Nehe & Holambe, 2012).
3.1.3 Performance Analysis
LPC performance evaluation includes the following parameters,
3.1.4 Types of Linear Predictive Coding
The different types of LPC are listed as follows,
DSP methods are used for speech analysis, synthesis, coding, recognition, enhancement, voice modification, speaker recognition, and language identification. Speech recognition has developed in a variety of ways over time. The feature extraction methods are employed to extract relevant information from speech signals for speech recognition and identification. This paper describes an overview of the Linear Predictive Coding (LPC) model of feature extraction. The purpose of Linear Predictive Coding is to minimize the bitrate of the speech transmission signal. A sound signal is divided into several segments using Linear Predictive Coding encoders, which subsequently provide information on each segment to the decoder. The quality of the voice signal is decreased as a result of the speech signal's lower bitrates.