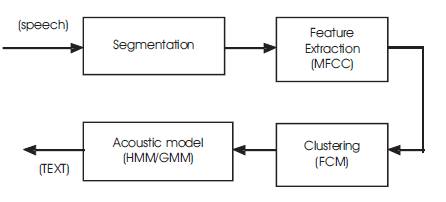
Figure 1. Block Diagram of CSR system
Speech segmentation is the signal processing front-end that segments continuous speech into uniquely identifiable or meaningful units as phonemes, syllables, words or subword and processes them to generate distinguishable features. It reduces the memory size of the input signal (speech) and minimizes the computation time complexity of large sequence of speech signal.
The next step is the Feature Extraction method, The segmented speech signal is parameterized by MFCC. The goal is to extract a number of parameters from the signal that has a maximum of information relevant for the classification. The number of features extracted from the waveform signal is commonly much lower than the number of signal samples, thus reducing the amount of data. The choice of suitable features varies depending on the classification technique. Typically, The Mel Frequency Cepstral Coefficients (MFCC) Extraction method is most suitable for the continuous speech signal recognition process. The extracted features of frames will be grouped using clustering techniques ie., and here we use two types of clustering methods (K means clustering and Fuzzy c means clustering) The clustered data will be handed to the classifiers ie., acoustic models such as HMM ,GMM, KNN, ELM classifiers ,etc., That will produce the text output.
1. Overview of Acoustic Models
Speaker recognition can be classified as speaker verification and speaker identification. Speaker verification deals with validating the identity claim of the speaker. Speaker identification deals with identifying the most likely speaker of the test speech data. Speaker identification can be further classified into closed-set or open-set modes. Closed set speaker identification refers to the case where the speaker is a member of the set of N enrolled speakers. In open-set speaker identification, the speaker may also be from outside the set of N enrolled speakers.
Speaker recognition can be operated in either textdependent or text-independent mode. In text-dependent mode, speech for the same text is used for both training and testing [3]. No such restrictions are imposed in textindependent mode. The present work focuses on the speech recognition from the continuous speech signal. Speaker recognition system may be considered to consist of four stages. They include: speech analysis, feature extraction, speaker modeling and speaker testing. Speech analysis involves analyzing the speech signal using suitable frame size and shift for the feature extraction. Feature extraction involves extracting speaker-specific features from the speech signal at reduced data rate. The extracted features are further combined using modeling techniques to generate speaker models.
The speaker models are then tested using the features extracted from the test speech signal. The improvement in the performance can be achieved by employing new or improved techniques in one or more of these stages. Here developing new modeling techniques are suitable for limited data condition, and using them, instead of existing modeling techniques. This may also improve the speaker recognition performance [1]. Hence the motivation for the present work. State-of-the-art speaker recognition systems employ various modeling techniques like Hidden Markov Modelling (HMM) and Gaussian Mixture Model (GMM). The success of each of the modeling techniques depends on the principle employed for clustering. Among these modeling techniques, the widely used one is GMM. The success of GMM is due to the availability of sufficient data for speaker modeling [4]. Recently, some attempts have been made to recognize the speakers under limited data condition using the concept of Gaussian Mixture Model–Universal Background Model (GMM–UBM).
2. Research Methodology
2.1 Hidden Markov Model (HMM)
HMM is a stochastic signal model and is referred to as Markov sources or probabilistic functions of Markov chains [1]. This model has been mostly applied to speech recognition systems and only recently it has been applied to bearing fault detection. Recent examples will include among others, Purushothama and Baruah and Chinnam [1]. In Hidden Markov Models the observation is a probabilistic function of the state and this means the resulting model is a doubly emended stochastic process with the underlining stochastic process that is not observable and Hidden Markov models are based on the well-known Markov chains from probability theory that can be used to model a sequence of events in time [2] .
However, this process can only be observed through another set of stochastic process that produces the sequence. There are a number of possible Markov models but the left-to-right or barks model is usually used in speech recognition, and is also used in this study [8]. Hidden Markov Model are defined as
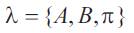
where λ is the model, A , B, and Π is a transition probability distribution, the observation probability distribution and initial state distribution, respectively.
The hidden morkov models provides better recognition in Uncontrolled Environment for speaker identification with Baum-Welch algorithm. [9]
2.2 Gaussian Mixture Model (GMM)
GMM non-linear pattern classifier also works by creating a maximum likelihood model for speech recognition. which is defined as
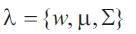
where λ is the model, w, μ, Σ are the weights, means and diagonal covariance of the features. Given a collection of training vectors, the parameters of this model are estimated by a number of algorithms such as the Expectation- Maximization (EM) algorithm, K-means algorithm and many more [5].
In any M order Gaussian mixture model, its possibility density function can be obtained through summing the M Gaussian probability density function with weighted, which can be expressed as the following equation
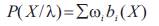
Where X is an D dimension random vector bi (Xt ) i=1,2,3...M.
To obtain a good GMM, a sufficient set of training data is used to train the GMM [3]. The entirely model training process was a supervision and the optimization of the process. And some criterions are used to determine the model parameters [7]. The commonly used criteria to determine the model parameters was the Maximum Likelihood (Maximum Likelihood, ML) criterion. For a length of T training vector sequence, such as x={x1 x2 ,x3 ...xT }the likelihood of GMM can be expressed as the following equation:
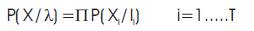
The above equation was a nonlinear function of the parameter λ, and it's more difficult to directly find out its maximum. Therefore, the Exception Maximum (Exception Maximum, EM) calculation is often used to estimate model parameter l of the GMM.
In this study, the EM algorithm is used since it has reasonable fast computational time when compared to other algorithms. The EM algorithm finds the optimum model parameters by iteratively refining GMM parameters to increase the likelihood of the estimated model for the given bearing fault feature vector
2.3 GMM-UBM (Gaussian mixture model-universal background model)
GMM-UBM is the abbreviation of Gaussian mixture model universal background model. It is proposed by Reynolds originally and used in speaker recognition field, aiming to overcome the defects of GMM that is a mismatch of channel between speaker model and testing speech and background noise, especially under the background noise. The matching degree of test utterance and model is very poor [6]. It was first used in speaker recognition system to train and obtain the speaker independent model. However, in this paper, the authors attempt to use it in abnormal voice detection system. GMM- UBM was regarded as the abnormal continuous text independent speech model, which can be obtained by training kinds of abnormal utterances [10]. GMM-UBM is also used in speech recognition.
GMM-UBM for abnormal speech and normal speech obtained respectively, through training a lot of independent-text abnormal voices and normal voices from different speakers. Bayesian adaptive method is mainly used to solve the performance of speech recognition system which dropped sharply, caused by the model mismatch in speech recognition processing and the lack of training speech data. And even in the case of mass training speech data, it can quickly and effectively obtain the speech GMM-UBM.
Conclusion
The acoustic models are the vital role to improve the performance of speech recognition. Using MFCC features together with HMM, GMM and GMM-UBM classifiers, the HMM outperforms the GMM classifier. However, the major drawback of HMM classifier is that it is computationally expensive, more than the GMM to train the features. GMMUBM classifier will improve the Classification Correct Ratio (CCR) compared to other GMM classifiers.