
Figure 1. Illustration of statistical difference method
Many algorithms have been proposed for detecting video shot boundaries and classifying shot and shot transition types. 1 Here we are using two different methods for comparison, using GIST , Color Histogram. Color histogram method draws the histogram for the frames and detects shot comparing these histograms but this is sensitive to illuminance and motion while the GIST uses two different properties of the video i.e color and gist for the detection of the shots. The aim of this paper is to make a comparison between two of the well-known methods used for detecting video shot boundaries. Firstly various methods are described in the preceding sections then a comparison is made about it. This paper shows that the GIST method produces good result over the other method.
Shot-boundary detection is the first step towards scene extraction in videos, which is useful for video content analysis and indexing. Shots are basic units of a video. There are many types of transitions between shots. Shot boundaries can be classified into two main categories: cut and gradual. A cut is an abrupt shot change that occurs over a single frame while a gradual is a slow change that occurs in a number of consecutive frames. With the gradual type, fades and dissolves are common. A fade is usually a change in brightness with one or several solid black frames in between, while a dissolve occurs when the images in the current shot get dimmer and the images of the next shot get brighter[1]. They are required for further video analysis such as:
They provide cue about high-level semantics:
Many approaches have been proposed for shot boundary detection. The simplest approach is to compute the differences between the color distributions of consecutive frames and use a threshold to classify whether a hard cut occurs. In order to detect gradual transitions, edge change ratios or motion vectors can be used [1,2]. Since these approaches use threshold based models for detection, their advantage is they are fast. Nevertheless, they are sensitive to changes in illumination and motion. Furthermore, they are difficult to generalize for new datasets. Recent works [3,4] use machine learning methods for making decisions and have received impressive results.
The basis of detecting shot boundaries in video sequences is the fact that frames surrounding a boundary generally display a significant change in their visual contents. The detection process is then the recognition of considerable discontinuities in the visual-content flow of a video sequence. In the first step of this process, feature extraction is performed, where the features depict various aspects of the visual content of a video. Then, a metric is used to quantify the feature variation from k frame to frame k+l. The discontinuity value z(k, k+l) is the magnitude of this variation and serves as an input into the detector. There, it is compared against a threshold T. If the threshold is exceeded, a shot boundary between frames k and k+l is detected. To be able to draw reliable conclusions about the presence or absence of a shot boundary between frames k and k+l, we need to use the features and metrics for computing the discontinuity values z(k, k+l) that are as discriminating as possible. This means that a clear separation should exist between discontinuity-value ranges for measurements performed within shots and at shot boundaries.
Further in this paper section 1, shows the different features that can be used to measure visual discontinuity, section 2, shows the method used to implement video shot boundary detection algorithm, section 4, gives a comparison between different methods.
Two common approaches[18]:
Figure 1. Illustration of statistical difference method
Use motion vector to determine discontinuity[18]. This can be seen in the Figure 2.

Figure 2. Example of motion vector method
The most common method used to detect shot boundaries.
Many algorithms have been proposed for detecting video shot boundaries and classifying shot and shot transition types. Few published studies compare available algorithms, and those that do have looked at limited range of test material. A comparison of several shot boundary detection and classification techniques can be done using their variations including histograms, discrete cosine transform, motion vector, and block matching methods. The performance and ease of selecting good thresholds for these algorithms are evaluated based on a wide variety of video sequences with a good mix of transition types. Threshold selection requires a trade-off between recall and precision that must be guided by the target application.
The approach here takes each (352 × 288) frame of the video and computes a color histogram using a total of 192 different colour bins where each bin contains the percentage of pixels from the whole frame. When this is done, the color histogram for each frame is checked against the histogram for the one following and a similarity metric is used to compute the likeness between the two adjacent frames[15]. When the sequence of similarity values is analysed, a shot will show a big change in the sequence where the shot boundary occurs, so by looking for these peaks in the differences, a shot boundary can be detected. The peak in the values is required to be above some minimum value before it will be detected as a shot cut
Video programmes will have many different types of shot boundaries, and those where the shot boundary occurs over a number of frames may not be detected by the method above. For example, a fade or dissolve occurring over a 3 second period in, say, a cookery or gardening program will span a total of 75 frames and the incremental difference between adjacent frames in this sequence will be quite small. Furthermore, it is possible that the two separate shots in such a transition may have similar colouring and hence colour histograms, anyway. Such omissions are difficult to avoid using colour histogram based segmentation, but nevertheless this method is very popular and if used correctly it is very reliable and accurate. On the downside it is slow to compute because each frame of the digital video has to be decoded and calculations run on it to extract color values.
This approach looks not at the colour differences, but at the differences between the edges detected[22] in adjacent frames. Each frame in the digital video is turned into a greyscale image and Sobel filtering applied to detect edges. The method looks for similar edges in adjacent frames to detect a shot boundary. The principle behind the edge detection approach is that it can counter problems caused by fades and dissolves and other transitions which are invariant to gradual colour changes. With edge detection, even when there are gradual transitions between shots, there should always be a pair of adjacent frames where an edge is detected in one, and not in the other and identifying an occurrence of this on a large scale locates a shot transition. Like the colour-based method above, this will require a minimum difference between adjacent frames to detect a shot cut but it has the advantage of not being fooled by a large colour change for example when we get a camera flash. In such a case the colour-based methods will register a large difference in colour and as a result it will detect a shot boundary but the edge detection method will be looking for pixel edge differences. The downside of this technique is that it needs to decode each frame and as a result may compute slowly.
The third of our methods for shot boundary detection, unlike the others, is based on processing the encoded version of the video[15]. One of the features of MPEG-1 encoding is that each frame is broken into a fixed number of segments called macroblocks and there are three types of these macroblocks, I-, P- and B-. The classification of the different macroblock types is done at the encoder, based on the motion estimation and efficiency of the encoding.
I-macroblocks are encoded independently of other macroblocks and are used when the segment being encoded is very different in appearance from other segments around it in the same frame, or the corresponding segment in previous or following frames. Pmacroblocks do not encode the region in the frame but instead have a motion vector which indicates the difference between the current block being encoded and the corresponding block in the previous frame. This is refered to as motion compensation and is used in video coding where objects remain stationary or move only a short distance between adjacent frames. B-macroblocks are bi-directionally predicted blocks and use both forward and backward prediction.
Different types of video sequence lead to different uses of IB- and P-macroblocks and different types of shot transitions in particular tend to have particular characteristic uses of macroblocks. Our use of macroblocks in this work is to see if we can identify and use these characteristics to determine shot boundaries directly from the compressed form of the video. For example, if a frame type that would be expected to contain backward predicted blocks does not actually have any, then it could be suggested that the future picture changes dramatically and this could indicate a shot boundary. Because it operates on the encoded form directly, it is likely to be more efficient than the other methods we use.
Although many methods have been proposed for this task[16], finding a general and robust shot boundary method that is able to handle the various transition types caused by photo flashes, rapid camera movement and object movement is still challenging. The authors present a novel approach for detecting video shot boundaries in which we cast the problem of shot boundary detection into the problem of text segmentation in natural language processing. This is possible by assuming that each frame is a word and then the shot boundaries are treated as text segment boundaries (e.g. topics).
The text segmentation based approaches in natural language processing can be used. The shot boundary detection process for a given video is carried out through two main stages. In the first stage, frames are extracted and labelled with pre-defined labels. In the second stage, the shot boundaries are identified by grouping the labeled frames into segments. We use the following six labels to label frames in a video: NORM FRM (frame of a normal shot), PRE CUT (pre-frame of a CUT transition), POST CUT (post-frame of a CUT transition), PRE GRAD (pre-frame of a GRADUAL transition), IN GRAD (frame inside a GRADUAL transition), and POST GRAD (post-frame of a GRADUAL transition).
Given a sequence of labelled frames, the shot boundaries and transition types are identified by looking up and processing the frames marked with a non NORM FRM label. It uses a support vector machine (SMV) for the purpose of shot boundary detection.
The motion activity is one of the motion features included in the visual part of the MPEG-7 standard. It also used to describe the level or intensity of activity, action, or motion in that video sequence. The main idea underlying the methods of segmentation schemes is that images in the vicinity of a transition are highly dissimilar. It then seeks to identify discontinuities in the video stream. The general principle is to extract a comment on each image, and then define a distance [5] (or similarity measure) between observations. The application of the distance between two successive images, the entire video stream, reduces a one-dimensional signal, in which we seek then the peaks (resp. hollow if similarity measure), which correspond to moments of high dissimilarity.
In this work [19], the authors used the extraction of key frames method based on detecting a significant change in the activity of motion. To jump 2 images which do not distort the calculations but we can minimize the execution time. First we extract the motion vectors between image I and image i+2 then calculates the intensity of motion, we repeat this process until reaching the last frame of the video and comparing the difference between the intensities of successive motion to a specified threshold. The idea can be visualised in Figure 3.
Figure 3. The idea of video segmentation using motion intensity
A new method for shot boundary detection using independent component analysis (ICA) is presented. By projecting video frames from illumination-invariant raw feature space into low dimensional ICA subspace, each video frame is represented by a two-dimensional compact feature vector. An iterative clustering algorithm based on adaptive thresholding[23] is developed to detect cuts and gradual transitions simultaneously in ICA subspace. This method has the following major steps: (i) Raw feature generation from illumination-invariant chromaticity histograms; (ii) ICA feature extraction; (iii) Dynamic clustering for shot detection.
The algorithm utilizes the properties of QR-decomposition and extracts a block-wise probability function that illustrates the probability of video frames to be in shot transitions [20]. The probability function has abrupt changes in hard cut transitions, and semi-Gaussian behaviour in gradual transitions. The algorithm detects these transitions by analyzing the probability function.
In this method we detect scene boundaries by considering the self-similarity of the video across time. For each instant in the video, the self similarity for past and future regions is computed [21], as well as the cross-similarity between the past and future. A significantly novel point in the video, i. e. a scene boundary, will have high self-similarity in the past and future and low cross-similarity between them.
Gist means Gesture Interpretation Using Spatio-Temporal Analysis, where Spatio-Temporal means which has both space as well as time properties like the movement of hand which shows the variartion in both space as well as time. Gist [6,7] has been shown to characterize the structure of images well while being resistant to luminance change and also small translation. They use gist representation to model the global appearance of the scene. Gist treats the scene as one object, which can be characterized by consistent global and local structure. This method differs from prior work that characterizes scene by the identity of objects present in the image. Gist has been shown to perform well on scene category recognition [6]. Gist also provides good contextual prior for facilitating object recognition task [7]. Within one shot, due to the motion, appearance or disappearance of objects, the color histogram may not be consistent. Gist captures the overall texture of the background while ignoring these small change due to foreground objects.
In order to compute gist-features we resize the image into 128x128 pixels. The filters used to compute gist are divided into 3 scales and 8 orientations. After convolving with each of the 24 filters, images are equally divided into 16 blocks, and the average is taken for each block. This results in a 384-dimensional (16 x 24) vector. The dimensionality of the features is reduced by using PCA. We retain the top 40 components as our gist representation. To represent the color-content of the image, the authors compute a global histogram with 10 uniformly placed bins in RGB as well as HSV color-space. This results in 60 additional dimensions encoding the color. They also observe that abrupt shot boundaries are marked by sharp-changes in the gist and color features. However, the absolute change in features is not consistent across videos or even across different shot boundaries within the same videos. Thus, a simple pair-wise frame difference will not work in order to detect shotboundaries. Gist method uses both color as well as gist properties of the image for detection of shot boundaries.
Here the researchers are using four different methods involved in video shot boundary detection for comparison, GIST and Segmentation.
The simplest approach is the color histogram to compute the differences between the color distributions of consecutive frames and use a threshold to classify whether a hard cut occurs. In order to detect gradual transitions, edge change ratios or motion vectors can be used [1, 2]. Since these approaches use threshold based models for detection, their advantage is they are fast. Nevertheless, they are sensitive to changes in illumination and motion. Furthermore, they are difficult to generalize for new datasets. This technique is able to differentiate abrupt shot boundaries by the analysis of color histogram differences and smooth shot boundaries but temporal color variation[17]. This provides a simple and fast algorithm able to work in real-time with reasonable high performances in a video indexing tool.
The algorithm firstly extracts abrupt shot discontinuities by the analysis of the color histogram difference, and then it detects possible gradual discontinuities for the following discrimination from motion activity as they behave a smooth discontinuity pattern. The simplicity of the method relies on the low complexity of the computation of the color histogram difference and that the most of the subsequent analysis is performed over the resulting 1-D signal. Unlike techniques based on pixel difference between adjacent frames, color histogram techniques reach a higher degree of independence to object motion within a frame sequence. A shot is detected by comparing the present value with a threshold value. The threshold value for cut detection used in the first derivative signal is obtained from the percentage of the maximum possible value of the color histogram difference. A cut is only detected when an abrupt variation overcome a certain percentage of color change in a video sequence.
The advantage of this method is that it takes into account the global variation of the image, being therefore less sensitive to camera or object movement. But due to the continues appearances and disappearance of the objects with a shot the histogram may not be consistent also it is sensitive to luminance as well as motion which shows its major disadvantage.
In this method we apply gist and color features to represent the individual frames. Gist [6,7] has been shown to characterize the structure of images well while being resistant to luminance change and also small translation. Thus, it is ideally suited for our application of shot boundary detection. The most intuitive way to detect shot change is to compute the pixel difference of two consecutive frames, if the overall difference is larger than some threshold, it is detected as a shot boundary [8],[9]. This method results in a large number of vectors and is susceptible to camera motion and object motion. The sensitivity to motion is reduced by extracting features from the whole frame, among which histogram is the mostly used [10,11,12]. The disadvantage of global features is it tends to have low performance at detecting the boundary of two similar shots. To balance the tradeoff of resistance to motion and discriminating similar shots, a region based feature is proposed. Region-based method divides each frame into equal-sized blocks, and extracts a set of features per block [13,14]. Based on the assumption that color content doesn't change rapidly within but across shots, color is the mostly used features [8], others are edges and textures [13].
Assume that features computed in the first stage are similar within one shot but vary across shots, one can compute the distance of feature vectors of adjacent frames, and compare it against a threshold. A distance higher than the threshold usually corresponds to a hard cut. This fixed threshold is hard to detect gradual transitions because of its slow-changing nature [13]. In addition, most videos have variations in each frame and also sudden change within one shot, such as appearance of a new object. Computing the distance of multiple frames will cancel these variations [13]. Another method is to vary the threshold depending on the average distance within the current shot or the statistics of the whole video [9]. The problem was also formulated as a binary classification task in which two classes are “transition” and “no transition”.
Within one shot, due to the motion, appearance or disappearance of objects, the color histogram may not be consistent. Gist captures the overall texture of the background while ignoring these small change due to foreground objects. A classifier trained to detect such rare occurrence would be biased to treat all frames as nontransition. But the classifier approach is impractical. Instead, we treat the task of detecting shot boundaries as an outlier detection problem. We use a simple z-score metric to determine outliers. The first strategy measures the z-score across all dimensions (assuming they are independent). The second strategy counts the number of dimensions in which the given data-point is an outlier. In practice, we observe that both strategies perform well. We define detected interval as the interval of the group of consecutive detected frames, and its width the number of frames it contains. For each detected interval, we mark it as cut if its width is higher than some threshold wt, as gradual transition otherwise.
This method proposed gist and color features for shotboundary detection in video. This method posed the task as an outlier detection problem in the gradient domain and proposed a simple z-score based approach to solve the problem. We observe that gist is better than color features for detecting abrupt transitions. However, color performs better for gradual transitions.
In this paper the authors presented various different approaches used for video – shot boundary detection process and give a comparison between some of the most commonly employed methods. They concluded from the above discussion that all these methods has some or the other problem and some of its advantages.
The method that seemed to produce good results was the GIST method. As it used two different approaches color and gist advantages at different stages i.e the gist feature gives efficient result in the case of abrupt shot detection while color feature produces good results in case of gradual transitions. The best performance[24] for the system(GIST) is: 84% precision and 91% recall for cuts. The median performance for the same task is 88% precision and 87% recall. The best system performance for gradual transitions is 60% precision at 70% recall. The median performance is 70% precision at 62% recall. Thus our system compares very favorably to existing approaches although we use a very simple decision rule. This can also be depicted via a graph [24] as shown in Figure 4.
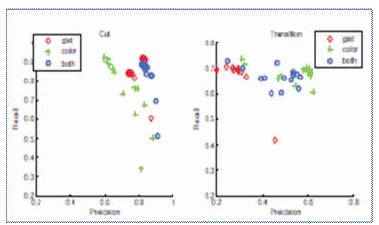
Figure 4. Precision recall of cuts and transitions using gist only (red), color only (green) and both (blue)
In the above graph we compare the performance of three sets of features: (1) gist-featres only, (2) color-features only and (3) gist and color. It is observed that using gist-only performs well for detecting cuts but not as well for detecting gradual transitions. However, color features alone perform better than gist for detecting gradual transitions. A combination of both features performs better than either used in isolation.