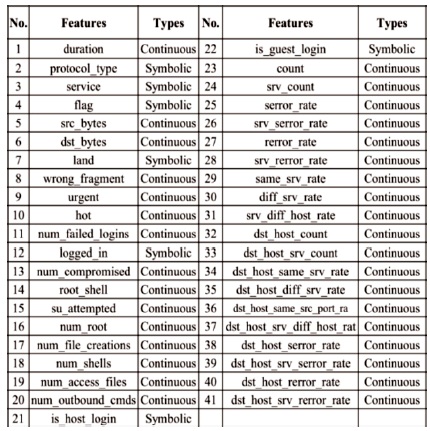
Table1. NSL-KDD Dataset Features (NSL-KDD Data Set., n.d.)
With the advancement of networking applications, the need for security to resolve malicious activity in the network has increased. Network intrusion detection has evolved as a significant security system in networks, enabling it to detect unauthorized access to any network traffic. Through network intrusion systems, a warning message was attained to take necessary action to avoid malicious attacks. However, there is still the need for improvement in network intrusion system since the advancement in technology has created complexity over the detection system, making the current detection system is not effective. Intrusion Detection System (IDS) usually operates based on a trained network traffic pattern. It is defined in such a way that if there exist any variant on the traffic pattern, intrusion will be detected. We need a solution to avoid network attacks, which can be achieved with IDS. Machine Learning (ML) algorithms play a key role in all sectors and domains. In this paper, we investigated the various supervised machine learning algorithms such as Naive Bayes, Random Forest, SVM and XGBoost, and the performance of each algorithm concerning accuracy. This study helps in finding a suitable algorithm to identify the attacks with more accuracy. We used the standard intrusion dataset, i.e. NSLKDD from Canadian Institute for Cyber Security.
Security mechanisms, such as firewalls, authentication, cryptography, and access control, are used as a first line of defence for security problems and issues. However, these anti-threat applications are unable to detect internal intrusions and inadequately provide security counter measures. Therefore, various types of intrusion systems that originated from Intrusion Detection Systems (IDSs), such as Intrusion Prevention Systems (IPSs) and Intrusion Response Systems (IRSs), were developed to detect, prevent, and respond to intrusions.
An IDS is a collection of software or hardware resources that can detect, analyze, and report intrusions in a computing system. As an extension of IDS, an inline IDS or IPS detects and prevents potential intrusions in real time (Inayat et al., 2016).
On the other side, the prompt development of information technology has produced several challenges in building reliable networks which are challenging operations such as threatening the availability, integrity and confidentiality of computer networks due to various types of attacks. The Denial of Service (DoS) attack is considered as one of the most common harmful attacks. An intrusion detection system is used to give an accurate result and to predict the type of attack. The objective of this paper is to produce a computerized system that can provide the best accuracy rate by the validation techniques. Nowadays, in information security, message detection is a property that a message should not be modified. While pre-processing the dataset, we calculate the performance measures like accuracy, recall and precision to generate Receiver Operating Characteristic (ROC) curves. Using the latest dataset of intrusion detection model, we compare various data validation techniques to get the best accuracy rate. Also, we can predict which types of attacks using algorithms belongs to machine learning (Hindy et al., 2018; Sekhar & Rao, 2019).
The scope of our paper is to provide a best accuracy rate by comparing various machine learning algorithms and also to provide the type of attack by considering some of the attributes like protocol type, duration, and flag. We are using the latest version of dataset in the intrusion detection model to provide accuracy as well as the confusion matrix to predict the attacks. The motivation behind this work is to improve the efficiency of IDS as well as to reflect network threats more accurately in future datasets.
Literature is a crucial part of any research, and it helps to know what is happening in the specific field. Towards the intrusion detection, we have gone through the previous researcher's research and their findings. We have provided precise information on various researchers who worked on IDS.
Almseidin et al. (2017) researched and made a comparison of different algorithms such as J48, Random Forest, Naïve Bayes and Multilayer Perceptron (MLP) using performance measures like accuracy, ROC and also compared the accuracy measures. As a point of their research on IDS, they performed solutions to deadly attacks. An unauthorized person who wants to steal the credentials of others can try with the help of various tools. They performed several experiments on KDD dataset with ML methods. The performed investigations showed that the decision table classifier achieved the lowest value of false negative to produce the highest average accuracy rate. Based on their analysis, it was found that only one ML method performance was not well for any attack. From the observed results, it was found that the Random Forest (RF) method would give better accuracy with 93.77%. They build training models for all machine learning concepts except MLP.
Anwar et al. (2017) analyzed an investigation on intrudes, kind of attacks considering the researcher papers from 2008 to 2018. Based on the analysis, they identified that most of the researchers used K-mean, SVM and ANN models. Furthermore, the manuscript tackles the problem of having a generic taxonomy for network threats. They classified the attacks on networks as active or passive. This survey suggests that over 97% of researchers use machine learning concepts for finding intrudes on the network. There is no standard dataset available to find the real-world attacks on network architecture.
Ren et al. (2019) investigated different machine learning algorithms to perform the accuracy for the comparison of algorithms and to predict the type of attacks. An IDS can effectively identify the anomaly behaviors in a network. They come up with data optimization concept, which consists of two parts: feature selection and data sampling. Genetic Algorithm was used to optimize the samples and Isolation Forest was implemented for removing the outliers. Optimal feature subset was obtained with the help of Random Forest (RF) and Genetic Algorithm (GA). This experiment was done in UNSW- NB15 dataset.
NSL-KDD dataset generated in 2009 is widely used in intrusion detection experiments. The dataset covers the KDD TrainC dataset as the training set and KDDTestC, and KDDTest21 datasets as the testing sets, which have different regular records and four different types of attack records. There are 41 features and 1 class label for every traf_c record, and the features include basic features (No.1- No.10), content features (No.11 - No.22), and traf_c features (No.23 - No.41) as shown in Table 1. According to their characteristics, attacks in the dataset are categorized into four attack types: DoS (Denial of Service attacks), R2L (Root to Local attacks), U2R (User to Root attack), and Probe (Probing attacks). The testing set contains some speci_c attack types that disappear in the training set, allowing for a more realistic theoretical basis for intrusion detection (Lee et al., 2018; NSL-KDD Data Set., n.d.; Yin et al., 2017).
Table1. NSL-KDD Dataset Features (NSL-KDD Data Set., n.d.)
The major objective of this paper is to develop a computerized system that provides the best accuracy rate by the validation techniques. Using the latest dataset of Intrusion Detection Model, we compare various data validation techniques to get the best accuracy rate. While pre-processing the dataset, we compute the performance measures like accuracy, recall and precision to generate ROC curves. Using the latest dataset, we can also predict which types of attacks using algorithms belongs to machine learning (Haq et al., 2015; Patel & Buddhadev, 2014; Yin et al., 2017). ROC curves. Using the latest dataset, we can also predict which types of attacks using algorithms belongs to machine learning (Haq et al., 2015; Patel & Buddhadev, 2014; Yin et al., 2017).
The proposed system is designed in a way to enhance the better result of the existing system by updated approaches using machine learning algorithms and programming language like Python to generate more accurate results.
The proposed system gives better results compared to the existing system. In this proposed system, we are using NSLKDD dataset to generate the output. With the help of those approaches, we are calculating not only performance measures but also declaring the type of attack.
Here we are going to discuss briefly the few machine learning algorithms used for detecting the intrudes and attacks.
One of the popular classification models was the Naive Bayes method, which is based on the probability of samples to classify the records for different classes. The initial step of Naive Bayes classifier is to find out the total number of classes and calculate the conditional accuracy for each dataset classes. After that, the conditional accuracy would be calculated for each attribute. The best applications of this technique are filtering the spam in the inbox, medical disease prediction, and analysis of the test.P (Evidence/Outcome), i.e., know data from train data
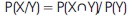
P (Outcome/Evidence), i.e., know predicate data from test data.
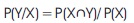
From the above two equations, Bayes rule is given as follows:
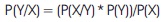
where,

Based on Bayes rule, we are going to extend Naive Bayes when multiple X variables as independent of each other.
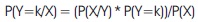
where, k is the class of Y.
SVMs are used when the data points are not linearly separable. Data points should be classified into different labelled classes. SVMs can able to perform both linear and non-linear data separation. They find the hyperplane to separate the data points. The hyperplane plays a pivotal role in separating the data. For practical implementation, available data points are divided into train and test sets. Using these sets, model build happens. Figure 1 shows the SVM algorithm for Optimal Hyperplane.
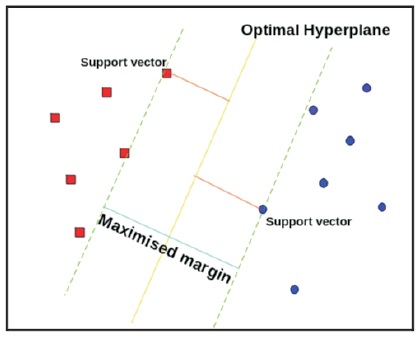
Figure 1. SVM Algorithm for Optimal Hyperplane
RF is a leading supervised method to classify the data. Data can be classified in the tree fashion. It takes more number of features to generate more trees. Each feature will act as a root for each tree.
Pseudo Code of RF:
Step 1 − Random sample selection from the NSL-KDD data set.
Step 2 − Based on the sample selection, a decision tree constructed. The outcome will be predicted from each decision tree.
Step 3 − Based on the predicted outcome, voting will be performed.
Step 4 − Finally, choose the predicted outcome with more votes.
In 2014, a researcher Tianqi Chen proposed a part of his project towards distributed machine learning community. It can work with any data type. It can work on data to classify the regression models. The advantage of XGBoost is that it can personalize the tree, shrink the leaf nodes based on the need and randomization of the parameters.
Development of XGBoost Algorithm from Decision Trees (He, 2018)
On understanding the concept and nature of the working mechanism of the algorithms, we would implement it using Python programming and machine learning libraries. Figure 2 shows the stepwise implementation process, each time we have to take one algorithm and find out the accuracy.
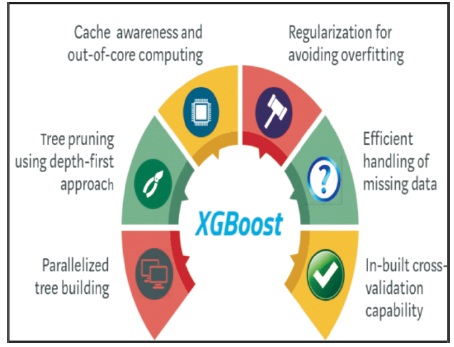
Figure 2. XGBoost Optimizes Standard GBM Algorithm (He, 2018)
Figure 3 shows the stepwise process to implement any machine learning algorithm on the dataset which involved in significant steps like pre-processing, learning, Evaluation and prediction.
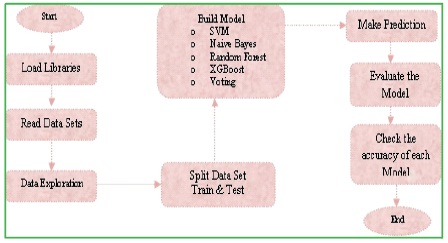
Figure 3. Implementation of Machine Learning Methods
During pre-processing, we are eliminating the noisy, duplicate and missing samples. By using one of the hot encoder techniques, we can convert the few attribute values from string type to numerical type. The whole dataset was split into train and test set with 80% and 20%.
During learning stage, SVM, Random Forest, Naive Bayes, XGBoost and Voting techniques are trained on the training dataset and fit the models for prediction.
Here, we would evaluate the model with new data and provide the performance accuracy.
Step 1: Initially, we have to load the required libraries such as data processing, file handling, visualizations and ML method.
Step 2:Reading the data set which has taken from NSL-KDD.
Step 3: Applying the data pre-processing techniques to process the dataset.
Step 4: Once the dataset is ready, we have to split it into training and test sets with 80% and 20%, respectively.
Step 5: Build the model using machine learning algorithms; here, we are using 5 algorithms.
Step 6: Make a prediction on the model for each algorithm.
Step 7: Now, evaluate the model with respect to predicted models.
Step 8: Comparing each algorithm based on the accuracy (Table 2).

Table 2. Accuracy Comparison
Figure 4 shows the comparison analysis of 4 machine learning algorithms on NSL-KDD dataset.
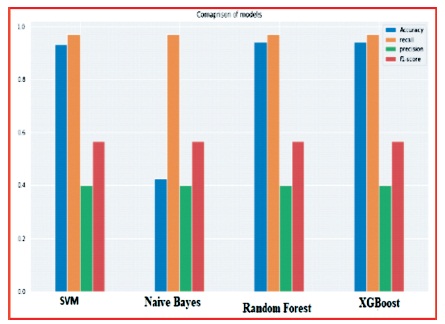
Figure 4. Comparison of ML Methods
Figure 5 and Figure 6 shows the generation of confusion matrix and attack identification scores of Random Forest and XGBoost algorithms, respectively.
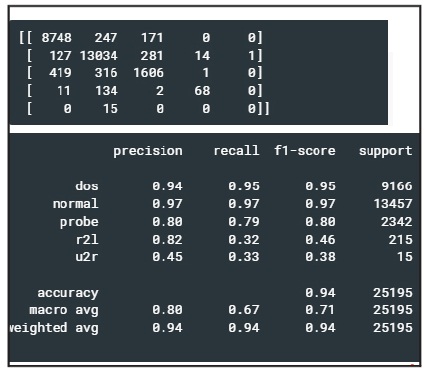
Figure 5. Confusion Matrix and Attack Classification Scores by Random Forest
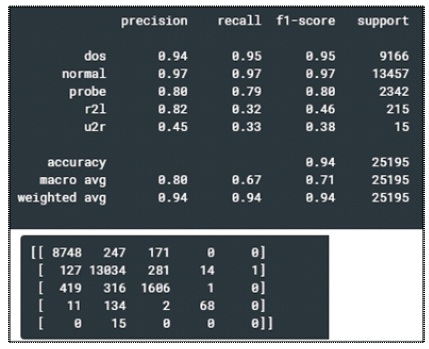
Figure 6. Confusion Matrix and Attack Classification Scores by XGBoost
In this study, we have used NSL-KDD data set for identifying the different attacks like Root to local, the user to Root, DoS and Probe. To find the intrudes, we applied machine learning techniques to evaluate the efficiency and the performance of the following machine learning classifiers: SVM, Random Forest, Naive Bayes, Extreme Gradient Boost algorithm. All the tests are based on the NSL-KDD intrusion detection dataset. The rate of the different type of the attacks in the NSL-KDD dataset is DoS attacks of standard packets and other types of attacks (R2L, U2R and PROBE). We have taken 80%, 20% of samples as train and test set, respectively from the dataset. Several performance metrics are computed (accuracy rate, precision, false negative, false positive, true negative and true positive). With the help of methods mentioned above, it was found that the performance accuracy of SVM is 93% with 95% F1 score for DoS attacks, Random Forest giving 94% with 95% F1 score for DoS attacks and 80% Probe attack, XGBoost 94% accuracy with 95% F1 score. From the results, it was observed that both Random Forest and XGBoost give better performance compared to other algorithms.