Figure 1. Entity Relationship Diagram For SARPS Database
A huge amount of time is spent on manual vetting of processed results to resolve errors in the output generated from the computerization of students academic results for higher institutions in Nigeria. This is not only for salient errors that can be discovered during the verification of results, but also for inconspicuous errors that pass through computed results unnoticed. Such errors can be attributed to errors associated with technical designs of the database and noncompliance of results processing with the institution's rules and study requirements, especially when such rules and requirements are violated. Currently, such errors, in most cases, are often resolved by manual vetting after processing. Some technical issues need to be resolved for reliable computerization of student results. This study provides design solutions that guarantee the correctness and responsiveness of result outputs without manual intervention in computerizing the academic results of the students. The results show that such design approaches save the time spent on manual vetting of computerized results and ensure the reliability of the processing system. Some technical issues are identified and corrected in the development of the system, in addition to the computations of the semester and cumulative GPAs.
Many of the existing database systems used in educational institutions for processing examination results are challenged with design problems making them inadequate and error-prone when used for processing students academic records. (Omilabu et al., 2016). Building a database for results processing is one thing; ensuring it serves the intended purpose is another. One important aspect of database design for students' results processing is that it must be useful, reliable and meets the very need of the operations it is designed for. The problem of result processing is unique to each institution. Different universities use various patterns of grading systems. Differences exist in the number of courses available, the values of course units, the types of course codes, the number, and type of course prerequisites, variations in the systems of managing continuous assessments and disparity in the styles of preparation of reports used by different institutions. Every university has its unique style of preparation and presentation of students' results. As such, it is practically difficult and awkward to implement result processing system used by one University to another unless the processing system is adapted for use by other universities. Otherwise, every university requires a customized processing system to minimize processing time, reduce computational errors, and achieve higher efficiency.
Current student academic records processing systems, in most cases, have failed to reduce or eliminate delays and stress due to manual efforts during processing and verification of processed results (Dar ,2018). In some cases, new errors have been introduced into the original data as the result of computerization. Reliable, computerized user friendly students result processing system should meet the needs of the user community. For instance, as a rule, every institution places a boundary for minimum and the maximum number of units a student can register in one semester. Besides, there is a requirement that stipulates courses which the student had qualified in the previous semester cannot be registered again. A major expectation from the student results processing system is the ability to provide integrity and consistency to data stored in a database. This should be done with referencing and manipulation of data without changing its integrity. There is case of data redundancies that must be avoided in the development of a good relational database. For a good implementation, the design must implement same validation rules and same data types, while the default values for same types of data must be maintained.
In this study, we aim to design an efficient, scalable and performance driven database system for processing student academic records for higher institutions in Nigeria. We used an efficient database design technique to achieve the following goals.
Writing computer programs to process and manage students' records is not a new concept (Alameri and Radchenko, 2017; Dar, 2018; Eludire, 2011; James, 2014; Udeze et al., 2017). Amare et al. (2018) revealed some of the various attempts involved in the computerization of results. The entire process of computation of students results become complex, more delicate and tedious when it is performed for a large number of students who registered different number and different types of courses having diverse course units. With the advent of computer systems, the manual paper based filing system was replaced with File-Based Systems (FBS) (Bowers, 2017). Data could be accessed more efficiently if they were stored on the computer. However, with problems such as data separation and isolation, data dependence, data duplication, incompatible data (i.e., data with different file formats), lack of flexibility in organising and querying the data, and the increased number of different application programs, FSB has favored the use of record processing to a better and more reliable DataBase Management System (DBMS).
The benefits of a well defined computerized student record processing using DBMS cannot be over-emphasized. Watt (2018) discussed the benefits as the ability to report information for decision making about individual students, schools, programmes, and the efficiency in processing and exchanging student records among schools. Many studies have been done about the designs and implementations of students' results processing of which some related works are considered. Matemilayo et al. (2017) presented a web-based architectural framework suitable for implementing a centralized transcript processing system in Nigerian tertiary institutions. Ukem and Ofoegbu (2012) developed a computer software application using relational database design and web technology to facilitate the automated processing of the results. The work consisted of level based result computations for individual students, but not the overall transcript showing the computation of all registered courses overall studies from one level to a higher level. Also, it does not show a computed level-based result broadsheet which displays the processed results of the students in a level of study. Matemilayo et al. (2017) presented seasonal results broadsheet for a level of study in a department, and Añulika et al. (2014) developed a computer software application to facilitate the automated processing of the results for public secondary schools.
A database is an electronic system used to collect, organize and store data in a way that simplifies data access, data manipulation and updates. Each list (called a table) must have only one topic (entity) and be unique (for example, "Student"). Databases are implemented and managed by database management systems, for example, SQL Server, MySQL, Oracle, MS Access, etc. The external database architecture corresponds to how the user related to objects in the database. Also, it represents the set of data within the database that corresponds to the operations performed by the user (Olivera, 2019). The internal database architecture defined the relationships among data and database entities, operations on data, and the correctness of database operations, scalability, costs, and performance issues. The result of record processing with the database includes improved data access and system performance. It enables increased productivity due to increased concurrency, improved data backups, and recovery and the ability to do more analysis of the same amount of data. Many advantages of DBMS for data management include data sharing, data consistency, data integrity enforcement, data security, data independence.
The earliest type of database is the hierarchical DB, Data Base (DB) then followed by the network DB, and finally the rational DB (Watt, 2018). A Flat Database (FD) is a database with limited functionalities where data is organized in a single table with a fixed number of fields (columns) as it exists in an excel table. An Object-Oriented DataBase (OODB) organizes data similarly to the object-oriented programming paradigm such that objects consist of data and methods associated with the data. Objects with similar data and methods are grouped into classes. Although other types of DBMSs are in use today, relational databases are proved to be more successful and widely used for record processing (IBM Corporation, 2013).
A Relational DataBase (RDB) is a collection of 2-dimensional logically independent tables, which consist of rows and columns. In RDB, no duplicate rows occur in a single relation (or Table). Tables can use SQL (Structured Query Language) to reference shared data in another table, preserving the integrity of original data (Coronel & Morris, 2016). This is known as referential integrity. With referential integrity, database relationships are kept consistent with the underlying entities and SQL. SQL queries provide efficient support for many-to-many relationships in relational databases (Olivera, 2019), more efficiently than with programming languages that cannot provide support for consistency of referenced objects in handling many-tomany relationships. Operations such as SELECT, CREATE, DELETE, UPDATE, JOIN, etc., can be performed on tables to provide transactions. Relational DataBase Management Systems (RDBMS) provide several required features for the success of data base design and implementation among the following:
The design issue refers to the basic issues that arise when designing relational database schema and proper approach to solving them. Implementation of database schemas follows the physical model structure which is produced from the conceptual and logical models for database construction. Teorey et al. (2015) describes the concepts used in the implementation of DataBase Design (DBDSGN), an experimental physical design tool for relational databases developed at IBM San Jose Research Laboratory. Mallig (2010) developed a relational database schema for a biblio metric database as an entity relationship diagram using the structural information typically found in scientific articles. Here, we emphasize some of the worst practices in the design of databases, and discuss some of the pitfalls of avoiding achieving a best database designs (TechTarget, n.d.;).
Normalisation is a process of restructuring the original forms of tables in a database into normal forms (1NF, 2NF, 3NF, etc). It was proposed by Codd (1971) as a means of preserving data integrity and eliminating data redundancy. It provides flexibility for storage and retrieval of data objects stored across data tables and enables the mapping of objects with data across multiple storage. It is a way of enforcing integrity constraints on the dependencies that exist among attributes and relations in a database. Non-normalised databases increase data redundancies and are subject to errors since the integrity and reliability of data are compromised.
Keeping many different versions of redundant attributes and tables up to date becomes a big problem to data redundancies. A major bad effect of data redundancy is data corruption and inconsistency. It may increase the size of the database unnecessarily and thereby reducing the overall efficiency of the data.
Database engines may offer features that support indexing, aggregate functions, locks to protect data, constraints that enforce data correctness, etc. Taking these features often ensures better database designs and implementation.
The primary key ensures the unique existence of data under an attribute that uniquely identifies a row in a database table. Composites keys are the combinations of more than one attribute (column) playing the row of a primary key. It is a good design decision supported by many database engines. However, since composite keys can rapidly increase the number of rows in a database and reduce the performance of the database indexing engine, many designers propose the use of simple integer ID primary keys for improved efficiency.
Querying a database is achieved by applying indexes on columns within a table or among multiple tables. The performance of indexes on data often depends on the data types of the attributes, it is a good design practice to carefully consider the data types of columns in a table that will result in better indexing performance. For instance, indexing on INT data type is faster than on DATE or DECIMAL data types.
A Referential Integrity (RI) in a relational database ensures the data, when referenced in another table within the database, does not change in value, type or scope throughout the database operation. It ensures that the relationship among tables in the database is always consistent in all times. This means that any changes in the primary key are reflected in the foreign keys that referenced it. Similarly, any updates to the foreign keys must be applied to the primary key they referenced.
Several approaches to detect errors in designing the database and eliminate them were presented in some previous studies. Currim et al. (2014) describes a Modeling Expertise Framework (MEF) that uses modeler expertise to predict errors through the classification of cognitive processes based on the Revised Bloom's Taxonomy (RBT) that can be applied to knowledge activities such as conceptual modeling. Nicolaos and Katerina (2015) presented an approach based on 'simple-talking' to abstract database terminology and logic from the application development process.
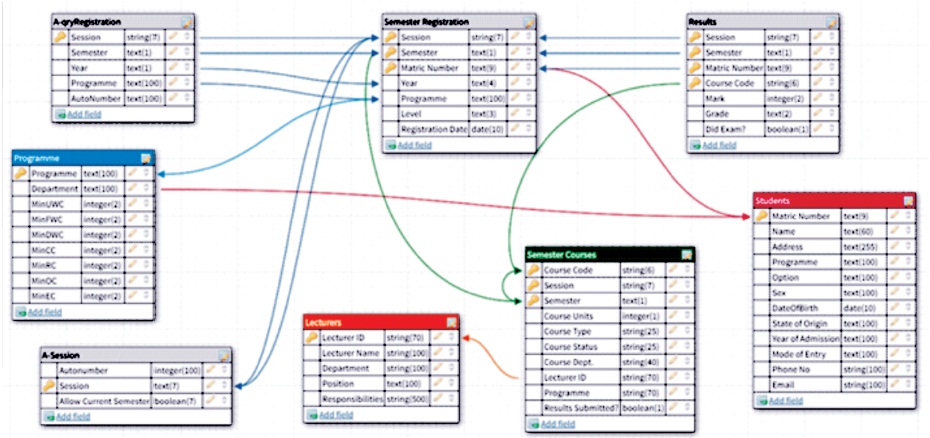
The project used a Relational Database Management System (RDBMS) design concept. It satisfies the ACID (atomicity, consistency, integrity, and durability) properties required for a database design (Waqas et al., 2015). The stages of our design are as follows. In first stage, we developed database tables and identified the various tables and attributes related to each table. We gathered the required information from student bio data, student semester registrations, courses registered by the students in each session, a student information handbook and institutional rules and regulations guiding undergraduate studies. This information was divided into tables (entities) with attributes as columns while each row in a table represents a recording unit of information. We populated these tables with available information and carefully avoided repetitions. In the second stage of development, we have defined the primary key as attributes or set of attributes that uniquely identify a tuple (row) within each table. Using foreign keys, we established relationships among the various tables in the database (such as one-to- one, one-to-many, and many-to-many) to enforce entity and referential integrity constraints (Harrington, 2016; Olivera, 2019). This is essential to achieve data accuracy and integrity. An entity relationship diagram was designed with DB Designer® software as shown in Figure 1. We applied normalizations to optimize the database, and a set of rules to convert the database to the 5NF (Fifth Normal Form). 5NF is a high degree of normalization for scalability and efficiency.
Figure 1. Entity Relationship Diagram For SARPS Database
We experimented with the first stage of this project with Microsoft Access DBMS, which includes the Microsoft Jet Database Engine (MDE). MDE includes ODBC (Open DataBase Connectivity) driver, Graphical User Interface (GUI) and software-development tools as the Application layer between the user and the DBMS (Tech Target, n.d.; Lambert & Frye, 2015). The OBDC layer was implemented as a driver in MS Access to give a two-tier architecture. It sends the user's request to the database management system and also receives the response from the DBMS to the user.
A spill student is one who exceeds the minimum number of semester α for his/her study as prescribed by the institution. Such student then becomes spill student but can continue studying up to the maximum allowable number of semester β. This means that a student who could not meet the minimum graduation requirements within the window (α, β) is a spill student. Traditionally, with the manual method, the processing of results for spill students is non-trivial. It is one aspect of results processing officers usually avoid. The reasons for this are straight forward.
To provide seamless processing of results for spill students with regular ones, we introduced two similar but different fields: Level (l), and Year (y). For instance, a student may be in 400 Level and Year 5. Year defines the number of years (or sessions) a student has spent studying in the institution while Level indicates the student's level of study. The system captures such student's registration as spill students. By this approach, we have used the same database architecture to process results for both regular and spill students without any error. Therefore, a spill student is one whose y > l in a continuous semester registration.
The first step to correct design error is the normalization of the semester registration table that creates another table named semester courses. Semester registration precedes course registration and contains the following fields: Matriculation number, session, semester, year, level, registration status and registration date. Hence, the registration status of the form "Regular", "Rusticated", "Leave of Absence" OR "No Registration Data" can be inscribed as the registration status of a student in any semester.
Often, errors occur in the computed unit passed when students registered and passed non-prescribed courses. Such error increases the total semester and cumulative units passed. A viable design solution to avoid such errors is to include a separate table “Semester Courses”,as in Figure 2, which specifies approved courses to be offered by each department under a particular programme for a given semester. Students are therefore constrained to register among the approved courses under their programmes for the semester. In any semester, the system resist attempts by students to register for courses outside the ones approved for his/her programme during course registration. As shown in Figure 2, the student with matriculation number 110404002 registered PHS 301 in the 2014/2015 session, which is not included among the approved courses for her programme in particular session. Therefore, the inner join in the entityrelationship diagram between two tables (Semester Courses and Results) in Figure 1 excludes PHS 301 from the student's results during processing.
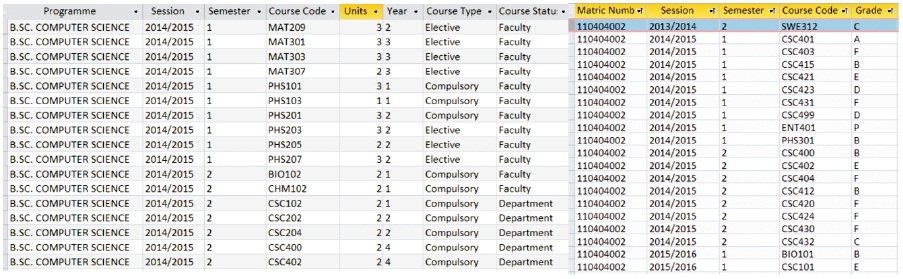
Figure 2. Tables Showing Sections of Semester Courses and Results of Student No. 110404002
Errors leading to double course registration arises if a student registered for the same course twice within the same session and semester for course MAT 104 as shown in Figure 3. To avoid this error, the Matric Number, Session and Semester attributes are jointly designed as composite primary keys. This includes referential integrity which ensures that two rows with the same Matric Number, Session and Semester violate the integrity of the entries.
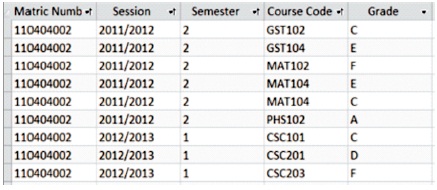
Figure 3. Results of Registered Courses for Student No. 110404002
We considered that some programmes come with options (specializations) which may have different criteria for graduating student under each option. A schema for programmes is designed with programme option to allow separate course information and criteria for programmes with different options (specialization). A sample of such a schema design is shown in Figure 4. One advantage of this design is that the system would not graduate any student who passed less than the required minimum number of units. Similarly, non-graduating students must have registered and passed the required minimum number of course units for at each level (or year) of the programme.
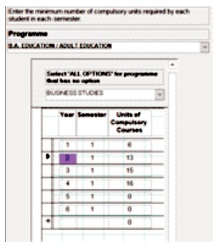
Figure 4. Academic Programmes Options Minimum Required Units
A course offered in one academic programme may have different course units in another programme. Also, a course may be of type “compulsory” for students in one programme, but “Elective” for students in another programme. one instance is that, a course is offered at 200 level for students in one programme, maybe a 300 level course for students in another programme, and this structure may differ from one semester to another. In another instance, a “compulsory” course with 2 units for 200 level students in a session may have its units, type and status changed in the following session. Caution is required when changes are made to data stored within the database. Through the introduction of the “Semester Courses” table, as shown in Figure 5, values of course units, type and status can be changed in the following semester without affecting previous values of these fields in other sessions. The new course units and course types do not replace existing old values but are entered for new session and such changes are affected the students only.
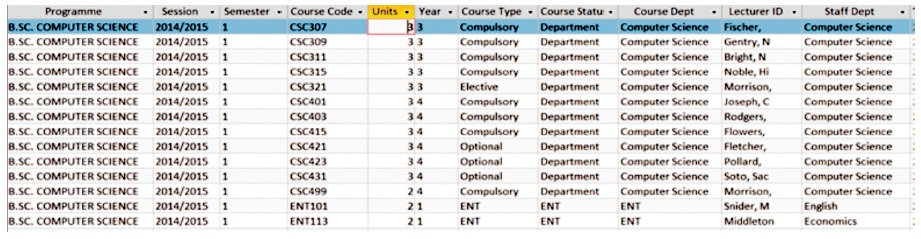
Figure 5. Table Showing List of Available Courses in 2014/2015 First semester
In many cases, it is more convenient to generate students' results having course types, course status and course unit information accompanying each course in the output results. This information is essential for users to determine as quickly as possible, if a student has met certain criteria for a particular situation, for example, to graduate students from the university. However, for university-wide results processing management of courses and their attributes in several programmes course status, types, units, etc., becomes complex. The reason is that if several students from different academic programmes and departments register for a common course, such a course may have different attributes to different programmes. For instance, while such course is "compulsory" and local to students in one department, it may be an "elective" and foreign course with different course units to students in other departments. This again includes time line by session to allow correctness of computed results over successive sessions. Figure 6 shows the table for all courses that address the problems. Based on supplied information of courses supplied for each programme, our approach attached information about a course to the course codes according to the properties of the course in an academic programme. Detail course information is included in the course sheets for spreadsheets and individual transcript results to reduce time spent on verification of results.
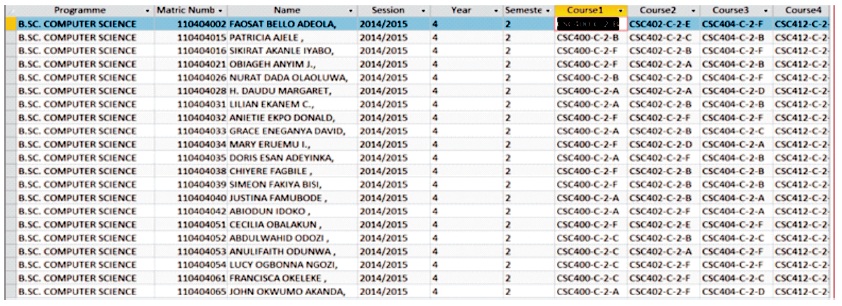
Figure 6. Table Showing Course Code, Course Type, Course Unit, and Grade as a Course Information Unit
Multiple Pass errors occur when a student registered and passed the same course more than once. The rule specifies that a course once passed by a student cannot be registered or graded at the second time. Conventional methods of detecting such errors done through manual vetting. This is an error that may go undetected until manual verification is performed because many of the existing systems are incapable to detect such errors electronically. Such errors occur when students register for courses in which they had passed in any one of the previous semesters. This leads to multiple passes in the same course by a student. An example of Multiple Pass error is illustrated in Figure 7a, Figure 7b and Figure 7c.
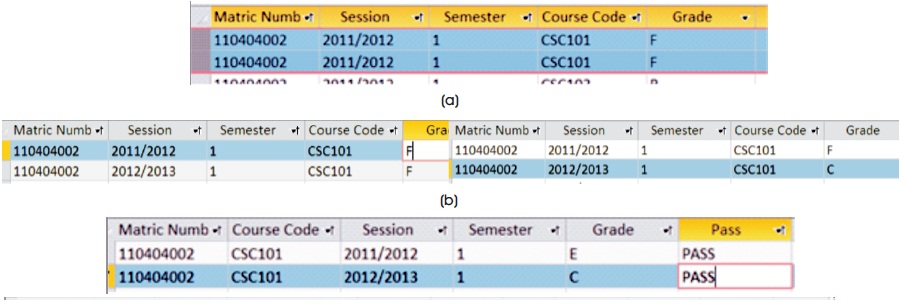
Figure 7. (a) Student Registers the Same Course (Already Failed) in the Same Session and Semester (Allowed), (b) Student Registers a Failed Course CSC 101in Another Session, (c) Students Registers a Passed CSC 101 in Another Session (Not Allowed)
In most existing systems, the errors are not detected since the registration for CSC 101occurs in different sessions. One possible technique to detect such errors is for the system to perform a lookup of previous registration to detect if the course has passed in previous registration. This may look feasible for one or a few numbers of students. However, the technique introduces performance degradation as the number of students increases because it is not scalable. We took advantage of system DBMS constraint in our approach to detect and restrict the occurrence of multiple pass errors. We employed primary key violation restrictions and applied an index to all "passed" courses, which were used as a combination of a composite key to enforce checks for the uniqueness of a record.
The program design identifies the software modules and their relationships as well as the solution statement and coding. The Top-Down design approach was adopted; a design process that begins the system from the topmost module and broken down into subsystems. Each subsystem is taken in turn and broken down further progressively into a program module to achieve a desired design. Figure 8 represents the activity diagram of the interactions from major users of the system, such as System Admin, Departmental Exams Officers, Level Coordinators, Course Lecturers, Students, and the University Admission Officer.
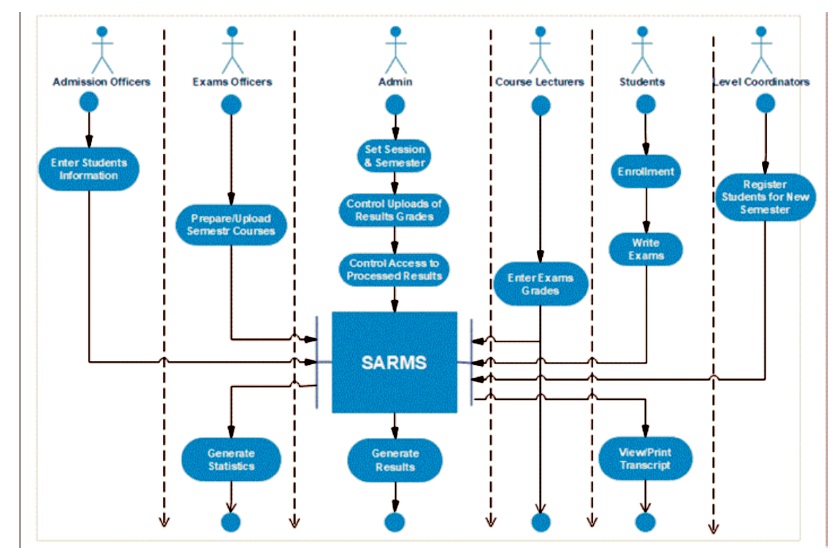
Figure 8. Activity Flow Diagram Of Sarms
The operational flowchart of the system is presented in Figure 9. A user sign in as Admin, Exam Officer (including department), Level Coordinator (including department, and level of student undertaking), Course Lecturer (including the courses taken) or as Student (including Matriculation number). Each user is permitted to interact with the system according to the set privileges as defined by the system administrator. All data inputs, data uploads, and selections by users at different times go into the SARMS database. A set of predefined processes within SARMS compute both semesters and cumulative results. The RegCnt is calculated for each student in each semester as shown in Figure 9.
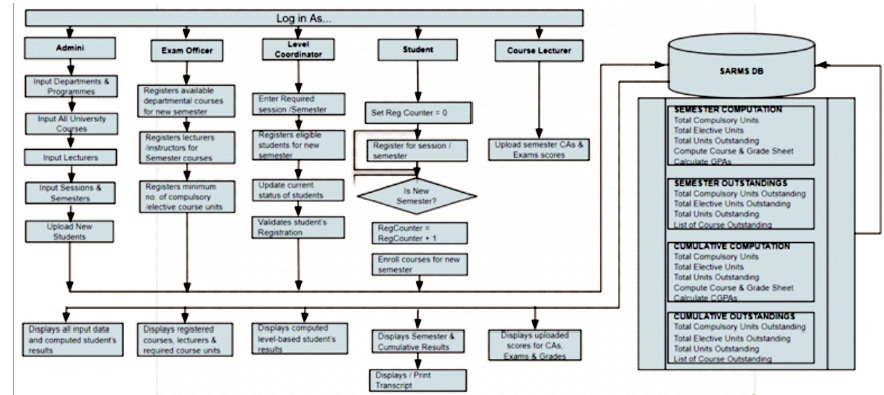
Figure 9. Operational Flowchart of SARMS
In every semester, the system computes the current semester GPAs, the cumulative GPAs of all students in the same level of study up to the current semester. Total Load Unit (TLU), Total Units Passed (TUP) and Total Units Outstanding are the units of compulsory courses outstanding. It also tracks time lines of events and operations on each student's records. It tracks all changes in each record and keeps previous records for future purposes. The system ensures that students registered and passed all prescribed courses before graduation. It prepares blank mark sheets through which the examiner can enter scores of students in continuous assessments and examinations. It ensures that a score sheet contains the list of students who are eligible for scores in a course. The semester GPAs is computed for every student using the relation below.
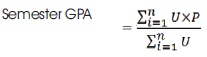
where, U = Course Unit, P = Grade Point and n = Number of courses in the semester Period
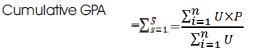
The semester GPAs are computed for every student using the relation below. For the previous semester, GPA is:
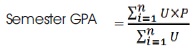
where, U = Course Unit, P = Grade Point and n = Number of courses in the semester. Previous Cumulative GPA (up to the last semester)
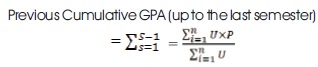
The semester GPAs are computed for every student using the relation below. For the semester that precedes last semester, GPA becomes
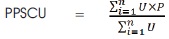
where, U = Course Unit, P = Grade Point and n = Number of courses in the semester.
Cumulative GPA up to the semester that precedes last semester is
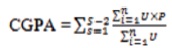
An outstanding course is one in which a student ought to have passed at a particular level of study, but it is either not registered, or it is registered with grade “F” (Fail) or “I” (Incomplete) or "-" (Dash) or " (Blank). Semester courses outstanding is a list of courses outstanding in a semester, while semester units outstanding refers to the total sum of units of courses outstanding in a semester.
The total semester and cumulative units of such courses are computed in each semester as
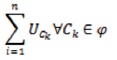
where, n = Number of courses outstanding, U = Course Unit, C = Courses outstanding, and φ = Set of grades with k “F”, “I”, “NR”, “-“, or “.
The system computes both semester and cumulative outstanding courses. Courses may be defined under each course type such as compulsory, required, elective, etc. The set of courses outstanding is listed by each semester and for each course type. It can likewise be listed by the overall semester enrolled according to the academic programme of study. For instance, the set of compulsory courses outstanding for any student at any level can be queried for output. Also, the OCM produces the total units of outstanding courses per semester or overall registered semesters.
Outstanding courses are neither exempted (“EX”) nor passed (“P”) by a student up to the current semester. This includes courses with “F” (Fail), “I” (Incomplete), “NR” (Not Registered) and “-“, or blank grades. Cumulative courses outstanding is a list of courses outstanding up to the current semester, while cumulative units outstanding refers to the total sum of units of courses outstanding up to the current semester. Figure 10 shows the output of a query showing semester units and courses outstanding. The total cumulative units of such courses are computed in each semester as,
where s = number of semesters up to the current semester
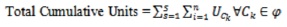
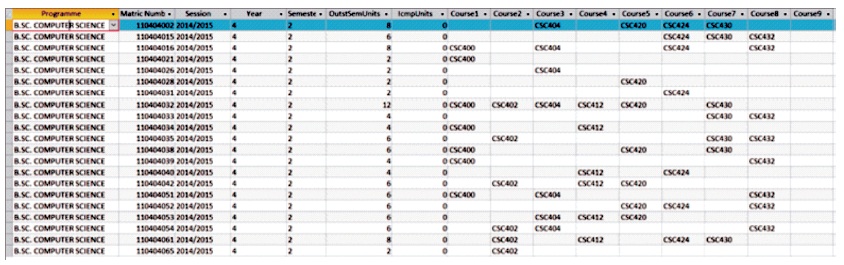
Figure 10. Result of Query Showing Semester Units and Courses Outstanding for Students in 400 Level
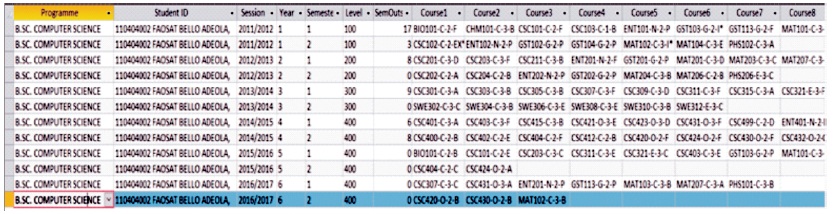
Figure 11. Result of Query Showing Course Information for the Student with Matriculation No. 110404002
Figure 12. Result of Query Showing the Minimum Number of Units Required at Each Level for Computer Science Students
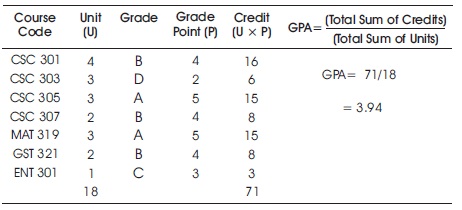
Table 1. Calculation of Grade Point Average (GPA)
The system computes the academic status of each student in each semester. This is based on the registration of current status of the student, the current and previous semester GPAs, and current and previous cumulative GPAs.
Academic Standing of students describes the academic status of the results of each student at the end of a semester. A student can be in “Good Standing”. This is the best status of a non-graduating student. It is different from the GPA values, which further describe the class or division in which any student can be under “Good Standing”. The current academic standing of a student in any semester is determined by his/her academic standing, semester GPA, and cumulative GPA in the previous semester, as well as the current semester and cumulative GPAs. A simplified description of academic standing for graduating and non-graduating students is explained in Table 2.
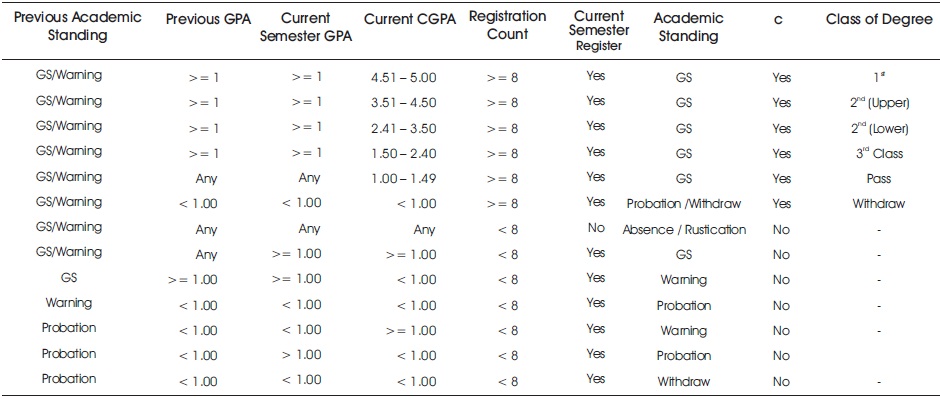
Table 2. Academic Standing for Graduating and Non-Graduating Students
No Registration Data ("INR"): ([REG]>=Nil And [Graduate]=
Good Standing ("GSD"): ([SGPA]>=1 And [CGPA]>=1
Warning ("WRN"): ([RegCnt]=1 Or ([PrevReg]=YES And [PrevPrevReg]=YES) and [CGPA]<1 or (([PSGPA]<1 And [SGPA]<1) Or [CGPA]<1,"PBN",IIf([SGPA]<1,"WRN","- "))))))))
Probation ("PBN"): ([PrevReg]=YES And (([CGPA]<1 And [PSGPA]<1) Or ([SGPA]<1 And [PPSGPA]<1)) or
(([RegCnt]=2 Or [PrevPrevReg]=YES) And (([PSGPA]<1 And [SGPA]<1) Or ([PSGPA]<1 And ([PCGPA]<1 And [SGPA]<1) Or [PCGPA]<1 And [CGPA]<1))
Withdraw ("WDL"): IIf(([PPSGPA]<1 And [PSGPA]<1 And [SGPA]<1) Or ([PSGPA]<1 And ([PCGPA]<1 And [SGPA]<1) Or [PCGPA]<1 And [CGPA]<1)
At each level of student's study, the status of each student is computed in every semester regarding the number of units of courses outstanding, the number of units of compulsory courses outstanding and the list of courses outstanding.
Minimum Cumulative Compulsory Units is given as:
MCCU: DSum("[Compulsory]","[Criteria]","[YrSemes] <= '" & [Criteria]![YearSems] & "' and [Option] = '" & [Criteria] ![Option] & "' and [Programme] = '" & [Criteria]! [Programme] & "'")
Such that each student will be,
GSTU = GSTU – GST; ENTU = ENTU – ENT; CCUU = MCCU – CCU, ECUU = ECUU – ECU;
A students is withdrawn from study programme if he/she registered and passed above the minimum number of units for General Studies Units (GSTU), Entrepreneurship Studies Units (ENTU), Compulsory Courses Units (CCUU), Required Courses Units (RCUU), Optional Courses Units (OCUU), Elective Courses Units (ECUU), and Compusory Units Passed (CUP) is greater than Total Prescribed Unit stipulated for the study (TotUnit), and there are no Semester Units Outstanding (SUO) or Cumulative Units Outstanding (CUO).
Graduate: If (([GSTU]>=0 And [ENTU]>=0 And [CCUU]>=0 And [RCUU]>=0 And [OCUU]>=0 And [ECUU]>=0 And [CUP]-[TotUnit]>=0) And [SUO]<=0 And [CUO]<=0).
CUP = Cumulative units passed, SUO = Semester Units Outstanding, CUO = Cumulative Units Outstanding, and TUPR = Total Units Passed Required.
Table 2 explains the criteria for each academic class.
Withdraw ("WDL"): IIf([RStatus]='ABS' And (([Status- 2]='ABS' Or 'RST') and ([PStatus-1]='ABS' Or 'RST'))
First Class (“1st Class"): IIf([Graduate]="Graduate" and [CGPA]>=4.5)
2nd Class Upper: ([Graduate]="Graduate" And [CGPA]>=3.5 And [CGPA]<4.5)
2nd Class (Lower): ([Graduate]="Graduate" And [CGPA]>=2.4 And [CGPA]<3.5)
3rd Class: ([Graduate] = "Graduate" And [CGPA]>=1.495 And [CGPA]<2.4) "Pass: ([Graduate]="Graduate" And [CGPA]>=1 And [CGPA]<1.49)
The SRC (called RegCnt as in Figure 9) counts the total number of semester registrations by a student during the course of study in the university. It is initialized as 0. It is associated with each student's registration record and increases each time a student registers for a semester. It keeps track of the current registered session and semester of every student. It is useful in determining the academic status of the student.
RegCnt: Last(DCount("[SessionSemester]",
"[RegTable]","[MatricNumber] = '" & [StudentsTable] ![MatricNumber] & "' and [SessionSemester] <= '" & [SessionSemester]![SC] & "'")).
The design prototype was tested using MS Access for quick detection and correction of design errors. The technology selected for implementing the system is XAMPP for the development and testing of applications in PHP and MySQL. Apache is used as the HTTP server, Chrome web browser on Microsoft Windows OS. The system was built on the web platform. The front-end interface was designed using HTML5, CSS3, and JavaScript, while the back end functionalities are powered by PHP server-side scripting language and MySQL (a relational database management system) in designing the database which runs on a web server.
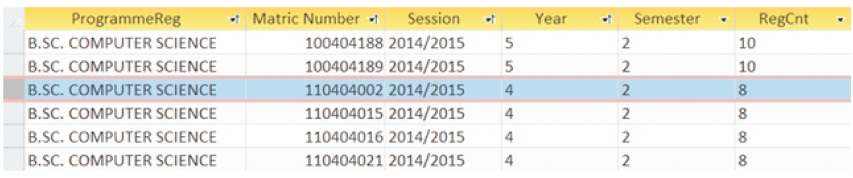
Figure 13. Result of Query that Counts the Number of Times a Student Registered in the Institution
In Semester Enrolment and Course Registration Module (SECRM), students can enroll for the new semester and register for courses based on the prescribed and available number of courses and their units. The SARMS enforces compliance with passed prerequisites courses and ensures that students are not registered below the minimum or above the maximum allowable units in a semester. Students profile will be included in this module to allow every registered student view and update records which are authorized by the University. Figure 14 – 21 shows some SARMS implementation views.
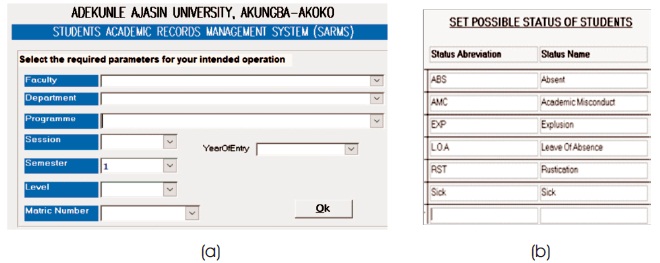
Figure 14. Views Showing (a) Query Parameters, and (b) Students Semester Registration Status.
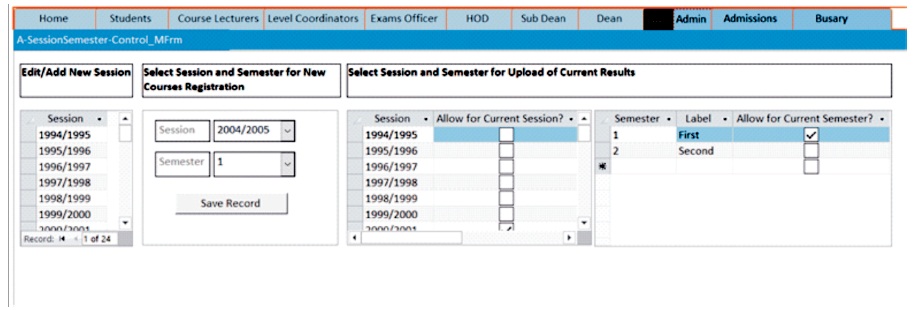
Figure 15. View Showing Session and Semester Setups for Examination Officer in a Department
Figure 16. Interface for Admin Login

Figure 17. Interface for Admin Dashboard
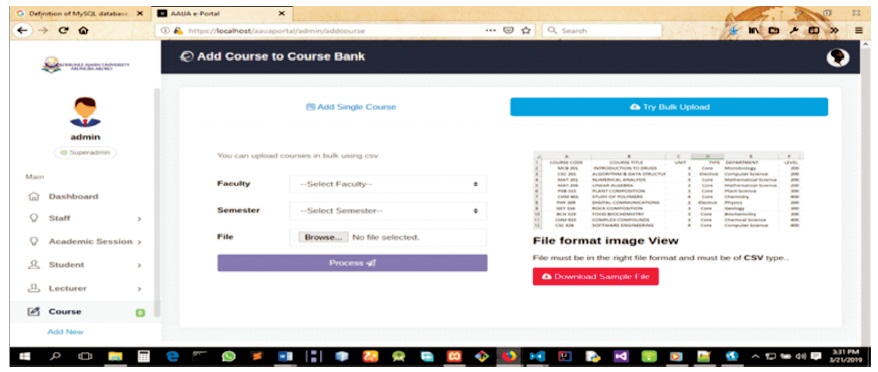
Figure 18. Administrators - Upload Courses in Bulk
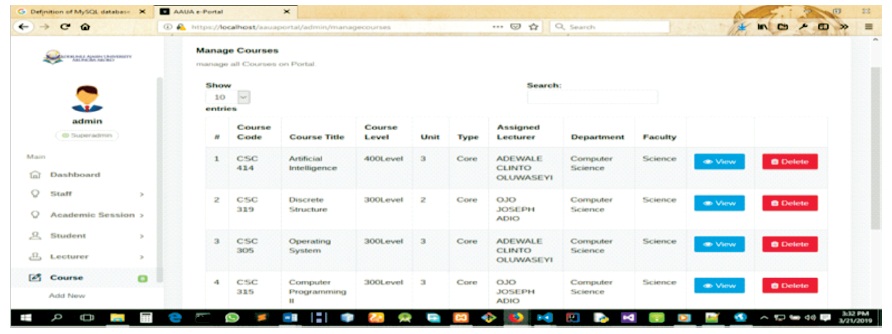
Figure 19. Administrator - Manages Courses
Figure 20. Administrator - Manages Departments
Figure 21. Administrator - Uploads Results
The system generates reports that are useful for various units of the universities such as Academic Planning office Dean's office the Business Committee of Senate (BCS), Office of the Registrar and the Students. The broadsheet of result shows per level including the grades, GPAs, all units, and academic status of students in a semester for consideration of approvals; computed summaries of results computed student transcripts for internal uses; provisions of various statistical reports.
Course Grade Sheet is the grade unit enables the course examiners to provide grades for courses they taught and examined. On the other hand, the unit provides an interface through which registered students can view their marks/grades. The grade structure is in the form "A" to "E" for courses passed with credits, "I" for an incomplete mark, "EX" for courses where students were exempted, "P" for courses passed without credits. The system accounts for grades returned as a dash ("-") or blank (") to compute the number of units taken, units passed as well as GPA.
Transcript report shows individual students' records consisting of courses taken, their grades and the computed semester and cumulative GPA. Transcripts generated from SARPS may form the official university transcript and it can be used to monitor a student's academic per formance. It is a detailed and summarised record of student's academic performance beginning from the first day of enrolment in the university. Students can view or print transcripts of results individually as approved by the institution. Figures 22, 23 and 24 show the transcripts generated for a student with matriculation number 110404002 of department of Computer Science
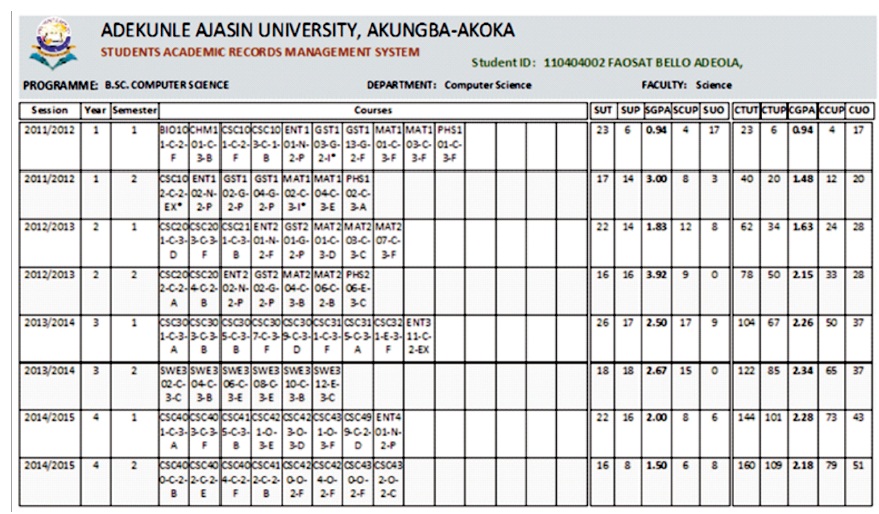
Figure 22. Report of the Transcript of Results from 100 Level to 400 Level for a Student with Matric. No. 110404002
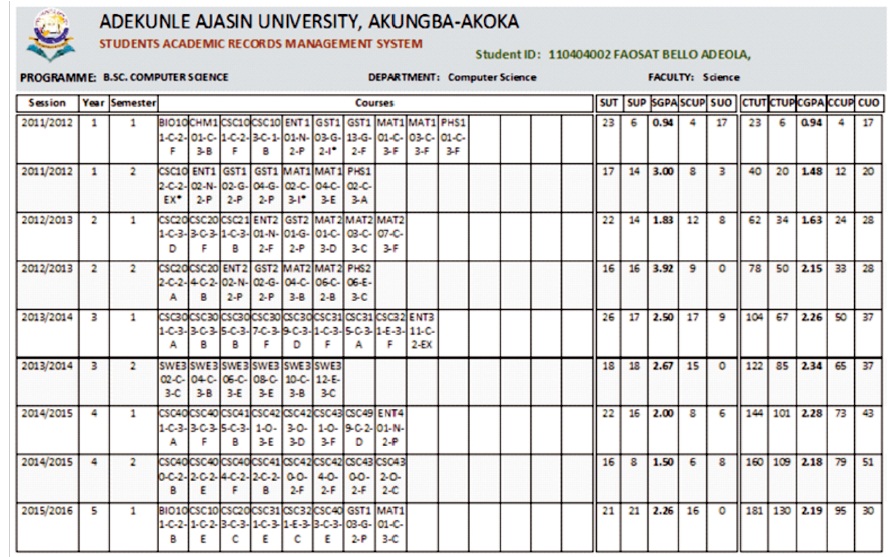
Figure 23. Transcript of Results from 100 Level to 400 Level of a Spill 2 Student
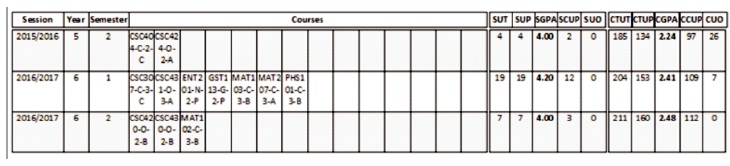
Figure 24. Transcript Record from 100 Level to 400 Level of a Spill 2 Student
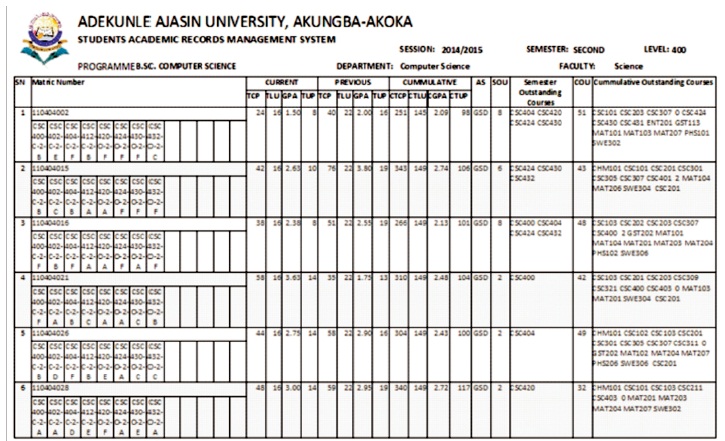
Figure 25. Page 1 Report of Broadsheet Results of Registered Computer Science Students in 400 level
Processed results of students in the same academic level and within the same academic programme are generated as a level-based broadsheet report (Figures 25 and 26). It is a summary of results consisting of a set of students in a semester. However, for the semester, the semester courses and units outstanding as well as cumulative courses and units outstanding are produced. The report represents the official documents of students' academic records for the Business Committee of Senate for verification (vetting). Computations in the broadsheet report include the following outputs: Computations of all GPAs (i.e. current, previous and cumulative);
Computations of the semester and cumulative Total Load Unit (TLU) and Total Units Passed (TUP); Computations of the semester and cumulative courses and units outstanding; checks for graduating students; and computation of students' academic standing
Figure 26 shows the report of broadsheet results of registered computer science students in spill 1.
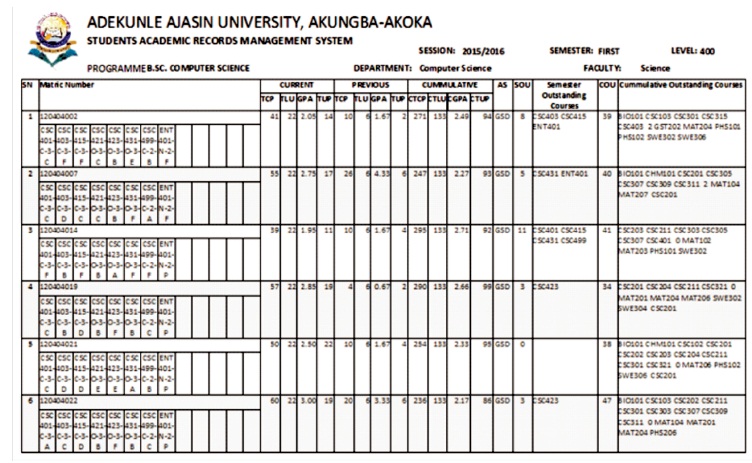
Figure 26. Page 1 Report of Broadsheet Results of Registered Computer Science Students in Spill 1
Figure 27 shows the broadsheet results of a registered computer science students (110404002) in first-semester spill 1. At the end of the first semester 2015/2016 session, the student has:
For Current Semester: Total Cumulative Units Passed (TCP) = 43, Total Load Units = 21, Semester GPA = 2.26 and Total Units Passed (TUP) = 21,
For Previous Semester: Total Cumulative Units Passed (TCP) = 24, Total Load Units = 16, Semester GPA = 1.50 and Total Units Passed (TUP) = 8,
The Total Cumulative Results is: Cumulative Units Passed (TCP) = 329, Total Load Units = 177, Cumulative GPA = 2.19 and Total Units Passed (TUP) = 130
In results, Semester Units Outstanding (SOU) = 0 while Cumulative Units Outstanding (COU) = 30 indicating that he/she has not passed up to the minimum number of credit units to graduate. The course outstanding is listed in the last column of Figure 27. Although the student passed all the registered courses in the current semester such that the semester courses outstanding = 0. The academic standing is “Good Standing”.

Figure 27. Broadsheet Results of a Registered Computer Science Students in Spill 1 First Semester
Figure 28 shows Broadsheet Results of a Registered Computer Science Students in Spill 2 First Semester. Figure 29 shows Broadsheet results of a graduating computer science students in Spill 2 Second semester .

Figure 28. Broadsheet Results of a Registered Computer Science Students in Spill 2 First Semester

Figure 29. Broadsheet Results of a Graduating Computer Science Students in Spill 2 Second Semester
In the first semester of the 2016/2017 session, there were cumulating units outstanding of 7, hence the academic standing is “Good Standing”. By the second semester 2016/2017 after six years of study, student candidate 110404002 completed all the requirements to graduate with both SUO and CUO = 0 and having no courses listed as outstanding. She graduated with 2nd class (lower division) having a cumulative GPA of 2.60.
Full access to the database is restricted to system administrator only. User access to the database is through authentication only. All updates are carried out using database queries and stored procedures after proper validations and data integrity checks. Users have “execute” permissions to store procedures and the stored procedures can be executed only when called from the package. Access level security is parallel to the actual hierarchy in the university organization according to Wang (2001).
For each output, the processing stage is monitored by the system; the facility is provided to rerun any process. However, if there is any oversight, the system requires authentication for tasks and keeps an audit for the same. Before processing results, the system ensures that all expected data are received and updated.
The proposed system adopts innovations and modern technologies to solve the problems involved in real automatic processing and management of student academic records. The proposed implementation of student academic processing system output preserves the culture of academic advising and counseling adopted by the Adekunle Ajasin University, Akungba- Akoko, and many other universities. It is flexible, customizable, multi-user (by all stakeholders), user friendly, fully computerized and efficient. The development of this integrated computerized system will save universities from the embarrassment caused by complaints from students, parents and the University's result management committee. Such complaints arise as a result of problems discovered in several result processing system which not only include inefficiency, i n accuracy, time consumption, costs, and inconveniences but is strenuous nature for its semimanual implementation which is very stressful to level coordinators. This solution will reduce drastically the efforts and time incurred in the manual vetting of processed results. Further work of the project include the implementation of student academic records management system on a cloud computing platform and predictive analysis of students' performance based on previous academic results.