
Parts of Speech tagging (POS) is an essential preliminary task of Natural Languages Processing (NLP). Its aim is to assign parts of speech tag to each word in corpus. The basic POS tags are noun, pronoun, verb, adjective and adverb, etc. POS tags are needed for speech analysis and recognition, Machine translation, Lexical analysis like word sense disambiguation, named entity recognitions, Information retrieval and this system also helped to uncover the sentiments of given text in opinion mining. At the same time, many Indian languages lack POS taggers because the research towards building basic resources like corpora and morphological analyzers is still in its infancy. Henceforth in this paper, a POS tagger for Telugu language, a South Indian language is proposed. In this model, the lexemes are tagged with various POS tags by using pre-tagged corpus, however a word may be tagged with multiple tags. This ambiguity in tag assignment is resolved with Stochastic Machine Learning Technique, i.e. Hidden Markov Model (HMM) Bigram tagger, which uses probabilistic information built based on contextual information or word tag sequences to resolve the ambiguity. In this system, the authors have developed a pre-tagged corpus of size 11000 words with standard communal tag sets for Telugu language and the same is used for testing and training the model. This model tested with input text data consists of different number of POS tags at word level and achieved the average performance accuracy of 91.27% in resolving the ambiguity.
Natural Language Processing (NLP) is directly related to human computer interaction in the field of computer science, semantics, and artificial intelligence in which computer has to understand and generate natural languages. Building NLP system is difficult because human's natural language is not always characteristic and structured (Baker et al., 2004). It is carried in different processing steps, namely sentence boundary detection, word segmentation, Parts of Speech (POS) tagging, word sense disambiguation, sentiment analysis, etc.
Parts of Speech tagging is an important task in the field of Natural Language Processing, which handles the lexical level ambiguities in linguistics, text analysis, and information retrieval systems. Appropriate part of speech tags, i.e. nouns, pronoun, verb, adjective and adverb, etc, are assigned in POS tagging for each word in a given input text. While assigning the POS tags to words, it has to consider the lexical and semantic features of a word in connection with related neighboring words in a phrase, sentence, paragraph, etc. In morphologically rich languages like Indian languages, a single word may belong to more than one POS tag (Brill, 1992). Resolving these ambiguities and label a word with suitable POS tag is a challenging task. And also, manual POS tagging is time and labor-intensive application. Hence research is in progress for automating the process based on grammatical rules, empirical methods using machine learning techniques, and also hybrid approaches.
Remarkable research work has already been done in POS tagging for English, European, and few Indian languages, however research work on part of speech tagging of Telugu Language, a South Indian Dravidian language is still in infant stage (Kumar & Josan, 2010). The rationale behind this is scarcity of standardized benchmark resources like machine readable grammatical rules and outsized pre-tagged corpus for Telugu. Subsequently, many attempts have been made by researchers to develop a POS tagger for Telugu language. However, context and behavior of a word is different in a particular context of word. It is necessary to address and resolve this lexical ambiguity for most of the Indian languages (Baker et al., 2004). As the processing of natural language is complex, sometimes it is difficult to assign appropriate tag to a word. Hence POS taggers developed should be accurate, efficient, and reusable and also able to predict the best tag based on the on-hand information.
In this paper, the authors have developed POS tagging system for Telugu language to tag the words with Parts of Speech tags with no ambiguity. In the process of Natural language processing of Telugu language, it is important to remove ambiguity in parts of speech tagging. This is very much essential for further processing like parsing, morphological analysis, and chinking many more operations. POS tagging of Telugu language has many applications in the field of Human interactions with the machine in the Telugu language. The applications are speech analysis and recognition, Machine translation, Lexical analysis like word sense disambiguation, named entity recognitions, Information retrieval, and this system also helped to uncover the sentiments of given text in opinion mining of Telugu language. In this paper, they described how POS tagging is performed with pre-tagged corpus and disambiguate the multiple tag assignments at word level with bigram HMM tagger. The study shows that the system can resolve the ambiguities with accepted accuracy.
Many POS Tagging approaches were developed based on supervised and unsupervised machine learning for various languages (Brill,1992; Alex & Zakaria, 2014; Ekbal, Mondal, & Bandyopadhyay, 2007; Kumavath & Jain, 2015). Supervised POS taggers use tagged corpus which comprises words with POS tags and further the system is trained on this pre-tagged corpus and tested for unseen text. Unsupervised POS tagging models does not incorporate with pre-tagged corpora. But as a substitute they do used some algorithmic techniques to assign tag sets automatically. POS taggers are made available based on three different approaches (Kumavath & Jain, 2015). They are as follows,
In this approach, a language resource dictionary is built based on the lexical, syntactic, and semantic rules of a language and tag a word appropriately. When ambiguities are raised with tags, use some linguistic aspects and contextual relations with neighboring words. Rule based tagger is divided into two steps:
We can build tagger/trainer that labels each word in a sentence with its POS tag, which in turn can be used to build labels for words in new sentences. Some machine learning approaches use statistical features to resolve the ambiguities in labeling named entities. Statistical or stochastic approach uses probabilistic and statistical information to assign tags to words and they purely depend on the corpus and further no grammar rules are used.
A blend of rule based and machine learning approach defines Hybrid approach. This system first uses machine learning based approach in which probabilistic analysis is carried out on pre-tagged corpus and then apply rule-based approach on remaining untagged corpus. In machine learning based approach, several techniques are used. Several machine learning techniques, such as Conditional Random Field (CRF), Hidden Markov Model (HMM), Maximum Entropy, and Support Vector Machine (SVM) have already proved their performance in POS tagging. Rule based approach focuses on grammar rules depending on a particular language. Hybrid approach performs POS tagging efficiently because probabilistic information as well as grammar rules was used.
There are numerous POS taggers developed for many Indian languages like Hindi, Bengali, Marathi, Punjabi, Kannada, Tamil, Malayalam, and for Telugu also using rule based, machine learning, and hybrid approaches. In this section, all these taggers were presented with respect to their approach adopted, corpus size, and performance accuracy.
Agarwal and Mani (2006) developed a POS tagger for Hindi language based on Conditional Random Field. In this model, the system is trained on Hindi morphemes corpus in which each morpheme is tagged with suitable POS tag and achieved an accuracy of 82.67% using 21000 words corpus.
Shambhavi, Ramakanth Kumar et al. proposed POS tagging of Kannada Language using supervised machine learning classification algorithms like second order Hidden Markov Model (HMM) and Conditional Random Field (CRF) (Shambhavi, Ramakanth, & Revanth, 2012). In this system, 51269 manually tagged words from EMILLE corpus were used for training with 25 tagsets. The test data sets approximately 2892 words are extracted from websites and show that the accuracy gained from HMM and CRF is 79.9% and 84.58%, respectively.
Selvam and Natarajan (2009) have presented a rule based morphological analyzer for POS tagging of Tamil Language. This system performs annotation on Tamil Bible which is used as POS tagged corpus. Rule based techniques further improved with statistical methods to handle inflectional and derivational word forms. This system achieved an accuracy of 85.56%.
Sarkar and Gayen (2013) have proposed a Trigram HMMBased POS Tagger for Indian Languages. This system produces POS tags for each word in raw input text. Unknown words are handled by integrating suffix analysis with prefix analysis and it is tested for four Indian Languages, such as Bengali, Hindi, Marathi, and Telugu and recorded good accuracy.
Dandapat and Sarkar (2006) addressed the POS tagger based on statistical approach using semi supervised bigram HMM and a ME model for Bengali Language 40,000 annotated words are used for training with HMM and ME algorithms and tested on arbitrary selected 5000 words with 40 different tags. To handle unknown words, a morphological analyzer is used and reported accuracy of 89% approximately on test data. Supervised learning model are more superior than other models in terms of performance.
Pattabhi, Rao, Ram, Vijayakrishna, and Shoba (2007) have proposed a Hybrid POS tagger for Indian Languages using probabilistic rule-based approach. Lexical rules were used to handle unknown words and recorded performance of 58.2%. Accepted descent performance due to the agglutinative nature of Telugu language and presence of more unknown words. This system identifies POS tags correctly for 3,547 words out of 6,098 words of test data set.
Patel and Gali (2008) have proposed Conditional Random Fields based part of speech tagger for Gujarati language. and is trained on corpus of size 10,000 words and tested on 5,000 words with recorded performance of 92%.
Sharma and Lehal (2011) have proposed part of speech tagger for Punjabi language using Hidden Markov Model. This model allocates the correct tag to the words with multiple POS tags by taking existing POS tagger as input using Viterbi algorithm of HMM with bi-gram model. It achieves the accuracy of 90.11% when trained on corpus of 20,000 words and was tested on the corpus containing 26,479 words.
Antony, Mohan, and Soman (2010) have proposed Part of Speech Tagger for Malayalam based on machine learning approach with Support Vector Machine (SVM). Ambiguities in lexical items are resolved and an appropriate tag set was assigned for Malayalam words. This model used Malayalam corpus of size 1,80,000 words and 20,000 words were manually tagged and trained with Support Vector Machine (SVM) with achieved accuracy of 63%. Jyoti, Darbari, and Mathur (2013) developed a simple and efficient Part of Speech Tagger using statistical approach Marathi, which is morphologically rich language. In this, a set of Hand coded rules are used with Unigram, Bigram, Trigram, and HMM methods to compute frequency and probability to achieve high accuracy.
Kumar and Josan (2010) have presented a survey on various implementations for POS tagging using rule based approaches and machine learning techniques like SVM, CRF, HMM, ME for Indian languages. The languages addressed are Hindi, Bengali, Malayalam, and Telugu. Hindi POS tagger is developed with HMM, ME, and CRF models with accuracy 93.05%, 89.34%, and 82.67%, respectively. And also morphology-based approach was implemented to identify POS tags in Hindi with an accuracy of 93.45%. SVM and CRF machine learning techniques were implemented to find POS tags in Bengali with accuracy 86.94% and 90.3%, respectively. For Malayalam language, POS tags are identified by using SVM and HMM with recorded accuracy 94% and 90%, respectively. Also POS tagger was presented for Telugu language based on rules, Brills tagger, and ME approach with acceptable accuracy 98%, 90%, and 81.78%, respectively.
Models which make use of frequency or probability are labelled as either Stochastic or Statistical. Parts of Speech tagging is defined as the word is tagged with possible parts of speech tags like noun, pronoun, verb and adverb, etc., liable on the grammatical rules of an input language, i.e POS tagging is a task to determine the sequence of part of speech tags T= t1, t2, t3, ....tn , for a given sequence of words W= w1, w2, w3, ....wn , in a sentence (Dermatas & Kokkinakis, 1995). Nevertheless, lexical words have ambiguous meanings, where multiple POS tags assignment is possible. Hence it is essential to disambiguate the POS tags assigned to the lexemes based on their usage in the given sentence. This is performed by stochastic techniques, which compute the probabilities with which word associates with a specific tag (Brants, 2000). This information is used to resolve the ambiguities while assigning POS tag to word. These stochastic taggers use tag sequence probabilities and word frequency measurements. An alternative to the word frequency approach is to calculate the probability of a given sequence of tags occurring. It is referred to as ngram approach, where the value of n can be 1, 2, or 3. These are represented by Unigram, Bigram, and Trigram models (Hasan, UzZaman, & Khan, 2007). Here Bigram tagger is used which assign tags considering context.
Word frequency measurements: Ambiguous word is assigned with a higher frequency tag in the training set.
Tag sequence probabilities: Ambiguities are resolved based on the probability that it occurs with 'n' prior tags.
Example:
In the example sentences, Pragathi has ambiguous POS tags Noun and Adjective. Hence to resolve the ambiguity, the context of the word in sentence is considered based on bi-gram probabilities. The probability driven approach HMM is used to assign the right tags for right context.
In this paper, Part of Speech (POS) tagging for Telugu language has been developed using Hidden Markov Model. The key idea is to enhance the performance of tagger by combining usage of statistical information of both tag sequence probabilities and word frequency measurements is known as the Hidden Markov Model (HMM). HMM is the most popular statistical model for POS tagging. Markov Chain is essentially the simplest known Markov model, that it obeys the Markov property. The Markov property suggests that the distribution for a random variable in the future depends solely only on its distribution in the current state, and none of the previous states have any impact on the future states. HMM also avoids smoothing. HMM (Hidden Markov Model) represents tags as hidden states and words as observable outputs (Ekbal, Mondal, & Bandyopadhvag, 2007) is shown in Figure 1.
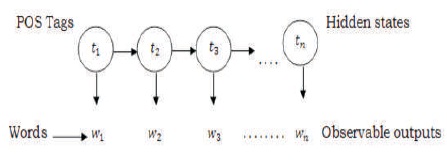
Figure 1. Representation of HMM
HMM uses two sources of information to resolve ambiguity in a word's POS tag:
HMM usually tags one sentence at a time. Given the sentence, it chooses the tag sequence that maximizes P(t1,n| w1,n).
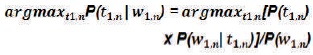
Find the t1,n that maximizes the probability, the denominator(constant) can be ignored:
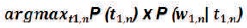
HMM is represented as quintuple notations HMM= (Q, A, O, B)
Q = Set of states: q0 (start state) and qf (final state)
A =Transition probability is the prior probability (tag sequence) transition from one node to another.
O =Sequence of observations (words)
B = Sequence of observation likelihoods (probability of observation generated at state) – likelihood (word sequence given tag sequence)
To build an HMM tagger:
The system is based on statistical Bigram model as shown in Figure 2, in which most probable tag is assigned for word based on the tags-the previous tag and the current tag.
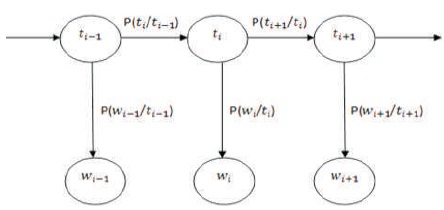
Figure 2. Working of Bigram Model
Tag assignment in bigram model is based on the context of current word in given sentence. This process is mathematically modeled as equation (3).
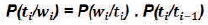
To model any problem using a Hidden Markov Model, a collection of observations and a collection of possible states are to be needed. The states in an HMM are hidden. In the Part of Speech tagging problem, the observations are the words themselves in the given sequence. As for the states, which are hidden, these would be the POS tags for the words.
Learning the transition probabilities: Transition probabilities represent the probability of transitioning to another state given a particular state.
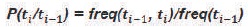
Learning the emission probabilities: Emission probabilities represent the probability of making certain observations given a particular state.
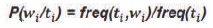
POS tagging system for Telugu Language has been developed in the proposed system. The input is Telugu text taken from Telugu newspapers. Then the corpus is developed and the POS tags that are considered are tag set of 13 tags listed in Table 1. The next step is to preprocess the developed corpus in two steps. Firstly, sentence segmentation is the process of dividing the Telugu text file into number of sentences using delimiters. And then Word Tokenization, divides each sentence in a text file into words called tokens based on space. The preprocessed corpus is trained and tested through Bigram HMM model to assign POS tags. During HMM Train, HMM parameters, Transition Probability, and Emission Probability have to be computed for the given input as annotated Telugu text file. Transition Probability is the probability of previous state in a sentence given a particular state. Emission Probability is the probability calculated as occurrence of a particular observation for a given particular state. During HMM test, the optimal sequence of tags is determined by Viterbi algorithm.
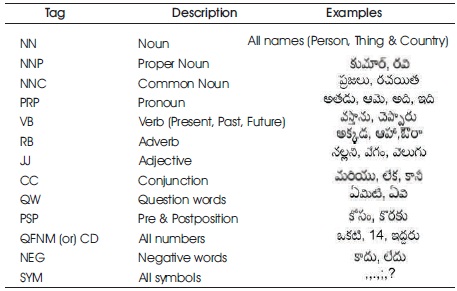
Table 1. Sample POS Tagset
POS Tags for Telugu Language: The structured format is different from language to language. Telugu follows Subject, Object, and Verb pattern. The POS Tags of Telugu are described below in detail:
Noun 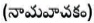 : It refers to a person name, country name, and a thing name. NN stand for Noun. For a particular name, proper noun is used, which stands as NNP.
: It refers to a person name, country name, and a thing name. NN stand for Noun. For a particular name, proper noun is used, which stands as NNP.
Eg: 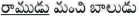 (Ramudu is a good boy)
(Ramudu is a good boy)
Pronoun 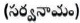 : A word that is used instead of a noun or noun phrase is called as Pronoun. It is represented as PRP.
: A word that is used instead of a noun or noun phrase is called as Pronoun. It is represented as PRP.
Eg: 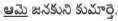 (She is the daughter of King Janaka)
(She is the daughter of King Janaka)
Verb 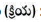 : It is used to describe an action, state or occurrence. Verb is denoted by VB.
: It is used to describe an action, state or occurrence. Verb is denoted by VB.
Eg: 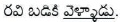 (Ravi went to school)
(Ravi went to school)
Adjective 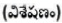 : It serves as a modifier of a noun to denote the quality of the thing named. It is represented as JJ.
: It serves as a modifier of a noun to denote the quality of the thing named. It is represented as JJ.
Eg: 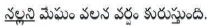 (Its raining because of Black clouds)
(Its raining because of Black clouds)
Adverb 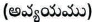 : Word that describes a verb, an adjective and another adverb used to represent place, time, or degree. Adverbs can also be used to modify whole sentence. RR is used to denote adverb.
: Word that describes a verb, an adjective and another adverb used to represent place, time, or degree. Adverbs can also be used to modify whole sentence. RR is used to denote adverb.
Eg: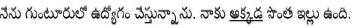 (I am working in Guntur city. There I have a house of my own)
(I am working in Guntur city. There I have a house of my own)
Conjunction 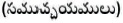 : A word used to connect clauses or sentences in the phrase. Conjunction is denoted by CC.
: A word used to connect clauses or sentences in the phrase. Conjunction is denoted by CC.
Eg: 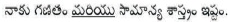 (I like Mathematics and General Science)
(I like Mathematics and General Science)
Preposition 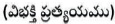 : A word that is used before a noun, a noun phrase or a pronoun connecting it to another word. It is represented by IN.
: A word that is used before a noun, a noun phrase or a pronoun connecting it to another word. It is represented by IN.
Eg: 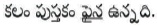 (Pen is on the book)
(Pen is on the book)
Tagset: Different organizations and people follow general principles and design strategies for the development of different tag sets (Vijayalaxmi and Patil, 2010). In general, most of the tag sets are language specific and are derived from the lexical category of the word. Based on the idiosyncrasies of Indian languages, limited tag sets are common and others are specific to particular language (Reddy & Sharoff, 2011). For POS tagging, standard communal tag sets are designed with 13 tags (Dash, Bhattacharyya, & Pawar, 2016). Table 1 shows the description of tag set for Telugu language.
The proposed system architecture is shown in Figure 3, which is organized into three modules.
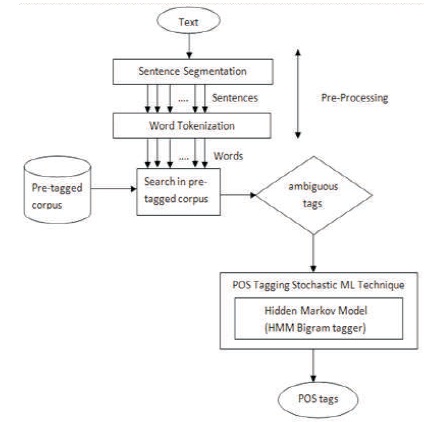
Figure 3. Architecture for POS Tagging
5.2.1 Pre-Processing
The first module is pre-processing where Sentence segmentation and Word Tokenization is done for input text file. The input is of Telugu text.
5.2.2 POS Tagger
The pre-tagged corpus or annotation is the input for processing of POS tagging. Pre-tagged corpus consists of words with tags for a sentence. Pre-tagged corpus is also called as training data. One word may occur with multiple tags. So, there is a chance to raise the ambiguity. To resolve the ambiguity, machine learning technique called HMM is applied. HMM uses Bigram tagger taking the context into consideration.
5.2.3 Ambiguity Resolver
The training data is trained using the emission and transition probabilities. The test data is tested by using Viterbi algorithm. The ambiguity is resolved and tags are generated for test data based on the context of the sentence.
Algorithm APRIT ()
Begin
1) Import Telugu text file from Telugu Newspaper or blogs.
2) call sentence_segment()
{
Read characters until delimiter
Repeat step 2 for given input text.
}
3) call word_tokenize()
{
Read characters until space
Repeat the process for entire Telugu text
}
4) Corpusdevelopment ()
{
Develop a pre-tagged corpus or annotation
Corpus consists of words with tags.
One word may encounter with multiple tags.
}
5) Resolve Ambiguity ()
{
HMM Train()
{
train the data, calculate the emission, and transition probabilities.
calculate these probabilities, HMM Bigram tagger is developed.
}
HMM Test ()
{
To test the data, Viterbi algorithm is used.
Assign tags to the data considering context.
}
}
End
Step 1: Consider input test file as
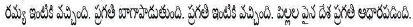
Step 2: Split input test file into sentences

Step 3: Split sentences into tokens

Step 4: Annotation or pre-tagged corpus
Training data:

Step 5: Resolve ambiguity and assign tags based on context
Test data:
Let us consider the computation using the example:
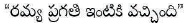
Here 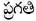 word has more than one POS tags, i.e. ambiguous as either NN or JJ tag. To resolve ambiguity and generate correct tag based on context, emission and transition probabilities have to be calculated.
word has more than one POS tags, i.e. ambiguous as either NN or JJ tag. To resolve ambiguity and generate correct tag based on context, emission and transition probabilities have to be calculated.
Emission probabilities of 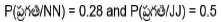
Transition probabilities of P (NN/NN) = 0.28 and P(JJ/NN) = 0
The computation of HMM Bigram tagger is P(NN/q ) x 0 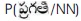 x P(NN/NN) x P(VB/NN) = 0.0054 considering
x P(NN/NN) x P(VB/NN) = 0.0054 considering 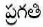 as NN.
as NN.
The computation of HMM Bigram tagger is P(NN/q ) x 0 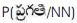 x P(NN/JJ) x P(VB/NN) = 0
x P(NN/JJ) x P(VB/NN) = 0 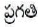 considering as JJ.
considering as JJ.
As the probability of being NN is more than probability of being JJ, NN tag set is assigned for word '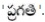 '. So, the tag NN with maximum probability is assigned to an ambiguous word.
'. So, the tag NN with maximum probability is assigned to an ambiguous word.
The authors have developed WordNet based on most frequently used terms collected from Telugu daily newspapers consists of 11,000 words with their id, POS tag, gloss, example, and synset of that word (Dash et al., 2016). WordNet comprises of 7620 nouns, 910 verbs, adverbs 220, and adjective 2250. The experimental results are evaluated based on word level tagging. They have taken input text with maximum of 10000 words and adopted 80-20% rule for training and testing. However, HMM model may produce in admissible tags while it assigns an appropriate tag for the given word. The performance of the developed model is measured in number of iterations with input text consisting of different number of POS tags at word level and recorded average performance accuracy as 91.27%. And also, in experimental study it is observed that as the corpus size increases there is graceful increase in the false positives and false negatives as shown in Table 2 and visually in Figure 4 with different bin sizes of input text consists of 2500, 5000, 7500, and 10000 POS tags.
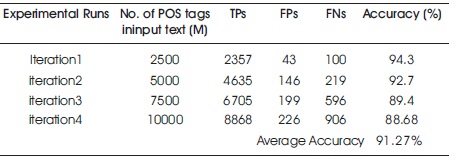
Table 2. Performance Accuracy with Different Number of POS Tags in Input Text
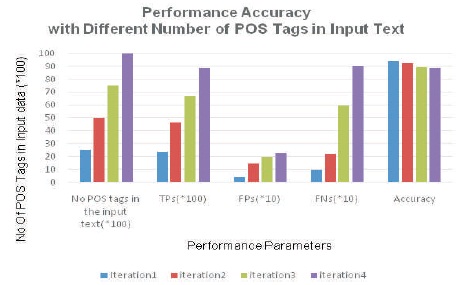
Figure 4. Performance Accuracy in Number of Iterations with Different Input Data Sizes
Number of POS tags tagged correctly: TP
Number of POS tags tagged incorrectly: FP
Number of POS tags tagged as unknown: FN
Total number of POS tags in the input text: M
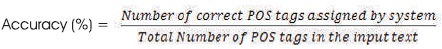
Comparative study of performance of the proposed system with POS tagging for Indian languages like Marathi, Hindi, Bengali, Kannada, Malayalam, and Punjabi is performed with respect to corpus size and recorded accuracy as follows and is shown in Table 3 and Figure 5.
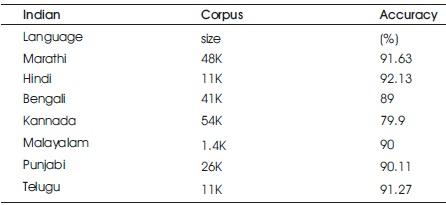
Table 3. Performance Comparison of POS for Different Indian Languages
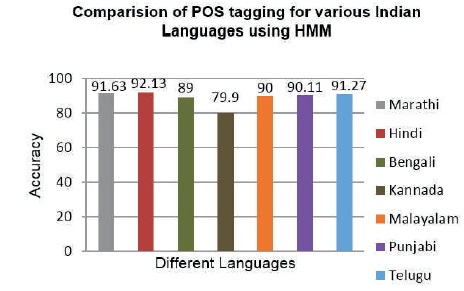
Figure 5. Performance Comparison of POS for Different Indian Languages
Accuracy of POS tagging for Telugu Language using various machine techniques, such as Maximum Entropy, Support Vector Machines, and Hidden Markov Model is shown in Table 4 and Figure 6.

Table 4. Performance of POS for Telugu Language
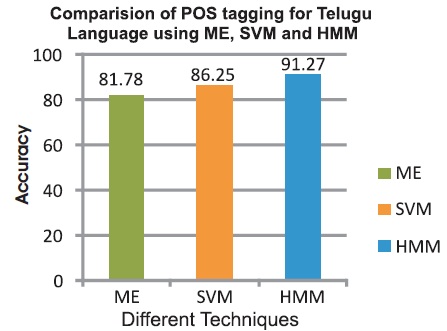
Figure 6. Performance of POS for Telugu Language
Natural Language Processing (NLP) has greater impact on processing of text. Part-of-Speech tagging is highly prominent operation in any Natural Language based applications. HMM is the most widely used technique to generate parts of speech tags. Hence it adopted to implement POS tagging system for Telugu language. HMM Bigram tagger is a generative and probabilistic model for Part of Speech Tagging, which does not assign tags to individual words, but selects the best tag sequence for the entire sentence. The authors have presented a well-organized and meek POS tagger for automatic tagging with 11,000 words corpus comprising of 7620 nouns, 910 verbs, adverbs 220, and adjective 2250. Viterbi algorithm is used to test the tagger. The correct word-tag combinations were disambiguated using the contextual information available in the text. Series of experiments carried with input text consists of different bin sizes with 2500, 5000, 7500, and 10000-word level POS tags and recorded average performance accuracy as 91.27%. The level of performance of POS tagger decides the performance levels of NLP tools. Henceforth, the system performance can be enhanced by augmenting more pre-tagged words to the WordNet and increasing the number of POS tags in the tag set. Further, different machine learning techniques can be adopted to achieve better results. Natural Language Processing of Indian Languages is still in inception stage and various approaches can be used to develop effective and powerful POS taggers. However, it becomes fruitful whenever full pledged pre-tagged corpus with all kinds of POS tags in natural languages is developed. Furthermore, the proposed system evaluated the tag assignment at word level, which is not an inevitable unit for some natural language applications, where units like the sentence, the paragraph, or the document are often more suitable.